本文提出使用可学习的元令牌来制定稀疏令牌,这有效地学习了关键信息,同时提高了推理速度。从技术上讲,主题标记首先通过交叉关注从图像标记中初始化。提出了双交叉注意(DCA)来促进图像令牌和元令牌之间的信息交换,其中它们在双分支结构中交替充当查询和密钥(值)令牌,与自注意相比,显著降低了计算复杂度。通过在具有密集视觉标记的早期阶段使用DCA,获得了不同大小的分层结构LeMeViT。在分类和密集预测任务中的实验结果表明,与baseline相比,LeMeViT具有1.7倍的显著加速、更少的参数和有竞争力的性能,并在效率和性能之间实现了更好的权衡。
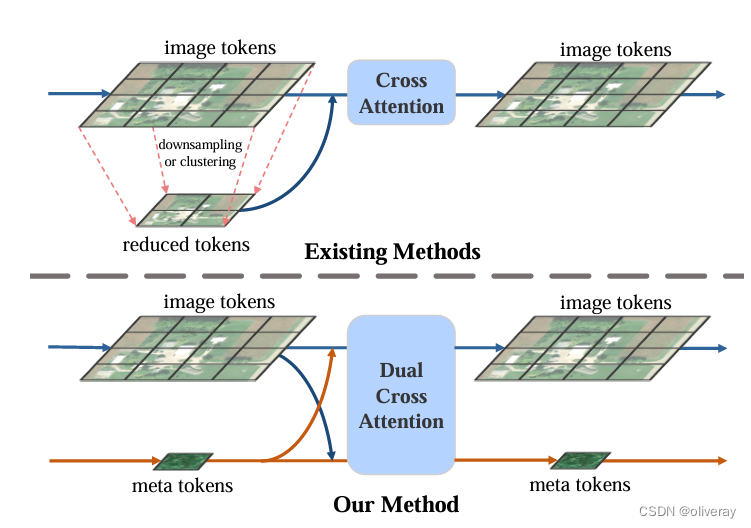
现有方法通常使用下采样或 clus tering 来减少当前块内的图像标记数量,这依赖于强先验或对并行计算不友好。而通过学习元标记稀疏地表示密集的图像标记。元代币通过计算高效的双交叉注意力块以端到端的方式与图像代币交换信息,促进信息分阶段流动。
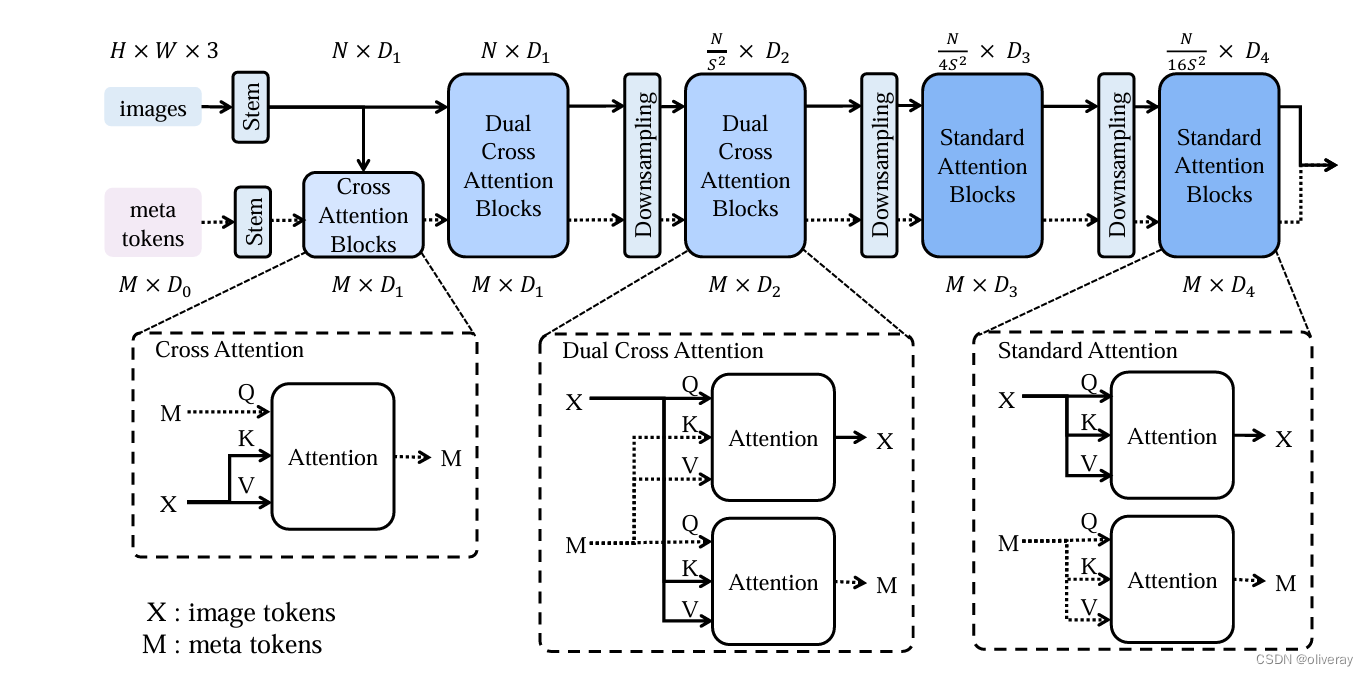
LeMeViT总结构:LeMeViT由三个不同的注意力块组成,从左到右排列为交叉注意力块、双交叉注意力块和标准注意力块。
通过代码来实现:
def scaled_dot_product_attention(q, k, v, scale=None):
"""Custom Scaled-Dot Product Attention
dim (B h N d)
"""
_,_,_,dim = q.shape
scale = scale or dim**(-0.5)
attn = q @ k.transpose(-1,-2) * scale
attn = attn.softmax(dim=-1)
x = attn @ v
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x):
"""
x: NHWC tensor
"""
x = x.permute(0, 3, 1, 2) #NCHW
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) #NHWC
return x
class Attention(nn.Module):
"""Patch-to-Cluster Attention Layer"""
def __init__(
self,
dim,
num_heads,
attn_drop=0.0,
proj_drop=0.0,
**kwargs,
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} not divisible by num_heads {num_heads}"
self.num_heads = num_heads
self.use_xformers = has_xformers and (dim // num_heads) % 32 == 0
self.q = nn.Linear(dim, dim)
self.k = nn.Linear(dim, dim)
self.v = nn.Linear(dim, dim)
self.attn_drop = attn_drop
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_viz = nn.Identity()
def forward(self, x):
if self.use_xformers:
q = self.q(x) # B N C
k = self.k(x) # B N C
v = self.v(x)
q = rearrange(q, "B N (h d) -> B N h d", h=self.num_heads)
k = rearrange(k, "B N (h d) -> B N h d", h=self.num_heads)
v = rearrange(v, "B N (h d) -> B N h d", h=self.num_heads)
x = xops.memory_efficient_attention(q, k, v) # B N h d
x = rearrange(x, "B N h d -> B N (h d)")
x = self.proj(x)
else:
x = rearrange(x, "B N C -> N B C")
x, attn = F.multi_head_attention_forward(
query=x,
key=x,
value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q.weight,
k_proj_weight=self.k.weight,
v_proj_weight=self.v.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q.bias, self.k.bias, self.v.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=self.attn_drop,
out_proj_weight=self.proj.weight,
out_proj_bias=self.proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=not self.training, # for visualization
average_attn_weights=False,
)
x = rearrange(x, "N B C -> B N C")
if not self.training:
attn = self.attn_viz(attn)
x = self.proj_drop(x)
return x
class StandardAttention(nn.Module):
def __init__(
self,
dim,
num_heads,
scale = None,
bias = False,
attn_drop=0.0,
proj_drop=0.0,
**kwargs,
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} not divisible by num_heads {num_heads}"
self.num_heads = num_heads
self.use_flash_attn = has_flash_attn
self.use_xformers = has_xformers and (dim // num_heads) % 32 == 0
self.use_torchfunc = has_torchfunc
self.qkv = nn.Linear(dim, 3 * dim)
self.attn_drop = attn_drop
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_viz = nn.Identity()
self.scale = dim**0.5
# @get_local('attn_map')
def forward(self, x):
if self.use_flash_attn:
qkv = self.qkv(x)
qkv = rearrange(qkv, "B N (x h d) -> B N x h d", x=3, h=self.num_heads).contiguous()
x = flash_attn_qkvpacked_func(qkv)
x = rearrange(x, "B N h d -> B N (h d)").contiguous()
x = self.proj(x)
elif self.use_xformers:
qkv = self.qkv(x)
qkv = rearrange(qkv, "B N (x h d) -> x B N h d", x=3, h=self.num_heads).contiguous()
q, k, v = qkv[0], qkv[1], qkv[2]
x = xops.memory_efficient_attention(q, k, v) # B N h d
x = rearrange(x, "B N h d -> B N (h d)").contiguous()
x = self.proj(x)
elif self.use_torchfunc:
qkv = self.qkv(x)
qkv = rearrange(qkv, "B N (x h d) -> x B h N d", x=3, h=self.num_heads).contiguous()
q, k, v = qkv[0], qkv[1], qkv[2]
x = F.scaled_dot_product_attention(q, k, v) # B N h d
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj(x)
else:
qkv = self.qkv(x)
qkv = rearrange(qkv, "B N (x h d) -> x B h N d", x=3, h=self.num_heads).contiguous()
q, k, v = qkv[0], qkv[1], qkv[2]
x = scaled_dot_product_attention(q, k, v) # B N h d
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj(x)
# with torch.no_grad():
# attn = (q @ k.transpose(-2, -1)) * self.scale
# attn_map = attn.softmax(dim=-1)
# # print("Standard:", attn_map)
return x
class DualCrossAttention(nn.Module):
def __init__(
self,
dim,
num_heads,
scale = None,
bias = False,
attn_drop=0.0,
proj_drop=0.0,
**kwargs,
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} not divisible by num_heads {num_heads}"
self.num_heads = num_heads
self.scale = scale or dim**(-0.5)
self.use_flash_attn = has_flash_attn
self.use_xformers = has_xformers and (dim // num_heads) % 32 == 0
self.use_torchfunc = has_torchfunc
self.qkv1 = nn.Linear(dim, 3 * dim)
self.qkv2 = nn.Linear(dim, 3 * dim)
self.attn_drop = nn.Dropout(attn_drop)
self.proj_x = nn.Linear(dim, dim)
self.proj_c = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_viz = nn.Identity()
# @get_local('attn_map')
def forward(self, x, c):
B, N, C = x.shape
B, M, _ = c.shape
scale_x = math.log(M, N) * self.scale
scale_c = math.log(N, N) * self.scale
if self.use_flash_attn:
qkv1 = self.qkv1(x)
qkv1 = rearrange(qkv1, "B N (x h d) -> B N x h d", x=3, h=self.num_heads).contiguous()
qkv2 = self.qkv2(c)
qkv2 = rearrange(qkv2, "B M (x h d) -> B M x h d", x=3, h=self.num_heads).contiguous()
q1, kv1 = qkv1[:,:,0], qkv1[:,:,1:]
q2, kv2 = qkv2[:,:,0], qkv2[:,:,1:]
x = flash_attn_kvpacked_func(q1, kv2, softmax_scale=scale_x)
x = rearrange(x, "B N h d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = flash_attn_kvpacked_func(q2, kv1, softmax_scale=scale_c)
c = rearrange(c, "B M h d -> B M (h d)").contiguous()
c = self.proj_c(c)
elif self.use_xformers:
qkv1 = self.qkv1(x)
qkv1 = rearrange(qkv1, "B N (x h d) -> x B N h d", x=3, h=self.num_heads).contiguous()
qkv2 = self.qkv2(c)
qkv2 = rearrange(qkv2, "B M (x h d) -> x B M h d", x=3, h=self.num_heads).contiguous()
q1, k1, v1 = qkv1[0], qkv1[1], qkv1[2]
q2, k2, v2 = qkv2[0], qkv2[1], qkv2[2]
x = xops.memory_efficient_attention(q1, k2, v2, scale=scale_x) # B N h d
x = rearrange(x, "B N h d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = xops.memory_efficient_attention(q2, k1, v1, scale=scale_c) # B N h d
c = rearrange(c, "B M h d -> B M (h d)").contiguous()
c = self.proj_c(c)
elif self.use_torchfunc:
qkv1 = self.qkv1(x)
qkv1 = rearrange(qkv1, "B N (x h d) -> x B h N d", x=3, h=self.num_heads).contiguous()
qkv2 = self.qkv2(c)
qkv2 = rearrange(qkv2, "B M (x h d) -> x B h M d", x=3, h=self.num_heads).contiguous()
q1, k1, v1 = qkv1[0], qkv1[1], qkv1[2]
q2, k2, v2 = qkv2[0], qkv2[1], qkv2[2]
x = F.scaled_dot_product_attention(q1, k2, v2) # B N h d
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = F.scaled_dot_product_attention(q2, k1, v1) # B N h d
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj_c(c)
else:
qkv1 = self.qkv1(x)
qkv1 = rearrange(qkv1, "B N (x h d) -> x B h N d", x=3, h=self.num_heads).contiguous()
qkv2 = self.qkv2(c)
qkv2 = rearrange(qkv2, "B M (x h d) -> x B h M d", x=3, h=self.num_heads).contiguous()
q1, k1, v1 = qkv1[0], qkv1[1], qkv1[2]
q2, k2, v2 = qkv2[0], qkv2[1], qkv2[2]
x = scaled_dot_product_attention(q1, k2, v2, scale=scale_x) # B N h d
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = scaled_dot_product_attention(q2, k1, v1, scale=scale_c) # B N h d
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj_c(c)
# with torch.no_grad():
# # q1 = rearrange(q1, "B h M d -> B M (h d)").contiguous()
# # k2 = rearrange(k2, "B h M d -> B M (h d)").contiguous()
# attn = (q1 @ k2.transpose(-2, -1)) * scale_x
# attn_map = attn.softmax(dim=-1)
# # print("Mix:", attn_map)
return x, c
class DualCrossAttention_v2(nn.Module):
def __init__(
self,
dim,
num_heads,
scale = None,
bias = False,
attn_drop=0.0,
proj_drop=0.0,
**kwargs,
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} not divisible by num_heads {num_heads}"
self.num_heads = num_heads
self.scale = scale or dim**(-0.5)
self.use_flash_attn = has_flash_attn
self.use_xformers = has_xformers and (dim // num_heads) % 32 == 0
self.use_torchfunc = has_torchfunc
self.qv1 = nn.Linear(dim, 2 * dim)
self.kv2 = nn.Linear(dim, 2 * dim)
self.attn_drop = nn.Dropout(attn_drop)
self.proj_x = nn.Linear(dim, dim)
self.proj_c = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_viz = nn.Identity()
def forward(self, x, c):
B, N, C = x.shape
B, M, _ = c.shape
scale_x = math.log(M, N) * self.scale
scale_c = math.log(N, N) * self.scale
if self.use_flash_attn:
qv1 = self.qv1(x)
qv1 = rearrange(qv1, "B N (x h d) -> B N x h d", x=2, h=self.num_heads).contiguous()
kv2 = self.kv2(c)
kv2 = rearrange(kv2, "B M (x h d) -> B M x h d", x=2, h=self.num_heads).contiguous()
q, v1 = qv1[:,:,0], qv1[:,:,1]
k, v2 = kv2[:,:,0], kv2[:,:,1]
x = flash_attn_func(q, k, v2, softmax_scale=scale_x)
x = rearrange(x, "B N h d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = flash_attn_func(k, q, v1, softmax_scale=scale_c)
c = rearrange(c, "B M h d -> B M (h d)").contiguous()
c = self.proj_c(c)
elif self.use_xformers:
qv1 = self.qv1(x)
qv1 = rearrange(qv1, "B N (x h d) -> x B h N d", x=2, h=self.num_heads).contiguous()
kv2 = self.kv2(c)
kv2 = rearrange(kv2, "B M (x h d) -> x B h M d", x=2, h=self.num_heads).contiguous()
q, v1 = qv1[0], qv1[1]
k, v2 = kv2[0], kv2[1]
x = xops.memory_efficient_attention(q, k, v2, scale=scale_x)
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = xops.memory_efficient_attention(k, q, v1, scale=scale_c)
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj_c(c)
elif self.use_torchfunc:
qv1 = self.qv1(x)
qv1 = rearrange(qv1, "B N (x h d) -> x B h N d", x=2, h=self.num_heads).contiguous()
kv2 = self.kv2(c)
kv2 = rearrange(kv2, "B M (x h d) -> x B h M d", x=2, h=self.num_heads).contiguous()
q, v1 = qv1[0], qv1[1]
k, v2 = kv2[0], kv2[1]
x = F.scaled_dot_product_attention(q, k, v2)
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = F.scaled_dot_product_attention(k, q, v1)
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj_c(c)
else:
qv1 = self.qv1(x)
qv1 = rearrange(qv1, "B N (x h d) -> x B h N d", x=2, h=self.num_heads).contiguous()
kv2 = self.kv2(c)
kv2 = rearrange(kv2, "B M (x h d) -> x B h M d", x=2, h=self.num_heads).contiguous()
q, v1 = qv1[0], qv1[1]
k, v2 = kv2[0], kv2[1]
x = scaled_dot_product_attention(q, k, v2)
x = rearrange(x, "B h N d -> B N (h d)").contiguous()
x = self.proj_x(x)
c = scaled_dot_product_attention(k, q, v1)
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj_c(c)
return x, c
class CrossAttention(nn.Module):
def __init__(
self,
dim,
num_heads,
scale = None,
bias = False,
attn_drop=0.0,
proj_drop=0.0,
**kwargs,
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} not divisible by num_heads {num_heads}"
self.num_heads = num_heads
self.use_flash_attn = has_flash_attn
self.use_xformers = has_xformers and (dim // num_heads) % 32 == 0
self.use_torchfunc = has_torchfunc
self.q = nn.Linear(dim, dim)
self.kv = nn.Linear(dim, 2 * dim)
self.attn_drop = attn_drop
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_viz = nn.Identity()
def forward(self, x, c):
B, N, C = x.shape
B, M, _ = c.shape
if self.use_flash_attn:
q = self.q(c)
kv = self.kv(x)
q = rearrange(q, "B M (h d) -> B M h d", h=self.num_heads).contiguous()
kv = rearrange(kv, "B N (x h d) -> B N x h d", x=2, h=self.num_heads).contiguous()
c = flash_attn_kvpacked_func(q, kv)
c = rearrange(c, "B M h d -> B M (h d)").contiguous()
c = self.proj(c)
elif self.use_xformers:
q = self.q(c)
kv = self.kv(x)
q = rearrange(q, "B M (h d) -> B M h d", h=self.num_heads).contiguous()
kv = rearrange(kv, "B N (x h d) -> x B N h d", x=2, h=self.num_heads).contiguous()
k, v = kv[0], kv[1]
c = xops.memory_efficient_attention(q, k, v)
c = rearrange(c, "B M h d -> B M (h d)").contiguous()
c = self.proj(c)
elif self.use_torchfunc:
q = self.q(c)
kv = self.kv(x)
q = rearrange(q, "B M (h d) -> B h M d", h=self.num_heads).contiguous()
kv = rearrange(kv, "B N (x h d) -> x B h N d", x=2, h=self.num_heads).contiguous()
k, v = kv[0], kv[1]
c = F.scaled_dot_product_attention(q, k, v)
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj(c)
else:
q = self.q(c)
kv = self.kv(x)
q = rearrange(q, "B M (h d) -> B h M d", h=self.num_heads).contiguous()
kv = rearrange(kv, "B N (x h d) -> x B h N d", x=2, h=self.num_heads).contiguous()
k, v = kv[0], kv[1]
c = scaled_dot_product_attention(q, k, v)
c = rearrange(c, "B h M d -> B M (h d)").contiguous()
c = self.proj(c)
return c
class LeMeBlock(nn.Module):
def __init__(self, dim,
attn_drop, proj_drop, drop_path=0., attn_type=None,
layer_scale_init_value=-1, num_heads=8, qk_dim=None, mlp_ratio=4, mlp_dwconv=False,
cpe_ks=3, pre_norm=True):
super().__init__()
qk_dim = qk_dim or dim
# modules
if cpe_ks > 0:
self.pos_embed = nn.Conv2d(dim, dim, kernel_size=cpe_ks, padding=1, groups=dim)
else:
self.pos_embed = lambda x: 0
self.norm1 = nn.LayerNorm(dim, eps=1e-6) # important to avoid attention collapsing
self.attn_type = attn_type
if attn_type == "D":
self.attn = DualCrossAttention(dim=dim, num_heads=num_heads, attn_drop=attn_drop, proj_drop=proj_drop)
elif attn_type == "D2":
self.attn = DualCrossAttention_v2(dim=dim, num_heads=num_heads, attn_drop=attn_drop, proj_drop=proj_drop)
elif attn_type == "S" or attn_type == None:
self.attn = StandardAttention(dim=dim, num_heads=num_heads, attn_drop=attn_drop, proj_drop=proj_drop)
elif attn_type == "C":
self.attn = CrossAttention(dim=dim, num_heads=num_heads, attn_drop=attn_drop, proj_drop=proj_drop)
self.norm2 = nn.LayerNorm(dim, eps=1e-6)
self.mlp = nn.Sequential(nn.Linear(dim, int(mlp_ratio*dim)),
DWConv(int(mlp_ratio*dim)) if mlp_dwconv else nn.Identity(),
nn.GELU(),
nn.Linear(int(mlp_ratio*dim), dim)
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# tricks: layer scale & pre_norm/post_norm
if layer_scale_init_value > 0:
self.use_layer_scale = True
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones((1,1,dim)), requires_grad=True)
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((1,1,dim)), requires_grad=True)
else:
self.use_layer_scale = False
self.pre_norm = pre_norm
def forward_with_xc(self, x, c):
_, C, H, W = x.shape
# conv pos embedding
x = x + self.pos_embed(x)
# permute to NHWC tensor for attention & mlp
x = rearrange(x, "N C H W -> N (H W) C")
# x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
# attention & mlp
if self.pre_norm:
if self.use_layer_scale:
_x, _c = self.attn(self.norm1(x), self.norm1(c))
x = x + self.drop_path(self.gamma1 * _x) # (N, H, W, C)
x = x + self.drop_path(self.gamma2 * self.mlp(self.norm2(x))) # (N, H, W, C)
c = c + self.drop_path(self.gamma1 * _c) # (N, H, W, C)
c = c + self.drop_path(self.gamma2 * self.mlp(self.norm2(c))) # (N, H, W, C)
else:
_x, _c = self.attn(self.norm1(x), self.norm1(c))
x = x + self.drop_path(_x) # (N, H, W, C)
x = x + self.drop_path(self.mlp(self.norm2(x))) # (N, H, W, C)
c = c + self.drop_path(_c) # (N, H, W, C)
c = c + self.drop_path(self.mlp(self.norm2(c))) # (N, H, W, C)
else: # https://kexue.fm/archives/9009
if self.use_layer_scale:
_x, _c = self.attn(x,c)
x = self.norm1(x + self.drop_path(self.gamma1 * _x)) # (N, H, W, C)
x = self.norm2(x + self.drop_path(self.gamma2 * self.mlp(x))) # (N, H, W, C)
c = self.norm1(c + self.drop_path(self.gamma1 * _c)) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.gamma2 * self.mlp(c))) # (N, H, W, C)
else:
_x, _c = self.attn(x,c)
x = self.norm1(x + self.drop_path(_x)) # (N, H, W, C)
x = self.norm2(x + self.drop_path(self.mlp(x))) # (N, H, W, C)
c = self.norm1(c + self.drop_path(_c)) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.mlp(c))) # (N, H, W, C)
x = rearrange(x, "N (H W) C -> N C H W",H=H,W=W)
# permute back
# x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
return x, c
def forward_with_c(self, x, c):
_, C, H, W = x.shape
_x = x
# conv pos embedding
x = x + self.pos_embed(x)
# permute to NHWC tensor for attention & mlp
x = rearrange(x, "N C H W -> N (H W) C")
# x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
# attention & mlp
if self.pre_norm:
if self.use_layer_scale:
c = c + self.drop_path(self.gamma1 * self.attn(self.norm1(x), self.norm1(c))) # (N, H, W, C)
c = c + self.drop_path(self.gamma2 * self.mlp(self.norm2(c))) # (N, H, W, C)
else:
c = c + self.drop_path(self.attn(self.norm1(x),self.norm1(c))) # (N, H, W, C)
c = c + self.drop_path(self.mlp(self.norm2(c))) # (N, H, W, C)
else: # https://kexue.fm/archives/9009
if self.use_layer_scale:
c = self.norm1(c + self.drop_path(self.gamma1 * self.attn(x,c))) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.gamma2 * self.mlp(c))) # (N, H, W, C)
else:
c = self.norm1(c + self.drop_path(self.attn(x,c))) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.mlp(c))) # (N, H, W, C)
x = _x
# permute back
# x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
return x, c
def forward_with_x(self, x, c):
_, C, H, W = x.shape
# conv pos embedding
x = x + self.pos_embed(x)
# permute to NHWC tensor for attention & mlp
x = rearrange(x, "N C H W -> N (H W) C")
# x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
# attention & mlp
if self.pre_norm:
if self.use_layer_scale:
x = x + self.drop_path(self.gamma1 * self.attn(self.norm1(x))) # (N, H, W, C)
x = x + self.drop_path(self.gamma2 * self.mlp(self.norm2(x))) # (N, H, W, C)
c = c + self.drop_path(self.gamma1 * self.attn(self.norm1(c))) # (N, H, W, C)
c = c + self.drop_path(self.gamma2 * self.mlp(self.norm2(c))) # (N, H, W, C)
else:
x = x + self.drop_path(self.attn(self.norm1(x))) # (N, H, W, C)
x = x + self.drop_path(self.mlp(self.norm2(x))) # (N, H, W, C)
c = c + self.drop_path(self.attn(self.norm1(c))) # (N, H, W, C)
c = c + self.drop_path(self.mlp(self.norm2(c))) # (N, H, W, C)
else: # https://kexue.fm/archives/9009
if self.use_layer_scale:
x = self.norm1(x + self.drop_path(self.gamma1 * self.attn(x))) # (N, H, W, C)
x = self.norm2(x + self.drop_path(self.gamma2 * self.mlp(x))) # (N, H, W, C)
c = self.norm1(c + self.drop_path(self.gamma1 * self.attn(c))) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.gamma2 * self.mlp(c))) # (N, H, W, C)
else:
x = self.norm1(x + self.drop_path(self.attn(x))) # (N, H, W, C)
x = self.norm2(x + self.drop_path(self.mlp(x))) # (N, H, W, C)
c = self.norm1(c + self.drop_path(self.attn(c))) # (N, H, W, C)
c = self.norm2(c + self.drop_path(self.mlp(c))) # (N, H, W, C)
x = rearrange(x, "N (H W) C -> N C H W",H=H,W=W)
# permute back
# x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
return x, c
def forward(self, x, c):
if self.attn_type == "D" or self.attn_type == "D2":
return self.forward_with_xc(x,c)
elif self.attn_type == "S":
return self.forward_with_x(x,c)
elif self.attn_type == "C":
return self.forward_with_c(x,c)
else:
raise NotImplementedError("Attention type does not exit")
class LeMeViT(nn.Module):
def __init__(self,
depth=[2, 3, 4, 8, 3],
in_chans=3,
num_classes=1000,
embed_dim=[64, 64, 128, 320, 512],
head_dim=64,
mlp_ratios=[4, 4, 4, 4, 4],
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop=0.,
drop_path_rate=0.,
# <<<------
attn_type=["C","D","D","S","S"],
queries_len=128,
qk_dims=None,
cpe_ks=3,
pre_norm=True,
mlp_dwconv=False,
representation_size=None,
layer_scale_init_value=-1,
use_checkpoint_stages=[],
# ------>>>
):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
qk_dims = qk_dims or embed_dim
self.num_stages = len(attn_type)
############ downsample layers (patch embeddings) ######################
self.downsample_layers = nn.ModuleList()
# NOTE: uniformer uses two 3*3 conv, while in many other transformers this is one 7*7 conv
stem = nn.Sequential(
nn.Conv2d(in_chans, embed_dim[0] // 2, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[0] // 2),
nn.GELU(),
nn.Conv2d(embed_dim[0] // 2, embed_dim[0], kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[0]),
)
if use_checkpoint_stages:
stem = checkpoint_wrapper(stem)
self.downsample_layers.append(stem)
for i in range(self.num_stages-1):
if attn_type[i] == "C":
downsample_layer = nn.Identity()
else:
downsample_layer = nn.Sequential(
nn.Conv2d(embed_dim[i], embed_dim[i+1], kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(embed_dim[i+1])
)
if use_checkpoint_stages:
downsample_layer = checkpoint_wrapper(downsample_layer)
self.downsample_layers.append(downsample_layer)
##########################################################################
#TODO: maybe remove last LN
self.queries_len = queries_len
self.meta_tokens = nn.Parameter(torch.randn(self.queries_len ,embed_dim[0]), requires_grad=True)
self.meta_token_downsample = nn.ModuleList()
meta_token_downsample = nn.Sequential(
nn.Linear(embed_dim[0], embed_dim[0] * 4),
nn.LayerNorm(embed_dim[0] * 4),
nn.GELU(),
nn.Linear(embed_dim[0] * 4, embed_dim[0]),
nn.LayerNorm(embed_dim[0])
)
self.meta_token_downsample.append(meta_token_downsample)
for i in range(self.num_stages-1):
meta_token_downsample = nn.Sequential(
nn.Linear(embed_dim[i], embed_dim[i] * 4),
nn.LayerNorm(embed_dim[i] * 4),
nn.GELU(),
nn.Linear(embed_dim[i] * 4, embed_dim[i+1]),
nn.LayerNorm(embed_dim[i+1])
)
self.meta_token_downsample.append(meta_token_downsample)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
nheads= [dim // head_dim for dim in qk_dims]
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))]
cur = 0
for i in range(self.num_stages):
stage = nn.ModuleList(
[LeMeBlock(dim=embed_dim[i],
attn_drop=attn_drop, proj_drop=drop_rate,
drop_path=dp_rates[cur + j],
attn_type=attn_type[i],
layer_scale_init_value=layer_scale_init_value,
num_heads=nheads[i],
qk_dim=qk_dims[i],
mlp_ratio=mlp_ratios[i],
mlp_dwconv=mlp_dwconv,
cpe_ks=cpe_ks,
pre_norm=pre_norm
) for j in range(depth[i])],
)
if i in use_checkpoint_stages:
stage = checkpoint_wrapper(stage)
self.stages.append(stage)
cur += depth[i]
##########################################################################
self.norm = nn.BatchNorm2d(embed_dim[-1])
self.norm_c = nn.LayerNorm(embed_dim[-1])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x, c):
for i in range(self.num_stages):
x = self.downsample_layers[i](x)
c = self.meta_token_downsample[i](c)
for j, block in enumerate(self.stages[i]):
x, c = block(x, c)
x = self.norm(x)
x = self.pre_logits(x)
c = self.norm_c(c)
c = self.pre_logits(c)
# x = x.flatten(2).mean(-1,keepdim=True)
# c = c.transpose(-2,-1).contiguous().mean(-1,keepdim=True)
# x = torch.concat([x,c],dim=-1).mean(-1)
x = x.flatten(2).mean(-1)
c = c.transpose(-2,-1).contiguous().mean(-1)
x = x + c
return x
def forward(self, x):
B, _, H, W = x.shape
c = self.meta_tokens.repeat(B,1,1)
x = self.forward_features(x, c)
x = self.head(x)
return x同时,在整体架构的基础上,作者设计了三种不同大小的模型,即 Tiny、Small 和 Base。通过调整每个阶段的块数和特征的尺寸来定制这些尺寸,其他配置在所有变体之间共享。我们将每个关注的头尺寸设置为 32,MLP 扩展率为 4,条件位置编码核大小为 3。元标记的长度设置为 16。
@register_model
def lemevit_tiny(pretrained=False, pretrained_cfg=None,
pretrained_cfg_overlay=None, **kwargs):
model = LeMeViT(
depth=[1, 2, 2, 8, 2],
embed_dim=[64, 64, 128, 192, 320],
head_dim=32,
mlp_ratios=[4, 4, 4, 4, 4],
attn_type=["C","D","D","S","S"],
queries_len=16,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
qk_dims=None,
cpe_ks=3,
pre_norm=True,
mlp_dwconv=False,
representation_size=None,
layer_scale_init_value=-1,
use_checkpoint_stages=[],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(pretrained, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def lemevit_small(pretrained=False, pretrained_cfg=None,
pretrained_cfg_overlay=None, **kwargs):
model = LeMeViT(
depth=[1, 2, 2, 6, 2],
embed_dim=[96, 96, 192, 320, 384],
head_dim=32,
mlp_ratios=[4, 4, 4, 4, 4],
attn_type=["C","D","D","S","S"],
queries_len=16,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
qk_dims=None,
cpe_ks=3,
pre_norm=True,
mlp_dwconv=False,
representation_size=None,
layer_scale_init_value=-1,
use_checkpoint_stages=[],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(pretrained, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def lemevit_base(pretrained=False, pretrained_cfg=None,
pretrained_cfg_overlay=None, **kwargs):
model = LeMeViT(
depth=[2, 4, 4, 18, 4],
embed_dim=[96, 96, 192, 384, 512],
head_dim=32,
mlp_ratios=[4, 4, 4, 4, 4],
attn_type=["C","D","D","S","S"],
queries_len=16,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
qk_dims=None,
cpe_ks=3,
pre_norm=True,
mlp_dwconv=False,
representation_size=None,
layer_scale_init_value=-1,
use_checkpoint_stages=[],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(pretrained, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model性能测试
现在浅浅试一下模型在图像分类上的表现,我选择其中的tiny和small两个版本。使用自制的葡萄多光条件数据集:包括4个类别和3种光照条件共12种数据集,分成8:1=训练集:测试集。
我的训练代码:
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
from models.lemevit import lemevit_small_v2
from torch.autograd import Variable
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
warnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0,1"
import pandas as pd
from torchvision.transforms import RandAugment
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch,model_ema):
model.train()
loss_meter = AverageMeter()
acc1_meter = AverageMeter()
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), Variable(target).to(device,non_blocking=True)
samples, targets = mixup_fn(data, target)
output = model(data)
optimizer.zero_grad()
if use_amp:
with torch.cuda.amp.autocast():
loss = torch.nan_to_num(criterion_train(output, targets))
scaler.scale(loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)
scaler.step(optimizer)
scaler.update()
else:
loss = criterion_train(output, targets)
loss.backward()
optimizer.step()
if model_ema is not None:
model_ema.update(model)
torch.cuda.synchronize()
lr = optimizer.state_dict()['param_groups'][0]['lr']
loss_meter.update(loss.item(), target.size(0))
acc1, acc5 = accuracy(output, target, topk=(1, 5))
loss_meter.update(loss.item(), target.size(0))
acc1_meter.update(acc1.item(), target.size(0))
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))
ave_loss =loss_meter.avg
acc = acc1_meter.avg
print('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))
return ave_loss, acc
# 验证过程
@torch.no_grad()
def val(model, device, test_loader):
global Best_ACC
model.eval()
loss_meter = AverageMeter()
acc1_meter = AverageMeter()
acc5_meter = AverageMeter()
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
val_list = []
pred_list = []
for data, target in test_loader:
for t in target:
val_list.append(t.data.item())
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
output = model(data)
loss = criterion_val(output, target)
_, pred = torch.max(output.data, 1)
for p in pred:
pred_list.append(p.data.item())
acc1, acc5 = accuracy(output, target, topk=(1, 5))
loss_meter.update(loss.item(), target.size(0))
acc1_meter.update(acc1.item(), target.size(0))
acc5_meter.update(acc5.item(), target.size(0))
acc = acc1_meter.avg
print('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\tAcc5:{:.3f}%\n'.format(
loss_meter.avg, acc, acc5_meter.avg))
if acc > Best_ACC:
if isinstance(model, torch.nn.DataParallel):
torch.save(model.module, file_dir + '/' + 'best.pth')
else:
torch.save(model, file_dir + '/' + 'best.pth')
Best_ACC = acc
if isinstance(model, torch.nn.DataParallel):
state = {
'epoch': epoch,
'state_dict': model.module.state_dict(),
'Best_ACC': Best_ACC
}
if use_ema:
state['state_dict_ema'] = model.module.state_dict()
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')
else:
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'Best_ACC': Best_ACC
}
if use_ema:
state['state_dict_ema'] = model.state_dict()
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')
return val_list, pred_list, loss_meter.avg, acc
def seed_everything(seed=0):
os.environ['PYHTONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
file_dir = 'checkpoints/LEMEVIT-small/'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir,exist_ok=True)
else:
os.makedirs(file_dir)
model_lr = 1e-3
BATCH_SIZE = 16
EPOCHS = 50
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
use_amp =True
use_dp = True
classes = 4
resume =None
CLIP_GRAD = 5.0
Best_ACC = 0
use_ema=False
model_ema_decay=0.9995
start_epoch=1
seed=1
seed_everything(seed)
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std= [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std= [0.5, 0.5, 0.5])
])
mixup_fn = Mixup(
mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,
prob=0.1, switch_prob=0.5, mode='batch',
label_smoothing=0.1, num_classes=classes)
dataset_train = datasets.ImageFolder('dataset/train', transform=transform)
dataset_test = datasets.ImageFolder("dataset/val", transform=transform_test)
with open('class.txt', 'w') as file:
file.write(str(dataset_train.class_to_idx))
with open('class.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(dataset_train.class_to_idx))
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
criterion_train = SoftTargetCrossEntropy()
criterion_val = torch.nn.CrossEntropyLoss()
model_ft = lemevit_small_v2(pretrained=False)
num_fr=model_ft.head.in_features
model_ft.head =nn.Linear(num_fr,classes)
print(model_ft)
if resume:
model=torch.load(resume)
print(model['state_dict'].keys())
model_ft.load_state_dict(model['state_dict'],strict = False)
Best_ACC=model['Best_ACC']
start_epoch=model['epoch']+1
model_ft.to(DEVICE)
optimizer = optim.AdamW(model_ft.parameters(),lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=40, eta_min=5e-8)
if use_amp:
scaler = torch.cuda.amp.GradScaler()
if torch.cuda.device_count() > 1 and use_dp:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model_ft = torch.nn.DataParallel(model_ft)
if use_ema:
model_ema = ModelEma(
model_ft,
decay=model_ema_decay,
device=DEVICE,
resume=resume)
else:
model_ema=None
# 训练与验证
is_set_lr = False
log_dir = {}
train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []
epoch_info = []
if resume and os.path.isfile(file_dir+"result.json"):
with open(file_dir+'result.json', 'r', encoding='utf-8') as file:
logs = json.load(file)
train_acc_list = logs['train_acc']
train_loss_list = logs['train_loss']
val_acc_list = logs['val_acc']
val_loss_list = logs['val_loss']
epoch_list = logs['epoch_list']
for epoch in range(start_epoch, EPOCHS + 1):
epoch_list.append(epoch)
log_dir['epoch_list'] = epoch_list
train_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch,model_ema)
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
log_dir['train_acc'] = train_acc_list
log_dir['train_loss'] = train_loss_list
if use_ema:
val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)
else:
val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
log_dir['val_acc'] = val_acc_list
log_dir['val_loss'] = val_loss_list
log_dir['best_acc'] = Best_ACC
with open(file_dir + '/result.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(log_dir))
print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))
epoch_info.append({
'epoch': epoch,
'train_loss': train_loss,
'train_acc': train_acc,
'val_loss': val_loss,
'val_acc': val_acc
})
df = pd.DataFrame(epoch_info)
df.to_excel(file_dir + "/epoch_info.xlsx",index=False)
with open('epoch_info.txt', 'w') as f:
for epoch_data in epoch_info:
f.write(f"Epoch: {epoch_data['epoch']}\n")
f.write(f"Train Loss: {epoch_data['train_loss']}\n")
f.write(f"Train Acc: {epoch_data['train_acc']}\n")
f.write(f"Val Loss: {epoch_data['val_loss']}\n")
f.write(f"Val Acc: {epoch_data['val_acc']}\n")
f.write("\n")
if epoch < 600:
cosine_schedule.step()
else:
if not is_set_lr:
for param_group in optimizer.param_groups:
param_group["lr"] = 1e-6
is_set_lr = True
fig = plt.figure(1)
plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')
# 显示图例
plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')
plt.legend(["Train Loss", "Val Loss"], loc="upper right")
plt.xlabel(u'epoch')
plt.ylabel(u'loss')
plt.title('Model Loss ')
plt.savefig(file_dir + "/loss.png")
plt.close(1)
fig2 = plt.figure(2)
plt.plot(epoch_list, train_acc_list, 'g-', label=u'Train Acc')
plt.plot(epoch_list, val_acc_list, 'y-', label=u'Val Acc')
plt.legend(["Train Acc", "Val Acc"], loc="lower right")
plt.title("Model Acc")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.savefig(file_dir + "/acc.png")
plt.close(2)
测试代码:
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from PIL import Image
import numpy as np
from sklearn.metrics import recall_score, precision_score, f1_score, accuracy_score
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义自定义数据集
class CustomDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.classes = sorted(os.listdir(root_dir))
self.image_paths = []
self.labels = []
for idx, class_name in enumerate(self.classes):
class_dir = os.path.join(root_dir, class_name)
for img_name in os.listdir(class_dir):
img_path = os.path.join(class_dir, img_name)
self.image_paths.append(img_path)
self.labels.append(idx)
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# 图像转换
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 加载数据集
dataset_root = 'dataset/sunlight'
dataset = CustomDataset(root_dir=dataset_root, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=False)
# 加载模型
model_path = 'checkpoints/LEMEVIT-small/best.pth'
model = torch.load(model_path)
model.to(device)
model.eval()
# 预测函数
def predict(model, dataloader, device):
all_preds = []
all_labels = []
with torch.no_grad():
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
return np.array(all_preds), np.array(all_labels)
# 获取预测结果
predictions, true_labels = predict(model, dataloader, device)
# 计算各个指标
recall = recall_score(true_labels, predictions, average='macro')
precision = precision_score(true_labels, predictions, average='macro')
f1 = f1_score(true_labels, predictions, average='macro')
accuracy = accuracy_score(true_labels, predictions)
# 获取类别名称
class_names = sorted(os.listdir(dataset_root))
print(f'Class names: {class_names}')
print(f'Recall: {recall:.4f}')
print(f'Precision: {precision:.4f}')
print(f'F1 Score: {f1:.4f}')
print(f'Accuracy: {accuracy:.4f}')
结果如下:

可以看到,根据实验结果,LEMEVIT-tiny和LEMEVIT-small在不同光照条件下的表现差异明显。LEMEVIT-tiny在所有条件下的指标均略高于LEMEVIT-small,尤其在阴影和正常光照下,显示出更稳定的性能。而在阳光下,两个模型的性能均有所下降,但LEMEVIT-tiny依然保持较高的精度和召回率。总体而言,LEMEVIT-tiny在光照变化下具有更优越的适应性和稳定性,表现出更高的鲁棒性。当然本结果只针对我的数据集起作用,各位可以自己去实验。
列出模型的地址:https://github.com/ViTAE-Transformer/LeMeViT
以上为全部内容!