1.流提取>>的优化(利用缓存区的思想)
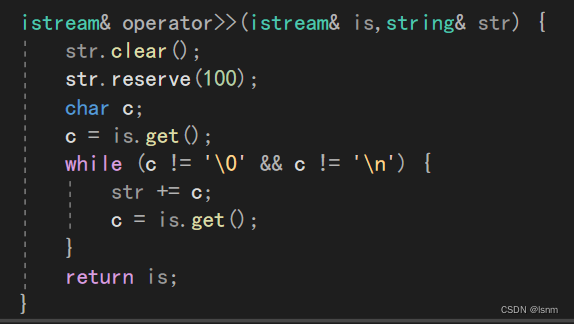
istream& operator>>(istream& is,string& str) {
str.clear();
char c;
c = is.get();
while (c != '\0' && c != '\n') {
str += c;
c = is.get();
}
return is;
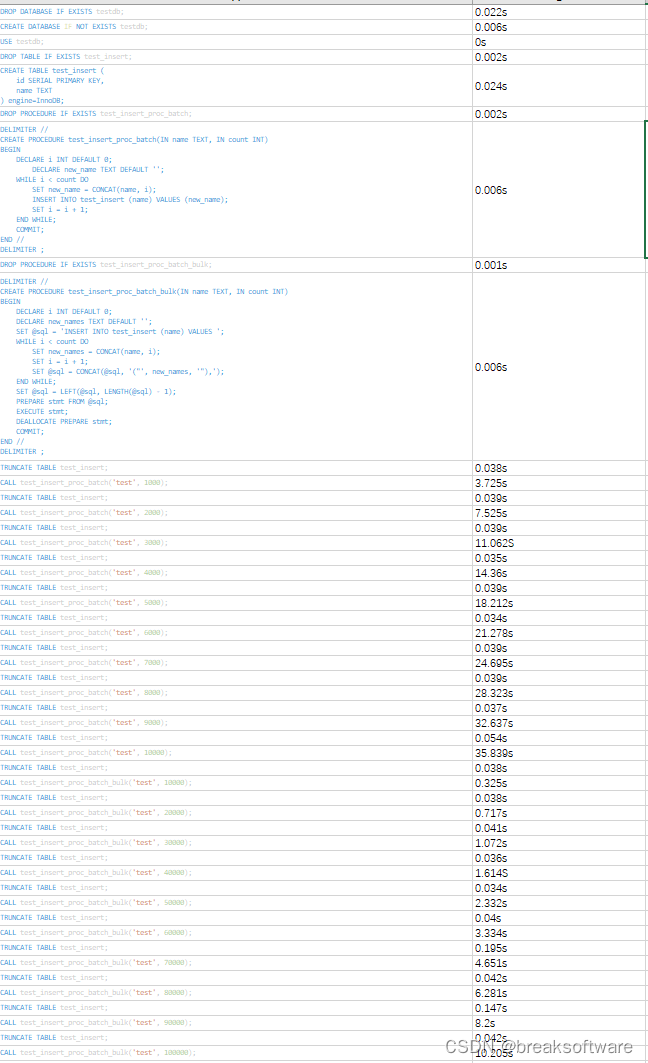
}在上文的对string的实践中,对于>>的重载(如上代码),当我们需要输入很多文字的时候,因为每次都会利用一次push_back(+=的实现是对push_back的复用),扩容相对较频繁。需要经历很多次扩容,开销较大。
解决办法1:通过reserve函数提前对str的空间进行规划
但是这样的reserve只对预计空间在100左右的string凑效。当要输入的字符很多时,依然需要多次扩容。
解决办法2:buff数组(利用缓冲区的思想):
先将输入的内容都放入buff数组中。
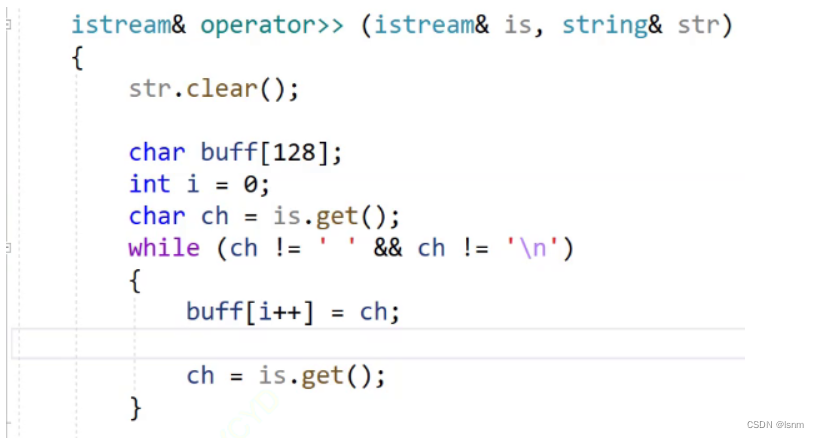
加入并使用一个人为确定大小的buff数组,既避免了频繁扩容,也避免了一次性扩太多造成浪费。每次几乎都不会执行push_back,都是按照需要开的。
这是一种借助缓冲区的思路,每次都将即将输入的单个字符放在缓冲区。在有必要时,将缓冲区的内容一次性全部放进_str中以提升效率。
每当一次输入结束(输入了'\n'或者‘ ’) ,就从buff数组中全部拿出来并且通过append放入_str中,因此只会根据大小扩容一次。
必须有将buff数组的最后一个元素赋\0的操作,因为insert的逻辑是会覆盖掉原数组的\0的。
istream& operator>>(istream& is,string& str) {
str.clear();
char buff[128]; int i = 0;
char c;
c = is.get();
while (c != '\0' && c != '\n') {
buff[i++] = c;
//0 - 126用来放char。由于insert的底层逻辑会覆盖\0,所以我们要在buff的末尾加\0
if (i == 127) {
buff[i] = '\0';
str += buff;
i = 0;
}
//str += c;
c = is.get();
}
if (i != 0) {
buff[i] = '\0';
str += buff;
}2.拷贝构造与赋值运算符的现代写法
对于拷贝构造和赋值运算符重载,还有一种“现代写法”
先复习一下传统写法:
string::string(string& s) {
_str = new char[s._size+1];//留一个位置给\0
strcpy(_str, s._str);
_size = s. _size;
_capacity = s._capacity;
}传统思路基本都是根据传入的string引用开一个相应的空间,然后将_size和_capacity一个一个赋值。
而现代写法的核心思路就是“让别人干活” :
我们使用传入参数s的_str进行构造一个新的字符串tmp。接着将tmp的三项数据拷贝交换给this


当然,在string环境下的现代写法与传统写法没有特别大的优势,这是因为string的字符串的拷贝没有什么代价。

还可以复用之前写的swap。
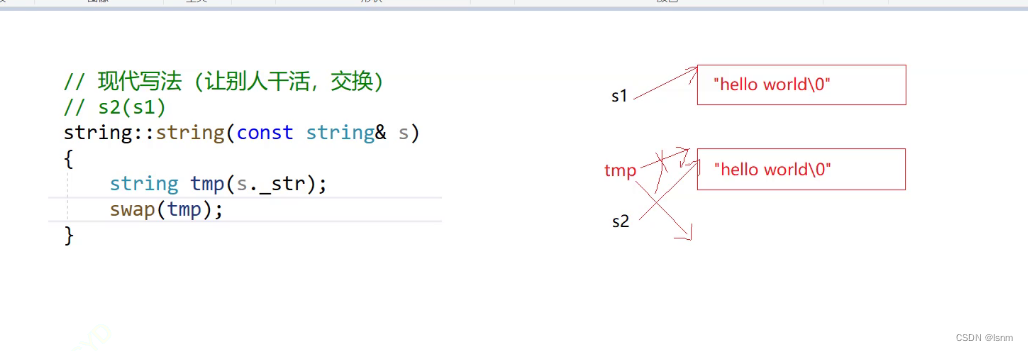
比如上图,要将s1赋值拷贝给s2,也就是先通过构造tmp来获得一份s1的拷贝,然后将这份拷贝的内容交换。其本质是this不能显示调用构造函数。
string::string(string& s) {
string tmp(s._str);
swap(tmp);
}赋值运算符:
同样先观察原来的实现方法:
string& string::operator=(const string& s) {
if (this != &s) {
char* tmp = new char[s._size + 1];//留一个位置给\0
strcpy(tmp,s._str);
_size = s._size;
_capacity = s._capacity;
delete[] _str;
_str = tmp;
tmp = nullptr;
}
return *this;
}依然先通过一个tmp来构造一个与s3一样一样的string,然后通过swap将tmp的内容与s1交换即可。
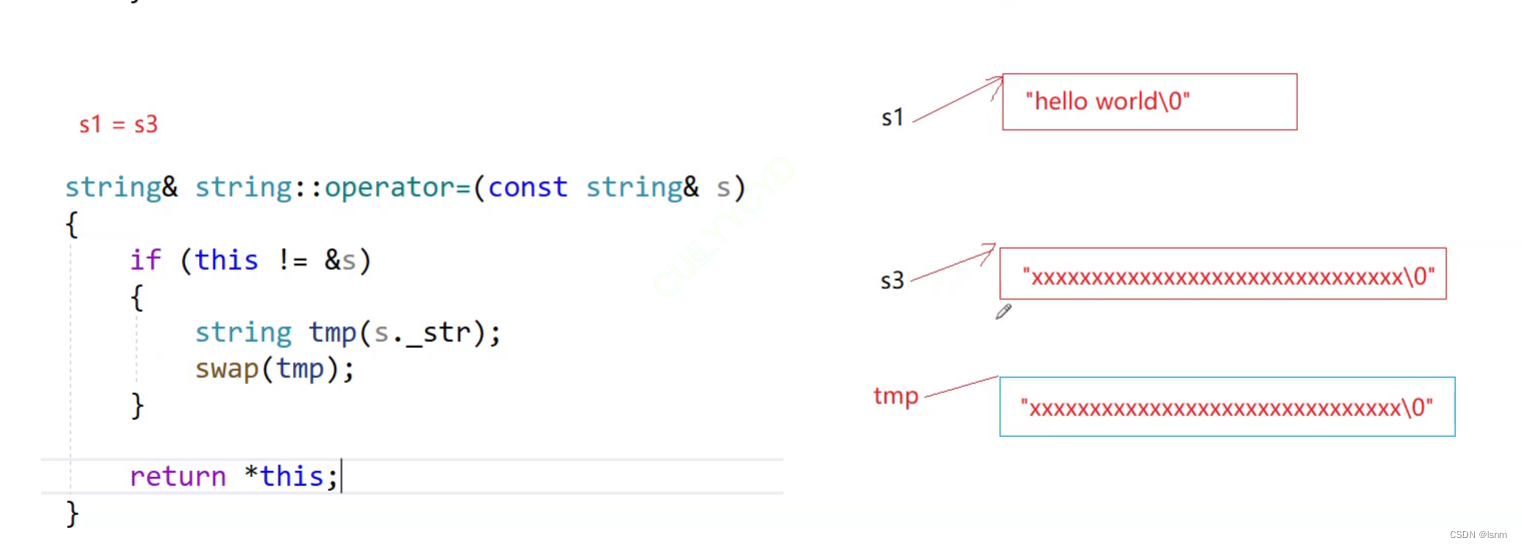
string& string::operator=(const string& s) {
if (this != &s) {
string tmp(s._str);
swap(tmp);
}
return *this;
}
swap的前面没有写作用域,在内部函数没有写前面的作用域就是对this进行该操作。
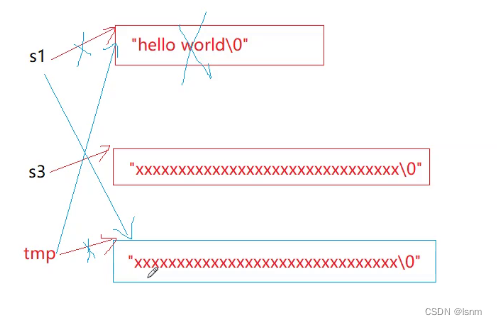
由于tmp是临时变量,并且tmp指向了s1原来指向的"hello world\0",所以在出栈帧之后tmp会被销毁,而销毁又会调用析构函数。所以hello world所在的string就自动无了。
还可以优化成:
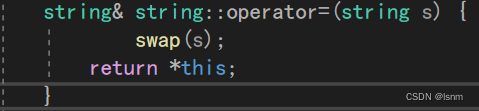
本质是利用传值传参的拷贝,不过这种方法记得改一改头文件中的参数类型。
3.写时拷贝(了解即可)
当我们对对象进行拷贝时不需要对对象进行修改时:
为了避免深拷贝对时间的浪费,我们能不能就利用浅拷贝呢?
目前已知的浅拷贝有两个如下问题:

引用计数解决问题1:引入一个计数的整形变量,每次拷贝时都会将这个整形变量++,每析构一次一次将这个变量-- ; 每次最后一个析构的对象才释放空间,否则只是将对应的使用次数--
写时拷贝解决问题2:如果有需要改变原数组的需求时:还是按照原来的进行拷贝,但是只对“对原对象进行了写入和修改”的对象进行拷贝。因此,所有的写入函数,如:insert append erase push_back等都需要重新加一个函数:
copy_on_write:

而对于copy_on_write的内部:通过对引用计数的判断来决定是否需要深拷贝。

因此,写时拷贝的目的是让不会改变原_str内容的对象共用一个_str,需要改变的还是会进行深拷贝。所以,只要不修改原_str,这样的拷贝方式稳赚不赔。
写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
C++面试中string类的一种正确写法 | 酷 壳 - CoolShell








![[Cloud Networking] Layer Protocol (continue)](https://img-blog.csdnimg.cn/direct/ccfe5144f1184ef29789898162bb7eda.png)