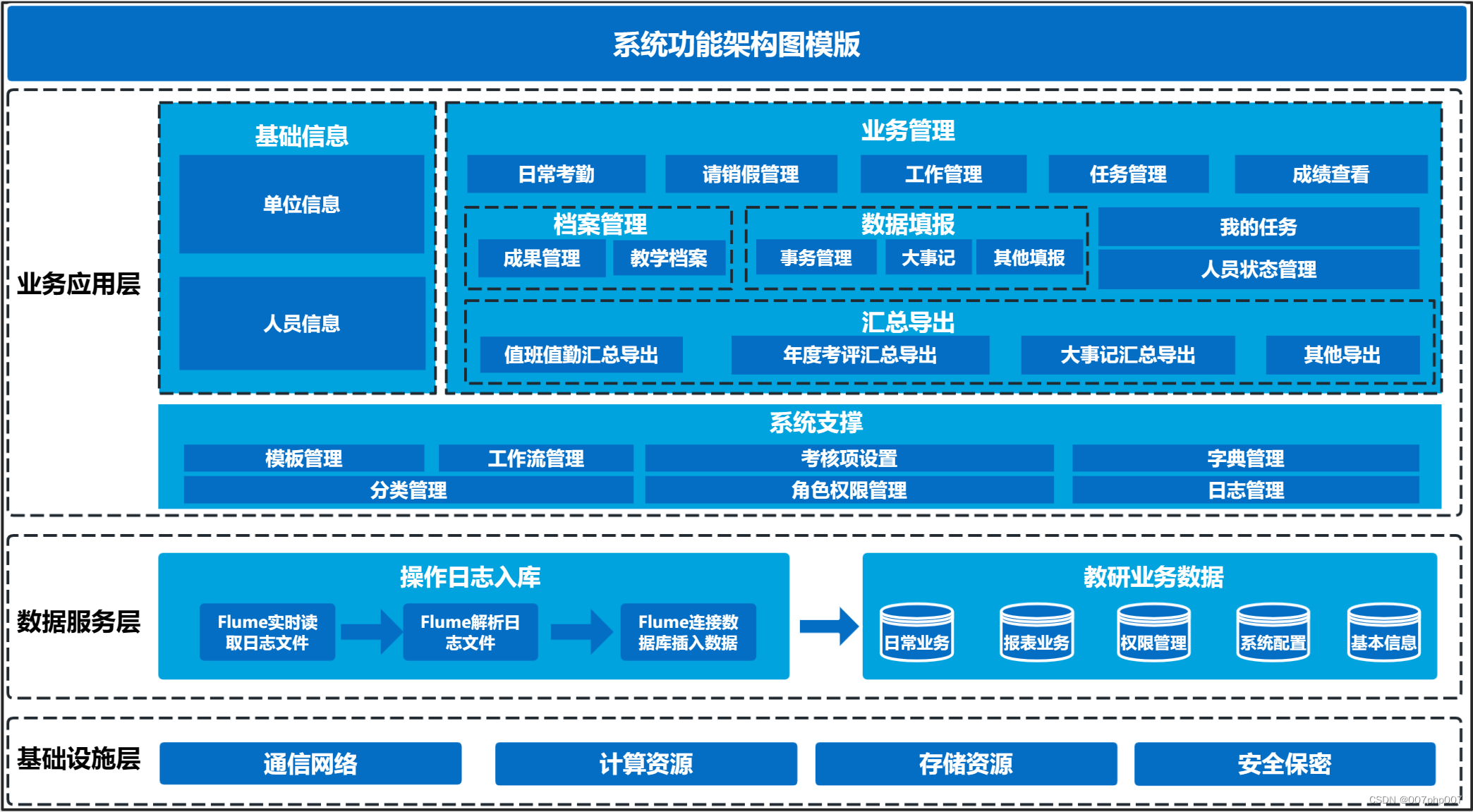
Program Synthesis with CodeGen — ROCm Blogs (amd.com)
CodeGen是基于标准Transformer的自回归语言模型家族,用于程序合成,正如作者所定义的,它是一种利用输入-输出示例或自然语言描述生成解决指定问题的计算机程序的方法。
我们将测试的特定CodeGen模型是在一组包含71.7B个Python编程语言标记的数据上进行微调的。要深入了解CodeGen的内部工作原理,我们建议用户查看Salesforce的这篇论文。
在本文中,我们将使用CodeGen进行几个推理示例,并演示它如何与AMD GPU和ROCm(Radeon Open Compute)无缝兼容地工作。

先决条件
软件:
- ROCm
- PyTorch
- Linux操作系统
对于支持的GPU和操作系统的列表,请参考这个页面。为了方便和稳定性,我们建议在Linux系统中使用以下代码拉取并运行ROCm/PyTorch Docker容器:
docker run -it --ipc=host --network=host --device=/dev/kfd --device=/dev/dri \
--group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--name=olmo rocm/pytorch:rocm6.0_ubuntu20.04_py3.9_pytorch_2.1.1 /bin/bash硬件:
确保系统识别了你的AMD GPU:
! rocm-smi --showproductname================= ROCm System Management Interface ================
========================= Product Info ============================
GPU[0] : Card series: Instinct MI210
GPU[0] : Card model: 0x0c34
GPU[0] : Card vendor: Advanced Micro Devices, Inc. [AMD/ATI]
GPU[0] : Card SKU: D67301
===================================================================
===================== End of ROCm SMI Log =========================接下来,我们检查是否安装了正确版本的ROCm。
!apt show rocm-libs -aPackage: rocm-libs
Version: 5.7.0.50700-63~22.04
Priority: optional
Section: devel
Maintainer: ROCm Libs Support <rocm-libs.support@amd.com>
Installed-Size: 13.3 kB
Depends: hipblas (= 1.1.0.50700-63~22.04), hipblaslt (= 0.3.0.50700-63~22.04), hipfft (= 1.0.12.50700-63~22.04), hipsolver (= 1.8.1.50700-63~22.04), hipsparse (= 2.3.8.50700-63~22.04), miopen-hip (= 2.20.0.50700-63~22.04), rccl (= 2.17.1.50700-63~22.04), rocalution (= 2.1.11.50700-63~22.04), rocblas (= 3.1.0.50700-63~22.04), rocfft (= 1.0.23.50700-63~22.04), rocrand (= 2.10.17.50700-63~22.04), rocsolver (= 3.23.0.50700-63~22.04), rocsparse (= 2.5.4.50700-63~22.04), rocm-core (= 5.7.0.50700-63~22.04), hipblas-dev (= 1.1.0.50700-63~22.04), hipblaslt-dev (= 0.3.0.50700-63~22.04), hipcub-dev (= 2.13.1.50700-63~22.04), hipfft-dev (= 1.0.12.50700-63~22.04), hipsolver-dev (= 1.8.1.50700-63~22.04), hipsparse-dev (= 2.3.8.50700-63~22.04), miopen-hip-dev (= 2.20.0.50700-63~22.04), rccl-dev (= 2.17.1.50700-63~22.04), rocalution-dev (= 2.1.11.50700-63~22.04), rocblas-dev (= 3.1.0.50700-63~22.04), rocfft-dev (= 1.0.23.50700-63~22.04), rocprim-dev (= 2.13.1.50700-63~22.04), rocrand-dev (= 2.10.17.50700-63~22.04), rocsolver-dev (= 3.23.0.50700-63~22.04), rocsparse-dev (= 2.5.4.50700-63~22.04), rocthrust-dev (= 2.18.0.50700-63~22.04), rocwmma-dev (= 1.2.0.50700-63~22.04)
Homepage: https://github.com/RadeonOpenCompute/ROCm
Download-Size: 1012 B
APT-Manual-Installed: yes
APT-Sources: http://repo.radeon.com/rocm/apt/5.7 jammy/main amd64 Packages
Description: Radeon Open Compute (ROCm) Runtime software stack确保PyTorch也识别了GPU:
import torch
print(f"number of GPUs: {torch.cuda.device_count()}")
print([torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])number of GPUs: 1
['AMD Radeon Graphics']现在让我们开始测试CodeGen。

库
在开始之前,请确保您已经安装了所有必要的库:
!pip install transformers接下来,导入您将在本博客中使用的模块:
import torch
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
加载模型
让我们加载模型及其分词器。CodeGen 有几种不同大小的变体,从 350M 到 16.1B 个参数不等。在本博客中,我们将对 350M 参数变体的模型进行推理。
torch.set_default_device("cuda")
start_time = time.time()
checkpoint = "Salesforce/codegen-350M-mono"
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
print(f"Loaded in {time.time() - start_time: .2f} seconds")
print(model)Loaded in 6.89 seconds
CodeGenForCausalLM(
(transformer): CodeGenModel(
(wte): Embedding(51200, 1024)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0-19): 20 x CodeGenBlock(
(ln_1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): CodeGenAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(qkv_proj): Linear(in_features=1024, out_features=3072, bias=False)
(out_proj): Linear(in_features=1024, out_features=1024, bias=False)
)
(mlp): CodeGenMLP(
(fc_in): Linear(in_features=1024, out_features=4096, bias=True)
(fc_out): Linear(in_features=4096, out_features=1024, bias=True)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(ln_f): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=1024, out_features=51200, bias=True)
)
运行推理
让我们创建一个函数,它接受一些输入提示并生成输出。我们还将估算以下两个推理指标:
延迟:模型生成输出所需的总时间
吞吐量:每秒生成的输出标记数
def run_inference(raw_input):
start_time = time.time()
# 注意:这里的 raw_input 应该是 raw_inputs 以保持与函数参数一致
inputs = tokenizer(raw_input, return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=1000)
latency = time.time() - start_time
throughput = len(outputs[0]) / latency
print(f"延迟: {latency: .2f} 秒")
print(f"吞吐量: {throughput: .2f} 标记/秒")
text = tokenizer.batch_decode(outputs)[0]
print(text)有了这个函数,我们就可以运行推理并与CodeGen一起享受乐趣了!我们将测试模型生成代码的能力。

生成代码
让我们给CodeGen一个中等难度的Leetcode问题,看看它的表现如何。
raw_inputs = '''
给定一个整数数组 nums,返回所有满足条件的三元组 [nums[i], nums[j], nums[k]],使得 i != j, i != k, 且 j != k,同时 nums[i] + nums[j] + nums[k] == 0。
注意,解集不能包含重复的三元组。
'''
text = run_inference(raw_inputs)
输出:
延迟: 14.45 秒
吞吐量: 36.12 标记/秒
给定一个整数数组 nums,返回所有满足条件的三元组 [nums[i], nums[j], nums[k]],使得 i != j, i != k, 且 j != k,同时 nums[i] + nums[j] + nums[k] == 0。
注意,解集不能包含重复的三元组。
示例 1:
输入: nums = [-1,0,1,2,-1,-4]
输出: [[-1,-1,2],[-1,0,1]]
解释:
-1 和 -1 是三元组。
-1 和 0 不是三元组。
-1 和 1 不是三元组。
-4 和 -1 不是三元组。
-4 和 -1 是三元组(注意去重)。
-4 和 0 不是三元组。
-4 和 1 是三元组(注意去重)。
-1 和 2 不是三元组。
示例 2:
输入: nums = []
输出: []
示例 3:
输入: nums = [0]
输出: []
约束条件:
1 <= nums.length <= 10^4
-10^4 <= nums[i] <= 10^4
"""
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
res = []
for i in range(len(nums)):
if i > 0 and nums[i] == nums[i-1]:
continue
l, r = i+1, len(nums)-1
while l < r:
if nums[i] + nums[l] + nums[r] == 0:
res.append([nums[i], nums[l], nums[r]])
while l < r and nums[l] == nums[l+1]:
l += 1
while l < r and nums[r] == nums[r-1]:
r -= 1
l += 1
r -= 1
elif nums[i] + nums[l] + nums[r] > 0:
r -= 1
else:
l += 1
return res
<|endoftext|>虽然给出的答案在Leetcode上是正确并被接受的,但我们注意到模型生成的示例中“1 和 -1 是三元组”这一说法并不合适,因为这与题目要求寻找和为特定目标数的两个数不相关。
让我们尝试另一个问题,这次稍微有些变化:
raw_inputs = '''
给定一个已按非递减顺序排序的1-索引整数数组numbers,找出两个数,使它们的和等于一个特定的目标数。设这两个数分别为numbers[index1]和numbers[index2],其中1 <= index1 < index2 <= numbers.length。
返回这两个数的索引index1和index2,索引加1后作为长度为2的整数数组[index1, index2]返回。
测试数据保证只有一个解。你不可以使用同一个元素两次。
你的解决方案必须只使用常数额外空间。
'''
text = run_inference(raw_inputs)
输出:
Latency: 13.03 seconds
Throughput: 41.05 tokens/s
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 <= numbers.length.
Return the indices of the two numbers, index1 and index2, added by one as an integer array [index1, index2] of length 2.
The tests are generated such that there is exactly one solution. You may not use the same element twice.
Your solution must use only constant extra space.
Example 1:
Input: numbers = [2,7,11,15], target = 9
Output: [1,2]
Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
Example 2:
Input: numbers = [2,3,4], target = 6
Output: [1,3]
Explanation: The sum of 2 and 3 is 6. Therefore index1 = 1, index2 = 3.
Example 3:
Input: numbers = [2,3,4], target = 18
Output: [1,3]
Explanation: The sum of 2 and 3 is 6. Therefore index1 = 1, index2 = 3.
Example 4:
Input: numbers = [2,3,4], target = 0
Output: [1,2]
Explanation: The sum of 2 and 0 is 0. Therefore index1 = 1, index2 = 2.
Example 5:
Input: numbers = [2,3,4], target = 10
Output: [1,3]
Explanation: The sum of 2 and 3 is 6. Therefore index1 = 1, index2 = 3.
Constraints:
1 <= numbers.length <= 10^4
-10^9 <= numbers[i] <= 10^9
-10^9 <= target <= 10^9
"""
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
for i in range(len(numbers)):
for j in range(i+1, len(numbers)):
if numbers[i] + numbers[j] == target:
return [i, j]
return []
<|endoftext|>这次给出的答案是不正确的,因为它遗漏了题目中的一个要求,即返回两个数的索引 index1 和 index2,索引值需要加1。
接下来,我们让模型生成一个在训练机器学习模型时常用的损失函数。这次我们不会像前两个例子那样给它太多的限制。
raw_inputs = '''
Implement the cross entropy loss function
'''
text = run_inference(raw_inputs)输出:
Latency: 32.24 seconds
Throughput: 31.02 tokens/s
Implement the cross entropy loss function
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossEntropyLoss(nn.Module):
def __init__(self, ignore_index=255):
super(CrossEntropyLoss, self).__init__()
self.ignore_index = ignore_index
def forward(self, inputs, targets):
n = inputs.size(0)
log_probs = F.log_softmax(inputs, dim=1)
loss = -torch.sum(targets * log_probs, dim=1)
loss = torch.mean(loss)
return loss
class DiceLoss(nn.Module):
def __init__(self, ignore_index=255):
super(DiceLoss, self).__init__()
self.ignore_index = ignore_index
def forward(self, inputs, targets):
n = inputs.size(0)
log_probs = F.log_softmax(inputs, dim=1)
loss = -torch.sum(targets * log_probs, dim=1)
loss = torch.mean(loss)
return loss
class DiceLoss2(nn.Module):
def __init__(self, ignore_index=255):
super(DiceLoss2, self).__init__()
self.ignore_index = ignore_index
def forward(self, inputs, targets):
n = inputs.size(0)
log_probs = F.log_softmax(inputs, dim=1)
loss = -torch.sum(targets * log_probs, dim=1)
loss = torch.mean(loss)
return loss在这里我们看到,尽管模型已经完成了生成CrossEntropyLoss类的代码,但它还是继续生成不必要的代码,直到达到最大长度限制(max_length=1000)。
最后,让我们要求模型实现二分查找算法。
raw_inputs = '''
Implement binary search
'''
text = run_inference(raw_inputs)输出:
Latency: 4.60 seconds
Throughput: 30.65 tokens/s
Implement binary search
"""
def binary_search(arr, target):
low = 0
high = len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
arr = [1,2,3,4,5,6,7,8,9,10]
target = 10
print(binary_search(arr, target))<|endoftext|>这次,我们看到模型能够完美地实现二分查找!
从上面的例子中,我们看到CodeGen的效果相当不错,但也有一些奇怪的行为,比如不知道何时停止或响应中遗漏了一些小细节。这可能是因为我们使用了只有3亿参数的最小变体,这对于一个语言模型来说相当小。我们鼓励读者探索更大的变体并测试生成响应的质量。