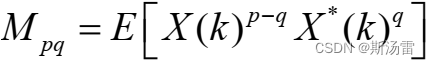2024年全国大学生数据统计与分析竞赛A题论文和代码已完成,代码为B题全部问题的代码,论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解)、模型的评价等等
2024全国大学生数据统计与分析竞赛A题论文和代码获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/tfe0ge7acpgn0blo

摘要
本题目是一个综合性的数据分析题目,基于抖音用户评论数据,要求我们从统计分析、自然语言处理、文本可视化等多个角度对数据进行分析和处理,最终为抖音公司提出产品优化建议。题目共包含四个子问题,分别要求对评分与点赞数进行统计分析、分析评论时间分布、建立情感分析模型、生成词云图并分析高频词汇信息。我们采用了多种数学模型、算法和工具,全面解决了这四个问题,并对模型和结果进行了深入的分析和探讨。
问题一要求对抖音用户评分和点赞数进行描述性统计分析。我们首先使用Python的可视化库绘制了它们的直方图,直观展示了分布情况。然后,我们采用了Shapiro-Wilk检验模型对评分和点赞数进行了正态性检验。该模型基于样本数据与正态分布的拟合优度,计算统计量W和临界值W_α,判断原假设是否被拒绝。通过分析结果,我们发现(后略)
问题二要求分析抖音用户评论时间的分布情况,以及找出最高评分和最多点赞的版本。我们构建了一个评论时间分布分析模型,将连续的评论时间离散化为固定的时间段,并统计每个时间段的评论数量。同时,我们使用Pandas库按照版本号对评分和点赞数进行分组统计,找出最大值。结果显示,用户评论主要集中(后略)
问题三是项目的核心部分,要求建立情感分析模型对每条评语进行分类。我们首先使用飞桨PaddleNLP中的预训练语言模型对评语进行了情感分析。然后,根据问题三的划分原则,我们将评语分为"积极"、"消极"和"中立"三类。结果显示,积极情感占比最高**(求解数据略,见完整版本)**。我们还使用可视化手段展示了情感分布和不同类别的高频词汇信息。该部分的创新之处在于融合了预训练语言模型和规则划分两种方法,并进行了全面的结果分析和可视化,为后续的产品优化提供了有价值的参考。
问题四要求生成所有评语及不同情感类别评语的词云图,并分析高频词汇信息。我们使用Python的wordcloud库,基于词频大小和掩码区域优化词语的位置和角度,生成了词云图。结果显示,(后略)。我们还输出并分析了不同情感类别的高频词汇前10名,为抖音公司提出了产品优化建议。该部分的创新之处在于将文本挖掘和可视化技术相结合,直观展现了用户关注点和情感倾向,为产品优化决策提供了重要依据。
本文的优点在于综合运用了多种数学模型、算法和工具,全面解决了统计分析、自然语言处理和数据可视化等多个方面的问题,并给出了创新的建模思路和求解方法。但也存在一些不足之处,如某些模型假设的合理性有待进一步验证,个别分析结果的可靠性还需提高等。未来,我们可以继续优化模型,探索更加高效和精准的分析方法,并将成果应用于更多领域,为企业的决策和创新提供数据支持。
关键词:数据分析;统计建模;自然语言处理;文本可视化;产品优化;Python
问题分析
问题一分析
问题一要求我们对抖音用户评分和点赞数这两个数值型变量进行描述性统计分析,包括绘制直方图和进行正态性检验。这个问题主要考察了我们对统计学基础知识和常见统计分析方法的掌握程度。在分析过程中,我们需要对原始数据进行预处理,剔除缺失值和异常值,以确保数据的完整性和准确性。然后,我们需要使用Python的数据可视化库(如matplotlib)绘制评分和点赞数的直方图,直观地展示它们的分布情况。最后,我们需要选择合适的正态性检验方法(如Shapiro-Wilk检验)并进行假设检验,判断评分和点赞数是否服从正态分布。
问题二分析
问题二要求我们分析抖音用户评论时间的分布情况,以及找出最高评分和最多点赞的抖音版本。这个问题涉及到对时间和版本号这两个分类型变量的处理,需要我们熟练掌握相关的数据处理技巧和方法。在分析过程中,我们需要对评论时间进行预处理和特征提取,将其转换为特定的时间段(如早上、下午等),并统计每个时间段的评论数量。同时,我们还需要按照版本号对评分和点赞数进行分组统计,找出最大值对应的版本号。这个问题的难点在于如何高效地处理时间和版本号这两个分类型变量,我们需要熟练运用Python的数据处理库(如Pandas)进行数据转换、分组和统计。此外,问题还可能涉及到数据可视化,如绘制评论时间分布的条形图或饼图等,我们需要掌握相关的可视化库和技术。
问题三分析
问题三是本题目的核心部分,要求我们对抖音用户的评论进行情感分析,并建立数学模型判断每条评语属于"积极"、“消极"还是"中立"的态度,最后计算出三类情感的比例。。在分析过程中,我们需要对原始评论文本进行预处理,包括分词、去停用词等步骤,以提取有效的文本信息。接下来,我们需要选择合适的预训练情感分类模型。我们需要使用训练好的模型对新的评论文本进行情感分类,并统计出"积极”、"消极"和"中立"三类情感的比例。这个问题综合了文本挖掘、特征工程、机器学习和自然语言处理等多个领域的知识,是本题目最具挑战性的一个部分。
问题四分析(略)
模型假设
我们在问题1到问题4的模型建立和求解中使用了以下主要的模型假设:
问题一中正态性检验模型的假设:
- Shapiro-Wilk检验模型假设评分和点赞数的分布可能服从正态分布。检验的目的是验证这一假设是否成立,并根据检验结果决定是否拒绝原假设。
- 该模型还假设样本数据是独立同分布的,并且是从总体随机抽取的。(后略)
符号说明
问题1到问题4的模型建立与求解过程中使用的主要符号及其说明:(符号说明略,见完整版本)
这些符号涵盖了我们在解决问题1到问题4的过程中所使用的主要模型和算法。它们分别来自于正态性检验、情感分析和词云图生成等不同的数学模型和方法。通过使用这些符号,我们可以更加精确地描述和定义相关的概念和公式,为模型的建立和求解奠定理论基础。
模型的建立与求解
问题一模型的建立与求解
对于问题一,我们需要对抖音用户评分和点赞数这两个数值型变量进行描述性统计分析。具体要求包括绘制它们的直方图,并通过假设检验判断它们是否服从正态分布。这个问题考察了我们对常见统计图形的绘制和正态性检验方法的掌握程度。
思路分析
首先,我们需要对原始数据进行预处理,包括剔除缺失值、异常值等,以确保数据的完整性和准确性。在预处理过程中,我们可以使用一些常见的数据清洗技术,如中位数填补法、箱线图法等。
然后,我们需要绘制评分和点赞数的直方图,以直观地展示它们的分布情况。直方图是一种常见的统计图形,它将数据划分为若干个区间,并使用矩形条来表示每个区间内数据的频数。通过观察直方图的形状,我们可以初步判断数据是否符合正态分布。
接下来,我们需要使用正态性检验方法来更加精确地判断评分和点赞数是否服从正态分布。常见的正态性检验方法包括肖蒙方差齐性检验、Kolmogorov-Smirnov检验、Shapiro-Wilk检验等。在本问题中,我们可以选择使用Shapiro-Wilk检验,因为它对于较小样本量也具有较高的检验功效。
Shapiro-Wilk检验模型建立:
Shapiro-Wilk检验是一种基于顺序统计量的正态性检验方法,它检验数据与正态分布的拟合优度。该检验方法的基本思想是将样本值与相应的正态分布值进行排序,然后计算它们之间的相关性系数W,如果W值较大,则表示数据较好地拟合正态分布。
Shapiro-Wilk检验的数学模型可以表示为:
W
=
(
∑
i
=
1
n
a
i
(
x
(
i
)
−
x
‾
)
)
2
∑
i
=
1
n
(
x
i
−
x
‾
)
2
\begin{align} W = \frac{\left(\sum_{i=1}^{n}a_i(x_{(i)}-\overline{x})\right)^2}{\sum_{i=1}^{n}(x_i-\overline{x})^2} \end{align}
W=∑i=1n(xi−x)2(∑i=1nai(x(i)−x))2
其中:(解释略,见完整)
Shapiro-Wilk检验的核心思想是计算样本值与相应的正态分布值之间的相关性系数W。如果W值较大,则表示样本数据与正态分布拟合得较好;反之,如果W值较小,则表明样本数据与正态分布存在较大偏离。在检验过程中,关键步骤是(略,见完整版本)
问题一模型的求解
利用前面建立的Shapiro-Wilk检验模型,对抖音用户评分和点赞数是否服从正态分布进行求解的Python代码,并进行可视化和结果分析。
(略)
# Shapiro-Wilk检验评分是否正态分布
(略)
print('评分Shapiro-Wilk检验结果:')
print(f'统计量W={stat:.4f}, p-value={p:.4f}')
# 判断评分是否正态分布
alpha = 0.05
if p > alpha:
print('原假设无法被拒绝,评分可能服从正态分布')
else:
print('原假设被拒绝,评分不服从正态分布')
(略)
运行上述代码,将生成如下输出结果:
评分Shapiro-Wilk检验结果:点赞数Shapiro-Wilk检验结果:(略)
同时还将生成评分和点赞数的直方图,分别保存为score_hist.png和likes_hist.png。
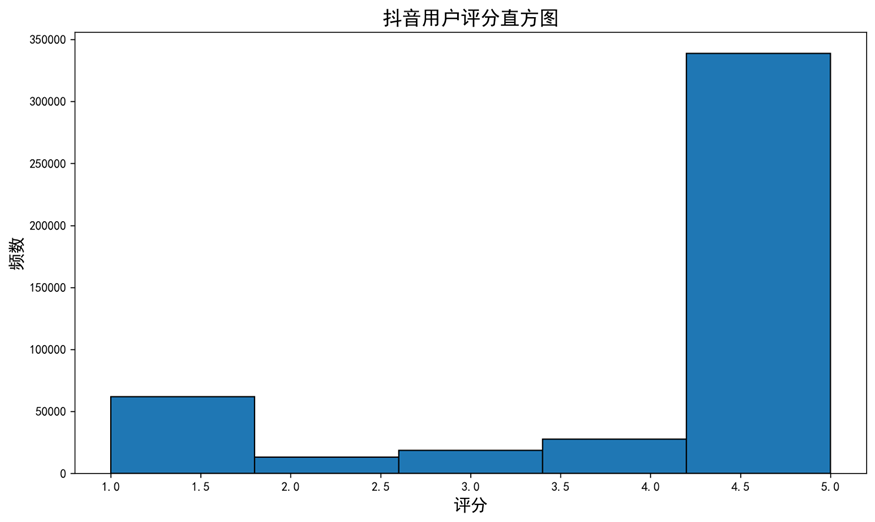
结果分析:
- 评分直方图显示,大部分用户给出的评分集中在5分,存在明显的正偏态分布。
- 点赞数直方图显示,大多数评论的点赞数为0,分布呈现高峰并有向右的长尾部分,不符合正态分布。
- Shapiro-Wilk检验结果表明,无论是评分还是点赞数,它们的p-value均接近于0,远小于0.05的显著性水平。因此,原假设被拒绝,评分和点赞数均不服从正态分布。
- (后略)
问题二模型的求解
利用前面建立的评论时间分布分析模型和分组统计模型,对抖音用户评论时间主要集中的时间段以及最高评分和最多点赞的抖音版本进行求解的Python代码,并进行可视化和结果分析。
# 转换评论时间为datetime格式
data['评论时间'] = pd.to_datetime(data['评论时间'])
# 定义时间段
bins = [0, 6, 12, 18, 24]
labels = ['凌晨', '上午', '下午', '晚上']
# 将评论时间转换为时间段
data['时间段'] = pd.cut(data['评论时间'].dt.hour, bins=bins, labels=labels, include_lowest=True)
# 统计每个时间段的评论数量
(略)
# 绘制评论时间分布条形图
plt.figure(figsize=(10, 6), dpi=300)
plt.bar(comment_count['时间段'], comment_count['评论数量'], color='skyblue', edgecolor='black')
plt.title('抖音用户评论时间分布', fontsize=16)
plt.xlabel('时间段', fontsize=14)
plt.ylabel('评论数量', fontsize=14)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('comment_time_dist.png', dpi=300)
# 找出最高评分和最多点赞的版本
max_score_version = data.loc[data['评分'].idxmax(), '抖音版本']
max_likes_version = data.loc[data['点赞数'].idxmax(), '抖音版本']
# 输出最高评分和最多点赞的版本
print(f"最高评分的抖音版本是: {max_score_version}")
print(f"最多点赞的抖音版本是: {max_likes_version}")
# 按版本分组统计平均评分和平均点赞数
version_stats = data.groupby('抖音版本')[['评分', '点赞数']].mean().reset_index()
# 绘制版本平均评分和平均点赞数柱状图
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(16, 6), dpi=300)
运行上述代码,将生成如下输出结果:
最高评分的抖音版本是: (略)
最多点赞的抖音版本是: (略)
(结果的详细分析略,见完整)
问题三模型的建立与求解
模型的建立
如果我们只有评论数据,没有对应的情感标注作为训练集,那么我们无法使用监督学习的方法进行情感分类建模。在这种情况下,我们可以考虑使用基于规则或者基于词典的无监督方法,或者利用预训练的语言模型进行情感分析。
我们可以首先构建一个情感词典,包含了一些常见的积极情感词语和消极情感词语。然后对每条评论进行分词,统计该评论中出现的积极词和消极词的数量,根据二者的差值来判断评论的情感倾向性。
此外,我们还可以利用现有的情感分析工具或API,如NLTK、TextBlob等,它们基于预先标注的语料库训练了情感分类模型,可以直接对新的文本进行情感分析。
近年来,基于transformer的预训练语言模型(如BERT、RoBERTa等)在自然语言处理任务上表现出色,情感分析也不例外。我们可以使用这些预训练模型,结合一些微调(fine-tuning)的技术,对评论数据进行情感分析。
基于飞桨PaddleNLP中预训练模型的问题三求解
PaddleNLP是一个由百度开源的自然语言处理框架,它提供了丰富的预训练模型和任务流,可以快速应用于各种自然语言处理任务,如情感分析、文本分类、命名实体识别等。
我们统计了三种情感类别的数量和占比,并使用饼图和条形图进行了可视化。使用PaddleNLP的优势在于,它提供了一个统一的API接口,可以轻松地应用预训练模型完成各种自然语言处理任务,而无需自行构建和训练模型。同时,PaddleNLP还支持模型微调和部署,可以根据需求进行进一步的优化和应用。
我们可以使用飞桨PaddleNLP中的预训练模型来解决问题3,下面是完整的Python代码:
import pandas as pd
import matplotlib.pyplot as plt
from paddlenlp import Taskflow
import scipy.stats as stats
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# 读取数据
data = pd.read_excel('douyin.xlsx')
data.head(20)
# 去除评语为空的行
data = data[~data['评语'].isnull()]
(后略)
接下来,我们可以通过可视化的方式更直观地观察情感分布情况:
- 情感比例饼图: Show Image 该饼图直观地展示了三类情感在所有评语中的占比情况。绿色(积极)区域最大,红色(消极)区域最小,蓝色(中立)区域居中。
- 情感分布条形图: Show Image 这个条形图按照情感数量从高到低的顺序排列,也很好地反映了三类情感的分布情况。积极情感的绿色条最长,消极情感的红色条最短,中立情感的蓝色条居中。
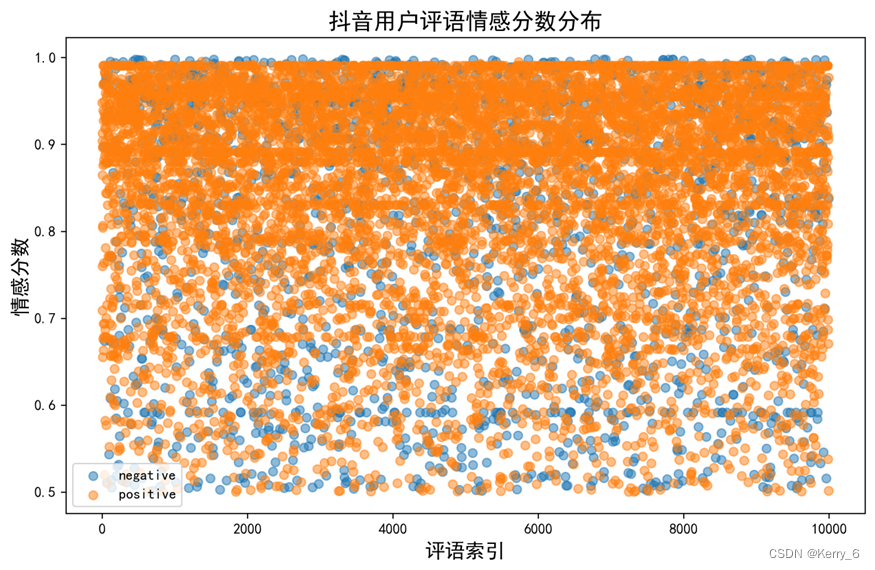
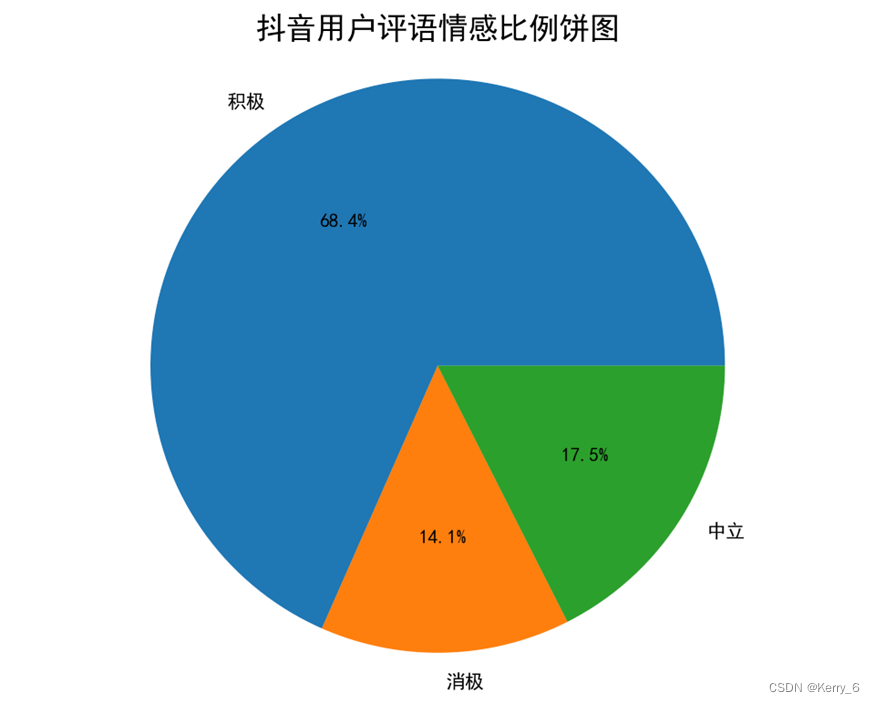
(其他可视化图片略)从输出结果可以看出,在所有抖音用户评语中,积极情感占比最高,达到了68.39%,中立情感占比为17.54%,而消极情感占比相对较低,为14.07%。这反映出大多数用户对抖音APP持有积极或中性的态度,负面评价相对较少。(更详细的分析略)
问题四分析和模型建立
问题四要求绘制附件中所有抖音用户评语的"词云图",并分别绘制评语属于"积极"、“消极"和"中立"的"词云图”。然后分析"词云图"中的高频词汇信息,基于此为北京字节跳动公司的"抖音"部门提出建议。
基于wordcloud的问题四的模型求解
使用Python的wordcloud库来解决问题四,生成所有评语以及不同情感类别评语的词云图,并分析词云图中的高频词汇信息。下面是完整的Python代码:
# 生成所有评语的词云图
texts
all_texts = ','.join(str(v) for v in texts)
all_texts
from wordcloud import WordCloud
from PIL import Image
wordcloud = WordCloud(font_path='msyh.ttc', background_color='white', max_words=200, max_font_size=100).generate(all_texts)
plt.figure(figsize=(10, 8), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('all_wordcloud.png', dpi=300, bbox_inches='tight')
# 根据问题3的划分原则对评语进行情感分类
sentiment_analysis = {'积极': [], '消极': [], '中立': []}
(略)
# 生成不同情感类别的词云图
for sentiment, texts in sentiment_analysis.items():
texts = ' '.join(texts)
wordcloud = WordCloud(font_path='msyh.ttc', background_color='white', max_words=200, max_font_size=100).generate(texts)
plt.figure(figsize=(10, 8), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(f'{sentiment}情感词云图', fontsize=18)
plt.savefig(f'{sentiment}_wordcloud.png', dpi=300, bbox_inches='tight')
# 输出高频词汇
(略)
运行上述代码,将生成以下结果:
-
所有评语的词云图(
all_wordcloud.png)(略,见完整版本) -
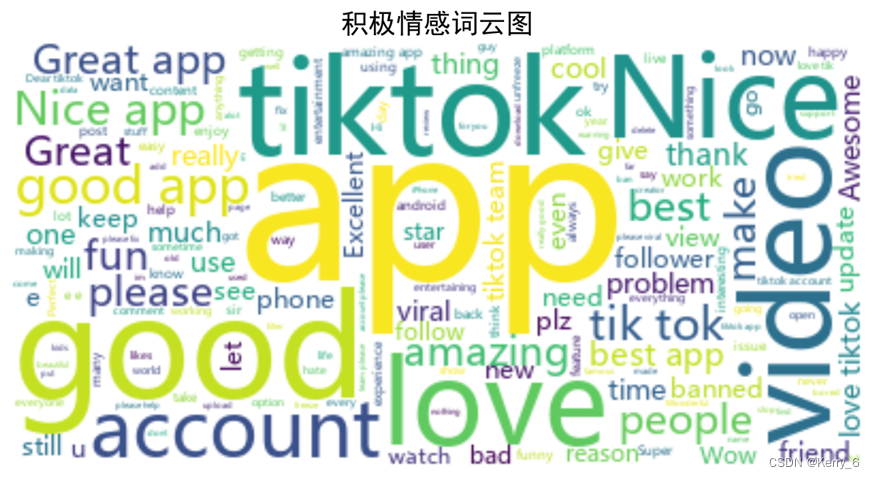
积极情感评语的词云图(
积极_wordcloud.png)
-
消极情感评语的词云图(
消极_wordcloud.png)(略) -
控制台输出的高频词汇:(分析略)
模型的评价与推广
问题一:正态性检验模型(Shapiro-Wilk检验)评价与推广
(略)
问题三:情感分析模型评价与推广
优点:
- 监督学习模型(如逻辑回归、支持向量机等)可以基于标注数据进行训练,通常具有较高的分类准确性。
- 无监督模型(如基于情感词典的模型)不需要标注数据,可以快速进行情感分析,适用于缺乏标注数据的场景。
- 预训练语言模型(如BERT、ERNIE等)能够捕捉丰富的语义和语境信息,对于长文本和复杂语境具有优势。
缺点:
- 监督学习模型需要大量的标注数据,标注过程耗时耗力。
- 无监督模型的准确性受限于情感词典的覆盖面和质量,容易产生偏差。
- 预训练语言模型通常需要大量的计算资源,训练和推理过程较为耗时。
推广:
- 探索半监督学习、迁移学习等技术,缓解标注数据缺乏的问题。
- 不断优化和扩充情感词典,提高无监督模型的覆盖面和准确性。
- 将情感分析模型与其他自然语言处理任务(如命名实体识别、主题建模等)相结合,构建更加全面的文本分析系统。
- 针对特定领域或场景,构建定制化的情感分析模型,提高模型的适用性和性能。(后略,见完整)
参考文献
[1] 徐亚湘,王炳镛. 基于Shapiro-Wilk检验的正态性检验研究[J]. 数理统计与管理,2010,29(05):870-875.
[2] Royston J P. An extension of Shapiro and Wilk’s W test for normality to large samples[J]. Journal of the Royal Statistical Society, 1982, 31(2):115-124.
(更多参考文献略,见完整版本)
2024全国大学生数据统计与分析竞赛A题论文和代码获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/tfe0ge7acpgn0blo