sql优化第一步:搞懂Oracle中的SQL的执行过程
从图中我们可以看出SQL语句在Oracle中经历了以下的几个步骤:
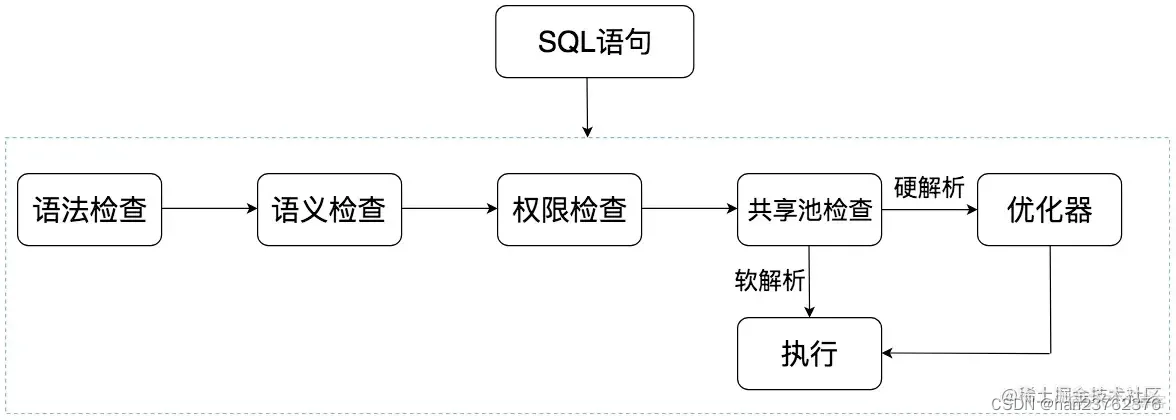
语法检查:检查SQL拼写是否正确,如果不正确,Oracle会报语法错误。
语义检查:检查SQL中的访问对象是否存在。比如我们在写SELECT语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证SQL语句没有错误。
权限检查:看用户是否具备访问该数据的权限。
共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存SQL语句和该语句的执行计划。Oracle通过检查共享池是否存在SQL语句的执行计划,来判断进行软解析,还是硬解析。
优化器:优化器中进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
执行器:当有了解析树和执行计划之后,就知道了SQL该怎么被执行,这样就可以在执行器中执行语句了。
共享池是Oracle中的术语,包括了库缓存,数据字典缓冲区等。**库缓存区,主要缓存SQL语句和执行计划。**数据字典缓冲区存储的是Oracle中的对象定义,比如表、视图、索引等对象。当对SQL语句进行解析的时候,如果需要相关的数据,会从数据字典缓冲区中提取。
硬解析和软解析
软解析:在共享池中,Oracle首先对SQL语句进行Hash运算,然后根据Hash值在库缓存(Library Cache)中查找,如果存在SQL语句的执行计划,就直接拿来执行,直接进入“执行器”的环节
硬解析:如果没有找到SQL语句和执行计划,就会进入“优化器”这个步骤,Oracle就需要创建解析树进行解析,生成执行计划
如何避免硬解析
在Oracle中,绑定变量是它的一大特色。绑定变量就是在SQL语句中使用变量,通过不同的变量取值来改变SQL的执行结果。
这样做的好处是能提升软解析的可能性,不足之处在于可能会导致生成的执行计划不能优化,因此是否需要绑定变量还需要视情况而定。
举个例子,我们可以使用下面的查询语句:
SQL> select * from student where student_id = 100;
1.
你也可以使用绑定变量,如:
SQL> select * from student where student_id = :student_id;
1.
这两个查询语句的效率在Oracle中是完全不同的。
如果在查询过student_id = 100以后,我们还需要继续查询101、102等学生的信息,那么我们每次使用第一种查询方式的时候,都会创建一个新鞋的查询解析。
使用第二种方式的时候,第一次查询之后,会在共享池中存在这类查询的执行计划,也就是上面提到的软解析。
绑定变量的方式可以减少硬解析,减少Oracle的解析工作量。但是因为参数不同,可能会导致SQL的执行效率不同,同时SQL优化也会比较困难。
sql优化第二步:看懂执行计划
Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执行计划去执行。分析语句的执行计划的工作是由优化器(Optimizer)来完成的。不同的情况,一条SQL可能有多种执行计划,但在某一时点,一定只有一种执行计划是最优的,花费时间是最少的。
相信你一定会用Pl/sql Developer、Toad等工具去看一个语句的执行计划,不过你可能对Rule、Choose、First rows、All rows这几项有疑问,因为我当初也是这样的,那时我也疑惑为什么选了以上的不同的项,执行计划就变了?
1、优化器的优化方式
Oracle的优化器共有两种的优化方式,即基于规则的优化方式(Rule-Based Optimization,简称为RBO)和基于代价的优化方式(Cost-Based Optimization,简称为CBO)。
A、RBO方式:优化器在分析SQL语句时,所遵循的是Oracle内部预定的一些规则。比如我们常见的,当一个where子句中的一列有索引时去走索引。
B、CBO方式:依词义可知,它是看语句的代价(Cost)了,这里的代价主要指Cpu和内存。优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小 、有少行、每行的长度等信息。这些统计信息起初在库内是没有的,是你在做analyze后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些我们应及时更新这些信息。在Oracle8及以后的版本,Oracle列推荐用CBO的方式。
我们要明了,不一定走索引就是优的 ,比如一个表只有两行数据,一次IO就可以完成全表的检索,而此时走索引时则需要两次IO,这时对这个表做全表扫描(full table scan)是最好的。
新版本的oracle逐渐抛弃对Rule方式的支持,即使是Rule方式,最后sql执行效率的衡量标准都是,sql执行消耗了多少资源?对代价(COST)的优化方式,需要表,索引的统计信息,需要每天多表和索引进行定时的分析,但是统计信息也是历史的,有时候也不一定是最优的,统计信息等于就是一个人的经验,根据以前的经验来判断sql该怎么执行(得到优化的sql执行路径),所以具体优化执行的时候,先手工分析sql,看是用RBO方式消耗大,还是CBO消耗大;DBA的工作就是要根据当前oracle的运行日志,进行各种调整,使当前的oracle运行效率尽量达到最优.可以在运行期间,采用hint灵活地采用优化方式.
2、优化器的优化模式(Optermizer Mode)
优化模式包括Rule,Choose,First rows,All rows,FIRST_ROWS_n这五种方式,也就是我们以上所提及的。如下我解释一下:
Rule:不用多说,即走基于规则的方式。 (RBO优化方式)
Choolse:这是我们应观注的,默认的情况下Oracle用的便是这种方式。指的是当一个表或或索引有统计信息,则走CBO的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走RBO的方式。
在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan),你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。
First Rows:它与Choose方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。 (CBO优化方式,提供一个最快的反应时间,根据系统的需求,使用情况)
All Rows:也就是我们所说的Cost的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐量。没有统计信息则走基于规则的方式。 (CBO优化方式,提供最大的吞吐量,就是使执行总量达到最大)
FIRST_ROWS_n(n=1,10,100,1000)
Oracle 采用 CBO 解析目标 SQL。
侧重点是最快的速度返回头 n 条记录。
本质上其实是 Oracle 把那些能够以最快相应速度返回头 n 条记录所对应的执行步骤的成本修改成一个很小的值(远远小于默认情况下 CBO 对同样执行步骤所计算的成本值)。
First Rows和All Rows是有冲突的.如果想最快第返回给用户,就不可能传递更多的结果,这就是First Rows返回最先检索到的行(或记录);而All Rows是为了尽量将所有的结果返回给用户,由于量大,用户就不会很快得到返回结果.就象空车能跑得很快,重装车只能慢慢地跑;
3、如何设定选用哪种优化模式
查看参数
show parameter optimizer_mode
修改参数
alter session set optimizer_mode='CHOOSE'
a、Instance级别
我们可以通过在init.ora文件中设定OPTIMIZER_MODE=RULE、OPTIMIZER_MODE=CHOOSE、OPTIMIZER_MODE=FIRST_ROWS、OPTIMIZER_MODE=ALL_ROWS去选用3所提的四种方式,如果你没设定OPTIMIZER_MODE参数则默认用的是Choose这种方式。
init.ora和init.ora都在$ORACLE_HOME/dbs目录下,可以用find $ORACLE_HOME -name init*.ora查看该目录下的init文件.
init.ora是对全体实例有效的;init.ora只对指定的实例有效.
B、Sessions级别
通过SQL> ALTER SESSION SET OPTIMIZER_MODE=;来设定。 将覆盖init.ora,init.ora设定的优化模式,也可以在sql语句中采用hint强制选定优化模式.如下:
C、语句级别
这些需要用到Hint,比如:
SQL> SELECT /+ RULE / a.userid,
2 b.name,
3 b.depart_name
4 FROM tf_f_yhda a,
5 tf_f_depart b
6 WHERE a.userid=b.userid;
在这儿采用hint,强制采用基于规则(rule)的优化模式;
hint语法,/+开头,/结尾,中间填写强制采用的优化模式.
4、为什么有时一个表的某个字段明明有索引,当观察一些语的执行计划确不走索引呢?如何解决呢 ?
A、不走索引大体有以下几个原因
♀你在Instance级别所用的是all_rows的方式
♀你的表的统计信息(最可能的原因)
♀你的表很小,上文提到过的,Oracle的优化器认为不值得走索引。
B、解决方法
♀可以修改init<SID>.ora中的OPTIMIZER_MODE这个参数,把它改为Rule或Choose,重起数据库。也可以使用4中所提的Hint.
♀删除统计信息
SQL>analyze table table_name delete statistics;
♀表小不走索引是对的,不用调的。
5、其它相关
A、如何看一个表或索引是否是统计信息
SQL>SELECT * FROM user_tables
2 WHERE table_name=<table_name>
3 AND num_rows is not null;
SQL>SELECT * FROM user_indexes
2 WHERE table_name=<table_name>
3 AND num_rows is not null;
b、如果我们先用CBO的方式,我们应及时去更新表和索引的统计信息,以免生形不切合实的执行计划。
SQL> ANALYZE TABLE table_name COMPUTE STATISTICS;
SQL> ANALYZE INDEX index_name ESTIMATE STATISTICS;