💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后端的开发语言ABAP,SQL进行任务的完成,对SAP企业管理系统,SAP ABAP开发和数据库具有较深入的研究。
💅文章概要: 各位小伙伴们大家好呀!你是否还在为寻找不到合适的配图而苦恼呢?本篇文章主要讲解一下如何抓取网站图片到本地, 从而实现快速找图的需求。希望能帮助到大家!
🤟每日一言: 永远年轻,永远热泪盈眶!
文章目录
- 前言
- PYTHON环境配置
- 库的安装
- CMD安装
- 代码实现
- 代码修改部分
- 抓取图片单组数量设置
- 抓取图片组别数量设置
- 图片存储路径
- 实现效果
- 写在最后的话
前言
各位小伙伴们大家好呀!瑞兔呈祥吗,你是否还在为寻找不到合适的兔兔配图而苦恼呢?本篇文章主要讲解一下如何抓取兔兔图片到本地, 从而实现快速找图的需求。希望能帮助到大家!
PYTHON环境配置
首先我们要进行Python的开发环境配置,这里我选用的是一款轻量小巧的跨平台开源集成开发环境:Geany
PS:关于Python如何配置Geany集成开发环境在笔者这篇文章中介绍地很详细了,不会地小伙伴可以阅览;或者使用其他的开发环境也是完全没有任何问题的!
【PYTHON】如何配置集成开发环境Geany
库的安装
在此Python爬虫中我们需要用到5个库:它们分别如下是:
- requests
- json
- urllib
- os
- time
CMD安装
(一)进入cmd命令提示符
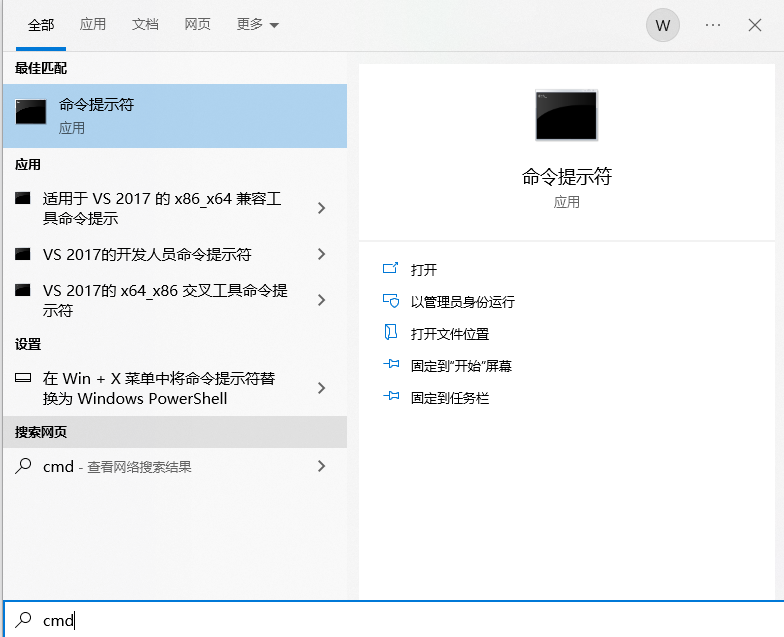
(二)输入安装代码:
pip install 库的名称
PS::
os和time一般来说不需要进行安装,python3环境中会自带。
代码实现
# -*- coding:utf8 -*-
import requests
import json
from urllib import parse
import os
import time
class BaiduImageSpider(object):
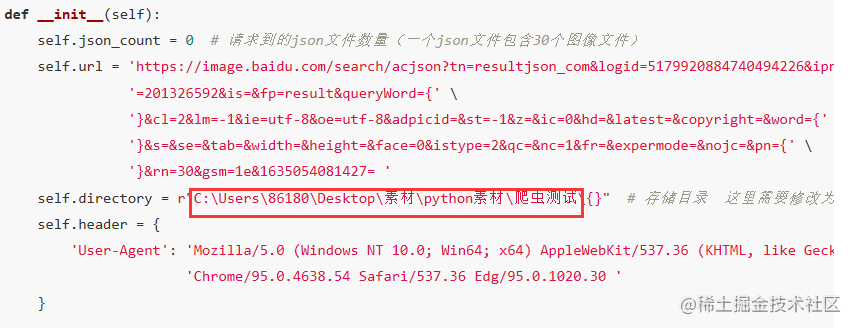
def __init__(self):
self.json_count = 0 # 请求到的json文件数量(一个json文件包含30个图像文件)
self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5179920884740494226&ipn=rj&ct' \
'=201326592&is=&fp=result&queryWord={' \
'}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={' \
'}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={' \
'}&rn=30&gsm=1e&1635054081427= '
self.directory = r"C:\Users\86180\Desktop\素材\python素材\爬虫测试\{}" # 存储目录 这里需要修改为自己希望保存的目录 {}不要丢
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30 '
}
# 创建存储文件夹
def create_directory(self, name):
self.directory = self.directory.format(name)
# 如果目录不存在则创建
if not os.path.exists(self.directory):
os.makedirs(self.directory)
self.directory += r'\{}'
# 获取图像链接
def get_image_link(self, url):
list_image_link = []
strhtml = requests.get(url, headers=self.header) # Get方式获取网页数据
jsonInfo = json.loads(strhtml.text)
for index in range(30):
list_image_link.append(jsonInfo['data'][index]['thumbURL'])
return list_image_link
# 下载图片
def save_image(self, img_link, filename):
res = requests.get(img_link, headers=self.header)
if res.status_code == 404:
print(f"图片{img_link}下载出错------->")
with open(filename, "wb") as f:
f.write(res.content)
print("存储路径:" + filename)
# 入口函数
def run(self):
searchName = "兔兔"
searchName_parse = parse.quote(searchName) # 编码
self.create_directory(searchName)
pic_number = 0 # 图像数量
for index in range(self.json_count):
pn = (index+1)*30
request_url = self.url.format(searchName_parse, searchName_parse, str(pn))
list_image_link = self.get_image_link(request_url)
for link in list_image_link:
pic_number += 1
self.save_image(link, self.directory.format(str(pic_number)+'.jpg'))
time.sleep(0.2) # 休眠0.2秒,防止封ip
print(searchName+"----图像下载完成--------->")
if __name__ == '__main__':
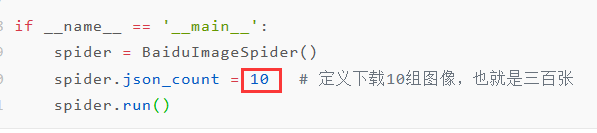
spider = BaiduImageSpider()
spider.json_count = 10 # 定义下载10组图像,也就是三百张
spider.run()
代码修改部分

默认代码为一次抓取10组图片,每组30张。若想一次性设置图片抓取数量多少,则进行以下修改:
抓取图片单组数量设置
上述代码默认一组的抓取数量为30张,所想设置单组的图片抓取数量,则将下图所框选处30修改成自己想要的数量。

抓取图片组别数量设置
上述代码默认一次抓取的图片组的数量为10组,所想自己设置图片抓取的组别数量,则将下图所框选处10修改成自己想要的数量。
图片存储路径
将下方的图片存储路径修改为自己的存储路径,抓取的图片将自动保存到该文件夹中,如果不存在改文件夹则会自动创建!
实现效果
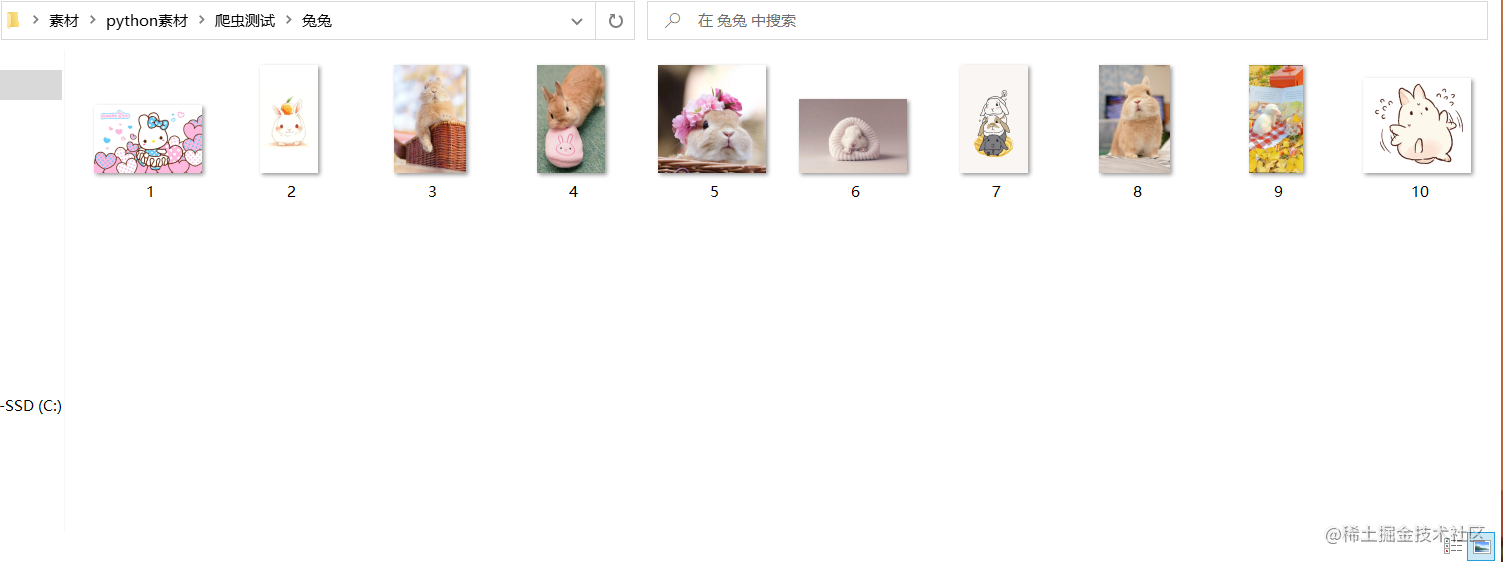
写在最后的话
本文花费大量时间介绍了如何抓取网站兔兔图片到本地,希望能帮助到各位小伙伴,码文不易,还望各位大佬们多多支持哦,你们的支持是我最大的动力!

✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{9c81c1}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{ed7976}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{98c091}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!