笔者(后台技术汇)恭祝各位大佬:2023年春节快乐,兔年祥瑞。

距离上次更新,已经过去5个月有余了,有小伙伴疑惑笔者是不是删库跑路了..
其实不是,这段时间是在参加一次比较大的项目重构(目前已经基本完成了功能灰度,节后可以实现全面覆盖)。这期间的工作量简直“让人发指”,历史包袱非常巨大,重构过程更是触目惊心,我只能暂时放下键盘,回去搬砖了..
在春节难得的私人时间里,以及往后空余时间,我会继续高质量文章输出的,非常感谢大家一直以来的支持。

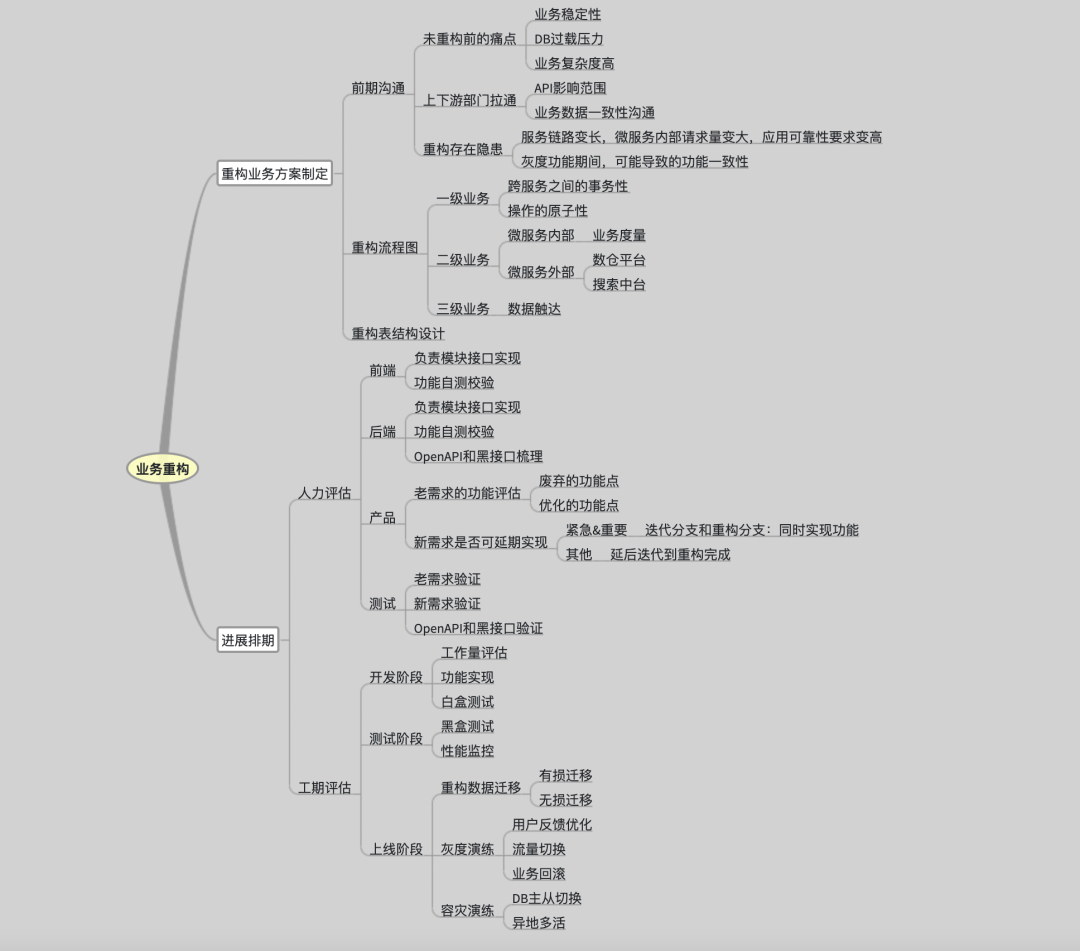
业务重构做了什么
为了避险,下面已对信息进行脱敏处理,这里先提及一下背景:
我们的业务系统是个大而全的应用单体系统。
部门此前经历了应用上云,更使用了先进的K8S进行容器资源编排管理;
生产环境的应用仍旧偶发性出现OOM,进而出现容器调度重启的情况,导致接口超时或500,在业务低峰期甚至直接影响SLA;
另外一个促使我们进行业务重构的原因,则是生产环境的DB资源面临着巨大压力,经常有定位到是DB导致的业务问题(部门在数据库资源的投入一直是非常慷慨的,基本观点是:如果堆资源能解决的问题,决不轻易重构业务),这里举几个例子说明:DB主从库延时导致的业务一致性问题、慢SQL问题、并发SQL。
业界对系统重构的态度一向是非常谨慎的,一般情况下不建议对老系统进行重构,毕竟重构是有代价的。
箭在弦上不得不发,严峻的SLA挑战和不断闪烁的告警,让组内领导下定了决心:必须进行业务重构!
接下来就是确定目标:我们组内开了很多次会议,根据产品形态和需求关联,圈出业务迁移的影响范围。其实这块跟业务息息相关了,是没法在一篇文章里面详细说尽的,尤其是技术文,尽可能的做到脱离业务需求,专注技术层面。
用一句话总结业务重构就是:将原本单体业务里的耗时逻辑优化重构、对DB单库的大表拆分、对过去设计不合理的表结构进一步重构聚合,最后以微服务形态进行落地,达到业务重构拆分的目的。
最后就是人力排期:
- 这次重构拆分的工作量巨大,几乎动员了所有需求相关的前后台开发同事;
- 重构过程里,由于存在复杂的API调用链,我们开了数次会议,拉通上下游部门进行协同开发;

遇到难题了,怎么办?
在重构过程里,团队每个成员分工负责自己所负责的模块内容,以周例会形式,把问题抛出来讨论,最终把同类问题归类解决。
- 项目管理问题
由于这次重构是偏向后台系统的,所以PM是我们的一位后台开发大佬。“时间紧任务重”是整个过程的基调,加班加点是经常的事情,不过花了很多时间,却仍然没能全部规避掉人力冲突问题。
比如,最大的冲突就是,在重构过程中,组长确定了迭代要歇一段时间,但产品一直催促上某个迭代改动,这种情况研发就比较被动了。但也不是没有解决办法..
- 业务方案问题
老项目是2017年开发的,当时基于SpringMVC开发了前后端,很多页面渲染逻辑都是在JSP里,因此这次重构遇到了前后端分离的问题;
1、API向上兼容是最常见的问题。
在业务性很强的服务来说,在业务开始之前需要有复杂的校验,如果在这个服务中支持多种业务类型,还需要根据不同的业务类型来选择不同的校验逻辑,因此在服务中将校验栈独立出来。
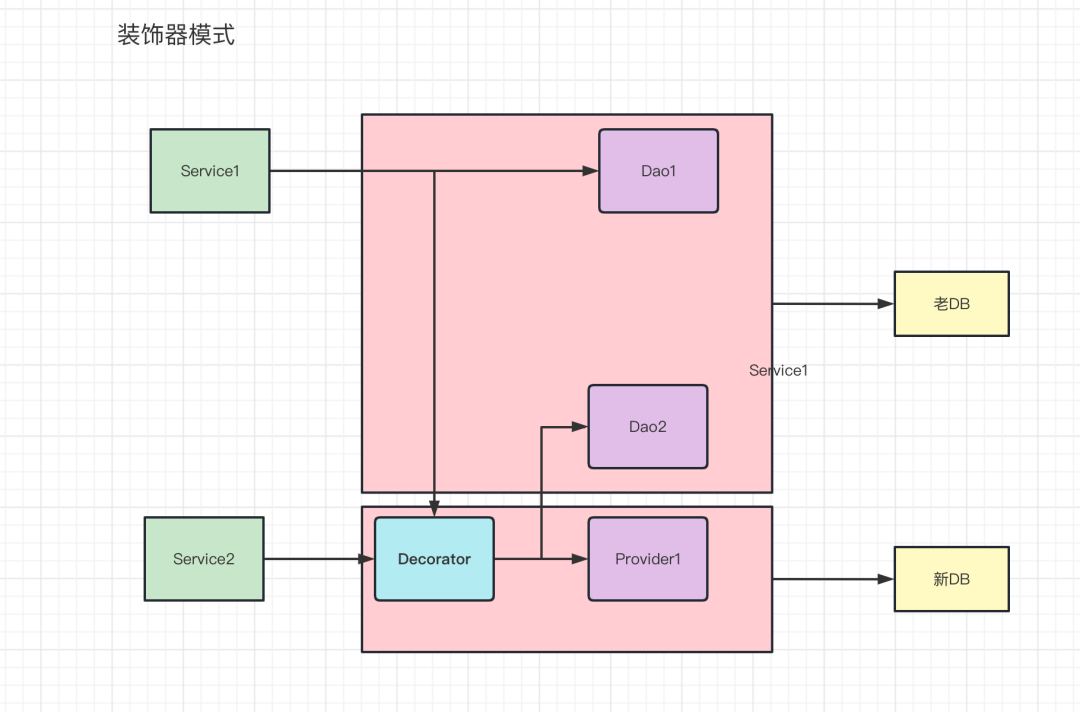
下面讲述一个简单场景:业务拆分会把原来的订单库,按业务维度分为电商订单和物流订单,并进行数据分库处理;这就导致原来查出两种类型数据的API,要两边查库返回同个模型的数据。
这里我们简单使用了装饰器模式,对Dao层进行增强处理。
所有DB的增删改查,都统一走Decorator:
- 未灰度的API,返回Dao1的分页数据;
- 灰度的API,返回Dao2的分页数据。
2、跨库分页检索数据一直是个难题,我们借助了ES来实现,这里其实没有太多可以展开说的了,都是纯业务的内容。但也有2个地方值得注意:
【2.1】一个是数据同步方案(Mysql -> ES)的优化;
【旧方案】Maxwell 监听 binlog + kafka数据订阅 + Es写入
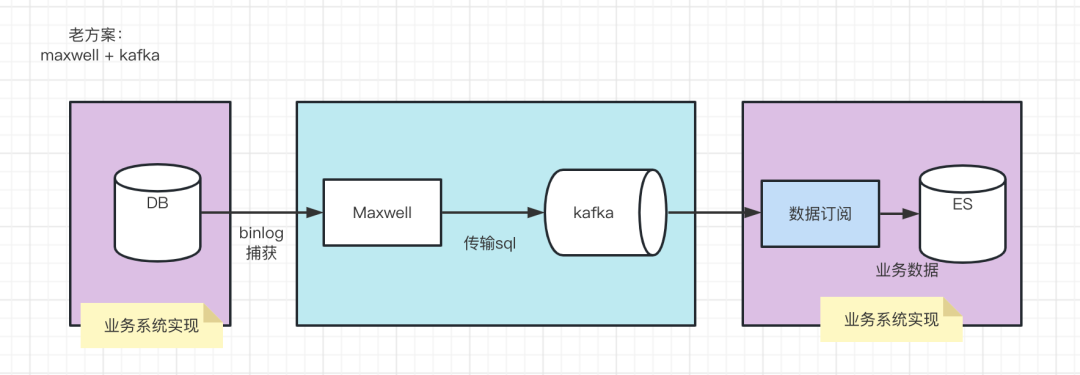
不足:日常容灾演练,会随时断掉了maxwell对主库DB的监听,此时影响到下游ES消费。如果要对 maxwell 拓展维护主从切换,难免增加了部署维护的昂贵使用成本。
【新方案】基于腾讯云DTS 的数据订阅能力+ Es写入
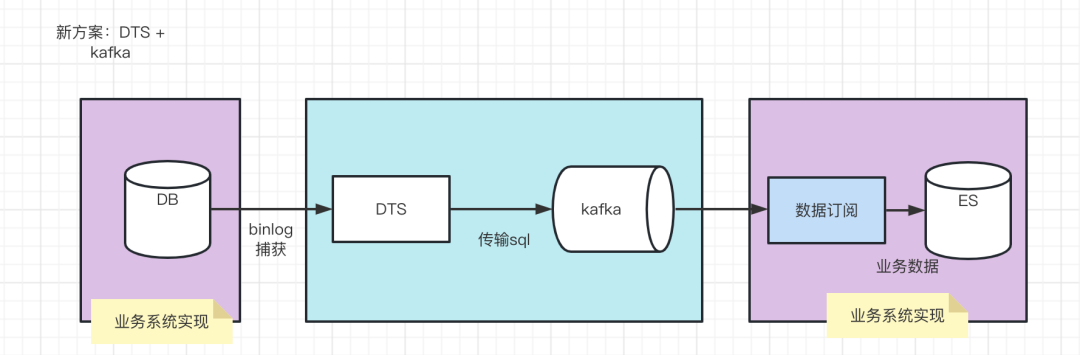
参考公开资料:https://www.shangyun51.com/productdetail?id=358
【2.2】ES分页方案
【1】from&size 分页越深,查询越慢
【2】search_after 方案,深度分页效率高
【3】scroll api方案
三种方案都有其优劣,按照业务对深度分页的强烈与否,去决定使用哪一种方案比较合适。
from/size方案的优点是简单,缺点是在深度分页的场景下系统开销比较大,占用较多内存。
search after基于ES内部排序好的游标,可以实时高效的进行分页查询,但是它只能做下一页这样的查询场景,不能随机的指定页数查询。
scroll方案也很高效,但是它基于快照,不能用在实时性高的业务场景,建议用在类似报表导出,或者ES内部的reindex等场景。
结论:最终我们使用了from/size方案,因为数据深度分页的场景,用户的需求并不强烈;更加强烈的是对数据同步的敏感度。
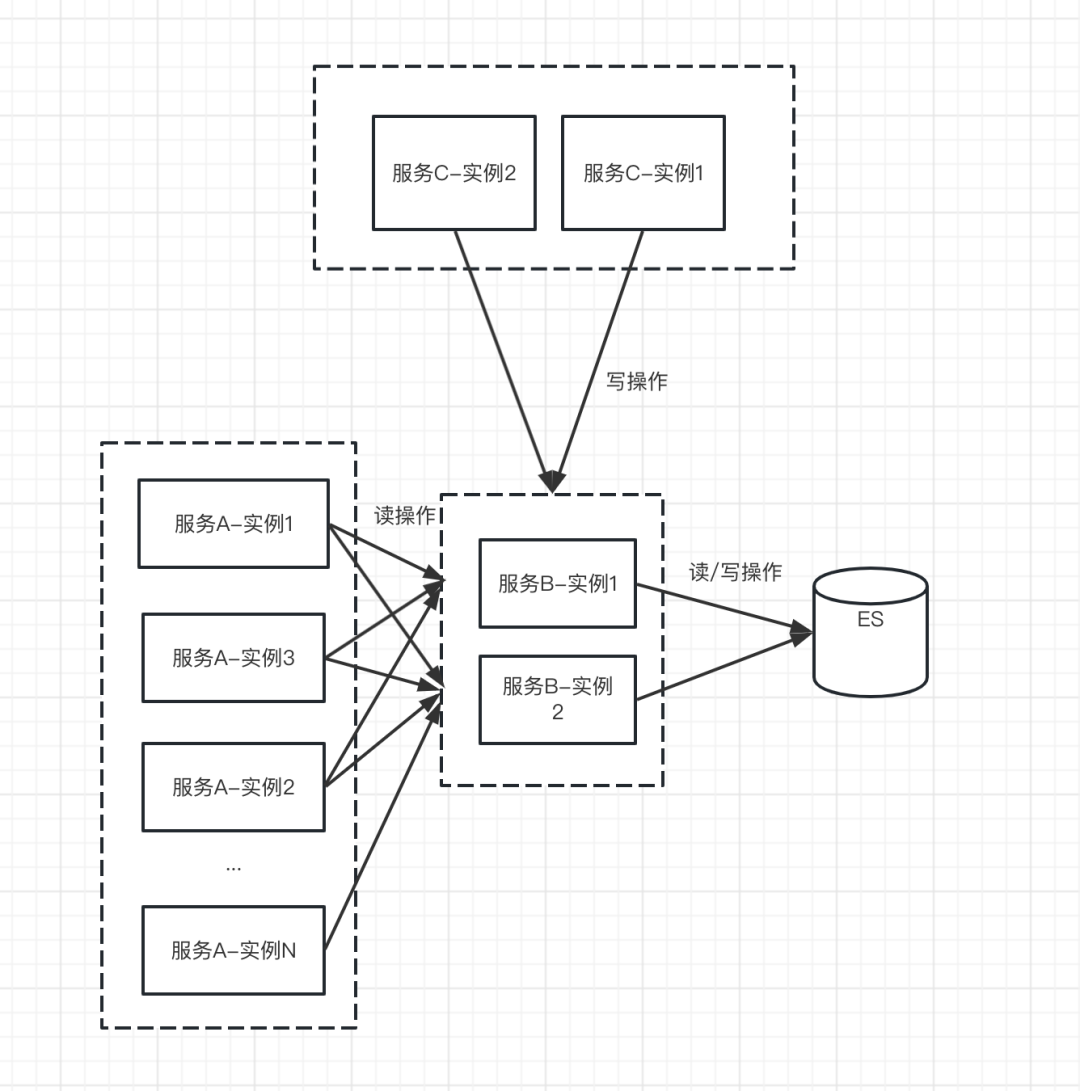
3、微服务内部RPC限流
在微服务体系下,针对ES读写我们分别采用不同的锁方案,读操作使用了客户端限流,写操作使用了单机限流。
由于业务的读写操作在服务层面就做了隔离,因此可以直接对服务A和服务C进行不同策略的限流方案。
- 由于读操作QPS比写操作QPS高出几个量级,因此使用客户端限流(基于Guava的工具类实现),后续即使进行了容器扩缩容,也不至于hold不住。
- 由于写操作仅发生在服务B(这是无状态服务),一般不会随意扩缩容,因此可以通过简单的锁同步(比如Semepohore)即可实现限流。

总结

以上只是一点点的浅浅回顾,还有很多知识点来不及分享(性能监控、指标梳理等),只能后续抽空继续写文章了。
总结一下,我们在重构前要有足够的业务思考,重构中要备份足够的技术深度和业务复杂度解决方案,重构后的上线更是非常复杂。
后续主要分下面几个模块来细说:
1、项目脚手架:抽象业务公共能力
2、Mybatis的插件编写:解决SQL的租户id注入和语法检测
3、线程池环境下的ThreadLocal内存泄漏问题
4、性能监控工具
往期推荐
《互联网技术峰会》
《ArchSummit:从珍爱微服务框架看架构演进》
《ArchSummit_2022_全球架构峰会》
《2021年深圳ArchSummit全球架构师峰会》
《经典书籍》
《Java并发编程实战:第1章 多线程安全性与风险》
《Java并发编程实战:第2章 影响线程安全性的原子性和加锁机制》
《Java并发编程实战:第3章 助于线程安全的三剑客:final & volatile & 线程封闭》
《服务端技术栈》
《Docker 核心设计理念》
《Kafka原理总结》
《HTTP的前世今生》
《算法系列》
《读懂排序算法(一):冒泡&直接插入&选择比较》
《读懂排序算法(二):希尔排序算法》
《读懂排序算法(三):堆排序算法》
《读懂排序算法(四):归并算法》
《读懂排序算法(五):快速排序算法》
《读懂排序算法(六):二分查找算法》