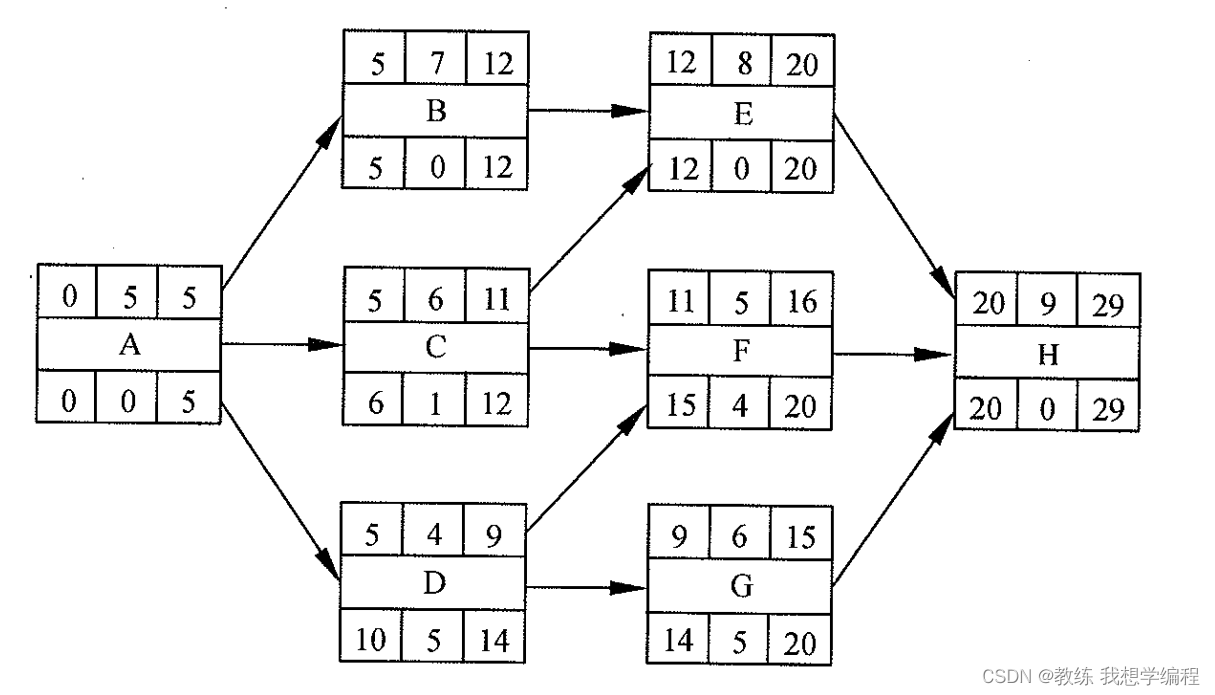
基础数据结构 & 架构设计 & 存储 & 集群
redis 简单来说其实就是一个基于内存的 key - value 数据库,它本身结构的前提就是 key - value 类似于 Java 中的 HashMap ,所以我们在聊 redis 的时候始终要记得这个前提,同时 redis 在执行读写操作命令时是串行执行的,这个特性使得 redis 可以用于实现分布式锁,同时因为是内存操作这个速度是极快的,并且以单线程执行也避免了线程切换所带来的消耗。
Redis 常用数据结构
String、Map、Set、List、ZSet (带权重的 Set 有点类似 Java 的 TreeSet)
redis 由 C 语言实现在底层 String 是自定义的数据结构 sds
struct sdshdr{
int len;
int free;
char buf[];
}
对于 redis 来说,存储空间的节省十分重要,所以,在优化设计上下了很多功夫,在 3.2 版本之后 sds 区分了多个长度的版本
struct sdshdr5{
unsigned char flags; /* 前 3 位标识类型, 后 5 位标识长度 */
char buf[];
}
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
........
对于 redis 来说,其整体就是一个 hashtable ,通过哈希函数对于到相应的槽位,本质就是一个对象数组,同样使用拉链法解决哈希碰撞问题。
同时会准备两个 ht[2] 方便来进行数据的扩容以及搬运。这个搬运过程是分散的。
数组中存储对于的 value 的数据。
对于 List 的实现,redis 同样做了优化,如果直接使用 链表来在进行构建,那么可能会出现胖指针的问题(即数据占用内存很小维持数据所需要的指针占用内存却很大),提供了 zplist 即 quicklist 双端链表 + zplist 的结合实现,quicklist 就是带有双向指针的链表,不过元素是 zplist
zplist 是 redis 自定义的数据结构,其意在于使用连续的一组空间表示一组数据。entry 定义了 prerawlen 和 len 来标识寻找前一个元素、自身和后一个元素。

zset 的实现是 dict 字典(即 hashtable) + 跳表实现
Redis 持久化
RDB 和 AOF 以及 混合持久化
RDB 快照
save 60 1000 // 60s 1000 个键发生了改变后同步 RDB
RDB 是 Redis 默认的一种持久化方式,当时间段内累计的键值改动达到配置值时会触发 RDB 持久化,Redis 提供了 bgsave 写时复制的能力,即在不阻塞读写的同时进行持久化,RDB 存储的是二进制字节码文件,每次同步都会将 Redis 内存的全部数据生成新的 RDB 快照替换原来的快照,RDB 恢复速度较快,但是容易丢失一部分数据。
AOF appand only file
不同于 RDB, AOF 是将每次执行的指令进行了存储,是一个极其安全的持久化方式,其恢复是根据 AOF 备份的指令进行指令重放。
可以配置每个命令都 flush 到 aof 文件,或者每秒刷一次。其安全性高,但是恢复数据的速度较慢
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
AOF 可以对其存储的指令重写,优化掉键值得某些无限中间过程直接执行结果,这样可以优化恢复数据时重新执行指令的时间
auto‐aof‐rewrite‐min‐size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就
很快,重写的意义不大
auto‐aof‐rewrite‐percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
混合持久化 4.0 开始支持
即结合 RDB 和 AOF 两种方式,AOF 在重写是不是优化指令,而是优化为 RDB 快照。在恢复时先载入快照数据,然后执行剩余的指令。
这样的结合即保证了安全性也提供了较快的恢复速度。
Redis 集群
主从
主从模式,一主一从,一主多从,主从模式可以分散服务的读数据压力,写数据仍由主节点负责。是最简单的一种集群模式。
主节点我们称其为 master 节点,从节点为 slave 。
数据同步:
对于首次与 master 建立长连接的 slave 节点,slave 会向主节点发生 PSYNC 命令,请求复制全量数据,这时主节点会执行 bgsave 将内存数据打包成为 rdb 文件进行持久化,在持久化期间新的可能引发数据变更的命令,主节点会记录在内存缓存中。
持久化完成后将全量 rdb 文件发送给 slave 节点,slave 将接收到的文件数据持久化生成 rdb 文件,然后加载到内存中。主节点在将期间缓存的数据变更指令同步给从节点,此时主从建立长连接,将持续同步后续的数据变更。达到主从数据一致。
当 slave 节点与主节点断连后会自动重新连接,如果主节点同时收到多个 slave 的连接请求 PSYNC 时,主节点不会进行多次的 bgsave ,会合并为一次,然后将这份 rdb 文件数据转发给多个并行的连接。
一般来说在主从断线重连后会进行数据的全量复制,但在 2.8 版本之后支持了 PSYNC 的断点续传功能,在一定的数据时效范围内可以进行断点续传,主从节点会记录 master 主进程 id 以及数据偏移 id ,重连后将从偏移 id 进行一个数据的续传,如果进程 id 发生变化或者 offset 太旧则会进行全量复制。
优点:
- 较单一 redis 服务可以分散集群读数据压力
- 多从节点备份,提高了数据存储的安全性
不足:
- 主节点宕机,整个集群将不可用,无法自动恢复,需要手动指定主节点
- 主从复制期间如果发生主节点宕机将丢失部分数据
- 只有一个主节点,服务的写入能力和存储能力将大大受限
- 过多的从节点可能会导致复制风暴(可以通过给 slave 下挂载 slave 来缓解主从复制风暴)
哨兵
哨兵模式是对主从模式主节点宕机无法自动恢复的一种补正,此模式下需要部署一个哨兵集群,其功能类似于服务注册与发现中心,客户端可以通过哨兵主节点发现 redis 服务,以及更新 redis 服务节点地址,同时对于主从 redis 服务进行监控,当主节点宕机后可以进行重新选主的操作。
集群(推荐)
集群模式是我们开发搭建大型服务项目最常用的,也是最推荐的,其支持主节点宕机自动选主,以及多个主节点同时提供写服务以分散数据写入以及数据存储压力,可以平滑扩容,(是基于 hash 算法,不同的 key hash 到不同的 master 节点中)
集群模式下,会将数据分为 16384 个槽位,每个主节点都会分配部分槽位,在操作键值时会进行槽位的计算,逻辑为:
hash-slot = crc16(key) % 16384
集群通信:
集群维护集群元数据的通信方式有两种:集中式通信和 gossip 协议通信,默认的 redis 集群采用 gossip 协议进行通信
元数据是指:集群节点信息,节点数量,主从角色,各节点共享信息等
集中式通信类似于很多中间件的元数据中心,所有的元数据信息集中在一个点上,优点是时效性好,可以快速感知,不足是所有元数据更新集中在一个点上,可能会导致元数据的存储压力。
gossip 协议包含多种消息,比如
meet :某节点给新节点发送,让新节点加入集群并进行集群通信
ping: 每个节点会频繁给其他节点发送 ping 消息,并且附带自身的元数据信息,集群节点间通过 ping 消息进行数据同步
pong: 对 ping 和 meet 的回复,同时附带自己的 元数据信息。也可以进行信息广播和更新
fail: 某个节点判断其他节点宕机后像集群发送 fail 同步该节点宕机的信息
gossip 优点在于是分散存储,信息是一步一步同步扩散到整个集群的,可能会存在一些延迟,但是集群的存储压力较小。
集群选主:
- slave 节点发现自己的 master 节点宕机
- 本机记录的 currentEpoch + 1 ,广播发送 FAILOVER_AUTH_REQUEST
- 其他 master 会响应该消息,并对于每个 epoch 只 ack 一次该消息
- slave 收到半数以上的 FAILOVER_AUTH_ACK 时会成为新的主节点并发送 pong 消息广播
建议
集群 master 个数最少三个,建议奇数个,slave 同样如此
选举过半机制防止集群脑裂。
注意集群的批量操作仅限于 key 可以落到同一个 slot 上的情况。如果非要有多个不同 key 进行批量操作,可以在 key 前面加 {xxx} 这样在计算 hash 槽时只会使用大括号中的值。
管道 Pipeline 和 Lua 脚本
简单说一下,pipeline 是同时提交多个 redis 命令,并且统一等待回复,这个好处仅在于减少多个命令和 redis 服务的通信,单各个命令的执行情况相互独立。
Lua 脚本是 redis 提供的非常强大的功能,其具备原子性可以替代 redis 的事务的功能。在事务上强烈建议使用 Lua 脚本。




![[电商实时数仓] 用户行为数据和业务数据采集以及ODS层](https://img-blog.csdnimg.cn/8d5a0268932544fc995056ee36f0d513.png)