尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的架构类/设计类的场景题:
1.说说分库分表的基因算法?
2.大厂常用的基因算法,是如何设计的?
3.百亿级分片,如何设计基因算法?
最近有小伙伴在面试美团,又遇到这一个问题。小伙伴支支吾吾的说了几句,卒。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V171版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,回复:领电子书
分库分表背景知识
问题1:为什么分库分表?
大家都知道,当一个表(比如订单表) 达到500万条或2GB时,需要考虑水平分表。
为啥? 读写并发高场景,单服务器单一数据库CPU、内存、网络IO压力大。
所以,需要分库,一个库拆成多个库。
同时,数据量大,单表存不下,需要分表,一张表拆分成多个表。
总之,分库分表的原因是:
-
数据量大,选分表;
-
并发高,选分库;
-
海量存储+高并发,分库+分表。
具体实操,请参考尼恩的硬核架构视频
问题2:如何做数据库水平拆分?
分库和分表, 主要还是 对数据的水平拆分,对数据的垂直拆分的重要程度弱太多,所以这个不做介绍。
水平分片又称为横向拆分。
相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。
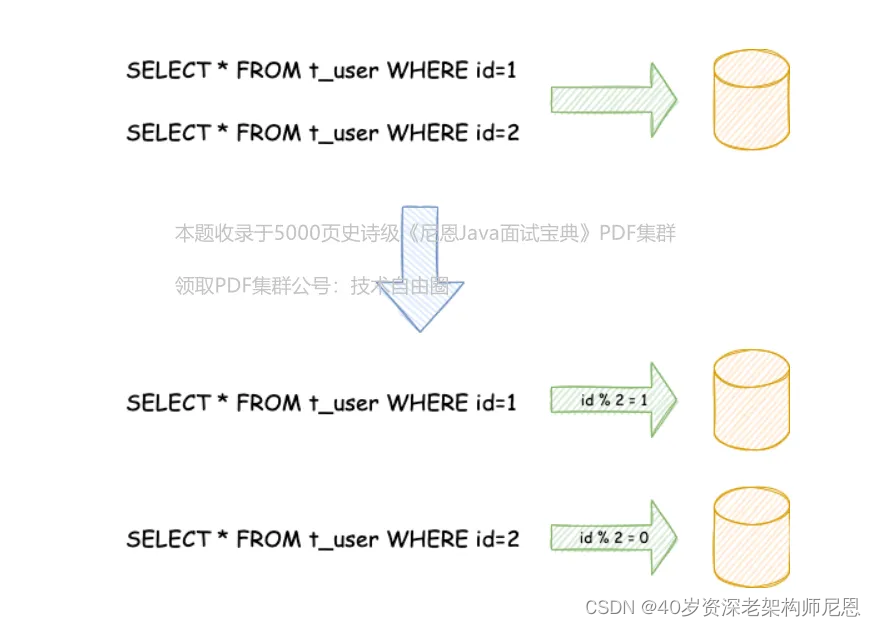
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
对数据的水平拆分 ,核心的设计是:
- 1: 用哪个字段拆分表,
- 2: 用什么路由策略寻找目标库表。
分片键的设计目标、建议
数据库水平拆分的字段叫分片键。分片键也称为 Sharding key
关于分片键的选择,我们需要选择具有共性的字段是最基本的要求,也是就尽量能覆盖绝大多数查询场景。
同时分片键也应具有足够庞大的基数以及唯一性,从而使 Shard 可灵活规划,具备较好的扩展性。
举个反例,如果选取布尔类型的字段为分片键,那么分片最多只能存在两份,这就陷入了非常尴尬的局面,基本失去了 Sharding 的意义。
如何做 Sharding key的设计呢?
-
最常见的情况是:用表的单个字段做分片键,
-
复杂情况是:可以用两个或多个字段组合成分片键。
Sharding key的设计目标:
合理选择 Sharding key,避免大多数的查询变成重量级操作,比如:
- 跨库查询
- 全表路由
40岁老架构师尼恩的建议是:
- 合理选择 Sharding key, 尽一切可能减少 全表路由、跨库查询,
- 从而使得大部分查询在 单库实现结果闭环,从而减少 多库之间大的数据合并和二次排序, 从而提升分库分表的吞吐量和性能。
分片键的设计建议:
- 选择具有共性的字段作为分片键,即查询中高频出现的条件字段;
- 分片字段应具有高度离散的特点,分片键的内容不能被更新;
- 可均匀各分片的数据存储和读写压力,避免片内出现热点数据;
- 尽量减少单次查询所涉及的分片数量,降低数据库压力;
- 最后,不要更换分片键,更换分片键需重分布数据,代价较大。
分片键的设计原则
-
选择查询频率最高的字段
分片键要能覆盖绝大多数查询场景,它决定了数据查询的效率。
正例:单号,id,时间字段
反例:姓别、商品类别
-
分片键不可以更新
分片键如果更新了,按原来的路由算法会计算出不同的库表地址,旧的数据无法正确读取
-
分片键不可以更换
分片键更换,意味着数据要重新分布,代价昂贵。
-
分片字段应有离散特性
分片键越离散,越容易把数据均匀分布在不同库表。
分片键的设计方案
按分片键的查询可以直接定位到目标库表,那么不按分片键的查询,是否只能遍历所有库表了呢?
举例:
-
电商领域有用户表和订单表。
-
订单表按订单号分库分表,
-
同时订单表有用户id字段。
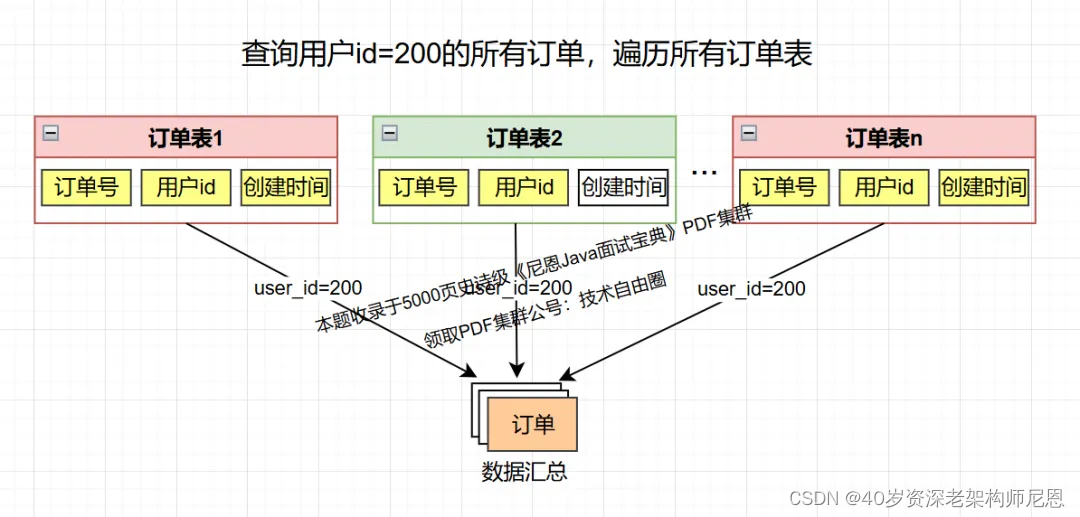
假如查询某个用户(比如user-id=200)的订单,怎么查呢?
此时,如果无法预知这个用户的数据存在订单的哪个库表,那么,其实就需要走 全表路由, 把请求路由到 这个表的所有的数据分片。
全表路由 具体如下图所示:
前面讲到,Sharding key的设计目标:
合理选择 Sharding key,避免大多数的查询变成重量级操作,比如:
- 跨库查询
- 全表路由
合理选择 Sharding key, 尽一切可能减少 全表路由、跨库查询, 从而使得大部分查询在 单库实现结果闭环,从而减少 多库之间大的数据合并和二次排序, 从而提升分库分表的吞吐量和性能。
如何去掉这里的 全表路由,提升查询效率呢?
针对这种非分片键的查询,有几种设计思路提升查询效率:
1 索引法
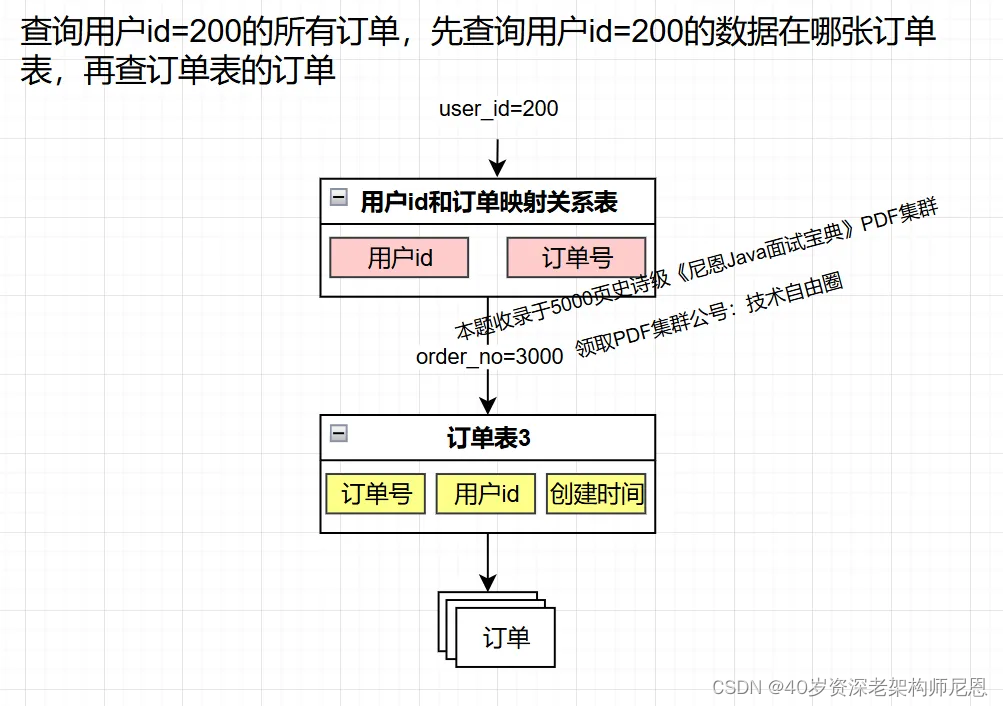
索引法的思路是,把非分片键和分片键的映射关系保存起来,
查询数据时,先从这个映射关系查找分片键,再用分片键路由到目标库表。
-
索引表
额外建一张表保存订单号和用户id的映射关系。
优点:实现简单
缺点:
-
查询数据多查一次索引表,性能低。
-
索引表可能会很大,甚至索引表本身要分表。
缓存映射关系
尼恩的3高架构宇宙中,有一条亘古不变的天条: 性能不够,缓存来凑。
既然索引表性能低,那么 用Redis保存订单号和用户id的映射关系。
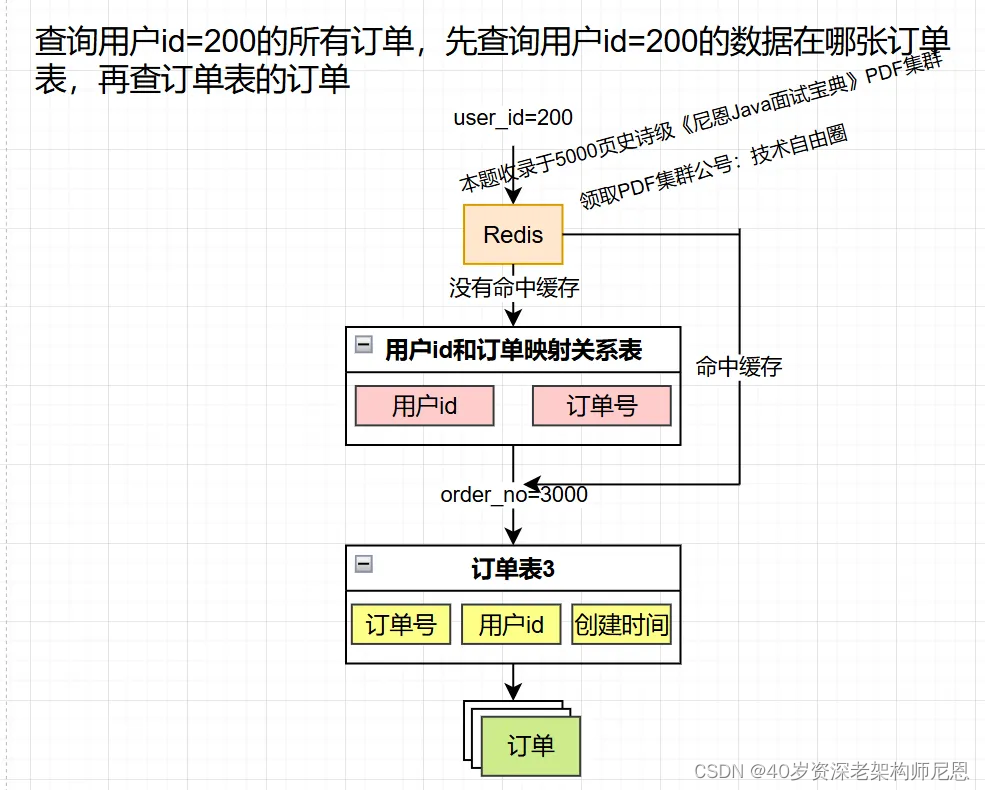
优点:查询速度比索引表快。
缺点:数据量大时,占用大量内存,缓存不断淘汰,命中率低,没有命中缓存还是得查索引表。
无论是用索引表还是用Redis,都无法在大数据量下有效查找分片键。
2 基因法
基因法的思路是,把非分片键到分片键的映射关系内嵌在非分片键字段,嵌入到非分片键的这部分内容就是基因。
基因法是大厂常常使用的方案,
比如,将买家 ID 融入到订单 ID 中,作为订单 ID 后缀。这样,指定买家的所有订单就会与其订单在同一分片内了,如下图所示。
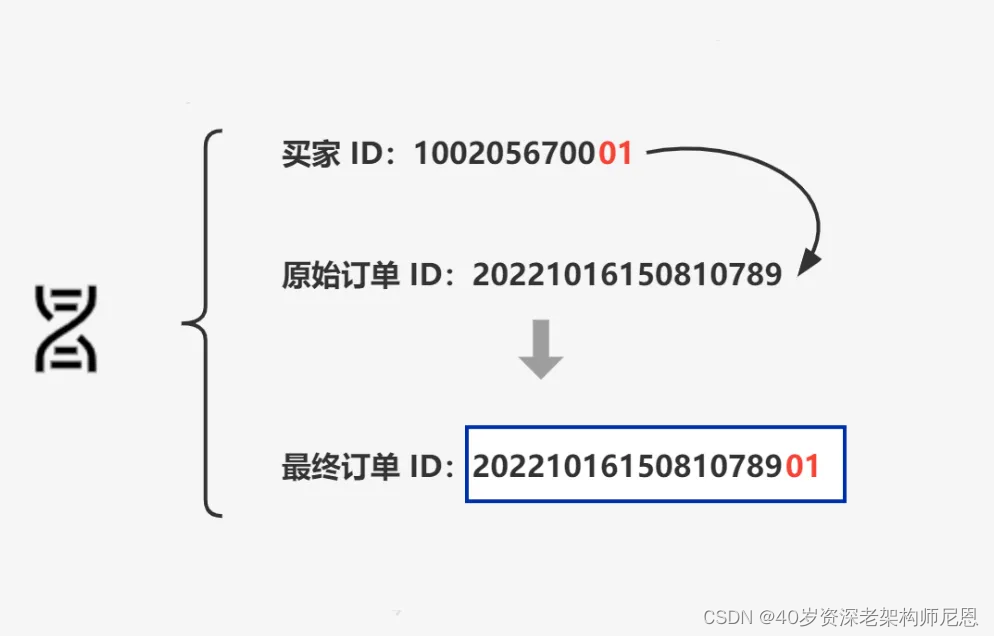
再具体一点:
-
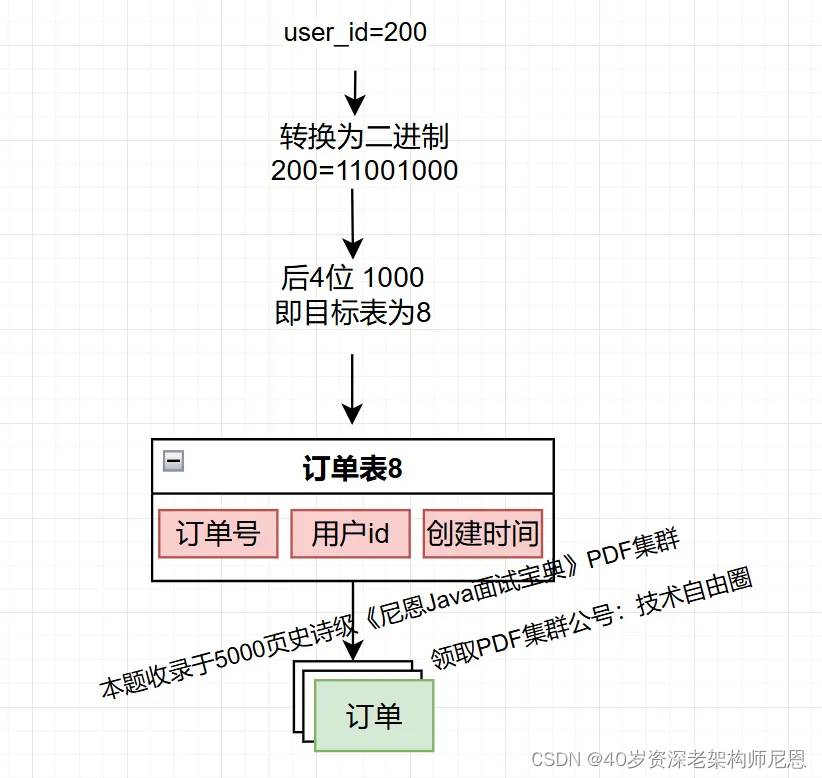
假如订单表用订单号%16路由,分16库表。
-
用户下单生成订单号时,订单号的最后4个bit位,通过位运算,设置为用户id的最后4bit位,那么,订单号的最后4个bit位就是订单号的用户基因。
此情此景,如果在 查询某个用户的订单,就不用全表路由了。
现在是单片路由,直接根据用户id的最后4bit位,路由到订单的目标库表。
3 基因法的理论基础
如果对一个10进制的数字按10取模,取模的结果只与这个数字最后1位有关:
199%10=9
19999%10=9
1234567899%10=9
同理,按100(10^2)取模,取模的结果只与这个数字最后2位有关:
199%100=99
19999%100=99
1234567899%100=99
同理,一个二进制的数字,按2^n取模,只与这个数字最后n位有关:
例:n=3,2^3=1000
10001111%(1000)=111, 即十进制的143%8=7
10011111%(1000)=111, 即十进制的159%8=7
因此,订单表用订单号%16分库分表,对16(2^4)取模的结果只和二进制订单号的最后4位有关,这4位决定了数据落在哪个库表上。
4 数字类型的分片键设计
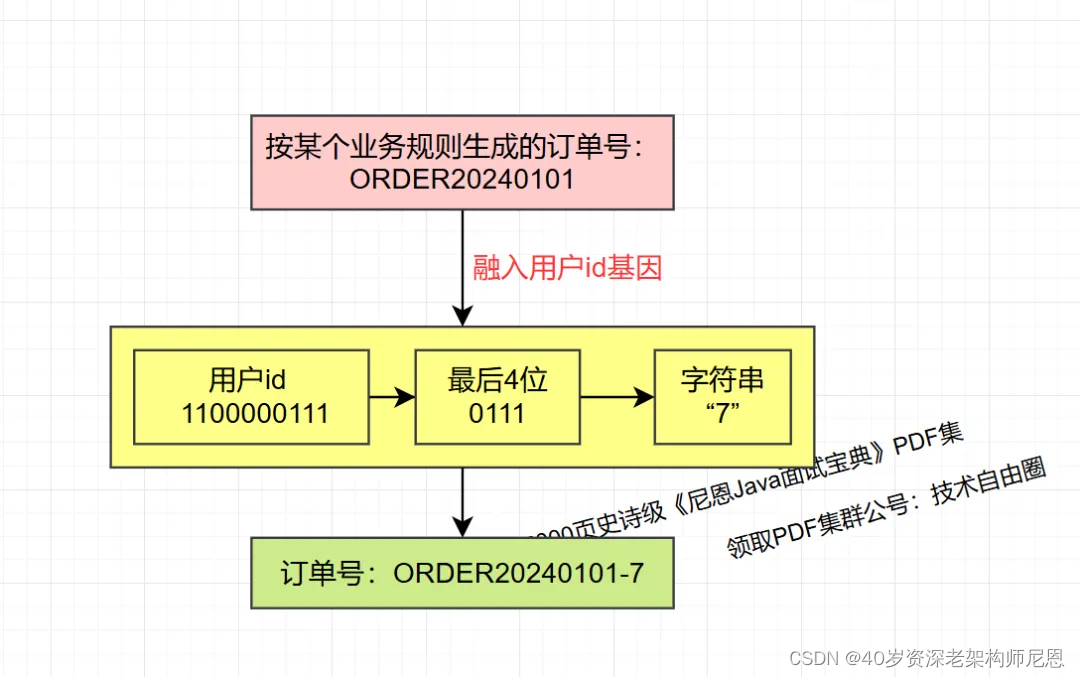
假如订单号是雪花算法生成的long类型数字,要在雪花算法的64个bit位中预留4位,用uid的后4位填充。

5 字符串类型分片键设计
假如订单号是一个字符串,将uid后4bit位转为字符串后拼接在订单号后面即可。
按某个业务规则生成的订单号:ORDER20240101
带有uid基因的订单号:ORDER20240101-0,ORDER20240101-15
6 基因法的优缺点:
-
优点:无论按照分片键还是按某个非分片键查数据,都可以直接定位到目标库表,性能比索引法高。
-
缺点:需要提前规划好库表容量,不方便扩容。
扩展方案设计:多个非分片键的组合查询
基因法解决了单个非分片键的数据查询路由问题,减少了全表路由的出现。
但是,如果有多个非分片键查询,是否要在分片键中融入多个基因呢?
No。
分片键的设计不应过于复杂,况且,即使能融入多个基因,又如何支持多个非分片键组合条件查询呢?
数据库不支持任意字段任意组合的高性能查询,这不是数据库的长项,应该用ES、ClickHouse等其他中间件来解决这类问题。
具体方案,请参见尼恩的文章:
字节面试:百亿级存储,怎么设计?只是分库分表?
说在最后:有问题找老架构取经
分库分表问题是高频问题,面试的时候如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典》V174,在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来帮扶、领路。
- 大龄男的最佳出路是 架构+ 管理
- 大龄女的最佳出路是 DPM,
女程序员如何成为DPM,请参见:
DPM (双栖)陪跑,助力小白一步登天,升格 产品经理+研发经理
领跑模式,尼恩已经指导了大量的就业困难的小伙伴上岸。
前段时间,领跑一个40岁+就业困难小伙伴拿到了一个年薪100W的offer,小伙伴实现了 逆天改命。
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓







![[消息队列 Kafka] Kafka 架构组件及其特性(二)Producer原理](https://img-blog.csdnimg.cn/direct/9ff2841fead74eefb58df0111529e074.png)