C++青少年简明教程:C++函数
C++函数是一段可重复使用的代码,用于执行特定的任务,可以提高代码的可读性和可维护性。函数可以接受参数(输入)并返回一个值(输出),也可以没有参数和返回值。
按函数是否由系统定义:分为库函数(系统函数)和自定义函数。
C++ 标准库提供了大量的程序可以调用的内置函数。例如,函数 strcat() 用来连接两个字符串,函数 memcpy() 用来复制内存到另一个位置。
本文重点介绍自定义函数。
函数定义(Function Definition)格式
<返回类型> <函数名>(<参数列表>)
{
函数体,执行具体的操作
}
函数定义包括函数的返回类型、名称、参数列表和函数体。
参数列表包括函数接受的参数的类型和名称。可以有零个或多个参数,每个参数由类型和名称组成,并用逗号分隔。
对于C++,main 函数(是程序的入口点)的类型必须是 int。对于自定义函数,函数类型可以是任何类型,包括 void(表示没有返回值)和其他基本数据类型(如 int、float 等等)。如果函数有返回值,则必须在函数体中使用 return 语句返回相应类型的值。在函数体中使用 return 语句时会将程序的执行控制权返回到调用该函数的地方,接着执行调用该函数的语句后面的代码。对于void类型的自定义函数,可以省略 return 语句或者使用“ return;”语句显式地表示函数的结束。
在C++中,函数声明(函数原型声明)是指在使用函数之前提供函数原型的过程。它包括函数的名称、参数列表和返回类型的描述,用于告诉编译器如何调用该函数。当函数的实现位于调用它的代码之后时,你需要提前声明这个函数,告诉编译器这个函数存在。C++函数头文件通常包含函数声明,以便在其他文件中引用和使用这些函数。
函数声明的一般形式为:
返回类型 函数名(参数列表);
例如:
int add(int a, int b); // 声明一个名为 add 的函数,它接受两个 int 类型的参数并返回一个 int 类型的值
【在C++中,用关键字extern可以进行函数声明,但这不是必须的,例如,“extern int add(int a, int b);”。在C++中,如果没有函数体的函数声明,通常都被认为是extern的。
对于函数声明,可以省略参数名,只保留参数类型。所以int js(int n);和int js(int);是等价的。】
函数声明和函数的定义在形式上的区别函数声明没有函数体。函数定义:
int add(int a, int b) {
return a + b; // 实现 add 函数,返回两个参数的和
}
函数声明是指提供函数原型的过程,用于告诉编译器有一个函数的存在和基本信息;而函数定义是给出函数具体实现的过程,包括函数头和函数体,用于描述函数的行为和实现。
函数调用(Function Call):
当你想在程序中使用函数时,你会"调用"它。调用函数时,你需要提供必要的参数(如果有的话)——实参。例如:
add(5, 3);
函数的形参和实参
函数的形参(形式参数)是在函数定义中声明的参数,它们用来接受函数调用时传递的实参值。形参在函数执行时起到的是占位符的作用,它们的值在函数调用时由相应的实参传递进来。
函数的实参(实际参数)是在函数调用中传递给函数的值或变量。实参可以是常量、变量、表达式、函数返回值等。当函数被调用时,实参的值被传递给形参,函数将使用这些值进行运算或处理,并可能返回一个结果。
例子:
#include <iostream>
using namespace std;
// 函数声明
int add(int a, int b);
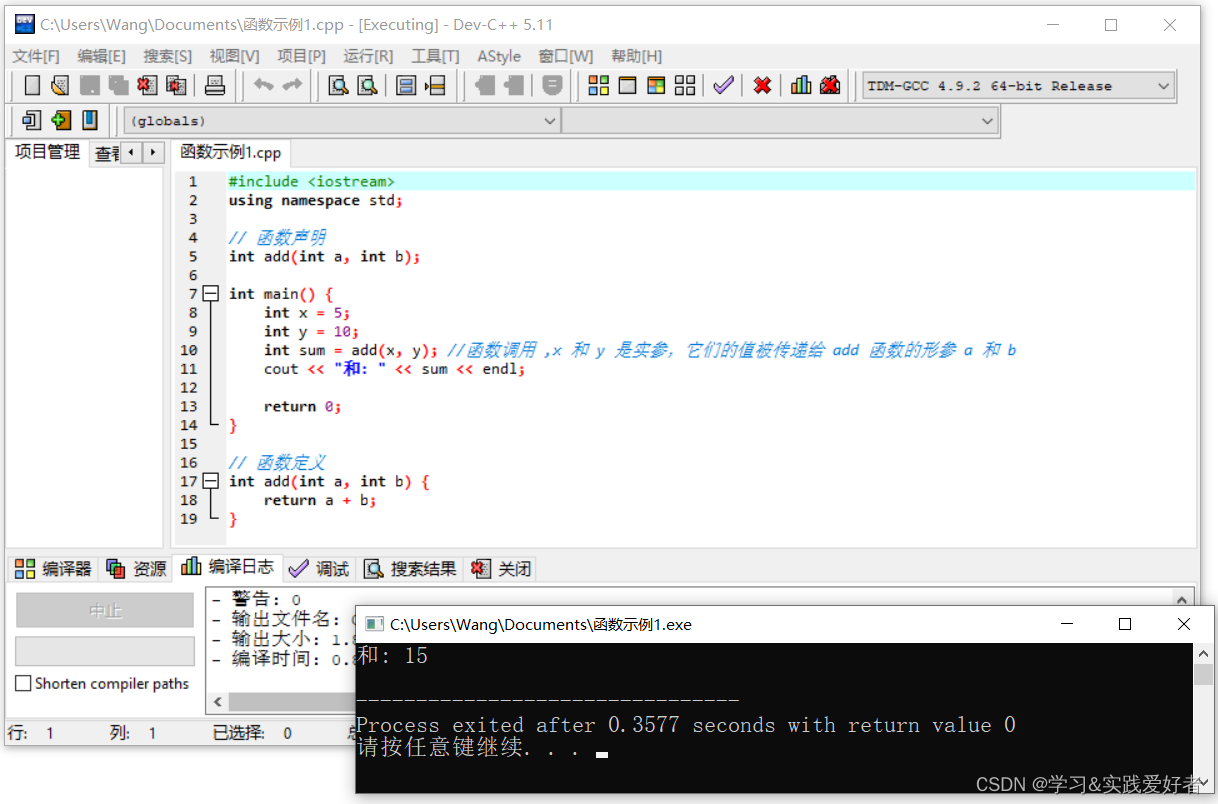
int main() {
int x = 5;
int y = 10;
int sum = add(x, y); //函数调用 ,x 和 y 是实参,它们的值被传递给 add 函数的形参 a 和 b
cout << "和: " << sum << endl;
return 0;
}
// 函数定义
int add(int a, int b) {
return a + b;
}
运行效果:
函数声明(Function Declaration)和函数定义(Function Definition)是两个不同的概念。
函数声明告诉编译器函数的名称、返回类型以及它接受哪些参数。但它不包含函数的实际代码。函数声明通常出现在函数被调用之前,以便编译器知道函数的存在和它的签名(即它的参数和返回类型)。
函数定义提供了函数的实际代码,即函数体。它包含了函数如何执行其任务的详细信息。函数定义也可以被视为函数的完整签名加上函数体。
函数定义中的函数名、返回类型以及参数列表必须与相应的函数声明完全匹配(除了某些特殊情况,如内联函数或模板函数)
在大型程序中,通常将函数声明放在头文件中,而函数定义放在源文件中。这样,其他源文件可以通过包含相应的头文件来使用该函数。
函数调用(Function Call)是执行已定义函数的方式。函数调用时,程序将控制权交给函数,并在函数执行完毕后返回。函数调用作为语句、表达式和参数的使用示例:
#include <iostream>
using namespace std;
int add(int a, int b) {
return a + b;
}
void printMessage() {
cout << "Hello, World!" << endl;
}
void displayResult(int result) {
cout << "Result: " << result << endl;
}
int main() {
printMessage(); // 作为语句
int sum = add(5, 3); // 作为表达式的一部分
displayResult(sum); // 作为参数传递
displayResult(add(2, 2)); // 嵌套使用:作为参数传递时作为表达式的一部分
return 0;
}
输出结果:
Hello, World!
Result: 8
Result: 4
C++函数参数的传递方式
函数参数传递是指在函数调用时,将实际参数(也称为实参)的值或引用传递给函数的形式参数(也称为形参)的过程。在C++中,当调用一个函数时,你需要提供与函数声明中指定的形参类型和数量相匹配的实参。这些实参可以是变量、常量、表达式或字面值等。
当调用函数时,传递参数的方式有:
1. 值传递(Pass by Value)/传值
将实参的值复制一份传给形参,在函数内对形参进行操作,不会影响到实参。在这种情况下,修改函数内的形式参数对实际参数没有影响。
#include <iostream>
using namespace std;
void add(int a, int b) {
cout << "a + b = " << a + b << endl;
}
int main() {
int x = 5, y = 10;
add(x, y); // 值传递方式调用函数
return 0;
}
2. 引用传递(Pass by Reference)/传地址
将实参的地址传递给形参,在函数内对形参进行操作,就是直接对实参操作。这意味着,修改形式参数会影响实际参数。
#include <iostream>
using namespace std;
void increment(int &num) {
num++; // 修改 num 的值
}
int main() {
int a = 5;
increment(a); // 引用传递方式调用函数
cout << "a = " << a << endl; // 输出 a 的值
return 0;
}
需要注意的是,在使用引用传递方式时,要确保传递的实参是一个变量而非常量或表达式的值。例如,以下代码是无效的:
increment(2 + 3); // 无法编译通过,因为2 + 3不是一个变量
3. 指针传递(Pass by Pointer)/传指针
指针传递(Pass by Pointer)通过传递指向实参的指针,让函数能够访问和修改实参的值。这意味着,修改形式参数会影响实际参数。关于指针以后介绍。
#include <iostream>
using namespace std;
void increment(int* ptr) {
(*ptr)++; // 修改 *ptr 所指向的变量的值
}
int main() {
int a = 5;
int* ptr = &a;
increment(ptr); // 通过指针传递实参
cout << "a = " << a << endl; // 输出 a 的值
return 0;
}
在 increment 函数中,通过解引用运算符 (*ptr) 访问了实参 a 的值,并对其进行了修改。在 main 函数中,定义了整型变量 a 和指向 a 的指针 ptr,将 ptr 作为参数通过指针传递给了 increment 函数。最后输出了 a 的值,结果为 6。
提示:引用传递和指针传递都是将实参的地址传递给形参。不同的是,引用传递使用了引用类型,而指针传递使用了指针类型。在函数内部,引用和指针都可以用于访问和修改实参的值。具体一点说,通过引用传递,函数形参会成为实参的别名,即形参与实参指向同一块内存空间,在函数内部对形参的修改会直接反映在实参上。通过指针传递,实际参数的地址被复制到指针形参中,通过解引用指针可以访问和修改实参的值。
在大多数情况下,引用传递比值传递需要更少的内存,并更有效。传递指针也是一种传递地址的方式,但是引用更容易使用,并且更不容易出错。
函数参数的默认值
在C++编程中,在定义函数时,可以为函数参数设置默认值。如果在调用函数时未传递参数,则使用默认值。例如:
#include <iostream>
using namespace std;
int sum(int a, int b = 6 ){
return ( a + b );
}
int main (){
// 局部变量声明
int a = 10;
int b = 20;
int result;
// 调用函数计算和
result = sum(a, b);
cout << "sum = " << result << endl; //sum = 30
// 再次调用函数
result = sum(a);
cout << "sum = " << result << endl; //sum = 16
return 0;
}
C++变量的作用域
C++中变量的作用域是指变量在程序中能够被访问到的范围。按变量的作用域可以将变量分为:
局部变量:变量在某个函数内部定义,只能在该函数内部访问,称为局部变量。
下面是使用了局部变量的例子:
#include <iostream>
using namespace std;
int main (){
// 局部变量声明
int a, b;
int c;
// 实际初始化
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}
全局变量:在所有函数外部定义的变量(通常是在程序的头部),称为全局变量。全局变量一旦声明,在整个程序中都是可用的。
下面是使用了全局变量的例子:
#include <iostream>
using namespace std;
//全局变量
int x = 20;
void func(){
int x = 10; //函数内部的局部变量
cout << "局部变量 x 的值为 : " << x << endl; //输出 10
cout << "全局变量 x 的值为 : " << ::x << endl; //输出 20
}
int main(){
cout << "初始全局变量 x 的值为 : " << x << endl; //输出 20
func(); //调用函数
cout << "调用函数后的全局变量 x 的值为 : " << x << endl; //输出 20
return 0;
}
示例中,定义了一个全局变量 x,它的值为 20。然后,在 func() 函数内定义了一个名称相同的局部变量 x,它的值为 10。当 func() 函数被调用时,它将输出局部变量 x 和全局变量 x 的值。从输出可以看出,程序优先使用函数内部的局部变量 x,而不是全局变量 x。如果需要使用或修改全局变量的值,则需要在函数中使用作用域解析运算符 :: 来引用全局变量。
在主函数中,我们首先输出全局变量 x 的值,然后调用函数 func()。在调用函数之后,我们再次输出全局变量 x 的值,以此证明函数内部对全局变量的修改并不会影响它的值。从输出可以看出,函数 func() 对全局变量 x 的修改并没有影响它的值,它的值仍然是 20。
练习、判断一个年份是否为闰年是一个常见的编程问题。闰年的规则是:
如果年份能被4整除但不能被100整除,则为闰年。
如果年份能被400整除,也是闰年。
以前(“If选择语句”一节中)提到过这个例子,现在采用自定义函数的方式实现,判断用户输入的年份是否为闰年:
#include <iostream>
using namespace std;
bool isLeapYear(int year) {
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {
return true;
} else {
return false;
}
}
int main() {
int year;
cout << "请输入一个年份: ";
cin >> year;
if (isLeapYear(year)) {
cout << year << " 是闰年." << endl;
} else {
cout << year << " 不是闰年." << endl;
}
return 0;
}
这个程序中,isLeapYear 函数接受一个整数年份作为参数,并返回一个布尔值,表示该年份是否为闰年。main 函数则负责获取用户输入的年份,并调用 isLeapYear 函数进行判断,然后输出相应的结果。
递归函数
在编程中,一个函数直接或间接地调用自身,函数称为递归函数,这种技术被称为递归。
递归函数通常包含两个部分:
基本情况(Base Case):这是递归的终止条件,即当函数达到某个条件时,它将不再调用自身,而是直接返回结果。没有基本情况,递归函数将会无限地调用自身,导致栈溢出错误。
递归步骤(Recursive Step):这是函数的主体部分,其中包含了将问题分解为更小子问题的逻辑,并调用自身(称为Recursive call:递归调用)来处理这些子问题。
简单地说,递归是一种函数调用自身的过程。递归函数或算法必须调用自身来解决规模更小的子问题。
我们可以使用一个例子来说明。比如,我们要计算从1到某个数n的总和。
1.我们可以创建一个自定义函数sum,它接受一个参数n,代表要计算总和的范围。
2.在函数内部,我们需要添加一些基本条件来结束递归。在这种情况下,如果n等于1,我们直接返回1。
3.如果n大于1,我们将函数自己调用,并传入n-1作为参数,并将结果与n相加。
4.这个过程会一直进行下去,直到n等于1,然后每个递归函数的返回值都会被加起来。
最后,我们只需调用这个函数并打印出结果即可。
#include <iostream>
using namespace std;
int sum(int n) {
if (n == 1) {
return 1;
}
else {
return n + sum(n - 1);
}
}
int main() {
int num = 5; // 假设我们要计算1到5的总和
int result = sum(num);
cout << "从1到" << num << "的总和为:" << result << endl;
return 0;
}
计算阶乘
阶乘(Factorial)是指将一个正整数 n 及小于等于 n 的所有正整数相乘的结果。符号通常用符号 "!" 表示。例如,4的阶乘(写作4!)是4*3*2*1=24。
C++函数来计算阶乘的函数:
int factorial(int n) {
if (n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}
这个函数的工作方式是这样的:
首先,它检查数字n是否为0。如果是,它返回1。这是因为0的阶乘被定义为1。
如果n不是0,那么函数会返回n乘以n-1的阶乘。这就是递归的部分:函数调用了自己,但是每次调用时,n都会减少1。
例如,如果我们调用factorial(4),函数会这样工作:
factorial(4)返回4 * factorial(3)
factorial(3)返回3 * factorial(2)
factorial(2)返回2 * factorial(1)
factorial(1)返回1 * factorial(0)
factorial(0)返回1
所以,factorial(3)的结果是4*3 * 2 * 1 * 1 = 24。
图示如下:

下面给出求一个数的阶乘完整代码
使用递归的完整代码:
#include <iostream>
using namespace std;
int factorial(int n) {
if (n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}
int main() {
int n;
cout << "请输入一个正整数: ";
cin >> n;
cout << "该数的阶乘为: " << factorial(n) << endl;
return 0;
}
这个递归示例中,函数名为 factorial,表示计算一个数的阶乘。当输入的参数 n 等于 0 时,是递归的基本情况,递归将结束并返回 1。当 n 不是 0 时,函数将调用自身并传入 n-1 作为参数,直到 n 等于 0。然后递归将回溯,并将每个递归调用返回的值合并,并返回给原始调用者。
作为对比,下面给出非递归实现的代码:
#include <iostream>
using namespace std;
int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}
int main() {
int n;
cout << "请输入一个正整数: ";
cin >> n;
cout << "该数的阶乘为: " << factorial(n) << endl;
return 0;
}
OK!
附、C++函数https://blog.csdn.net/cnds123/article/details/108917528