YOLOv8----seg实例分割(制作数据集,训练模型,预测结果)
内容如下:【需要软件及工具:pycharm、labelme、anaconda、云主机(跑训练)】
1.制作自己的数据集
2.在yolo的预训练模型的基础上再训练自己的模型
3.训练结束后,尝试预测图片的实体分割
1.制作数据集:
下载安装labelme:
$ conda create -n labelme python=3.8 #创建一个专门做数据集的虚拟环境
$ conda activate labelme #进入此虚拟环境
#下载并安装labelme以及依赖软件包
$ conda install pyqt
$ conda install pillow
$ pip install labelme
$ conda list #查看labelme有没有安装进去
$ labelme #直接在终端输入labelme即可进入labelme


可能遇到的问题:【CondaHTTPError: HTTP 000 CONNECTION FAILED for url】
解决方法:【修改国内源】
找到.condarc文件【一般位于C盘的user,主机用户的文件夹下】
替换成:
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
show_channel_urls: true
ssl_verify: false
安装好labelme之后,就可以开始制作数据集了:

【说明一下,创建矩形就是制作detect检测数据集,创建多边形就是制作segment实体分割数据集】
【制作好一幅图之后,点击保存,会在图片的同级目录下生成对应的JSON文件】
JSON文件生成之后,想要在YOLO中使用,得先转换成TXT模式:【代码如下】
1.detect数据集JSON转TXT
import json
import os
import pandas as pd
def convert(img_size, box):
x1 = box[0]
y1 = box[1]
x2 = box[2]
y2 = box[3]
return (x1, y1, x2, y2)
def decode_json(json_floder_path, json_name,label):
txt_name = r'' #转换后,TXT文件所在的文件夹目录
+ json_name[0:-5] + '.txt'
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
if i['shape_type'] == 'rectangle':
if (label['label'] != i['label']).all():
new_label=pd.DataFrame(columns=['label'], data=[i['label']])
label=label.append(new_label,ignore_index=True)
try:
x1 = float((i['points'][0][0])) / img_w
y1 = float((i['points'][0][1])) / img_h
x2 = float((i['points'][1][0])) / img_w
y2 = float((i['points'][1][1])) / img_h
n = label[label['label']==i['label']].index[0]
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(n) + " " + " ".join([str(a) for a in bbox]) + '\n')
except IndexError:
print(json_name[0:-5]+'的'+i['label']+"标签坐标缺失")
return label
if __name__ == "__main__":
json_floder_path = r''#JSON数据的文件夹
json_names = os.listdir(json_floder_path)
label= pd.DataFrame(columns = ['label'])
for json_name in json_names:
if json_name[-4:]=='json':
print(json_name)
label=decode_json(json_floder_path, json_name,label)
label.to_csv('label.txt', sep='\t', index=True)
2.segment数据集JSON转TXT
import json
import os
import glob
import os.path as osp
def labelme2yolov2Seg(jsonfilePath="", resultDirPath="", classList=["类别1","类别2"]):
"""
此函数用来将labelme软件标注好的数据集转换为yolo实体分割中使用的数据集
:param jsonfilePath: labelme标注好的*.json文件所在文件夹
:param resultDirPath: 转换好后的*.txt保存文件夹
:param classList: 数据集中的类别标签
:return:
"""
# 0.创建保存转换结果的文件夹
if (not os.path.exists(resultDirPath)):
os.mkdir(resultDirPath)
# 1.获取目录下所有的labelme标注好的Json文件,存入列表中
jsonfileList = glob.glob(osp.join(jsonfilePath, "*.json"))
print(jsonfileList) # 打印文件夹下的文件名称
# 2.遍历json文件,进行转换
for jsonfile in jsonfileList:
# 3. 打开json文件
with open(jsonfile, "r") as f:
file_in = json.load(f)
# 4. 读取文件中记录的所有标注目标
shapes = file_in["shapes"]
# 5. 使用图像名称创建一个txt文件,用来保存数据
with open(resultDirPath + "\\" + jsonfile.split("\\")[-1].replace(".json", ".txt"), "w") as file_handle:
# 6. 遍历shapes中的每个目标的轮廓
for shape in shapes:
# 7.根据json中目标的类别标签,从classList中寻找类别的ID,然后写入txt文件中
file_handle.writelines(str(classList.index(shape["label"])) + " ")
# 8. 遍历shape轮廓中的每个点,每个点要进行图像尺寸的缩放,即x/width, y/height
for point in shape["points"]:
x = point[0] / file_in["imageWidth"] # mask轮廓中一点的X坐标
y = point[1] / file_in["imageHeight"] # mask轮廓中一点的Y坐标
file_handle.writelines(str(x) + " " + str(y) + " ") # 写入mask轮廓点
# 9.每个物体一行数据,一个物体遍历完成后需要换行
file_handle.writelines("\n")
# 10.所有物体都遍历完,需要关闭文件
file_handle.close()
# 10.所有物体都遍历完,需要关闭文件
f.close()
if __name__ == "__main__":
jsonfilePath = "" # 要转换的json文件所在目录
resultDirPath = "" # 要生成的txt文件夹
labelme2yolov2Seg(jsonfilePath=jsonfilePath, resultDirPath=resultDirPath, classList=["类别1","类别2"]) # 更改为自己的类别名
转换好之后,创建一个这样的文件夹:【解释如下】
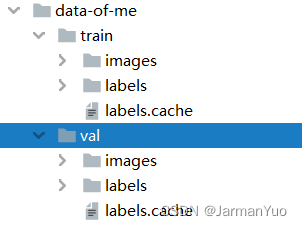
【train:训练所用的数据(包含图片,和图片所标注的数据集文件)】
【val:训练的时候,验证所用的数据,同样包含图片和类别坐标txt数据】
然后训练代码如下:【代码中的文件解释,在下面文章中紧随】
from ultralytics import YOLO
model = YOLO('yolov8-seg.yaml').load('yolov8x-seg.pt')#改成自己所放的位置
model.train(data='./datasets/coco128-seg.yaml',epochs=50,imgsz=640)
yolov8-seg.yaml

yolov8x-seg.pt【yolo代码GitHub官网下载的实例分割的预训练模型,一般直接放到根目录即可】
coco128-seg.yaml【注意:calss写的时候,要和labelme中你标注的时候创建的label序号对应上】
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco128.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco128-seg ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/yoloProject/ultralytics-registry/ultralytics/yolo/data-of-me # dataset root dir
train: train/images # train images (relative to 'path') 128 images
val: val/images # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: 类别1 #自己起名字
1: 类别2
OK,run完my_train.py后,就可以得到训练的结果:

然后,可以直接拿着weight文件夹下生成的两个模型进行预测【best,last顾名思义】
预测的时候,直接命令行、python脚本都可以:
1.命令行:yolo predict model=best.pt source=图片文件或所在文件夹
2.python代码:
from ultralytics import YOLO
# 读取模型,这里传入训练好的模型
model = YOLO('best.pt')
# 模型预测,save=True 的时候表示直接保存yolov8的预测结果
metrics = model.predict(['123.png'], save=True)
# 如果想自定义的处理预测结果可以这么操作,遍历每个预测结果分别的去处理
for m in metrics:
# 获取每个boxes的结果
box = m.boxes
# 获取box的位置,
xywh = box.xywh
# 获取预测的类别
cls = box.cls
print(box, xywh, cls)
预测结果:【控制台会输出存放路径】

补充:如果你想把框去掉,或者把label信息去掉不显示
找到yolo的cfg配置文件,找到prediction settings,然后想要啥,想去掉啥,随你

比如:
只要框:

只识别分割,别的啥都不要: