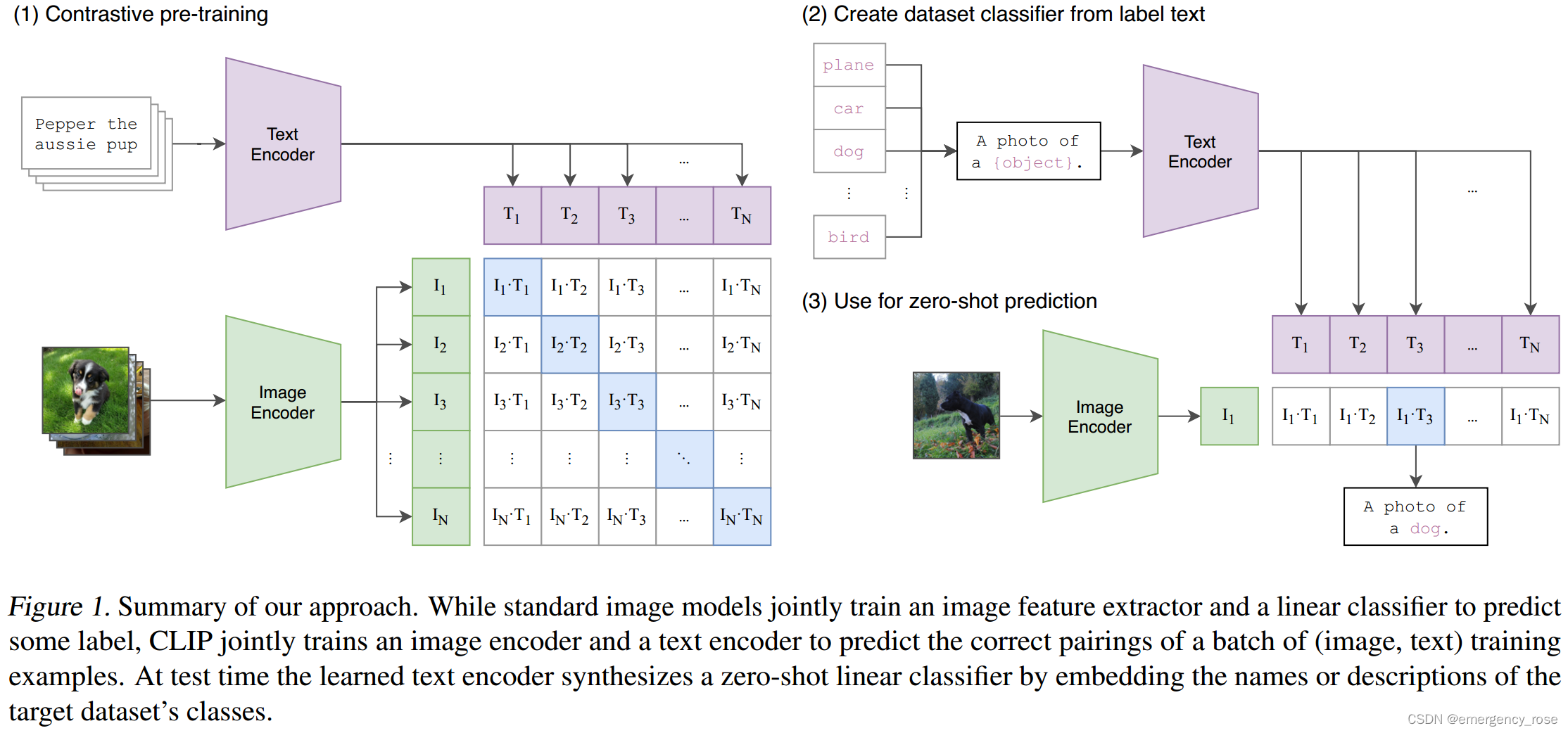
通过在4亿图像/文本对上训练文字和图片的匹配关系来预训练网络,可以学习到SOTA的图像特征。预训练模型可以用于下游任务的零样本学习

1、网络结构
1)simplified version of ConVIRT
2)linear projection to map from each encoder's representation to the multi-modal embedding space
3)image encoder
-> ResNet
antialiased rect-2 blur pooling
用attention pooling (single layer of "transformer-style" multi-head QKV attention, where the query is conditioned on the global average-pooled representation of the image)来代替global average pooling
-> Vision Transformer (ViT)
add an additional layer normalization to the combined patch
position embeddings before the transformer
slightly different initialization scheme
4)text encoder
-> Transformer
architecture modifications
63M-parameter 12 layer 512-wide model with 8 attention heads
lower-cased byte pair encoding (BPE) representation of the text with a 49152 vocab size
the max sequence length was capped at 76
the text sequence is bracketed with [SOS] and [EOS] tokens
the activations of the highest layer of the transformer at the [EOS] token are treated as the feature representation of the text which is layer normalized and then linearly projected into the multi-modal embedding space
5)scale
-> image encoder
equally increase the width, depth, and resolution of the model
-> text encoder
only scale the width of the model to be proportional to the calculated increase in width of the ResNet, do not scale the depth at all
* text encoder对CLIP的表现影响较小
2、数据
1)400 million (image, text) pairs from Internet
2)many of the (image, text) pairs are only a single sentence
3、训练
1)Contrastive Language-Image Pre-training (CLIP)
2)text as a whole, not the exact words of that text
3)Given a batch of N (image, text) pairs, predict N x N possible (image, text) pairings。N取32768
4)jointly train an image encoder and text encoder
5)maximize the cosine similarity of the real pairs; minimizing the cosine similarity of the
incorrect pairs
6)train from scratch
7)数据增强
random square crop from resized images
8)learnable temperature parameter (control the range of the logits in the softmax)
4、优势
无需softmax分类器来预测结果,因此可以更灵活的用于zero-shot任务