实验内容简介:
Spark是一个分布式计算框架,常用于大数据处理。本次实验中,首先设计一个包含主节点和从节点的Spark集群架构,并在CentOS的Linux环境下进行搭建。通过下载并解压Spark安装包,配置环境变量和集群参数,部署Spark集群。接着言编写Spark应用程序,并将其打包,通过spark-submit命令将应用程序提交到Spark集群中运行,观察任务分配和执行进度,验证集群的性能和正确性。
安装步骤:
1.安装下载文件
Spark安装包下载地址: http://spark.apache.org
进入以后点击左上角download
跳转到下载页面中,提供了几个下载选项,主要是Spark release及Package type的选择。
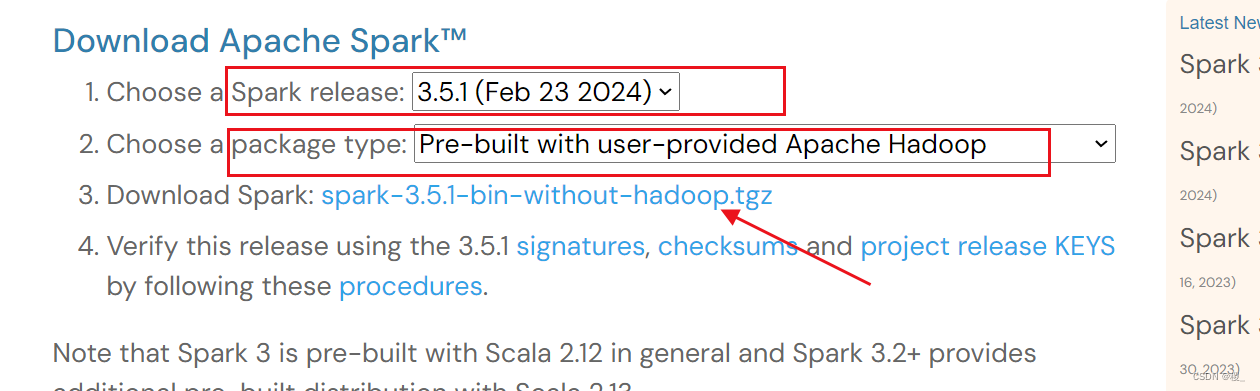
第1项Spark release一般默认选择最新的发行版本。
第2项package type则选择“Pre-build with user-provided Hadoop [can use with most Hadoopdistributions]”,可适用于多数Hadoop版本。
选择好之后,再点击第3项给出的链接就可以下载Spark了。跳转后再次点击链接即可。
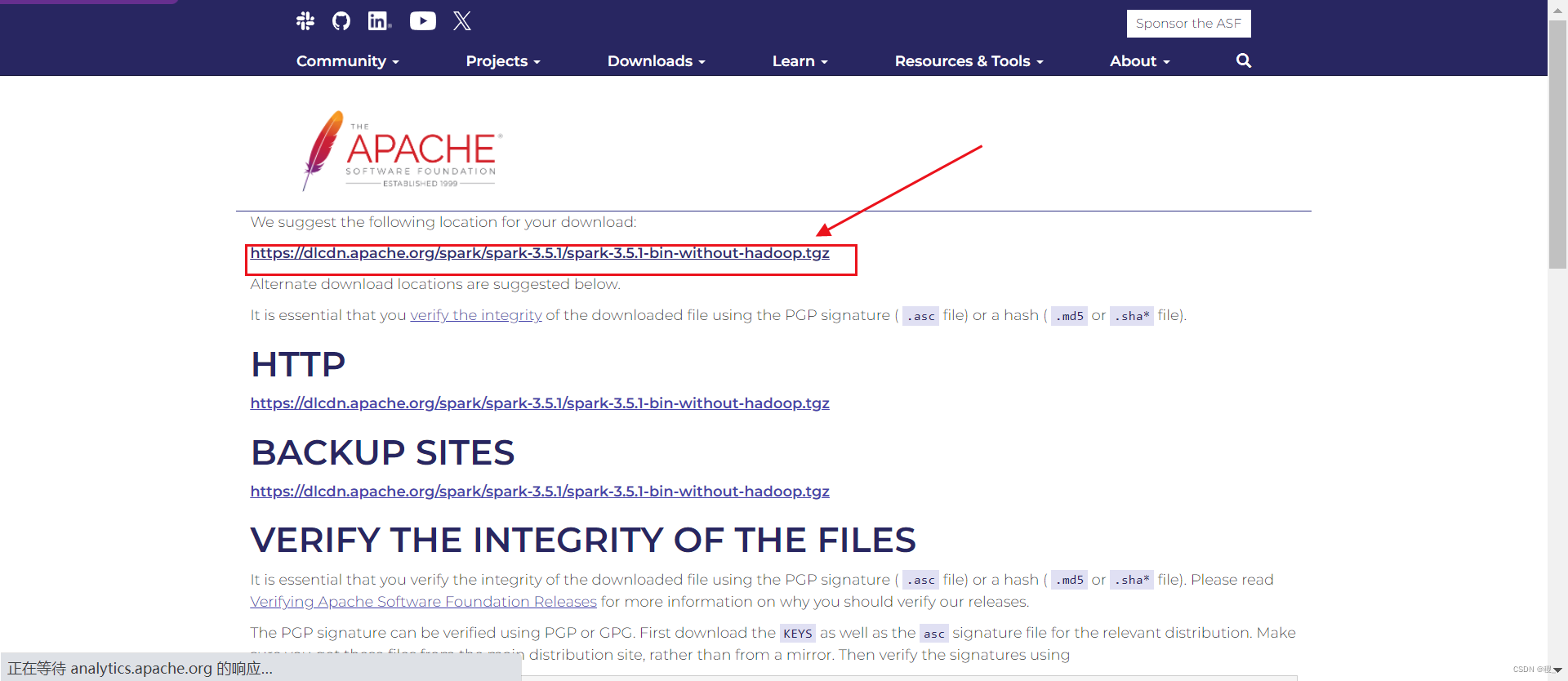
2.
 等待下载......
等待下载......
3.下载完成通过rz上传到虚拟机
下图操作在集群的主机zkpk用户下执行

4.在用户zkpk的目录下,试图解压但无权限
[zkpk@scala00 ~]$ sudo tar -zxf ~/spark-3.5.1-bin-without-hadoop.tgz -C /usr/local/
We trust you have received the usual lecture from the local System Administrator. It usually boils down to these three things: #1) Respect the privacy of others. #2) Think before you type. #3) With great power comes great responsibility.
[sudo] password for zkpk: zkpk is not in the sudoers file. This incident will be reported.
用户 zkpk 没有在系统的 sudoers 文件中,因此没有权限使用 sudo 命令。sudo 允许用户以超级用户(或其他用户)的权限执行命令。要解决这个问题,需要以具有 sudo 权限的用户(通常是 root 用户)身份登录,并编辑 sudoers 文件来添加 zkpk 用户。
于是,在root用户下,执行命令:visudo
找到类似下图的地方
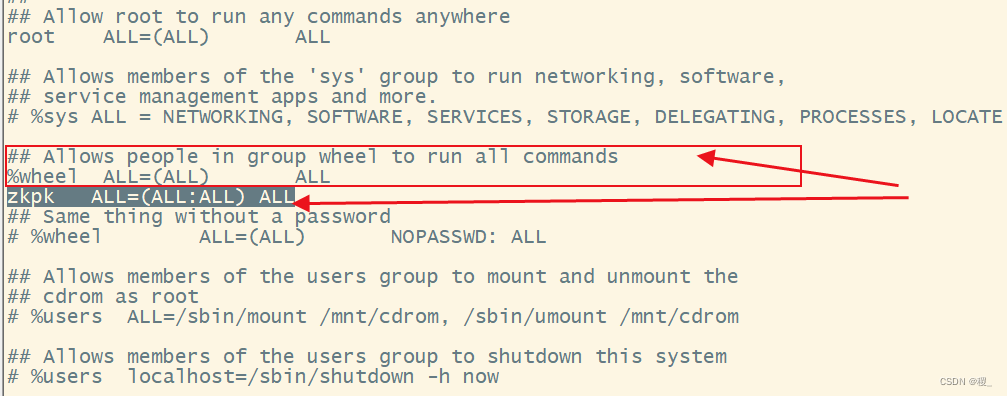
添加zkpk ALL=(ALL:ALL) ALL使得zkpk 用户有 sudo 权限
保存好,切换回root用户下
5.继续解压
解压安装包spark-3.5.1-bin-without-hadoop.tgz至路径/usr/local:
$ sudo tar -zxf ~/spark-3.5.1-bin-without-hadoop.tgz -C /usr/local/
$ cd /usr/local
$ sudo mv ./spark-3.5.1-bin-without-hadoop/ ./spark # 更改文件夹名,改为spark
$ sudo chown -R zkpk ./spark #更改用户名zkpk

6.配置class path
由于已经遗忘路径,通过以下方式查找
[zkpk@scala00 bin]$ pwd
/home/zkpk/hadoop-3.1.3/bin
[zkpk@scala00 bin]$ /home/zkpk/hadoop-3.1.3/bin/hadoop classpath
/home/zkpk/hadoop-3.1.3/etc/hadoop:/home/zkpk/hadoop-3.1.3/share/hadoop/common/lib/*:/home/zkpk/hadoop-3.1.3/share/hadoop/common/*:/home/zkpk/hadoop-3.1.3/share/hadoop/hdfs:/home/zkpk/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/home/zkpk/hadoop-3.1.3/share/hadoop/hdfs/*:/home/zkpk/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/home/zkpk/hadoop-3.1.3/share/hadoop/mapreduce/*:/home/zkpk/hadoop-3.1.3/share/hadoop/yarn:/home/zkpk/hadoop-3.1.3/share/hadoop/yarn/lib/*:/home/zkpk/hadoop-3.1.3/share/hadoop/yarn/*
指定 Spark 应用程序在运行时需要的额外的类路径(classpath)是
export SPARK_DIST_CLASSPATH=$(/home/zkpk/hadoop-3.1.3/bin/hadoop classpath)
命令会执行 hadoop classpath 命令,并将输出的完整 classpath 赋值给 SPARK_DIST_CLASSPATH 环境变量。
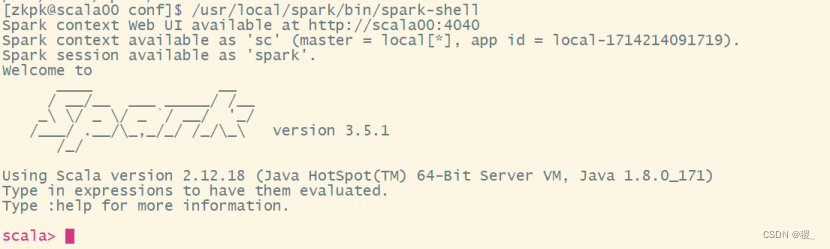
7.启动sparkshell成功
8.Spark部署模式
Local 模式:单机模式
Standalone模式: Spark 自己的集群管理器
YARN 模式:使用YARN 作为集群管理器
Mesos 模式:使用Mesos作为集群管理器
Spark Shell 提供了简单的方式使用Spark API
Spark Shell 以实时、交互的方式来分析数据
Spark Shell 支持Scala和Python 一个Driver就包括main方法和分布式数据集
Spark Shell本身就是一个Driver,里面已经包含了main方法