香橙派Orange AI Pro / 华为昇腾310芯片 部署自己训练的yolov8模型进行中国象棋识别
- 一、香橙派简介
- 1.1、香橙派 AI Pro 硬件资源介绍
- 1.2、华为昇腾310(Ascend310) 简介
- 1.3、 昇腾310AI能力和CANN 简介
- 昇腾310 NPU简介
- 二、远程环境配置
- 2.1、ssh
- 2.2、vnc
- 三、香橙派Orange AI Pro安装pytorch并运行yolov8
- 使用conda安装虚拟环境
- 环境配置
- 代码下载
- 推理图片
- 推理usb摄像头
- 四、香橙派Orange AI Pro使用昇腾310 npu和cann 部署加速yolov8
- 4.1、增加swap 交换内存
- 4.2、设置设备编译进程数CPU核数(可选)
- 4.4、编译安装acllite
- 设置Ascend环境变量
- 下载ascend官方示例代码
- 编译acllite
- 4.5、yolov8 pt 模型转onnx模型
- 4.6、yolov8 onnx模型转换om模型
- 4.7、使用华为昇腾 npu推理加速运行自己训练的yolov8模型——python代码
- 代码
- 安装依赖
- 运行效果图
- 4.7 使用华为昇腾npu运行自己训练的yolov8模型——C++部署
- 下载ascend官方示例代码
- 修改sampleYOLOV8.cpp后处理代码
- 编译运行
- 五、其他开发环境安装
- 5.1、香橙派Orange AI Pro / 华为昇腾310 使用源码方式安装opencv 4.9.0
- 六、可能出现的错误
- 6.1、转换模型出现BrokenPipeError: [Errno 32] Broken pipe
- 6.2、 晟腾 onnx转换到om模型报错 /usr/local/Ascend/ascend-toolkit/latest/bin/atc: line 17: 7998 Aborted (core dumped) P K G P A T H / b i n / a t c . b i n " {PKG_PATH}/bin/atc.bin " PKGPATH/bin/atc.bin"@"
- 6.3、 python 推理 晟腾npu模型报错 ModuleNotFoundError: No module named 'IPython'
- 6.4、 运行om模型报错: RuntimeError: [-1][ACL: general failure]
- 6.5、 使用opencv 4.5 运行dnn 读取yolov8 onnx 模型,报错[ERROR:0] global
- 6.6、 fatal error: opencv2/opencv.hpp: No such file or directory
- 6.7、fatal error: AclLiteUtils.h: No such file or directory
- 6.8、编译acllite 报错: Can not find INSTALL_DIR env
- 七、昇腾芯片常用命令
- 基础信息查看命令
- 查看npu,AI core以及cpu的资源情况
- 将远程文件复制到本地
- AI CPU和Control CPU切换
- 八、 使用总结
- 香橙派Ai pro的优点
- 香橙派Ai pro的不足
- 参考文章
官方参考资料:
在香橙派官网可以下载到OrangePi AIpro的相关资料,其中包括用户手册,
1、官网地址:香橙派官网
2、昇腾论坛:香橙派AIpro学习资源一站式导航
3、orangepi 论坛:http://forum.orangepi.cn/
4、升腾官方 深度学习示例源码库:https://gitee.com/ascend/samples
一、香橙派简介
香橙派(Orange Pi)是深圳市迅龙软件有限公司旗下开源产品品牌,香橙派AIpro开发板采用昇腾AI技术路线,接口丰富且具有强大的可扩展性,提供8/20TOPS澎湃算力,可广泛使用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理等AI领域。通过昇腾CANN软件栈的AI编程接口,可满足大多数AI算法原型验证、推理应用开发的需求。该产品搭载的是华为昇腾310芯片。
而昇腾310主打高能效、灵活可编程,参数如下
- 16TOPS@INT8, 8TOPS@FP16
- 功耗8W
- 华为自研达芬奇架构
- 12nm FFC工艺
1.1、香橙派 AI Pro 硬件资源介绍

1.2、华为昇腾310(Ascend310) 简介
Ascend310 AI处理器逻辑架构昇腾AI处理器的主要架构组成:芯片系统控制CPU(Control CPU)AI计算引擎(包括AI Core和AI CPU)多层级的片上系统缓存(Cache)或缓冲区(Buffer)数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等AI Core:集成了2个AI Core。
Ascend310 AI处理器规格:
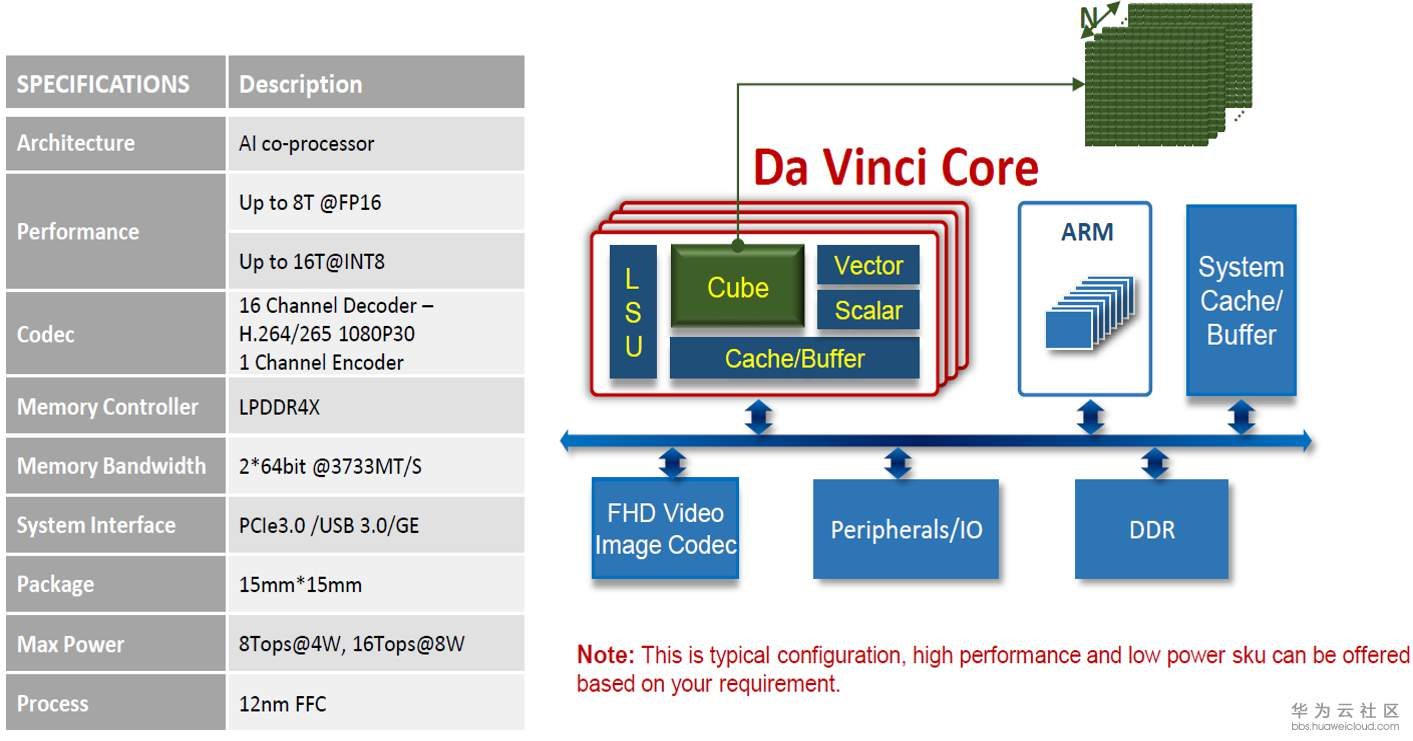
昇腾 310,高能效比推理型 AI 处理器,基于达芬奇架构,本质上是一块 SoC,集 成了多个运算单元,包括 CPU(8 个 a55)、AI Core、数字视觉预处理子系统等。除了 CPU 之外,该芯片真正的算力担当是采用了达芬奇架构的 AI Core。这些 AI Core 通过 特别设计的架构和电路实现了高通量、大算力和低功耗,特别适合处理深度学习中神经 网络必须的常用计算。目前该芯片能对整型数(INT8、INT4) 或对浮点数(FP16)提 供强大的算力。根据海思官网披露,该芯片 FP16 算力为 8TOPS,INT8 算力 16TOPS, 采用 12nm 工艺制造。
Ascend310 AI处理器逻辑架构:
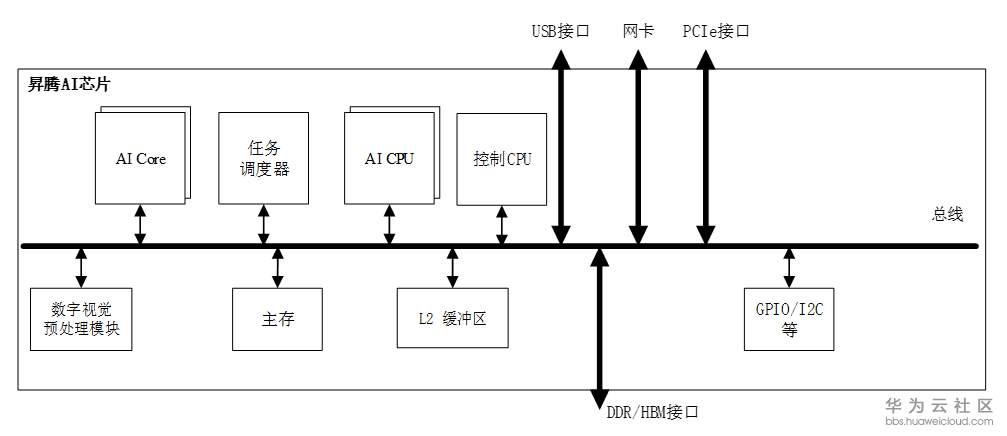
昇腾AI处理器的主要架构组成:
-
芯片系统控制CPU(Control CPU)
-
AI计算引擎(包括AI Core和AI CPU)
-
多层级的片上系统缓存(Cache)或缓冲区(Buffer)
-
数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等
-
AI Core:集成了2个AI Core。昇腾AI芯片的计算核心,主要负责执行矩阵、向量、标量计算密集的算子任务,采用达芬奇架构。
-
ARM CPU核心: 集成了8个A55。其中一部分部署为AI CPU,负责执行不适合跑在AI Core上的算子(承担非矩阵类复杂计算);一部分部署为专用于控制芯片整体运行的控制CPU。两类任务占用的CPU核数可由软件根据系统实际运行情况动态分配。此外,还部署了一个专用CPU作为任务调度器(Task Scheduler,TS),以实现计算任务在AI Core上的高效分配和调度;该CPU专门服务于AI Core和AI CPU,不承担任何其他的事务和工作。
-
DVPP:数字视觉预处理子系统,完成图像视频的编解码。用于将从网络或终端设备获得的视觉数据,进行预处理以实现格式和精度转换等要求,之后提供给AI计算引擎。
-
Cache & Buffer:SOC片内有层次化的memory结构,AI core内部有两级memory buffer,SOC片上还有8MB L2 buffer,专用于AI Core、AI CPU,提供高带宽、低延迟的memory访问。芯片还集成了LPDDR4x控制器,为芯片提供更大容量的DDR内存。
-
对外接口:支持PCIE3.0、RGMII、USB3.0等高速接口、以及GPIO、UART、I2C、SPI等低速接口。
昇腾AI处理器特点:
-
昇腾AI处理器集成了多个ARM公司的CPU核心,每个核心都有独立的L1和L2缓存,所有核心共享一个片上L3缓存。集成的CPU核心按照功能可以划分为专用于控制芯片整体运行的主控CPU 和专用于承担非矩阵类复杂计算的AI CPU。两类任务占用的CPU核数可由软件根据系统实际运行情况动态分配。
-
除了CPU之外,该芯片真正的算力担当是采用了达芬奇架构的AI Core。这些AI Core通过特别设计的架构和电路实现了高通量、大算力和低功耗,特别适合处理深度学习中神经网络必须的常用计算如矩阵相乘等。目前该芯片能对整型数(INT8、INT4) 或对浮点数(FP16)提供强大的乘加计算力。由于采用了模块化的设计,可以很方便的通过叠加模块的方法提高后续芯片的计算力。
-
针对深度神经网络参数量大、中间值多的特点,该芯片还特意为AI计算引擎配备了容量为8MB的片上缓冲区(On-Chip Buffer),提供高带宽、低延迟、高效率的数据交换和访问。能够快速访问到所需的数据对于提高神经网络算法的整体性能至关重要,同时将大量需要复用的中间数据缓存在片上对于降低系统整体功耗意义重大。为了能够实现计算任务在AI Core上的高效分配和调度,还特意配备了一个专用CPU作为任务调度器(Task Scheduler,TS)。该CPU专门服务于AI Core和AI CPU,而不承担任何其他的事务和工作。
-
数字视觉预处理模块主要完成图像视频的编解码,支持4K分辨率,视频处理,对图像支持JPEG和PNG等格式的处理。来自主机端存储器或网络的视频和图像数据,在进入昇腾AI芯片的计算引擎处理之前,需要生成满足处理要求的输入格式、分辨率等,因此需要调用数字视觉预处理模块进行预处理以实现格式和精度转换等要求。数字视觉预处理模块主要实现视频解码(Video Decoder,VDEC),视频编码(Video Encoder,VENC),JPEG编解码(JPEG Decoder/Encoder,JPEGD/E),PNG解码(PNG Decoder,PNGD)和视觉预处理(Vision Pre-Processing Core,VPC)等功能。图像预处理可以完成对输入图像的上/下采样、裁剪、色调转换等多种功能。数字视觉预处理模块采用了专用定制电路的方式来实现高效率的图像处理功能,对应于每一种不同的功能都会设计一个相应的硬件电路模块来完成计算工作。在数字视觉预处理模块收到图像视频处理任务后,会读取需要处理的图像视频数据并分发到内部对应的处理模块进行处理,待处理完成后将数据写回到内存中。
1.3、 昇腾310AI能力和CANN 简介
一颗昇腾310芯片可以实现高达16T的现场算力,支持同时识别包括人、物体、交通标志、障碍物在内的两百个不同目标,一秒钟可处理上千张图片,无论在急速行驶的汽车上还是高速运转的生产线,无论是复杂的科学研究还是日常教育活动,昇腾310可以为各行各业提供触手可及的高效算力。
CANN(Compute Architecture for Neural Networks)异构计算架构,是以提升用户开发效率和释放昇腾AI处理器极致算力为目标,专门面向AI场景的异构计算架构。对上支持主流前端框架,向下对用户屏蔽系列化芯片的硬件差异,以全场景、低门槛、高性能的优势,满足用户全方位的人工智能诉求。CANN通过Plugin适配层,能轻松承接基于不同框架开发的AI模型,将不同框架定义的模型转换成标准化的Ascend IR(Intermediate Representation)表达的图格式,屏蔽框架差异。
算子在硬件上的加速计算构成了加速神经网络的基础和核心。目前CANN提供了1200+种深度优化的、硬件亲和的算子,正是如此丰富的高性能算子,筑起了澎湃的算力源泉,让你的神经网络「瞬时」加速。
- NN(Neural Network)算子库:CANN覆盖了包括TensorFlow、Pytorch、MindSpore、ONNX框架在内的,常用深度学习算法的计算类型,在CANN所有的算子中占有最大比重,用户只需要关注算法细节的实现,大部分情况下不需要自己开发和调试算子。
- BLAS(Basic Linear Algebra Subprograms)算子库:BLAS为基础线性代数程序集,是进行向量和矩阵等基本线性代数操作的数值库,CANN支持通用的矩阵乘和基础的Max、Min、Sum、乘加等运算。
- DVPP(Digital Video Pre-Processor)算子库:提供高性能的视频编解码、图片编解码、图像裁剪缩放等预处理能力。
- AIPP(AI Pre-Processing)算子库:主要实现改变图像尺寸、色域转换(转换图像格式)、减均值/乘系数(图像归一化),并与模型推理过程融合,以满足推理输入要求。
- HCCL(Huawei Collective Communication Library)算子库:主要提供单机多卡以及多机多卡间的Broadcast,allreduce,reducescatter,allgather等集合通信功能,在分布式训练中提供高效的数据传输能力。
昇腾310 NPU简介
Ascend 310处理器,可以高效地在端侧部署典型的深度学习推理应用。以下是昇腾310的主要特点:
- 高效能低功耗: 昇腾310采用7nm工艺制造,拥有高效的能耗比,能够在提供强大计算能力的同时保持较低的功耗,非常适合嵌入式和边缘计算应用。
- 强大计算能力: 昇腾310能够提供多达16 TOPS(Tera Operations Per Second)的整数计算能力和8 TFLOPS(Tera Floating Point Operations Per Second)的浮点计算能力,能够高效处理复杂的深度学习模型。
- 丰富的接口支持: 昇腾310支持多种接口,包括PCIe、I2C、UART等,方便与各种外设进行连接,适用于广泛的应用场景。
- 全场景AI支持: 昇腾310支持包括图像处理、语音识别、自然语言处理等多种AI任务,提供灵活的AI推理能力。
- 优秀的开发工具: 昇腾310配备了丰富的开发工具和软件生态,包括华为的MindSpore、TensorFlow、PyTorch等主流深度学习框架的支持,使开发者能够快速上手并进行模型训练和部署。
二、远程环境配置
我一般就直接
ssh HwHiAiUser@192.168.71.128
下面是更详细的步骤
2.1、ssh
获取香橙派ip地址
首先将显示器鼠标键盘接入香橙派,然后在终端输入ifconfig 查看ip地址。
ifconfig
然后在ubuntu主机使用Remmina远程香橙派,一般ubuntu自带 Remmina,如果没有 可以使用以下命令安装:
sudo apt install remmina remmina-plugin-rdp remmina-plugin-vnc
输入用户名和密码
默认用户名和密码如下
HwHiAiUser
Mind@123
成功进入
当然也可以之间在主机终端直接连接ssh
ssh HwHiAiUser@192.168.71.155
Mind@123
2.2、vnc
首先在香橙派上安装和设置vnc
sudo apt update
sudo apt install tightvncserver
配置密码
vncserver
配置开机启动
mv ~/.vnc/xstartup ~/.vnc/xstartup.bak
vim ~/.vnc/xstartup
然后输入
#!/bin/bash
xrdb $HOME/.Xresources
startxfce4 &
保存后给权限
sudo chmod +x ~/.vnc/xstartup
启动vnc
vncserver
关闭vnc
sudo systemctl stop vncserver@*
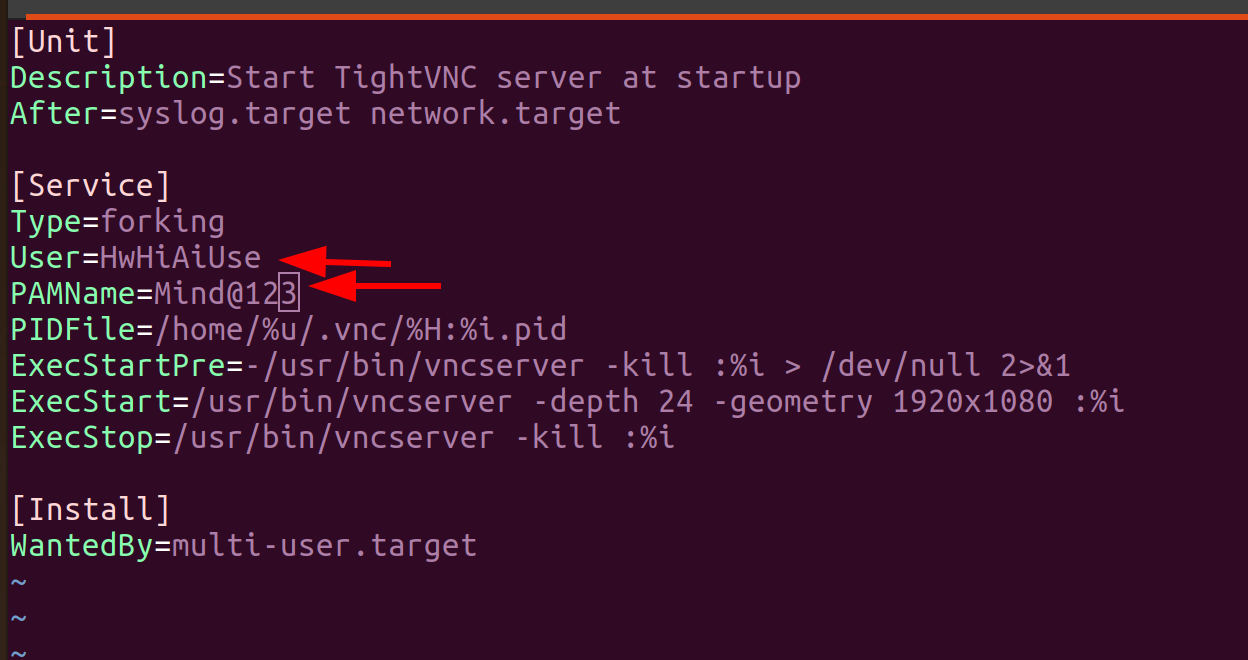
修改用户名和密码
sudo vim /etc/systemd/system/vncserver\@.service
然后在ubuntu主机打开Remmina的主界面中,点击“+”号图标来创建一个新的连接配置。配置如下:
注意端口号也要写,一般板子的第一个桌面连接是用5901端口。
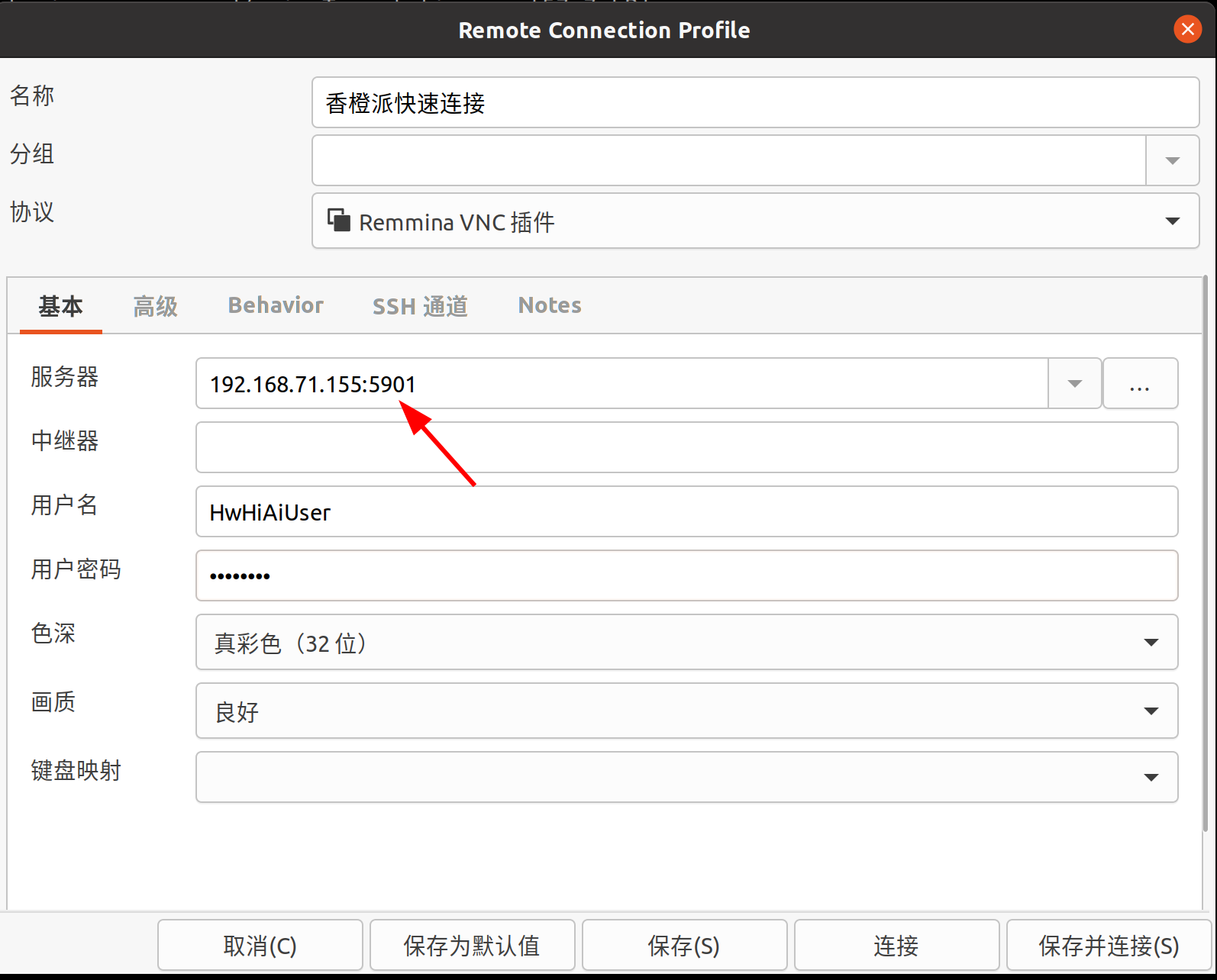
然后连接,成功!

三、香橙派Orange AI Pro安装pytorch并运行yolov8
使用conda安装虚拟环境
环境配置
其中requirements.txt 中包含了必要的配置环境:
基本如下:
3.10>=Python>=3.7
torch>=1.7.0
torchvision>=0.8.1
#创建虚拟环境
conda create --name pytorch python=3.8
conda activate pytorch
#安装ultralytics,可以直接使用yolo
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
测试环境是否配置成功:
import torch
print(torch.__version__)
a = torch.Tensor(5,3)
print(a)
代码下载
git clone https://github.com/ultralytics/ultralytics
推理图片
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
# model = YOLO("yolov8n.pt")
model = YOLO('./weights/24_0506_6541_yolov8x_1280.pt') # load a custom model
# Define path to the image file
source ="./images/*.jpg"
# Run inference on the source
results = model(source,show=True,save=True) # list of Results objects
推理usb摄像头
插入usb相机,然后查看是否插入成功

使用pytorch cpu版本 yolov8x模型 推理usb摄像头,命令如下:
yolo predict model=./weights/24_0506_6541_yolov8x_1280.pt source=0 show
耗时达到了恐怖的50s。
yolov8s也需要2s多。但是精度还是不错的,不过毕竟 Orange AI Pro 的成本低,ai推理肯定是需要C++和npu加速来部署。
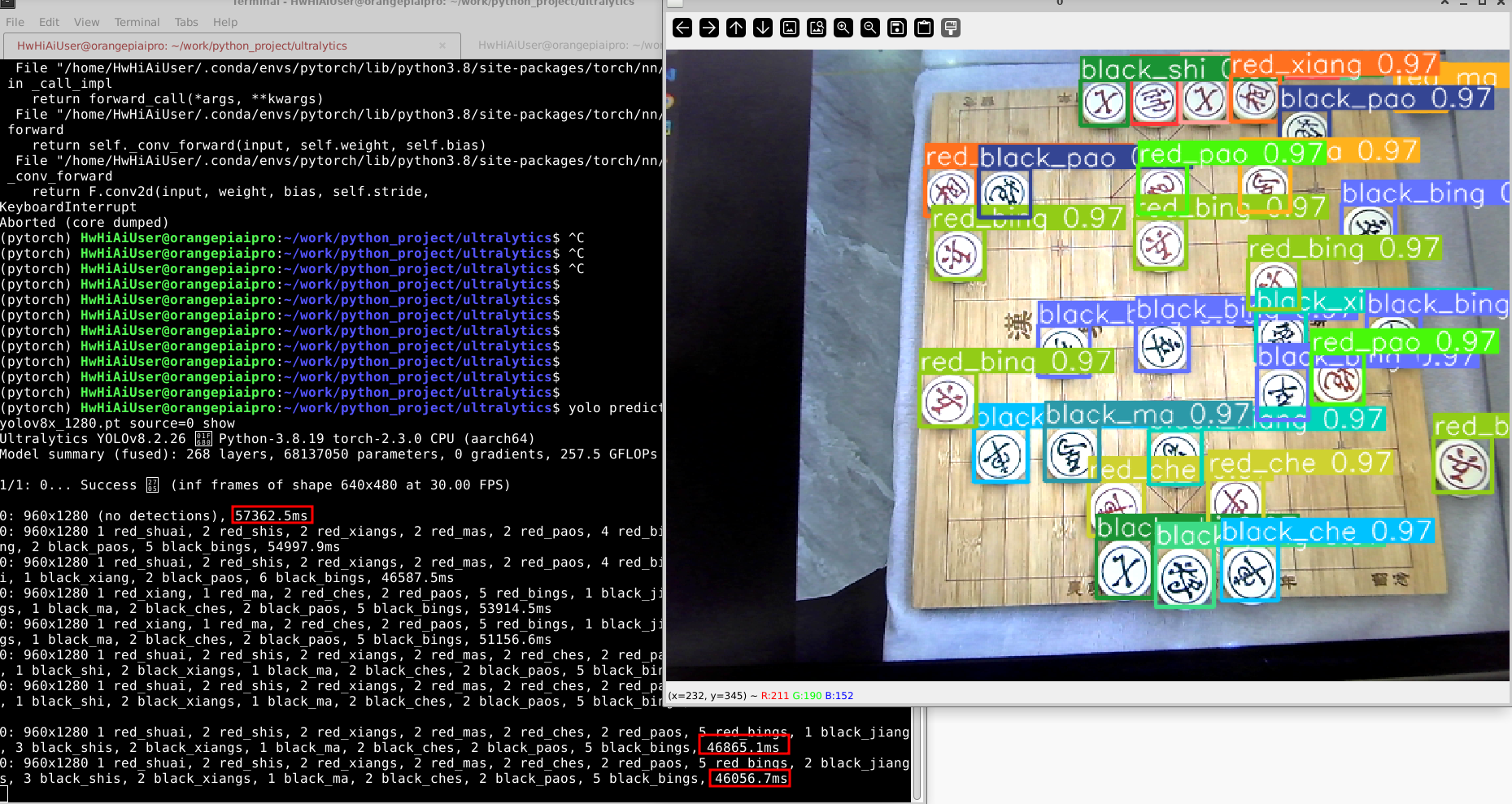
pytorch+cpu推理,虽然环境配置很方便,但是几乎没有实际使用的意义。ai推理还是需要用npu。
四、香橙派Orange AI Pro使用昇腾310 npu和cann 部署加速yolov8
4.1、增加swap 交换内存
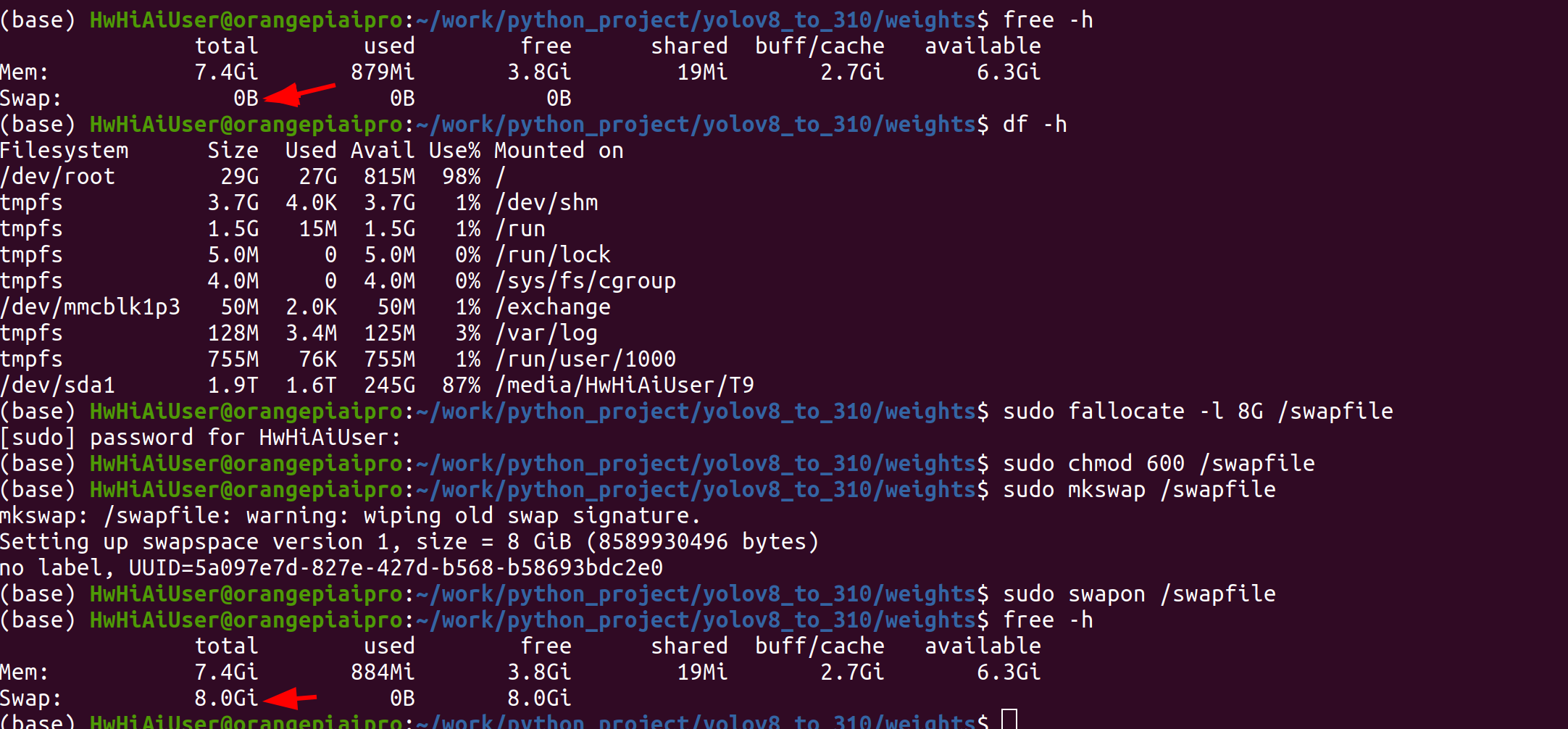
通过free -h命令查看内存使用情况,如果内存总量小于4G,则需要挂载swap分区
free -h
申请一个8G的文件作为swap分区【推荐2.5G以上,请提前预留足够的空间】
sudo fallocate -l 8G /swapfile
修改文件权限
sudo chmod 600 /swapfile
创建swap分区
sudo mkswap /swapfile
挂载swap分区
sudo swapon /swapfile
通过 free -h查看swap分区是否挂载成功
free -h
4.2、设置设备编译进程数CPU核数(可选)
转om模型时内存不足,开发板cpu核数较少,atc过程中使用的最大并行进程数默认是服务器的配置,可以使用环境变量减少atc过程中的进程数来减少内存消耗;当设备内存小于 8G 时,可设置如下两个环境变量减少atc模型转换过程中使用的进程数,减小内存占用。
- 减小算子最大并行编译进程数
export TE_PARALLEL_COMPILER=1
- 减少图编译时可用的CPU核数
export MAX_COMPILE_CORE_NUMBER=1
4.4、编译安装acllite
设置Ascend环境变量
设置环境变量,配置程序编译依赖的头文件,库文件路径。
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest;
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub;
export THIRDPART_PATH=${DDK_PATH}/thirdpart;
export LD_LIBRARY_PATH=${THIRDPART_PATH}/lib:$LD_LIBRARY_PATH;
export INSTALL_DIR=/usr/local/Ascend/ascend-toolkit/latest;
为了方便,不用每次执行,可将下面内容直接写入.bashrc文件
export CPU_ARCH=`arch`
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
export THIRDPART_PATH=/usr/local/Ascend/thirdpart/${CPU_ARCH} #代码编译时链接samples所依赖的相关库文件
export LD_LIBRARY_PATH=${THIRDPART_PATH}/lib:$LD_LIBRARY_PATH #运行时链接库文件
export INSTALL_DIR=/usr/local/Ascend/ascend-toolkit/latest #CANN软件安装后的文件存储路径,根据安装目录自行修改
# 执行命令使其立即生效。
source ~/.bashrc
下载ascend官方示例代码
git clone https://gitee.com/ascend/samples
我将代码下载到了/media/HwHiAiUser/T9/Ascend_310/work/ ,复制公共comon文件夹到THIRDPART_PATH
sudo cp -r /media/HwHiAiUser/T9/Ascend_310/work/samples/common ${THIRDPART_PATH}
进入inference/acllite/cplusplus 文件夹
编译acllite
执行以下命令安装acllite
cd /media/HwHiAiUser/T9/Ascend_310/work/samples/inference/acllite/cplusplus
make
sudo make install
编译没有问题,但是在安装的时候总是报错
Makefile:4: *** "Can not find INSTALL_DIR env, please set it in environment!.". Stop.
4.5、yolov8 pt 模型转onnx模型
这一步也可在自己电脑上转换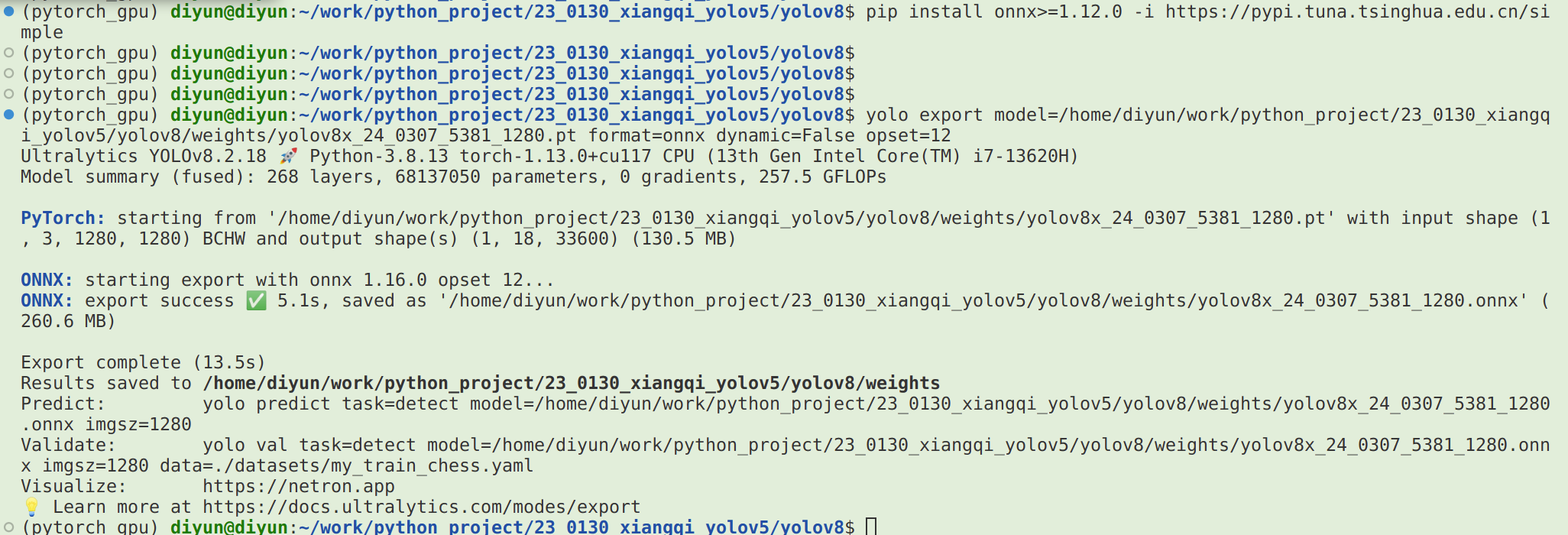
从输出信息中可以看出,我自己训练的这个中国象棋模型 yolov8x.pt原始模型的输出尺寸为 (1, 3, 1280, 1280),格式为 BCHW ,输出尺寸为 (1, 84, 8400) 。这个模型的更多信息,可以用 netron 工具进行可视化查看,在安装了netron后,可以执行如下命令打开yolov8x.onnx模型进行Web网络结构的查看:
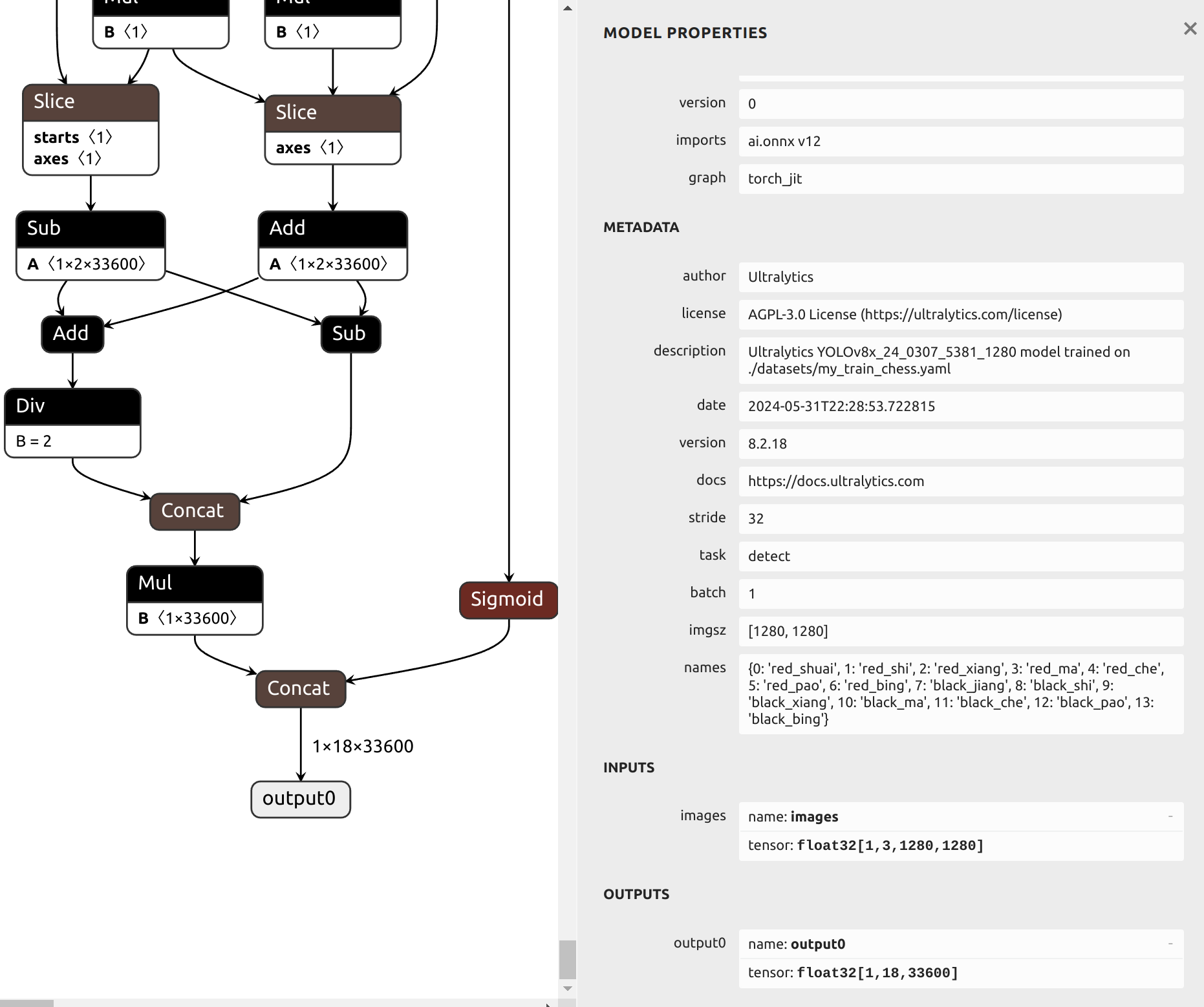
4.6、yolov8 onnx模型转换om模型
转换命令
atc --framework=5 --model=yolov8x_24_0307_5381_1280.onnx --input_format=NCHW --input_shape="images:1,3,1280,1280" --output=yolov8x_24_0307_5381_1280_huawei --soc_version=Ascend310B4
atc命令中各参数的含义如下:
–framework:原始框架类型,5表示ONNX。
–model:ONNX模型文件存储路径。
–input_format:输入的格式定义
–output:离线om模型的路径以及文件名。
–soc_version:昇腾AI处理器的型号。
在服务器种执行npu-smi info命令进行查询,在查询到的“Name”前增加Ascend信息,例如“Name”对应取值为310B4,实际配置的–soc_version值为Ascend310B4。

转换成功标志

4.7、使用华为昇腾 npu推理加速运行自己训练的yolov8模型——python代码
代码
""" "*******************************************************************************************
*文件名称 :.py
*文件功能 :华为晟腾 yolov8x.om python 推理代码 ——文件夹推理
版本:1.0
内容:华为晟腾 yolov8x.om python 推理代码 ——文件夹推理
时间:2023.6.2
作者:狄云
********************************************************************************************"""
import os
print(os.environ['LD_LIBRARY_PATH'])
import cv2
import numpy as np
from IPython.display import display, clear_output,Image
from time import time
from ais_bench.infer.interface import InferSession
from ultralytics.utils import ASSETS, yaml_load
from ultralytics.utils.checks import check_yaml
#中国象棋类别
CLASSES =['red_shuai','red_shi','red_xiang','red_ma','red_che','red_pao','red_bing','black_jiang','black_shi','black_xiang','black_ma','black_che','black_pao','black_bing']
colors = np.random.uniform(0, 255, size=(len(CLASSES), 3))
model = InferSession(device_id=0, model_path="chess_yolov8x_24_0307_5381_1280.om")
def draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):
label = f'{CLASSES[class_id]} ({confidence:.2f})'
color = colors[class_id]
cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)
cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
def main(original_image):
[height, width, _] = original_image.shape
length = max((height, width))
image = np.zeros((length, length, 3), np.uint8)
image[0:height, 0:width] = original_image
scale = length / 640
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
begin_time = time()
outputs = model.infer(feeds=blob, mode="static")
end_time = time()
print("om infer time:", end_time - begin_time)
outputs = np.array([cv2.transpose(outputs[0][0])])
rows = outputs.shape[1]
boxes = []
scores = []
class_ids = []
for i in range(rows):
classes_scores = outputs[0][i][4:]
(minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)
if maxScore >= 0.25:
box = [
outputs[0][i][0] - (0.5 * outputs[0][i][2]), outputs[0][i][1] - (0.5 * outputs[0][i][3]),
outputs[0][i][2], outputs[0][i][3]]
boxes.append(box)
scores.append(maxScore)
class_ids.append(maxClassIndex)
result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)
detections = []
for i in range(len(result_boxes)):
index = result_boxes[i]
box = boxes[index]
detection = {
'class_id': class_ids[index],
'class_name': CLASSES[class_ids[index]],
'confidence': scores[index],
'box': box,
'scale': scale}
detections.append(detection)
draw_bounding_box(original_image, class_ids[index], scores[index], round(box[0] * scale), round(box[1] * scale),
round((box[0] + box[2]) * scale), round((box[1] + box[3]) * scale))
# 指定图像文件夹路径
input_image_folder = 'path_to_your_image_folder' # 替换为你的图像文件夹路径
out_image_folder = 'output'
# 遍历文件夹中的所有图像文件
for filename in os.listdir(input_image_folder):
if filename.endswith(".jpg") or filename.endswith(".png"): # 根据你的图像格式调整
image_path = os.path.join(input_image_folder, filename)
image = cv2.imread(image_path) # 读取图像
if image is not None:
start_time = time.time() # 获取开始时间
# 调用main函数进行处理
main(image)
end_time = time.time() # 获取结束时间
print(f" 函数耗时:{(end_time - start_time) * 1000:.2f} 毫秒")
# 显示图像(可选)
cv2.imshow('Image', image)
cv2.waitKey(0) # 按任意键查看下一张图像
# 保存处理后的图像(可选)
output_path = os.path.join(out_image_folder, filename) # 替换为保存路径
cv2.imwrite(output_path, image)
# 释放资源
cv2.destroyAllWindows()
安装依赖
!pip install scikit_video
!pip install pip_packages/aclruntime-0.0.2-cp39-cp39-linux_aarch64.whl
!pip install pip_packages/ais_bench-0.0.2-py3-none-any.whl
参考:http://www.hzhcontrols.com/new-1997735.html
注意,aclruntime和ais_bench推理程序的whl包请 前往下载。
晟腾git 仓库 :https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_bench
运行效果图
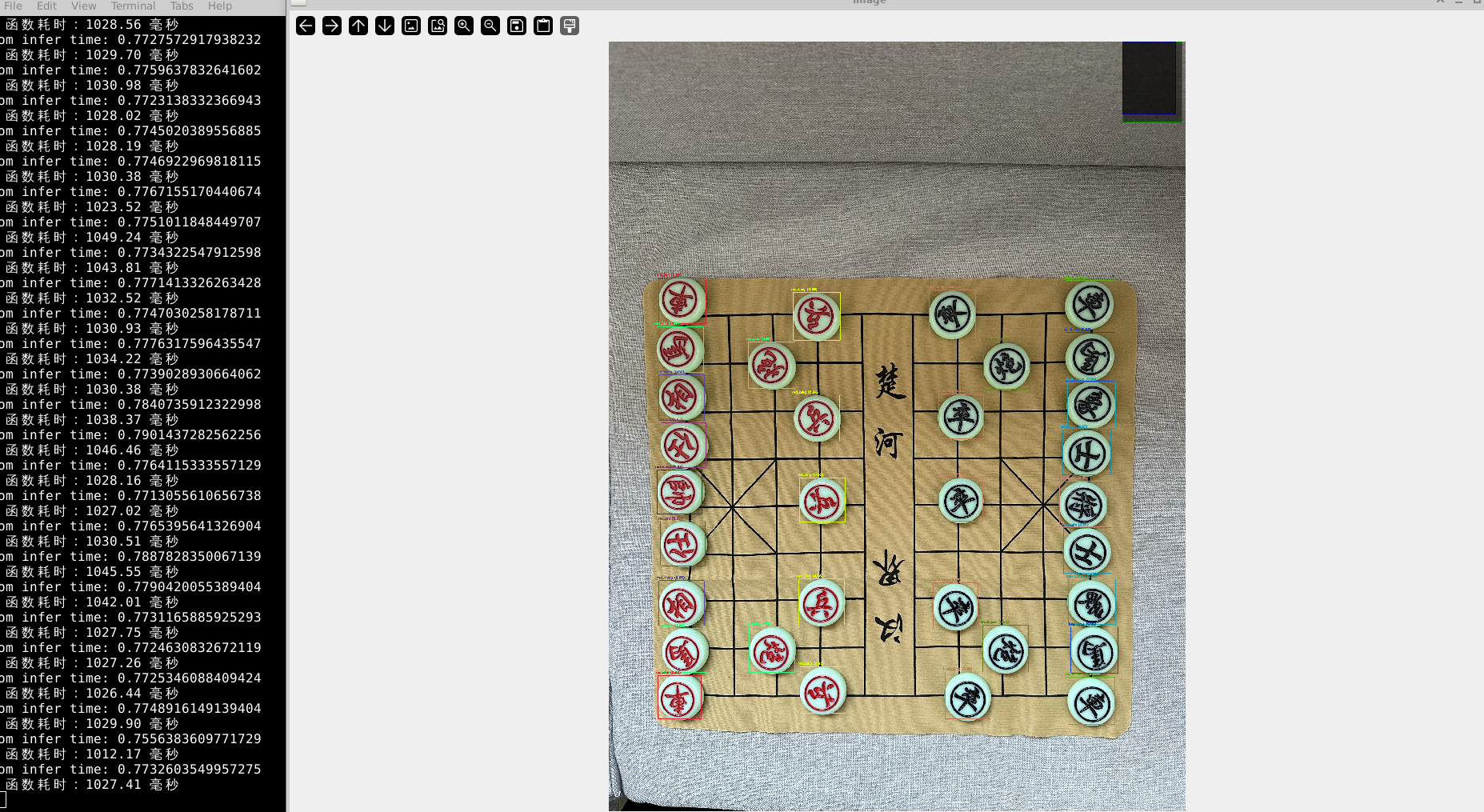 准确度不错
准确度不错

使用python 进行om推理,整体上速度较直接使用pytorch和pt模型快了很多,yolov8x ,1280*1280分辨率,速度是1s左右,但是还是不能达到实时的效果,还需要进行C++来部署。
4.7 使用华为昇腾npu运行自己训练的yolov8模型——C++部署
华为昇腾 CANN YOLOV8 推理示例 C++样例 , 可以基于Ascend CANN Samples官方示例中的sampleYOLOV7进行适配。一般来说,YOLOV7模型输出的数据大小为[1,25200,85],而YOLOV8模型输出的数据大小为[1,84,8400],因此,需要对sampleYOLOV7中的后处理部分进行修改,从而做到YOLOV8/YOLOV9模型的适配。(当然自己训练的模型这几个参数都会变化,主要和模型类别以及输入分辨率有关)
下载ascend官方示例代码
git clone https://gitee.com/ascend/samples
进入 inference/modelInference/sampleYOLOV7,将sampleYOLOV7文件夹复制一份,并命名为sampleYOLOV8
修改sampleYOLOV8.cpp后处理代码
注意修改类别和输入分辨率
size_t classNum = 80;
size_t modelOutputBoxNum = 8400;
上面两个参数主要看你的onnx输入输出,改成自己的即可。
Result SampleYOLOV8::GetResult(std::vector<InferenceOutput> &inferOutputs,
string imagePath, size_t imageIndex, bool release)
{
uint32_t outputDataBufId = 0;
float *classBuff = static_cast<float *>(inferOutputs[outputDataBufId].data.get());
// confidence threshold
float confidenceThreshold = 0.35;
// class number
size_t classNum = 80;
//// number of (x, y, width, hight)
size_t offset = 4;
// total number of boxs yolov8 [1,84,8400]
size_t modelOutputBoxNum = 8400;
// read source image from file
cv::Mat srcImage = cv::imread(imagePath);
int srcWidth = srcImage.cols;
int srcHeight = srcImage.rows;
// filter boxes by confidence threshold
vector<BoundBox> boxes;
size_t yIndex = 1;
size_t widthIndex = 2;
size_t heightIndex = 3;
// size_t all_num = 1 * 84 * 8400 ; // 705,600
for (size_t i = 0; i < modelOutputBoxNum; ++i)
{
float maxValue = 0;
size_t maxIndex = 0;
for (size_t j = 0; j < classNum; ++j)
{
float value = classBuff[(offset + j) * modelOutputBoxNum + i];
if (value > maxValue)
{
// index of class
maxIndex = j;
maxValue = value;
}
}
if (maxValue > confidenceThreshold)
{
BoundBox box;
box.x = classBuff[i] * srcWidth / modelWidth_;
box.y = classBuff[yIndex * modelOutputBoxNum + i] * srcHeight / modelHeight_;
box.width = classBuff[widthIndex * modelOutputBoxNum + i] * srcWidth / modelWidth_;
box.height = classBuff[heightIndex * modelOutputBoxNum + i] * srcHeight / modelHeight_;
box.score = maxValue;
box.classIndex = maxIndex;
box.index = i;
if (maxIndex < classNum)
{
boxes.push_back(box);
}
}
}
ACLLITE_LOG_INFO("filter boxes by confidence threshold > %f success, boxes size is %ld", confidenceThreshold,boxes.size());
// filter boxes by NMS
vector<BoundBox> result;
result.clear();
float NMSThreshold = 0.45;
int32_t maxLength = modelWidth_ > modelHeight_ ? modelWidth_ : modelHeight_;
std::sort(boxes.begin(), boxes.end(), sortScore);
BoundBox boxMax;
BoundBox boxCompare;
while (boxes.size() != 0)
{
size_t index = 1;
result.push_back(boxes[0]);
while (boxes.size() > index)
{
boxMax.score = boxes[0].score;
boxMax.classIndex = boxes[0].classIndex;
boxMax.index = boxes[0].index;
// translate point by maxLength * boxes[0].classIndex to
// avoid bumping into two boxes of different classes
boxMax.x = boxes[0].x + maxLength * boxes[0].classIndex;
boxMax.y = boxes[0].y + maxLength * boxes[0].classIndex;
boxMax.width = boxes[0].width;
boxMax.height = boxes[0].height;
boxCompare.score = boxes[index].score;
boxCompare.classIndex = boxes[index].classIndex;
boxCompare.index = boxes[index].index;
// translate point by maxLength * boxes[0].classIndex to
// avoid bumping into two boxes of different classes
boxCompare.x = boxes[index].x + boxes[index].classIndex * maxLength;
boxCompare.y = boxes[index].y + boxes[index].classIndex * maxLength;
boxCompare.width = boxes[index].width;
boxCompare.height = boxes[index].height;
// the overlapping part of the two boxes
float xLeft = max(boxMax.x, boxCompare.x);
float yTop = max(boxMax.y, boxCompare.y);
float xRight = min(boxMax.x + boxMax.width, boxCompare.x + boxCompare.width);
float yBottom = min(boxMax.y + boxMax.height, boxCompare.y + boxCompare.height);
float width = max(0.0f, xRight - xLeft);
float hight = max(0.0f, yBottom - yTop);
float area = width * hight;
float iou = area / (boxMax.width * boxMax.height + boxCompare.width * boxCompare.height - area);
// filter boxes by NMS threshold
if (iou > NMSThreshold)
{
boxes.erase(boxes.begin() + index);
continue;
}
++index;
}
boxes.erase(boxes.begin());
}
ACLLITE_LOG_INFO("filter boxes by NMS threshold > %f success, result size is %ld", NMSThreshold,result.size());
// opencv draw label params
const double fountScale = 0.5;
const uint32_t lineSolid = 2;
const uint32_t labelOffset = 11;
const cv::Scalar fountColor(0, 0, 255); // BGR
const vector<cv::Scalar> colors{
cv::Scalar(255, 0, 0), cv::Scalar(0, 255, 0),
cv::Scalar(0, 0, 255)};
int half = 2;
for (size_t i = 0; i < result.size(); ++i)
{
cv::Point leftUpPoint, rightBottomPoint;
leftUpPoint.x = result[i].x - result[i].width / half;
leftUpPoint.y = result[i].y - result[i].height / half;
rightBottomPoint.x = result[i].x + result[i].width / half;
rightBottomPoint.y = result[i].y + result[i].height / half;
cv::rectangle(srcImage, leftUpPoint, rightBottomPoint, colors[i % colors.size()], lineSolid);
string className = label[result[i].classIndex];
string markString = to_string(result[i].score) + ":" + className;
ACLLITE_LOG_INFO("object detect [%s] success", markString.c_str());
cv::putText(srcImage, markString, cv::Point(leftUpPoint.x, leftUpPoint.y + labelOffset),
cv::FONT_HERSHEY_COMPLEX, fountScale, fountColor);
}
string savePath = "out_" + to_string(imageIndex) + ".jpg";
cv::imwrite(savePath, srcImage);
if (release)
{
free(classBuff);
classBuff = nullptr;
}
return SUCCESS;
}
编译运行
在CMakeLists.txt里增加
find_package(OpenCV REQUIRED)
修改 sample_build.sh ,记得将 yolov7x.om 改成你自己转换成功的模型
然后执行:
cd $HOME/samples/inference/modelInference/sampleYOLOV8/scripts
bash sample_build.sh
这个步骤才是最终ai推理的整体流程。
五、其他开发环境安装
5.1、香橙派Orange AI Pro / 华为昇腾310 使用源码方式安装opencv 4.9.0
下载源码到香橙派
https://opencv.org/releases/
解压
unzip opencv-4.9.0.zip
进入解压后的文件
cd opencv-4.9.0
创建构建目录build
mkdir build
进入目录
cd build
使用cmake配置后续的构建环境
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_GENERATE_PKGCONFIG=ON ..
命令解释
第一行是构建的版本:这里是发行版RELEASE
第二行是安装的目录
第三行是显式地通过添加 -D OPENCV_GENERATE_PKGCONFIG=ON 到 CMake 命令来确保OPENCV能够被pkg-config工具找到
然后使用make -j2或者make -j4来进行编译,这个编译时间比较长,j后面的数字可以修改成4,6,8,视你的机器的处理核心数来定,越高的话越快,我是make -j2,因为香橙派Orange AI Pro 总共四个核,如果全部占满,直接会卡死。
make -j2
这样子就可以了,接下来使用命令安装Opencv,这样会安装Opencv以及生成的pkg-config文件
sudo make install
最后更新动态链接器的缓存
sudo ldconfig
这样就完成了
验证是否安装成功,使用pkg-config来检查是否能够找到OpenCV
pkg-config --modversion opencv4
安装成功

六、可能出现的错误
6.1、转换模型出现BrokenPipeError: [Errno 32] Broken pipe
Traceback (most recent call last):
File "/usr/local/miniconda3/lib/python3.9/multiprocessing/pool.py", line 131, in worker
put((job, i, result))
File "/usr/local/miniconda3/lib/python3.9/multiprocessing/queues.py", line 378, in put
self._writer.send_bytes(obj)
File "/usr/local/miniconda3/lib/python3.9/multiprocessing/connection.py", line 205, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/usr/local/miniconda3/lib/python3.9/multiprocessing/connection.py", line 416, in _send_bytes
self._send(header + buf)
File "/usr/local/miniconda3/lib/python3.9/multiprocessing/connection.py", line 373, in _send
n = write(self._handle, buf)
BrokenPipeError: [Errno 32] Broken pipe
内存不足,需要添加交换空间
在昇腾论坛找到了解决方案https://www.hiascend.com/forum/thread-0239142592318174023-1-1.html,总结就是:
转om模型时内存不足,开发板cpu核数较少,atc过程中使用的最大并行进程数默认是服务器的配置,可以使用环境变量减少atc过程中的进程数来减少内存消耗。
·减小算子最大并行编译进程数
export TE_PARALLEL_COMPILER=1
·减少图编译时可用的CPU核数
export MAX_COMPILE_CORE_NUMBER=1
之后就可以成功转换om模型啦!
6.2、 晟腾 onnx转换到om模型报错 /usr/local/Ascend/ascend-toolkit/latest/bin/atc: line 17: 7998 Aborted (core dumped) P K G P A T H / b i n / a t c . b i n " {PKG_PATH}/bin/atc.bin " PKGPATH/bin/atc.bin"@"
atc --framework=5 --model=yolov8n.onnx --input_format=NCHW --input_shape="images:1,3,640,640" --output=yolov8n_huawei --soc_version=Ascend310B4
ATC start working now, please wait for a moment.
Exception in thread Thread-1:
Fatal Python error: _enter_buffered_busy: could not acquire lock for <_io.BufferedWriter name='<stderr>'> at interpreter shutdown, possibly due to daemon threads
Python runtime state: finalizing (tstate=0xaaaacb04b040)
Current thread 0x0000e7fff9bab020 (most recent call first):
<no Python frame>
/usr/local/Ascend/ascend-toolkit/latest/bin/atc: line 17: 11752 Aborted (core dumped) ${PKG_PATH}/bin/atc.bin "$@"
同样是cpu和内存不够的问题,可以通过增加交换空间解决。
解决办法如下
通过free -h命令查看内存使用情况,如果内存总量小于4G,则需要挂载swap分区
free -h
申请一个8G的文件作为swap分区【推荐2.5G以上,请提前预留足够的空间】
sudo fallocate -l 8G /swapfile
修改文件权限
sudo chmod 600 /swapfile
创建swap分区
sudo mkswap /swapfile
挂载swap分区
sudo swapon /swapfile
通过 free -h查看swap分区是否挂载成功
free -h
6.3、 python 推理 晟腾npu模型报错 ModuleNotFoundError: No module named ‘IPython’
ModuleNotFoundError: No module named ‘IPython’
pip install IPython -i https://pypi.tuna.tsinghua.edu.cn/simple
6.4、 运行om模型报错: RuntimeError: [-1][ACL: general failure]
[INFO] create model description success
[ERROR] Check i:0 name:images in size:4915200 needsize:19660800 not match
[ERROR] Check InVector failed ret:-1
Traceback (most recent call last):
File "ascend_yolov8_folder_infer.py", line 100, in <module>
main(image)
File "ascend_yolov8_folder_infer.py", line 47, in main
outputs = model.infer(feeds=blob, mode="static")
File "/home/HwHiAiUser/.conda/envs/pytorch/lib/python3.8/site-packages/ais_bench/infer/interface.py", line 510, in infer
return self.run(inputs, out_array)
File "/home/HwHiAiUser/.conda/envs/pytorch/lib/python3.8/site-packages/ais_bench/infer/interface.py", line 450, in run
outputs = self.session.run(self.outputs_names, inputs)
RuntimeError: [-1][ACL: general failure]
[INFO] unload model success, model Id is 1
检查模型输入尺寸和图片输入尺寸。需要和你的onnx模型的输入输出对应。
6.5、 使用opencv 4.5 运行dnn 读取yolov8 onnx 模型,报错[ERROR:0] global
使用opencv 4.5 运行dnn 读取yolov8 onnx 模型,报错[ERROR:0] global ./modules/dnn/src/onnx/onnx_importer.cpp (718) handleNode DNN/ONNX: ERROR during processing node with 2 inputs and 1 outputs: [Add]:(/model.22/Add_output_0)
terminate called after throwing an instance of ‘cv::Exception’
what(): OpenCV(4.5.4) ./modules/dnn/src/onnx/onnx_importer.cpp:739: error: (-2:Unspecified error) in function ‘handleNode’
Node [Add]:(/model.22/Add_output_0) parse error: OpenCV(4.5.4) ./modules/dnn/src/onnx/onnx_importer.cpp:1067: error: (-215:Assertion failed) blob_0.size == blob_1.size in function ‘parseBias’
解决办法
将opencv 4.5 升级到4.9
https://opencv.org/releases/
安装方式:
https://blog.csdn.net/weixin_55189321/article/details/135994384
6.6、 fatal error: opencv2/opencv.hpp: No such file or directory
/media/HwHiAiUser/T9/Ascend_310/work/samples/inference/modelInference/sampleYOLOV8/src/sampleYOLOV8.cpp:2:10: fatal error: opencv2/opencv.hpp: No such file or directory
2 | #include <opencv2/opencv.hpp>
在CMakeLists.txt里增加
find_package(OpenCV REQUIRED)
6.7、fatal error: AclLiteUtils.h: No such file or directory
/media/HwHiAiUser/T9/Ascend_310/work/samples/inference/modelInference/sampleYOLOV8/src/sampleYOLOV8.cpp:3:10: fatal error: AclLiteUtils.h: No such file or directory
3 | #include "AclLiteUtils.h"

6.8、编译acllite 报错: Can not find INSTALL_DIR env
sudo make install
Makefile:4: *** "Can not find INSTALL_DIR env, please set it in environment!.". Stop.
指定安装路劲。
七、昇腾芯片常用命令
基础信息查看命令
# 查看Ubuntu发行版版本号
lsb_release -a
# 查看当前系统的内核名称、主机名、内核发型版本、节点名
uname -a
# 查询设备信息
npu-smi info
# 查询设备0中编号为0(NPU)的芯片的详细信息
npu-smi info -t board -i 0 -c 0
# 查看昇腾芯片的详细信息
ascend-dmi -i -dt
查看npu,AI core以及cpu的资源情况
由于Aipro带了四颗AI core,我们可以使用
npu-smi info watch
来查看npu,AI core以及cpu的资源情况。
将远程文件复制到本地
进入香橙派
示例命令
scp username@remote_host:/path/to/remote/file /path/to/local/directory
我的命令
scp diyun@192.168.71.150://home/diyun/work/python_project/23_0130_xiangqi_yolov5/yolov8_to_310.zip ./
AI CPU和Control CPU切换
昇腾310B独特的机制:AI CPU和Control CPU切换
npu-smi是昇腾AI处理器的系统管理工具,类似于NVIDIA GPU的 nvidia-smi,通过npu-smi info命令我们可以查看到AI处理器名称为310B4(8T算力版本)。
根据开发手册所说:OrangePi AiPro使用的昇腾SOC总共有4个CPU,这4个CPU既可以设置为control CPU,也可以设置为AICPU。默认情况下,control CPU和AI CPU的分配数量为 3:1。
# 查看control CPU和AI CPU的分配数量
(base) root@orangepiaipro:/home/HwHiAiUser# npu-smi info -t cpu-num-cfg -i 0 -c 0
Current AI CPU number : 1
Current control CPU number : 3
Current data CPU number : 0
# 查询AI CPU占用率
(base) root@orangepiaipro:/home/HwHiAiUser# npu-smi info -t usages -i 0 -c 0
Memory Capacity(MB) : 7545
Memory Usage Rate(%) : 27
Hugepages Total(page) : 15
Hugepages Usage Rate(%) : 100
Aicore Usage Rate(%) : 0
Aicpu Usage Rate(%) : 0
Ctrlcpu Usage Rate(%) : 0
Memory Bandwidth Usage Rate(%) : 1
# 查询芯片的算力档位
(base) root@orangepiaipro:/home/HwHiAiUser# npu-smi info -t nve-level -i 0 -c 0
nve level : 8T_1.0GHz
# 设置AI CPU为0,最多可以设置3个AI CPU(3:1:0,最后的0为data CPU,固定配置为 0)
sudo npu-smi set -t cpu-num-cfg -i 0 -c 0 -v 0:4:0
八、 使用总结
香橙派Ai pro的优点
1、既可以有ai 推理,npu加速的能力,也有控制能力。吊打树莓派这种鸡肋产品。
2、价格便宜,也支持大多数主流的算法,这个ai性能和价格可以说让jetson nano这种高价低性能的产品没有了生存空间。(jetson nano 1.5k,jetson orin 4k,Orange AI Pro应该1k以内)。
3、资料和示例代码较齐全。
4、自带wifi功能很方便
香橙派Ai pro的不足
1、图像界面不稳定,在重启后登陆系统的时候,经常出现登陆不进去的问题。
2、转晟腾npu模型的时候,内存严重不够用,如果不配置交换空间,系统直接会卡死。希望香橙派能够优化一下。
3、cpu能力较差,不过这个价位说实话已经不错了。
4、晟腾生态不如英伟达。华为的ai芯片种类很多,没有一个统一的技术架构,代码和模型不能通用,比如之前很不错的海思芯片,现在又出来个晟腾芯片,不知道过几年又会不会出新的,英伟达的cuda和tensorrt加速的c++代码,不光在最低阶的jetson nano上能用,可以不用改任何代码,也可以快速移植到xavier、orin,甚至4090等ubuntu台式机上。增加学习成本。
参考文章
1、香橙派OrangePi AIpro上手初体验
2、昇腾 CANN YOLOV8 和 YOLOV9 适配
3、昇腾AI处理器:Ascend310和CANN简介
4、解密昇腾AI处理器–Ascend310简介
5、模型转换:华为昇腾310B1平台深度学习算法模型转换
6、vnc可以参考:https://blog.csdn.net/qq_63913621/article/details/139252520?spm=1001.2014.3001.5502
7、yolov8_pose 全身姿态估计 pytorch转onnx转昇腾部署
8、华为昇腾芯片ai开发工具ATC使用教程
9、https://blog.csdn.net/Johnor/article/details/139234285
10、yolov5和yolov7的例程
11、多媒体开发:https://zhuanlan.zhihu.com/p/685708537