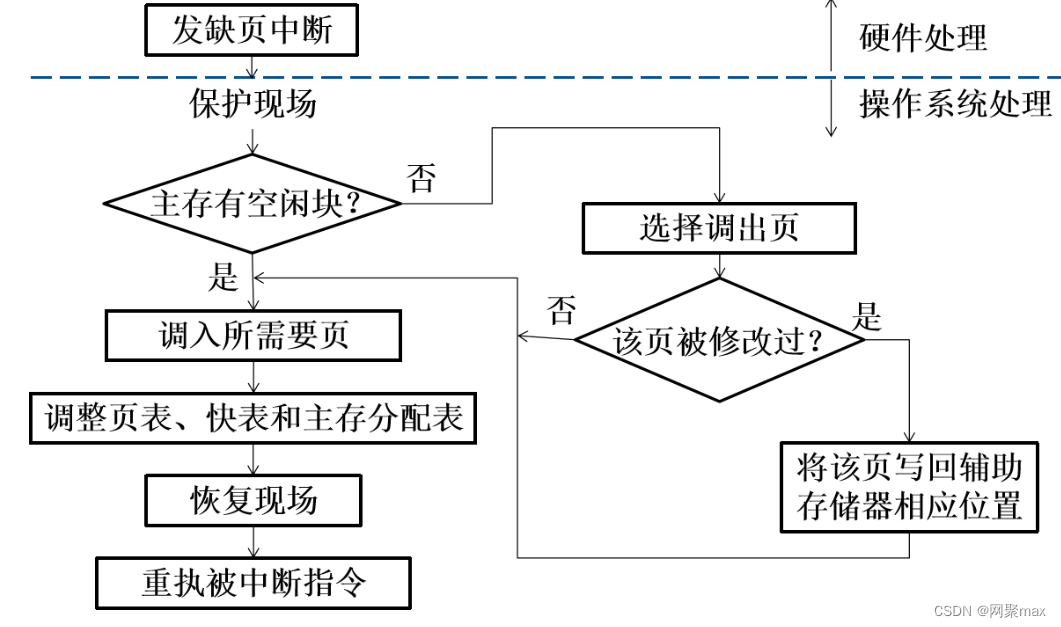
目录
- 三、简单存储服务S3
- (一)S3的基本概念和操作
- (二)S3的数据一致性模型
- (三)S3的安全措施
- 四、非关系型数据库服务SimpleDB和DynamoDB
- (一)非关系型数据库与传统关系数据库的比较
- (二)SimpleDB
- (三)DynamoDB
- (四)SimpleDB和DynamoDB的比较
三、简单存储服务S3
(一)S3的基本概念和操作
简单存储服务(Simple Storage Services,S3)构架在Dynamo之上,用于提供任意类型文件的临时或永久性存储。S3的总体设计目标是可靠、易用及低成本。
S3存储系统的基本结构,其中涉及两个基本概念:桶(Bucket)和对象(Object)。

1、桶
桶是用于存储对象的容器,其作用类似于文件夹,但桶不可以被嵌套,即在桶中不能创建桶。目前,Amazon限制了每个用户创建桶的数量,但没有限制每个桶中对象的数量。桶的名称要求在整个Amazon S3的服务器中是全局唯一的,以避免在S3中数据共享时出现相互冲突的情况。在对桶命名时,建议采用符合DNS要求的命名规则,以便与CloudFront等其他AWS服务配合使用。
2、对象
- 数据:任意类型,但大小会受到对象最大容量的限制。
- 元数据:数据内容的附加描述信息,通过名称-值(name-value)集合的形式来定义。
| 元数据名称 | 名 称 含 义 |
|---|---|
| last-modified | 对象被最后修改的时间 |
| ETag | 利用MD5哈希算法得出的对象值 |
| Content-Type | 对象的MIME(多功能网际邮件扩充协议)类型,默认二进制/八位组 |
| Content-Length | 对象数据长度,以字节为单位 |
3、基本操作
S3中支持对桶和对象的操作,主要包括:Get、Put、List、Delete和Head。下表列出了五种操作的主要内容。
| 操 作 目 标 | Get | Put | List | Delete | Head |
|---|---|---|---|---|---|
| 桶 | 获取桶中对象 | 创建或更新桶 | 列出桶中所有键 | 删除桶 | —— |
| 对象 | 获取对象数据和元数据 | 创建或更新对象 | —— | 删除对象 | 获取对象元数据 |
(二)S3的数据一致性模型
与其构建的基础Dynamo相同,S3中采用了最终一致性模型。在数据被充分传播到所有的存放节点之前,服务器返回给用户的仍是原数据,此时用户操作可能会出现后面几种情况:
| 用户操作 | 结果 | |
|---|---|---|
| 1 | 写入一个新的对象并立即读取它 | 服务器可能返回“键不存在” |
| 2 | 写入一个新的对象并立即列出桶中已有的对象 | 该对象可能不会出现在列表中 |
| 3 | 用新数据替换现有的对象并立即读取它 | 服务器可能返回原有的数据 |
| 4 | 删除现有的对象并立即读取它 | 服务器可能返回被删除的数据 |
| 5 | 删除现有的对象并立即列出桶中的所有对象 | 服务器可能列出被删除的对象 |

(三)S3的安全措施

1、身份认证(Authentication)


2、访问控制列表(Access Control List)
访问控制列表是S3提供的可供用户自行定义的访问控制策略列表。S3的访问控制策略(ACP)提供如下所列的五种访问权限。

注意:S3的ACL不具有继承性
S3中有三大类型的授权用户:
(1)所有者(Owner)
所有者是桶或对象的创建者,默认具是WRITE_ACP权限。所有者默认就是最高权限拥有者。
(2)个人授权用户(User)
两种授权方式,一种是通过电子邮件地址授权的用户,另一种是通过用户ID进行授权。
(3)组授权用户(Group)
一种是AWS用户组,它将授权分发给所有AWS账户拥有者;另一种是所有用户组,这是一种有着很大潜在危险的授权方式。
四、非关系型数据库服务SimpleDB和DynamoDB
(一)非关系型数据库与传统关系数据库的比较
| 传统的关系数据库 | 非关系型数据库 | |
|---|---|---|
| 数据模型 | 对数据有严格的约束 | key和value可以使用任意的数据类型 |
| 数据处理 | 满足CAP原则的C和A,在P方面很弱 | 满足CAP原则的A和P,而在C方面比较弱 |
| 接口层 | 以SQL语言对数据进行访问的,提供了强大的查询功能,并便于在各种关系数据库间移植 | 通过API操作数据,支持简单的查询功能,且由于不同数据库之间API的不同而造成移植性较差 |
总结:

(二)SimpleDB
SimpleDB基本结构图如下,包含了域、条目、属性、值等概念。

1、域(Domain)
域是用于存放具有一定关联关系的数据的容器,其中的数据以UTF-8编码的字符串形式存储。每个用户账户中的域名必须是唯一的,且域名长度为3~255个字符。每个域中数据的大小具有一定的限制。但域的划分也会为数据操作带来一些限制,是否划分域需要综合多种因素考虑。
2、条目(Item)
条目对应着一条记录,通过一系列属性来描述,即条目是属性的集合。在每个域中,条目名必须是唯一的。与关系数据库不同,SimpleDB中不需要事先定义条目的模式,即条目由哪些属性来描述。操作上具有极大的灵活性,用户可以随时创建、删除以及修改条目的内容。
3、属性(Attribute)
属性是条目的特征,每个属性都用于对条目某方面特性进行概括性描述。每个条目可以有多个属性。属性的操作相对自由,不用考虑该属性是否与域中的其他条目相关。
4、值(Value)
值用于描述某个条目在某个属性上的具体内容。一个条目的一个属性中可以有多个值。
例如:某类商品除颜色外其他参数完全一致,此时可以通过在颜色属性中存放多个值来使用一个条目表示该商品,而不需要像关系数据库中那样建立多条记录。

如图显示了SimpleDB的树状组织方式,其中可以看出SimpleDB对多值属性的支持。

- 限制:SimpleDB中每个属性值的大小不能超过1KB。
- 导致:SimpleDB存储的数据范围极其有限。
- 解决:将相对大的数据存储在S3中,在SimpleDB中只保存指向某个特定文件位置的指针。
(三)DynamoDB
DynamoDB的特点:
DynamoDB以表为基本单位,表中的条目同样不需要预先定义的模式。DynamoDB中取消了对表中数据大小的限制,用户设置任意大小,并由系统自动分配到多个服务器上。DynamoDB不再固定使用最终一致性数据模型,而是允许用户选择弱一致性或者强一致性。DynamoDB还在硬件上进行了优化,采用固态硬盘作为支撑,并根据用户设定的读/写流量限制预设来确定数据分布的硬盘数量。
(四)SimpleDB和DynamoDB的比较
SimpleDB和DynamoDB都是Amazon提供的非关系型数据库服务。
SimpleDB:限制了每张表的大小,更适合于小规模复杂的工作。自动对所有属性进行索引,提供了更加强大的查询功能。
DynamoDB:支持自动将数据和负载分布到多个服务器上,并未限制存储在单个表中数据量的大小,适用于较大规模负载的工作。