Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
11.1 ES简介与安装
es使用java开发,使用lucene作为核心,需要配置好java环境!
使用docker安装教程如下:
#拉取镜像
docker pull elasticsearch:6.5.4
#创建并启动镜像
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:6.5.4
#参数说明如下:
# --name表示镜像启动后的容器名称
# -d: 后台运行容器,并返回容器ID;
# -e: 指定容器内的环境变量
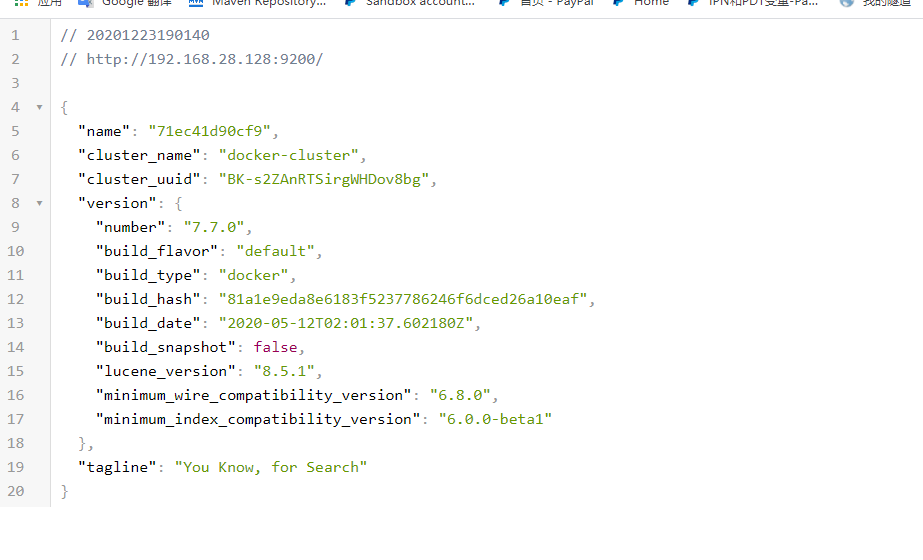
# -p: 指定端口映射,格式为:主机(宿主)端口:容器端口然后打开浏览器访问ip:9200 如果出现以下界面就是安装成功
11.2 ES-head简介与安装
由于ES官方并没有为ES提供界面管理工具,仅仅是提供了后台的服务。
elasticsearch-head是一个为ES开发的一个页面客户端工具,其源码托管于GitHub,地址为:https://github.com/mobz/elasticsearch-head
我们这里提供docker安装方式:
#拉取镜像
docker pull mobz/elasticsearch-head:5
#创建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#启动容器
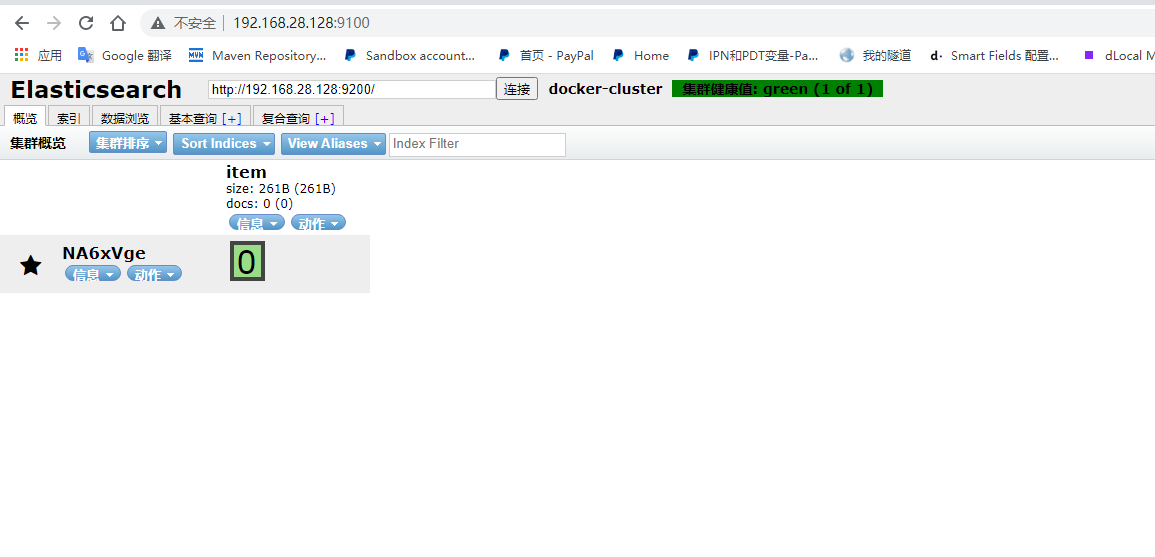
docker start elasticsearch-head通过浏览器进行访问ip:9100(看到的内容稍有不同, 建议再往下看一下):
尝试连接easticsearch会发现无法连接上,由于是前后端分离开发,所以会存在跨域问题,需要在服务端做CORS的配置。
需要修改ES的配置文件:
docker exec -it elasticsearch /bin/bash (进不去使用容器id进入)
vi config/elasticsearch.yml添加内容如下:
http.cors.enabled: true
http.cors.allow-origin: "*"然后重启ES项目即可
exit
docker restart 容器id接下来你可以尝试通过ES-head对ES做一些操作, 比如:新增一个索引, 你会发现没啥反应, 打开F12会有406错误.
需要你修改ES-head的配置文件
#复制vendor.js到外部
docker cp {ES-head的容器id}:/usr/src/app/_site/vendor.js /usr/local/
#修改vendor.js, 修改内容在下面
vim vendor.js
#修改内容:
1. 通过:6886跳转到6886行(vim的跳转固定行数命令:rowNum), 修改其中的"application/x-www-form-unlencoded" 为
"application/json;charset=UTF-8"
2.通过:7574跳转到7574行, 同样的修改:
"application/x-www-form-unlencoded" 修改为
"application/json;charset=UTF-8"
#修改结束
# 修改完成后
docker cp /usr/local/vendor.js {ES-head的容器id}:/usr/src/app/_site
# 重启ES-head
docker restart 容器id11.3 ES 基本概念入门
主要可以分为:索引,文档, 映射,文档类型四个部分
ES中的概念 | MySQL中的概念 | 映射关系(备注) |
_index(索引) | table(表) | 索引(index)是Elasticsearch对逻辑数据的逻辑存储, 这一点与MySQL中的Table一致 |
document(文档) | row(行) | 存储在Elasticsearch中的主要实体叫文档 一个文档相当于数据库表中的一行记录。 不同点:ES的文档可以有多种结构, 但是字段名相同时, 字段类型必须一致 你可以理解为一个有很多很多固定列的表. 没用到的列对于当前行都是不存在. |
mapping(映射) | 无对应 | 所有文档写进索引之前都会先进行分析 如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射 一般由用户自己定义规则。 |
文档类型 | 类似json对象的类型 | 在ES中,一个索引对象可以存储很多不同用途的对象。 例如,一个博客应用程序可以保存文章和评论。 不同的文档类型不能为相同的属性设置不同的类型。 例如,文章和评论存储在同一个索引中时,叫title的字段必须具有相同的类型。 |
概念看起来很乏味, 只需要记住索引对应的是表, 文档对应的是行, 其他的我们在接下来的实战中学习.
11.4 ES的RESTful API实战样例.
在Elasticsearch中,提供了丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
11.4.1 新建索引操作
先打开ES-head, ip:9100,然后在网页最上面的输入框输入ES的ip:9200, 连接, 连接成功后->索引->新建索引->新建一个名称为test的索引, 分片数为2,副本数为0,注意点ok前需要打开F12的网络.
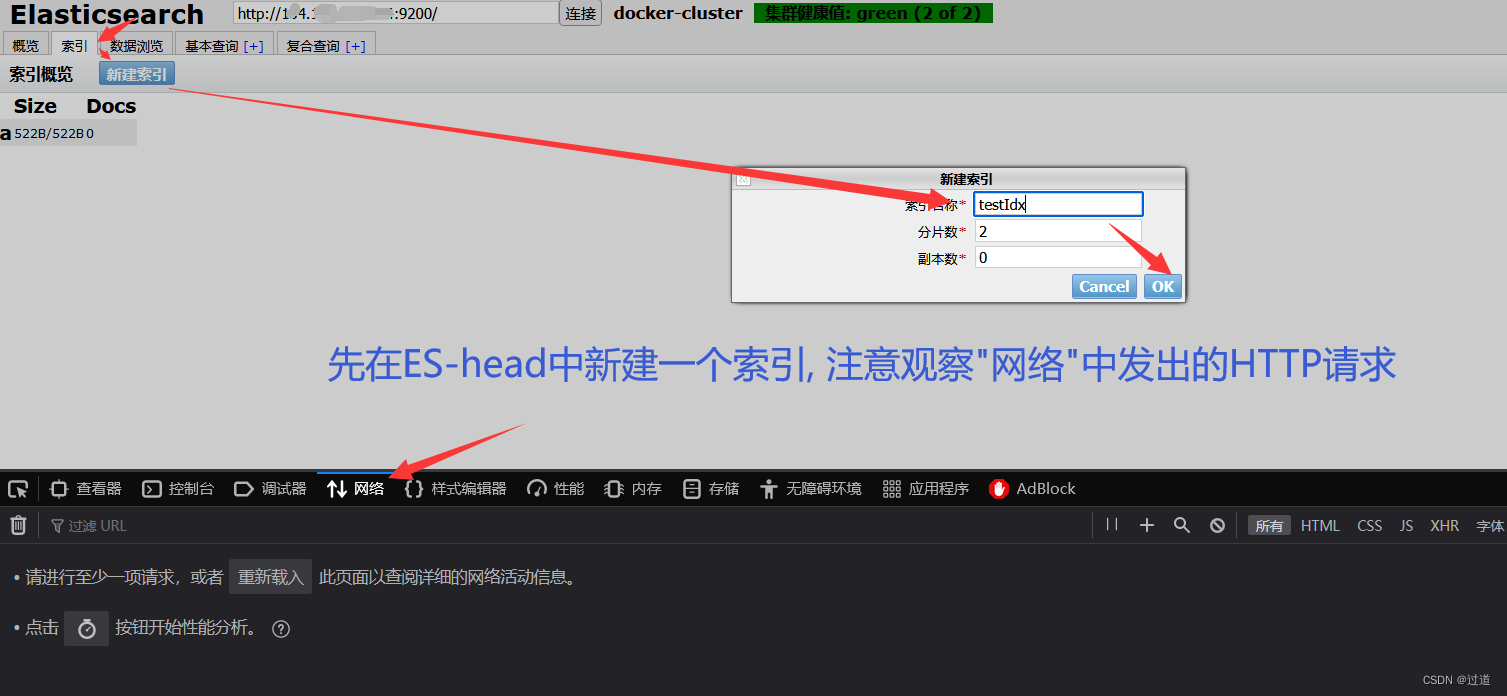
testIdx会报错400, 因为索引名称必须全小写, 所以索引名称改成test.
创建成功后观察网络:
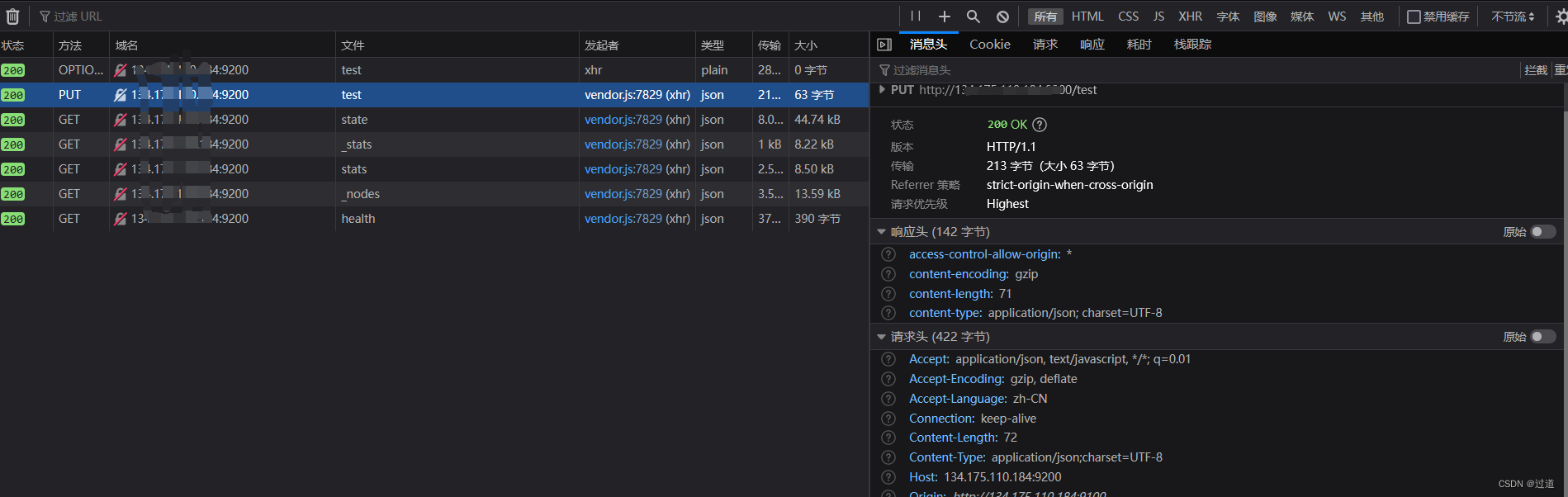
会发现它里面发出了若干个请求, 主要观察下第二个, 你会发现其发出的内容基本就是如下请求:
PUT http://{ES的ip}:9200/test
# 下面这段json是put的请求体的内容:
{
"settings": {
"index": {
"number_of_shards": "2", #分片数(注释需要删掉哦)
"number_of_replicas": "0" #副本数(注释需要删掉哦)
}
}
}
#注意http请求头里必须有这个key-value
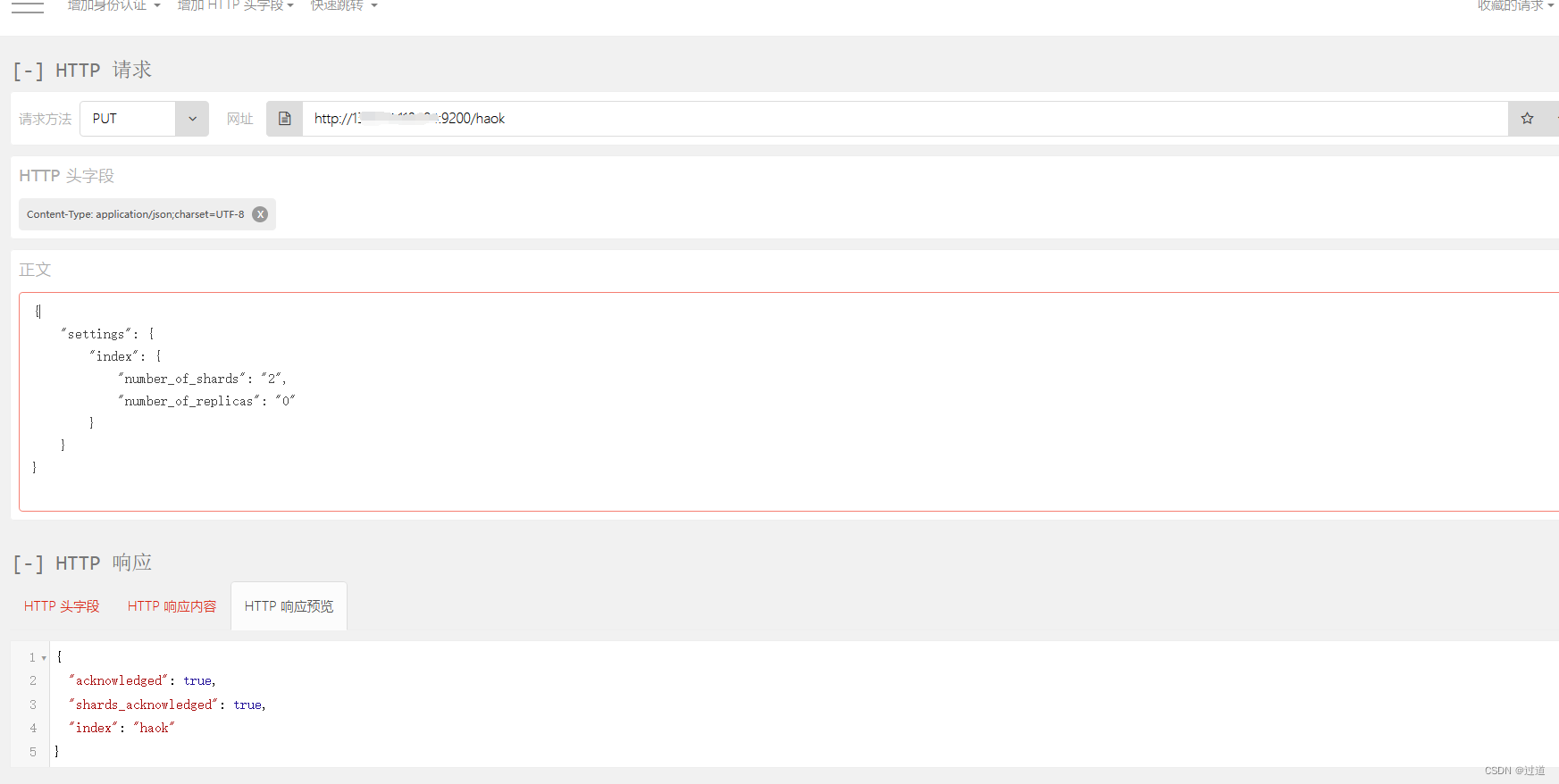
Content-Type:application/json;charset=UTF-8我们可以自己在浏览器打开一个Http请求插件, 按照上面要求输入,把test改成haok, 不然会报错索引已存在:
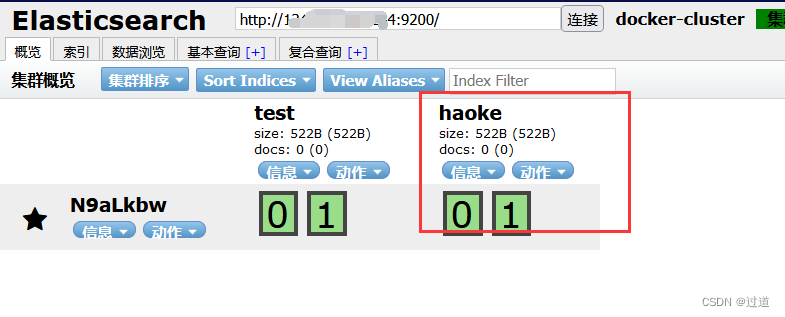
打开es-head查看, 确实多了一个索引:
11.4.2 删除索引操作
#删除索引
DELETE http://{ES的ip}:9200/haok
# 返回结果如下
{
"acknowledged": true
}查看ES-head, 删除成功了.
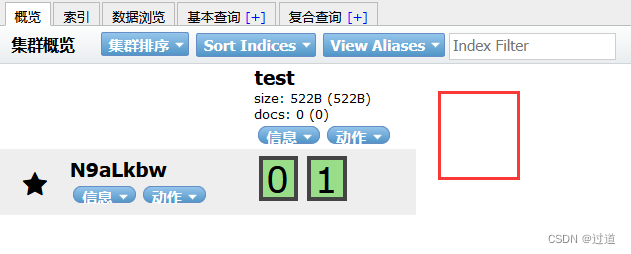
11.4.3 插入数据
URL规则:
POST http://ip:9200/{索引}/{类型}/{id}
POST http://ip:9200/test/user/1001
# 解释: test是我们一开始建的索引, user是一个类型, 在第一次插入数据时会自动创建, 1001是指定主键的值
#请求体数据如下:
{
"id":1001,
"name":"张三",
"age":20,
"sex":"男"
}
#响应内容:
{
"_index": "haoke",
"_type": "user",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}插入后,查看内容:
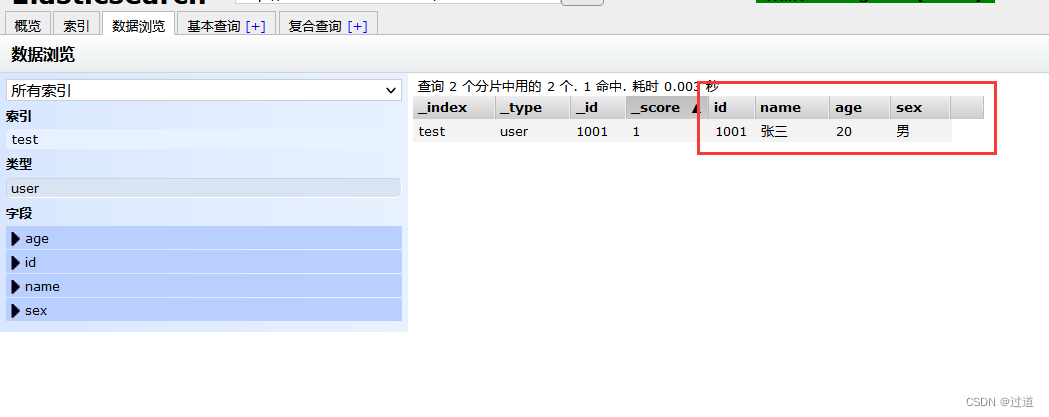
然后我们再试试不指定id的插入,观察下_id的值.
POST http://ip:9200/test/user
# 不指定id
#请求体数据如下:
{
"id":1002,
"name":"张三",
"age":20,
"sex":"男"
}查看ES-head
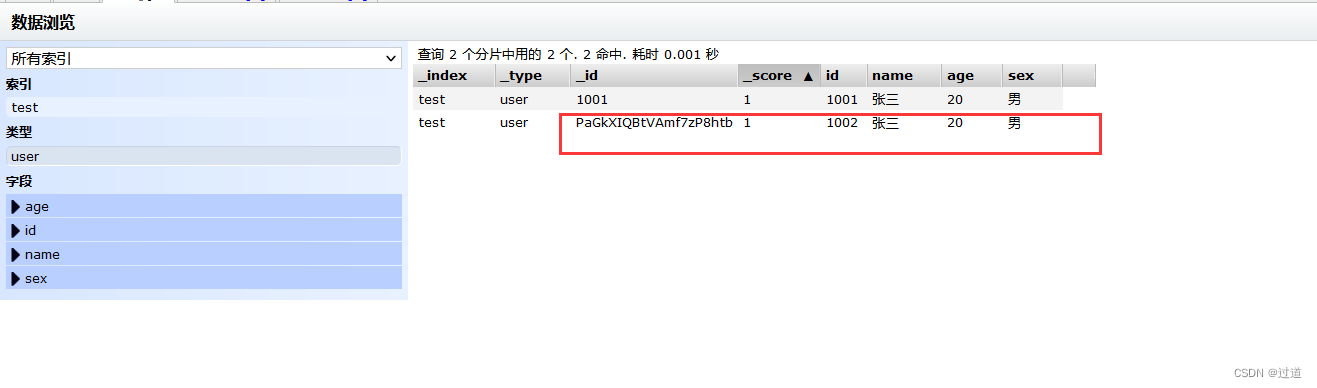
可以看到_id是随机生成的一个字符串.
11.4.4 更新数据
更新数据本质上是覆盖数据:
PUT http://ip:9200/test/user/1001
{
"id":1001,
"name":"张三",
"age":21,
"sex":"女"
}
#你可以删掉一个属性, 会发现被删除的属性也丢失了.
#响应体:
{
"_index": "test",
"_type": "user",
"_id": "1001",
"_version": 2, # 注意版本号更新了, 从1->2
"result": "updated",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}当然, ES也支持局部属性更新, 不过底层仍然是取出修改部分,然后覆盖.
局部更新代码:
#注意:这里多了_update标识
POST http://ip:9200/test/user/1001/_update
{
"doc":{
"age":23
}
}
#相应里版本号会再加一, ES中也只更新了age11.4.5 删除数据
DELETE http://ip:9200/test/user/1001
#响应内容:
{
"_index": "test",
"_type": "user",
"_id": "1001",
"_version": 4, #删除版本号也会增加
"result": "deleted",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
#如果删除一条不存在的数据,会响应404:
DELETE http://ip:9200/test/user/10011报错404
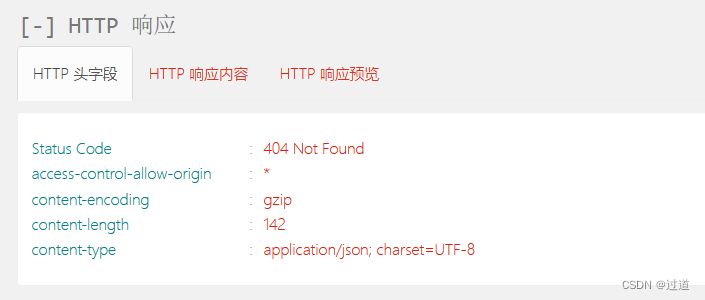
删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch将会在你之后添加更多索引
的时候才会在后台进行删除内容的清理。
11.4.6 查询数据
GET http://ip:9200/haoke/user/BbPe_WcB9cFOnF3uebvr
# BbPe_WcB9cFOnF3uebvr是我的1002的_id, 你需要根据你自己的1002的_id替换
#响应内容
{
"_index":"test",
"_type":"user",
"_id":"PaGkXIQBtVAmf7zP8htb",
"_version":1,
"found":true,
"_source":{
"id":1002,
"name":"张三",
"age":20,
"sex":"男"
}
}搜索全部数据
#在搜索前, 我们手动插入两条数据
PUT http://ip:9200/test/user/1003
{
"id":1003,
"name":"李四",
"age":20,
"sex":"男"
}
PUT http://ip:9200/test/user/1004
{
"id":1004,
"name":"王五",
"age":20,
"sex":"男"
}
#获取全部数据
GET http://ip:9200/test/user/_search
#响应内容:
{
"took": 1,
"timed_out": false,
"_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 },
"hits": {
"total": 3,
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "PaGkXIQBtVAmf7zP8htb",
"_score": 1.0,
"_source": {
"id": 1002,
"name": "张三",
"age": 20,
"sex": "男"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_score": 1.0,
"_source": {
"id": 1003,
"name": "李四",
"age": 20,
"sex": "男"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1004",
"_score": 1.0,
"_source": {
"id": 1004,
"name": "王五",
"age": 20,
"sex": "男"
}
}
]
}
}关键字搜素数据
#查询年龄等于20的用户
GET http://ip:9200/test/user/_search?q=age:2011.4.7 DSL 搜索
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现
POST http://ip:9200/test/user/_search
#请求体
{
"query" : {
"match" : {
"id" : 1002
}
}
}
#响应:
{
"took": 6,
"timed_out": false,
"_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 },
"hits": {
"total": 1,
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "PaGkXIQBtVAmf7zP8htb",
"_score": 1.0,
"_source": {
"id": 1002,
"name": "张三",
"age": 20,
"sex": "男"
}
}
]
}
}查询id小于1004的男性
POST http://ip:9200/test/user/_search
#请求数据
{
"query": {
"bool": {
"filter": {
"range": {
"id": {
"lt": 1004
}
}
},
"must": {
"match": {
"sex": "男"
}
}
}
}
}
#响应
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.13353139,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "PaGkXIQBtVAmf7zP8htb",
"_score": 0.13353139,
"_source": {
"id": 1002,
"name": "张三",
"age": 20,
"sex": "男"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_score": 0.13353139,
"_source": {
"id": 1003,
"name": "李四",
"age": 20,
"sex": "男"
}
}
]
}
}POST http://ip:9200/haoke/user/_search
#请求数据
{
"query": {
"match": {
"name": "张三 李四"
}
}
}
# 查询name = 张三 || name = 李四11.5 ES常见高级操作
11.5.1 文档
在之前的概念入门中提到, ES的文档 ≈ 数据库表中的一行记录, 而在ES中存储文档的格式为json. 而json是支持嵌套对象的.
{
"_index": "test",
"_type": "user",
"_id": "1005",
"_version": 1,
"_score": 1,
"_source": {
"id": 1005,
"name": "孙七",
"age": 37,
"sex": "女",
"card": {
"card_number": "123456789" # 本行为重点
}
}
}在学习查询的时候, 我们还看到了每次请求返回的内容都有一些通用的值, 其中如下这三个被称为"元数据"
"_index": "haoke", # 文档存储的地方, 就是数据库中其所在的DB
"_type": "user", # 文档代表的对象的类 就是数据库中其所属的Table
"_id": "1005", # 文档的唯一标识, 就是数据库中的主键.可以在查询url后面添加pretty参数,使得返回的json更易查看。
比如
POST http://ip:9200/haoke/user/_search?pretty
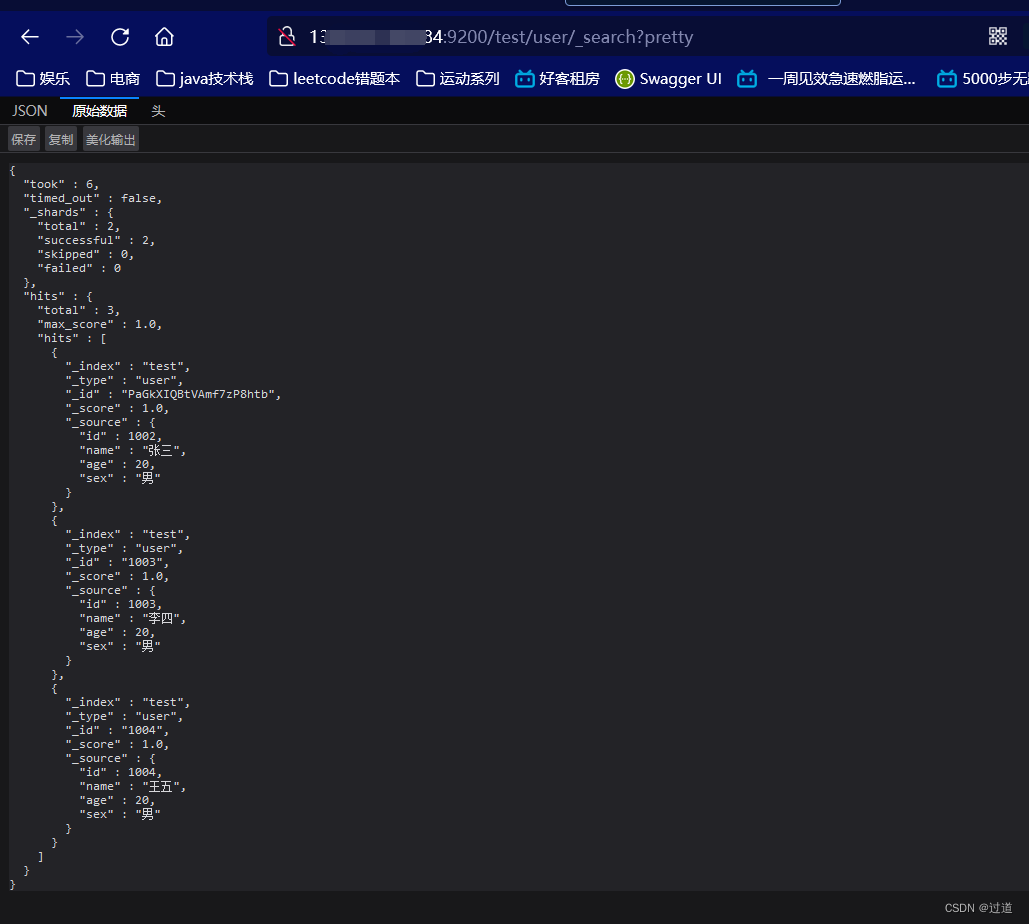
11.5.2 指定响应字段
在响应的数据中,如果我们不需要全部的字段,可以指定某些需要的字段进行返回。
GET http://ip:9200/test/user/1003?_source=id,name
#返回值如下:
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_version": 1,
"found": true,
"_source": {
"name": "李四", # 只有id和name属性
"id": 1003
}
}如不需要返回元数据,仅仅返回原始数据,可以这样:
GET http://ip:9200/haoke/user/1003/_source
#响应如下: 响应中不再有元数据
{
"id": 1003,
"name": "李四",
"age": 20,
"sex": "男"
}当然, 上面两种可以一起用
GET http://ip:9200/haoke/user/1003/_source?_source=id,name
#响应如下: 响应中不再有元数据,并且只有选定的属性答应
{
"name": "李四",
"id": 1003
}11.5.3 判断文档是否存在
HEAD http://ip:9200/haoke/user/1005
# 当前存在时响应状态为200
# 当前不存在时响应状态为40411.5.4 批量查询
POST http://ip:9200/haoke/user/_mget
#请求体:
{
"ids" : [ "1001", "1003" ]
}
# 输出内容如下:
{
"docs": [{
"_index": "test",
"_type": "user",
"_id": "1004",
"_version": 1,
"found": true,
"_source": {
"id": 1004,
"name": "王五",
"age": 20,
"sex": "男"
}
}, {
"_index": "test",
"_type": "user",
"_id": "1003",
"_version": 1,
"found": true,
"_source": {
"id": 1003,
"name": "李四",
"age": 20,
"sex": "男"
}
}]
}11.5.5 分页
和SQL使用LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受from 和size 参数:
GET /_search?size=5 # 默认从idx=0 开始查, size=5
GET /_search?size=5&from=5 # 默认从idx=5 开始查, size=5
GET /_search?size=5&from=10 # 默认从idx=10 开始查, size=5ES支持分布式, 这就意味着如果你请求排序后的前一千个对象, 那么每台机器都会查出排序好的前一千个, 然后汇总到 请求节点, 再进行排序, 最后才将真正的前1000个返回.
11.6 分词与中文分词
分词就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。
举例:我是中国人 --> 我/是/中国人
POST http://ip:9200/_analyze
# 请求体
{
"analyzer":"standard", # 我在这里使用的是标准分词器。
"text":"hello world"
}
#输出:
{
"tokens": [{
"token": "hello", #分词第一个:hello
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
}, {
"token": "world", #分词第一个:world
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}]
}那么如果分词中文能得到我们想要的结果吗?
# 使用标准分词器分析‘你好世界’
{
"tokens": [{
"token": "你",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
}, {
"token": "好",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
}, {
"token": "世",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
}, {
"token": "界",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}]
}这个效果肯定不对的。 这是因为ES的标准分词器不支持中文, 所以我们就需要自已安装一个支持中文的分词器。
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
#安装方法:将下载到的elasticsearch-analysis-ik-6.5.4.zip解压到/elasticsearch/plugins/ik
目录下即可。
#如果使用docker运行
docker cp /tmp/elasticsearch-analysis-ik-6.5.4.zip
elasticsearch:/usr/share/elasticsearch/plugins/
#进入容器
docker exec -it elasticsearch /bin/bash
mkdir /usr/share/elasticsearch/plugins/ik
cd /usr/share/elasticsearch/plugins/ik
unzip elasticsearch-analysis-ik-6.5.4.zip
#重启容器即可
docker restart elasticsearch再次测试
POST http://172.16.55.185:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
# 输出如下:
{
"tokens": [{
"token": "你好",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
}, {
"token": "世界",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}]
}11.7 全文搜索
11.7.1 倒排索引
在介绍倒排索引之前, 先说一下"正排索引".
我们搜索一篇文章是否有某个关键字, 最常见的sql语句就是like
-- 搜索博客的文章标题或者内容中包含'测试'
SELECT * FROM blog WHERE title LIKE '%测试%' OR content LIKE '%测试%' 这个思路就是正排, 我们去所有的文章的标题和内容中寻找.
如果有1000w篇3000字的文章, 效率怎么样? 自然是非常非常慢了.
一般我们使用常见的汉字只有5000个, 加上常见的生僻字也就一万两千个, 所以换一种思路, 不是去文章找词, 而是在添加一篇文章到数据库里, 将文章编号与其中所有的词关联.
编号 | 单词 | 文章编号(使用'->'拼接多个文章编号) |
1 | 你好 | 1->3->1102 |
2 | 世界 | 1->1101 |
3 | 测试 | 2 |
那么,我们搜索'你好'的时候, 很快就定位到了编号为1,3,1102的文章.
实际上, 我们这里的文章编号的结构往往更复杂.
1->3->1102
我们判断词与文章的关联度往往需要该词在文中出现的次数
比如: (1, 3)->(3, 1)->(1102, 2);
其中(1,3)就是编号为1的文章中单词出现了三次
此外, 我们在搜索引擎中搜东西, 还会告诉你该词在文中的上下文, 这就需要我们记录单词出现的下标了.
(1, 3,[11, 17, 53])->(3, 1[22])->(1102, 2[101, 188]);
其中(1,3,[11, 17, 53])就是编号为1的文章中单词出现了三次, 位置分别是idx = 11,idx = 17,idx = 53
全文搜索两个最重要的方面是:
相关性(Relevance) 它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这种计算方式可以是 TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法。
分析(Analysis) 它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了创建倒排索引以及查询倒排索引。
11.7.2 构造数据
PUT http://172.16.55.185:9200/itcast
# 构建分片索引和类型,指定类型的属性的类型, 注意我们指定了hobby的分词器是ik,所以支持分词且支持中文分词
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"person": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"mail": {
"type": "keyword"
},
"hobby": {
"type": "text",
"analyzer":"ik_max_word"
}
}
}
}
}插入数据
POST http://ip:9200/itcast/_bulk
#批量插入操作, 注意hobby会被ik分词器解析
{"index":{"_index":"itcast","_type":"person"}}
{"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、篮球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影、羽毛球"}然后响应是200, 就去ip:9100看看数据.
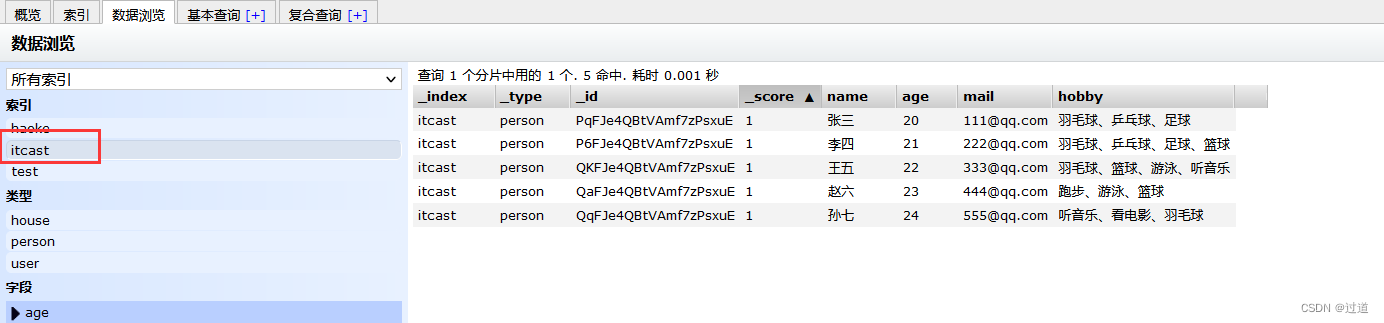
11.7.3 单词搜索实战
POST http://ip:9200/itcast/person/_search
# ES使用倒排索引查询hobby(爱好)中包含'音乐'的文档, 并且在hobby中高亮
{
"query":{
"match":{
"hobby":"音乐"
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
# 响应内容
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.6841192,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "Uv0cDWgBR-bSw8-LpdkZ",
"_score": 0.6841192,
"_source": {
"name": "王五",
"age": 22,
"mail": "333@qq.com",
"hobby": "羽毛球、篮球、游泳、听音乐"
},
"highlight": {
"hobby": [
"羽毛球、篮球、游泳、听<em>音乐</em>"
]
}
},
{
"_index": "itcast",
"_type": "person",
"_id": "VP0cDWgBR-bSw8-LpdkZ",
"_score": 0.6841192,
"_source": {
"name": "孙七",
"age": 24,
"mail": "555@qq.com",
"hobby": "听音乐、看电影、羽毛球"
},
"highlight": {
"hobby": [
"听<em>音乐</em>、看电影、羽毛球"
]
}
}
]
}
}如果你认真观察上文的输出的话, 你会看到每一个查出来的person不仅有元数据和版本, 还有一个之前没见过的属性_score
"_score": 0.6841192
这个属性就是我们前面提到的相关性的数值化. 这个值就是根据词频和反向文档频率和字段总长度计算得出
词频: term frequency,即词 “音乐” 在相关文档的hobby 字段中出现的频率
反向文档频率: inverse document frequency,即词 “音乐” 在所有文档的hobby 字段中出现的频率
字段的长度 : 即字段越短相关度越高
11.7.4 多词搜索
我们接下来搜索爱好"音乐和篮球"
POST http://ip:9200/itcast/person/_search
# 查询hobby中包含音乐或者篮球的词, 并高亮
{
"query":{
"match":{
"hobby":"音乐 篮球"
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
# 输出如下:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.3192271,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "QKFJe4QBtVAmf7zPsxuE",
"_score": 1.3192271,
"highlight": {
"hobby": ["羽毛球、<em>篮球</em>、游泳、听<em>音乐</em>"]
}
}, {
"_index": "itcast",
"_type": "person",
"_id": "QqFJe4QBtVAmf7zPsxuE",
"_score": 0.81652206,
"highlight": {
"hobby": ["听<em>音乐</em>、看电影、羽毛球"]
}
}, {
"_index": "itcast",
"_type": "person",
"_id": "QaFJe4QBtVAmf7zPsxuE",
"_score": 0.6987338,
"highlight": {
"hobby": ["跑步、游泳、<em>篮球</em>"]
}
}, {
"_index": "itcast",
"_type": "person",
"_id": "P6FJe4QBtVAmf7zPsxuE",
"_score": 0.50270504,
"highlight": {
"hobby": ["羽毛球、乒乓球、足球、<em>篮球</em>"]
}
}]
}
}结果明显是或的查询, 说明如果不指定默认查询的是分词后的或的关系.
# 在上一个查询的基础上, 我们在hobby搜索条件里加上 "operator":"and", 这样就可以按且的关系查询了.
{
"query": {
"match": {
"hobby": {
"query": "音乐 篮球",
"operator": "and"
}
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
# 查询结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.3192271,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "QKFJe4QBtVAmf7zPsxuE",
"_score": 1.3192271,
"highlight": {
"hobby": ["羽毛球、<em>篮球</em>、游泳、听<em>音乐</em>"]
}
}]
}
}11.7.5 组合搜索
POST http://172.16.55.185:9200/itcast/person/_search
# 必须包含'篮球', 不能包含'音乐',包含了'游泳'的话权重更高.
{
"_source": false,
"query": {
"bool": {
"must": {
"match": {
"hobby": "篮球"
}
},
"must_not": {
"match": {
"hobby": "音乐"
}
},
"should": [{
"match": {
"hobby": "游泳"
}
}]
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
#响应内容
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.8336569,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "QaFJe4QBtVAmf7zPsxuE",
"_score": 1.8336569,
"highlight": {
"hobby": ["跑步、<em>游泳</em>、<em>篮球</em>"]
}
}, {
"_index": "itcast",
"_type": "person",
"_id": "P6FJe4QBtVAmf7zPsxuE",
"_score": 0.50270504,
"highlight": {
"hobby": ["羽毛球、乒乓球、足球、<em>篮球</em>"]
}
}]
}
}11.7.6 权重
有些时候,我们可能需要对某些词增加权重来影响该条数据的得分。如下:
搜索关键字为“游泳篮球”,如果结果中包含了“音乐”权重为10,包含了“跑步”权重为2
POST http://ip:9200/itcast/person/_search
{
"query": {
"bool": {
"must": {
"match": {
"hobby": {
"query": "游泳 篮球",
"operator": "and"
}
}
},
"should": [{
"match": {
"hobby": {
"query": "音乐",
"boost": 10
}
}
},
{
"match": {
"hobby": {
"query": "跑步",
"boost": 2
}
}
}
]
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
#响应内容:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 9.484448,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "QKFJe4QBtVAmf7zPsxuE",
"_score": 9.484448,
"_source": {
"name": "王五",
"age": 22,
"mail": "333@qq.com",
"hobby": "羽毛球、篮球、游泳、听音乐"
},
"highlight": {
"hobby": ["羽毛球、<em>篮球</em>、<em>游泳</em>、听<em>音乐</em>"]
}
}, {
"_index": "itcast",
"_type": "person",
"_id": "QaFJe4QBtVAmf7zPsxuE",
"_score": 5.4279313,
"_source": {
"name": "赵六",
"age": 23,
"mail": "444@qq.com",
"hobby": "跑步、游泳、篮球"
},
"highlight": {
"hobby": ["<em>跑步</em>、<em>游泳</em>、<em>篮球</em>"]
}
}]
}
}11.7.7 短语匹配
在Elasticsearch中,短语匹配意味着不仅仅是词要匹配,并且词的顺序也要一致,如下:
POST http://172.16.55.185:9200/itcast/person/_search
{
"query":{
"match_phrase":{
"hobby":{
"query":"羽毛球篮球"
}
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
# 返回内容:
{
"took": 43,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.307641,
"hits": [{
"_index": "itcast",
"_type": "person",
"_id": "QKFJe4QBtVAmf7zPsxuE",
"_score": 1.307641,
"_source": {
"name": "王五",
"age": 22,
"mail": "333@qq.com",
"hobby": "羽毛球、篮球、游泳、听音乐"
},
"highlight": {
"hobby": ["<em>羽毛</em><em>球</em>、<em>篮球</em>、游泳、听音乐"]
}
}]
}
}