Go语言是云计算时代的语言
Go语言2007年诞生于Google,2009年开源,Go语言与区块链技术一样年轻
本文是对Go语言基本语法的总结

目录
Go词法单元
token
Go的token
标识符
内置数据类型标识符
常量值标识符
空白标识符
关键字
程序整体结构的关键字
声明复合结构的关键字
控制程序结构的关键字
内置函数
操作符和分隔符
字面常量
整型字面量
浮点型字面量
字符型字面量
字符串字面量
变量
显式的完整声明
短类型声明
常量
Go的常量
预声明标识符
基本数据类型
布尔类型
整型
浮点型
复数类型
字符串
rune类型
复合数据类型
指针
数组
map
结构控制语句
if语句
switch语句
for语句
标签和跳转
Go语言简介
罗布在 2007 年 9 月 25 号 回复给 肯、罗伯特的有关新的编程语言讨论主题的邮件说在开车回家的路上我得到了些灵感,给这门编程语言取名为“go”,它很简短,易书写。

Go语言的哲学:少即是多,世界是并行的,组合优于继承,面向接口编程
Go词法单元
token
token是源程序的基本的不可分割的单元
编译器先进行词法分析,将源程序分割成一个个token
Go的token
- 操作符
- 纯分隔符
操作符例如‘:=’,‘+’,‘a’
纯分隔符没有任何语法意义,如空格,制表符,换行符和回车符
标识符
标识变量,类型,常量等语法对象的符号名称
Go的标识符必须是字母或下划线开头,后面可以有数字
内置数据类型标识符
整型(12个):
byte int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
浮点型(2个):
float32 float32
复数型(2个):
complex64 complex128
字符和字符串型(2个)
string rune
接口型:
error
布尔型:
bool
常量值标识符
true false //表示bool类型的两常量值,真和假
iota //用在连续的枚举类型声明中
nil //指针/引用型的变量的默认值是nil
空白标识符
_
用来声明一个匿名的变量,在赋值表达式的左端
关键字
有特定语法意义的标识符,用户不能使用重名的自定义标识符
Go只有25个关键字
程序整体结构的关键字
package //定义包名
import //导入包名
const //常量声明
var //变量声明
func //函数定义
defer //延迟执行
go //并发语法糖
return //函数返回
声明复合结构的关键字
struct //定义结构类型
interface //定义接口类型
map //声明或创建map类型
chan //声明或创建通道类型
控制程序结构的关键字
if else for range continue break switch select type case default fallthrough switch goto
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。

内置函数
内置函数就是高级语言的一种语法糖,不需要import引入
- append-用来追加元素到数组、slice中,返回修改后的数组、slice
- close-主要用来关闭channel
- delete-从map中删除key对应的value
- panic-停止常规的goroutine (panic和recover:用来做错误处理)
- recover-允许程序定义goroutine的panic动作
- real-返回complex的实部 (complex、real imag:用于创建和操作复数)
- imag-返回complex的虚部
- make-用来分配内存,返回Type本身(只能应用于slice, map, channel)
- new-用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
- cap-capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
- copy-用于复制和连接slice,返回复制的数目
- len-来求长度,比如string、array、slice、map、channel ,返回长度
- print、println-底层打印函数,在部署环境中建议使用 fmt 包
操作符和分隔符
| 算术运算符 | 含 义 |
|---|---|
| + | 相加 |
| - | 相减 |
| * | 相乘 |
| / | 相除 |
| % | 取余数 |
| ++ | 自增1 |
| -- | 自减1 |
| 比较运算符 | 含 义 |
|---|---|
| == | 相等 |
| != | 不相等 |
| < | 小于 |
| <= | 小于或等于 |
| > | 大于 |
| >= | 大于或等于 |
| 逻辑运算符 | 含 义 |
|---|---|
| && | 逻辑与(AND),当运算符前后两个条件的结果均为 true 时,运算结果为 true |
| || | 逻辑或(OR),当运算符前后两个条件的结果中有一个为 true 时,运算结果为 true |
| ! | 逻辑非(NOT),对运算符后面的条件的结果取反,当条件的结果为 true 时,整体运算结果为 false,否则为 true |
| 位运算符 | 含 义 |
|---|---|
| & | 按位与(AND)操作,其结果是运算符前后的两数各对应的二进制位相与后的结果 |
| | | 按位或(OR)操作,其结果是运算符前后的两数各对应的二进制位相或后的结果 |
| ^ | 按位异或(XOR)操作,当运算符前后的两数各对应的二进制位相等时,返回 0;反之,返回 1 |
| << | 按位左移操作,该操作木质上是将某个数值乘以 2 的 n 次方,n 为左移位数。更直观地来看,其结果就是将某个数值的所有二进制位向左移了 n 个位置,并将超限的高位丢弃,低位补 0 |
| >> | 按位右移操作,该操作本质上是将某个数值除以 2 的 n 次方,n 为右移位数。更直观地来看,其结果就是将某个数值的所有二进制位向右移了 n 个位置,并将超限的低位丢弃,高位补 0 |
| 赋值运算符 | 含 义 |
|---|---|
| = | 直接将运算符右侧的值赋给左侧的变量或表达式 |
| += | 先将运算符左侧的值与右侧的值相加,再将相加和赋给左侧的变量或表达式 |
| -= | 赋给左侧的变量或表达式侧的值相减,再将相减差赋给左侧的变量或表达式 |
| *= | 先将运算符左侧的值与右侧的值相乘,再将相乘结果赋给左侧的变量或表达式 |
| /= | 先将运算符左侧的值与右侧的值相除,再将相除结果赋给左侧的变量或表达式 |
| %= | 先将运算符左侧的值与右侧的值相除取余数,再将余数赋给左侧的变量或表达式 |
| <<= | 先将运算符左侧的值按位左移右侧数值指定数量的位置,再将位移后的结果赋给左侧的变量或表达式 |
| >>= | 先将运算符左侧的值按位右移右侧数值指定数量的位置,再将位移后的结果赋给左侧的变量或表达式 |
| &= | 先将运算符左侧的值与右侧的值按位与,再将位运算后的结果赋给左侧的变量或表达式 |
| |= | 先将运算符左侧的值与右侧的值按位或,再将位运算后的结果赋给左侧的变量或表达式 |
| ^= | 先将运算符左侧的值与右侧的值按位异或,再将位运算后的结果赋给左侧的变量或表达式 |
| 指针运算符 | 含 义 |
|---|---|
| & | 获取某个变量在内存中的实际地址 |
| * | 声明一个指针变量 |
字面常量
整型字面量
表示具体的整形数值
698
0700
0xhello
浮点型字面量
表示一个浮点数值
0.
56.12
056.23
1e6
.25
.5239e5
字符型字面量
采用UTF-8编码,使用单引号括住
'a'
'豪'
'\000'
'\x07'
'\u12e4'
字符串字面量
使用双引号括住
"orz"
"大楚兴"
变量
显式的完整声明
var varName dataType [ = value]示例
var a int = 1
var a int = 4*2
var a int = b短类型声明
varName:=value- 短类型声明只能出现在函数内(包括在方法内)
- Go语言编译器自动对数据类型进行判断
- Go语言支持多个变量同时声明并赋值
a,b:=1,"hello"如果一个对象的指针被多个方法或者线程引用时,那么我们成这个对象的指针发生了逃逸。

常量
Go的常量
- 布尔型
- 字符串型
- 数值型
常量存储在程序的只读段里
.rodata section
ro就是read only(只读)

预声明标识符
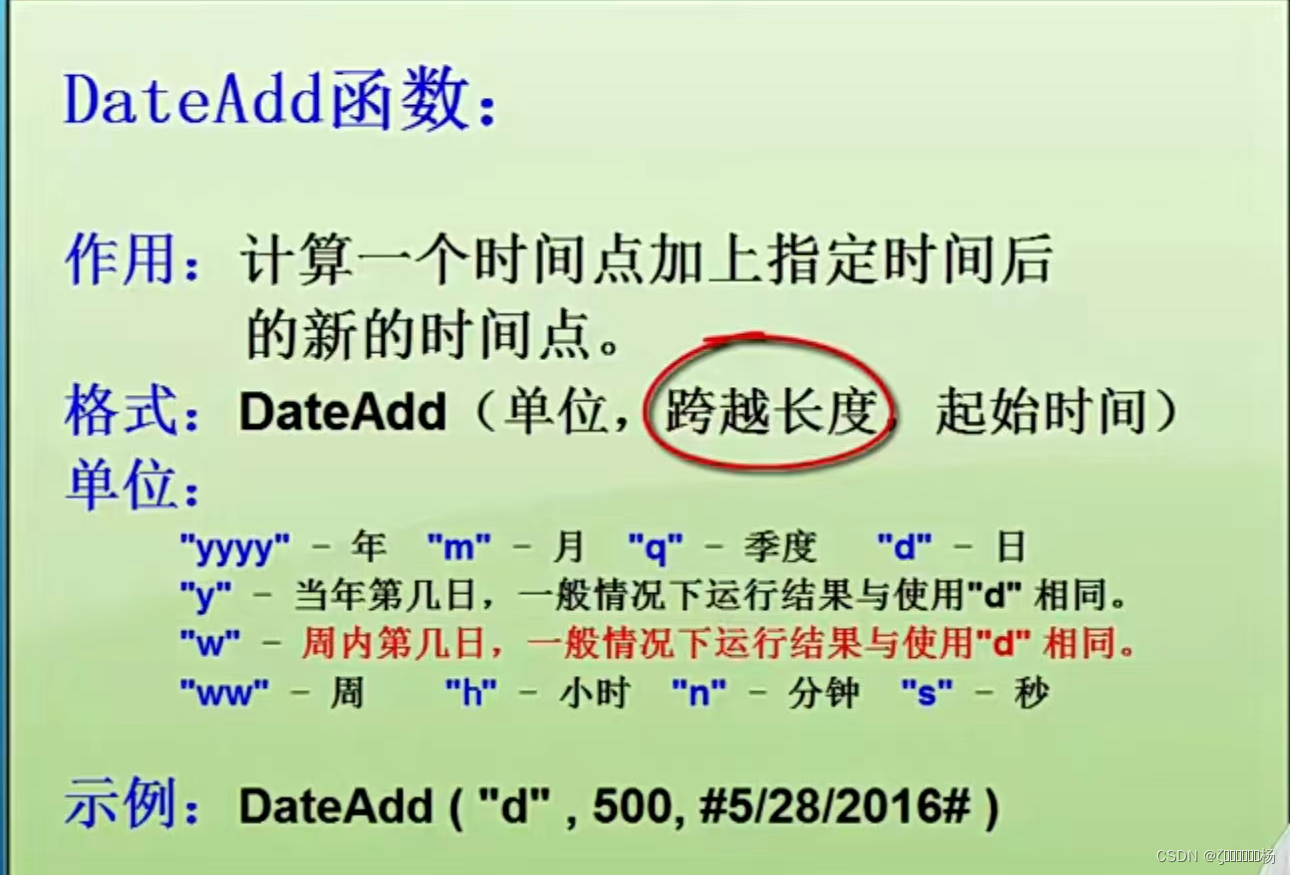
iota
用在常量声明中,初始值是0,可以看成是一个自增枚举变量
const{
a=iota //a==0
b=iota //b==1
c=iota //c==2
}
/* 简写模式*/
const{
a=iota //a==0
b //b==1
c //c==2
}基本数据类型

布尔类型
bool
只有true和false
不初始化,默认是false
整型
byte int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte是uint8的别名
浮点型
float32 float64
- 浮点数字面量被自动类型推断为float64类型
- 浮点数很难精确表示和存储,高精度科学计算应该使用math标准库
复数类型
complex64 complex128
complex128由两个float64组成
var value1 complex64 = 3.1 +5i字符串
Go语言的字符串是一种基本的数据类型
- 字符串是常量,可以用数组索引形式访问当元素,但是不能修改某个字节的值
- 字符串转换成切片[]byte(s)要慎用,尤其是当数据量较大时
- 字符串结尾不含NULL字符
- 字符串的底层实现是一个二元数据结构
type stringStruct struct{ str unsafe.Pointer //指向底层字节数组的指针 len int //字节数组的长度 } - 基于字符串的切片和原字符串指向相同的底层字符数组,也不能修改
a:="Hello World" b:=a[0:4]
遍历一个字符串
d:="Hello World"
for i:=0;i<=len(d);i++{
fmt.Println(d[i])
}统一码(Unicode),也叫万国码、单一码。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
将世界上所有的文字用2个字节统一进行编码。那样,像这样统一编码,2个字节就已经足够容纳世界上所有语言的大部分文字了。

rune类型
Go内置两种字符类型,一种是byte字节类型,一种是表示Unicode编码的字符rune
rune是uint32的别名
Go语言默认的字符编码是UTF-8类型
复合数据类型
Go语言基本的复合数据类型有指针,数组,切片,字典,通道,结构和接口
指针
声明类型为*T
Go语言支持多级指针**T
- *T出现在"="左边表示指针声明,*T出现在“=”表示指针指向的值
var a = 11 p:=&a - 结构体的指针访问同C语言一样采用‘.’操作符
type User struct{ name string age int } stu:=User{ name:"Peter", age:18, } p:=&stu fmt.Println(p.name) - Go语言不允许指针的运算
a:=4543 p:=&a p++ //不允许此操作 - 允许函数返回局部变量的地址
数组
[n]elemetype
示例
var arr [2]int
array := [...]float64{7.0,8.5,9.1}map
map创建
ma:=map[string]int{"a":1,"b":2}结构控制语句
程序的执行在本质上就是顺序和跳转,循环也是一种跳转
if语句
- if后面的条件判断子句不需要用小括号括起来
- {必须放在if或者if else这行的行尾
- Go语言没有三元运算符?:
- if后面可以带一个简单的初始化语句,用分号来分割,作用域是整个if语句块
if x<=y{
return y
}else{
return x
}
if x:=f();x<y{
return x
}else if x>z{
return z
}else{
return y
}switch语句
- 支持default语句
- 条件表达式不一定是整数
- fallthough语句来强制执行下一个case子句
- switch后面也可以带一个初始化语句
switch{
case score>=90:
grade='A'
case score>=80:
grade='B'
case score>=70:
grade='C'
case score>=60:
grade='D'
default:
grade='F'
}for语句
Go语言仅支持一种循环语句,for语句
Go语言的设计哲学,只提供一种方法将事情解决好
for init;condition;post{ //类似C语言中的for
}
for condition{ //类似C语言中的while
}
for{ //死循环
}标签和跳转
goto语句用于函数内部的跳转,需要配合使用标签
goto Lable
break 跳出循环
continue 跳出for switch语句
continue 跳出本次循环
本文包含了Go语言最基础的语法,变量类型和条件控制
未完待续