论文:Evaluating the Text-to-SQL Capabilities of Large Language Models
⭐⭐⭐⭐
arXiv:2204.00498
一、论文速读
本论文尝试了多种 prompt 结构,并且评估了他们在 Codex 和 GPT-3 上的表现。下面介绍这些 prompt 结构:
二、不同的 prompt 结构
2.1 Question 类型

这种 prompt 不提供数据库信息,只是以 SQL 注释的形式提供了一个 question。
2.2 API Docs 类型

这种风格遵循了 Codex 文档中 Text2SQL 示例的风格,并且以不符合 SQLite 标准的注释风格包含 DB schema。
2.3 Select X 类型
以 Select 3 为例:
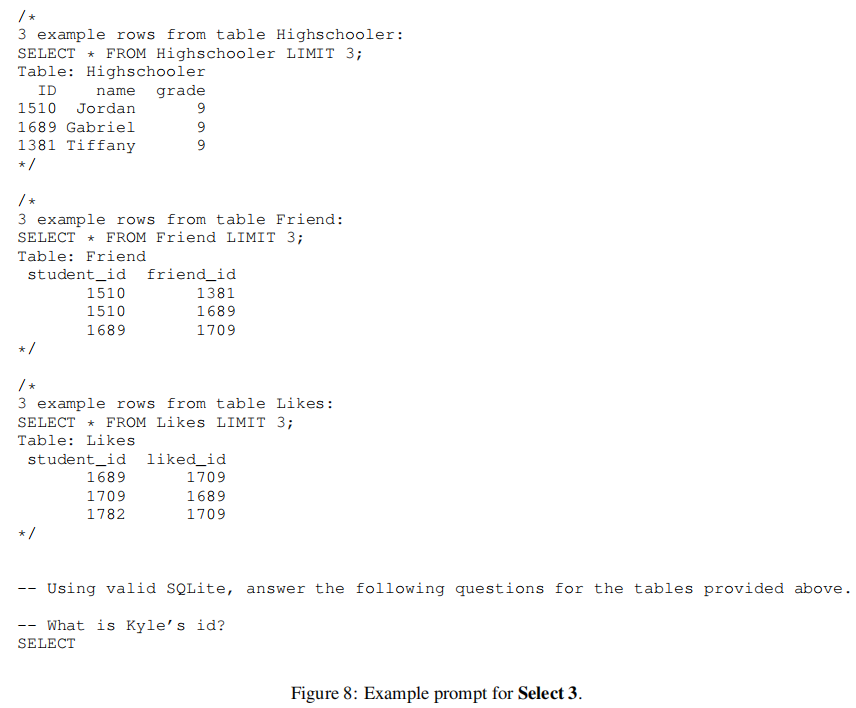
以注释的形式,给出了对每个 table 执行 SELECT * FROM T LIMIT X 的结果以及 table headers。
2.4 Create Table 类型
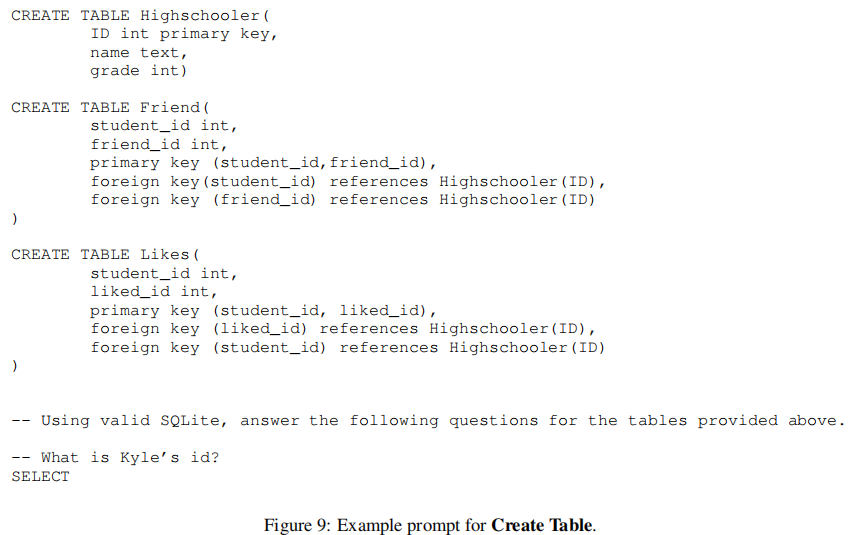
包含了每个 table 的 CREATE TABLE 命令,里面包含了 column type 和 foreign key 的声明。
2.5 Create Table + Select X 类型
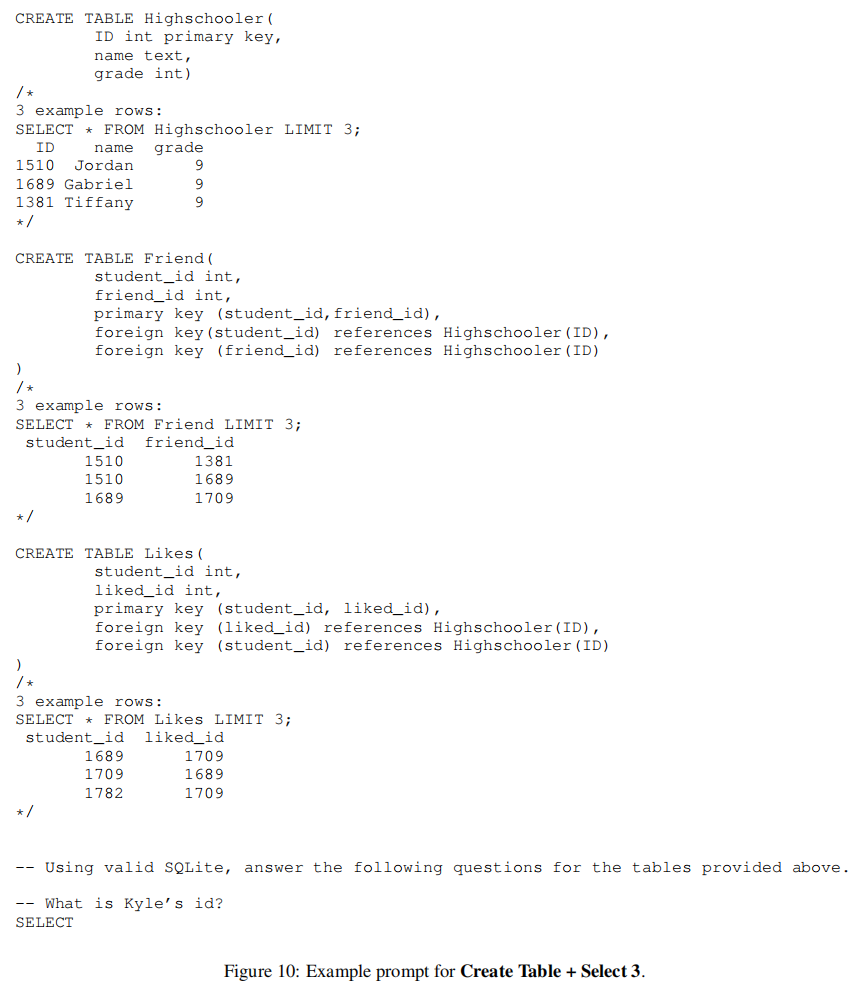
这是上述两种 prompt 格式的组合。
2.6 Few-shot 类型

这种就是包含了几个 NL question 和 result 的 pairs 作为 few-shot demonstrations。
三、实验结果
3.1 Zero-shot 的结果
下表展示了不同模型大小在 Spider 上的比较结果:
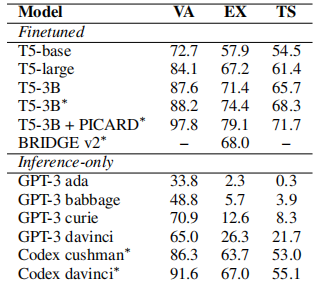
可以看到,Codex davinci 版本表现最好,所以 Codex 为 Text2SQL 任务提供了强大的基准。
下表展示了在 Codex davinci 上设置不同的 prompt style 的表现:
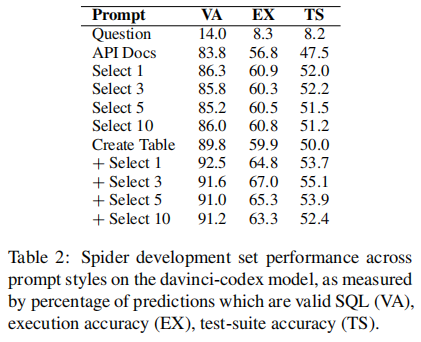
这可以明显感觉到,prompt style 对性能至关重要:Question 类型的只有 8.3% 的执行精度,而在 API Docs 类型中引入 schema info 后,这一性能提升了 59.9%。
此外,在 SELECT X 的 style 中,可以观察到在添加更多 rows 时,性能的变化可以忽略不计。但在 CREATE TABLE + SELECT X 中,最好的是 3 rows,随着添加更多 rows,性能显著会下降。
3.2 Few-shots 的结果
在 Codex 上使用 few-shots 类型的 prompts,基于 Create Table + Select X 风格,在 n 个 question-query pairs 附加到输入上。
下图是在 GeoQuery 和 Scholar 两个数据集上,将微调的 T5 作为 baseline 的比较结果(横轴是 demonstrations 的个数):
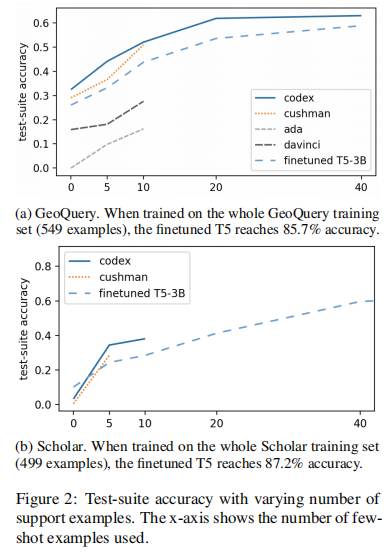
Codex 在 few samples 中比 T5 显示出更好的适应性,并超越了 T5 baseline。
四、结论
论文指出,在代码上训练的 LLM 为 Text2SQL 任务提供了强大的 baseline,论文中还对 error cases 做了分析。
论文也指出,与传统的基于微调小模型的少样本学习相比,用这些 LLM 进行基于 prompt 的 few-shot learning 表现出竞争力。