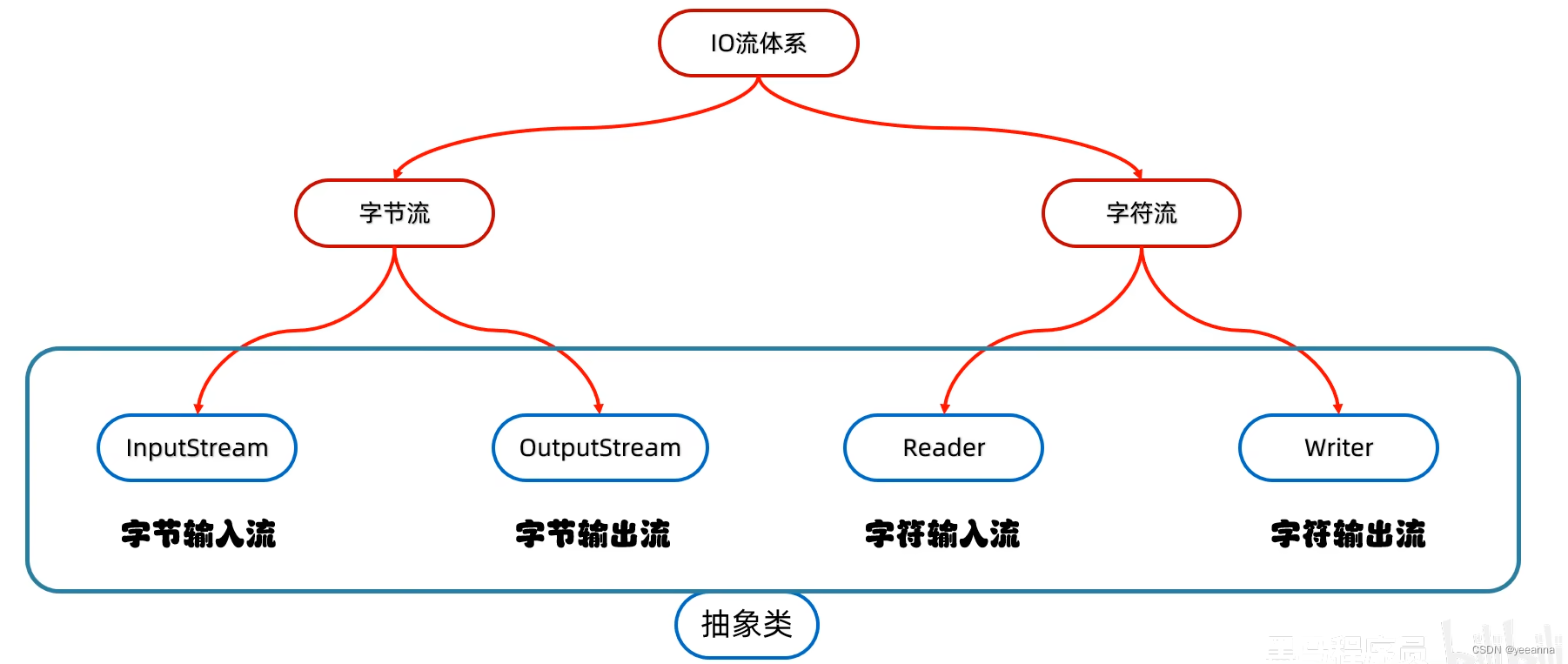
IO流
IO流
-
什么是IO流?
存储和读取数据的解决方案I:input
O:output
流:像水流一样传输数据
-
IO流的作用?
用于读写数据(本地文件,网络)
-
IO流按照流向可以分类哪两种流?
输出流:程序 -> 文件
输入流:文件 -> 程序
-
IO流按照操作文件的类型可以分类哪两种流?
字节流:可以操作所有类型的文件
字符流:只能操作纯文本文件
-
什么是纯文本文件?
用windows系统自带的记事本打开并且能读懂的文件
txt文件,md文件,xml文件,lrc文件等
(word, excel不是纯文本文件)
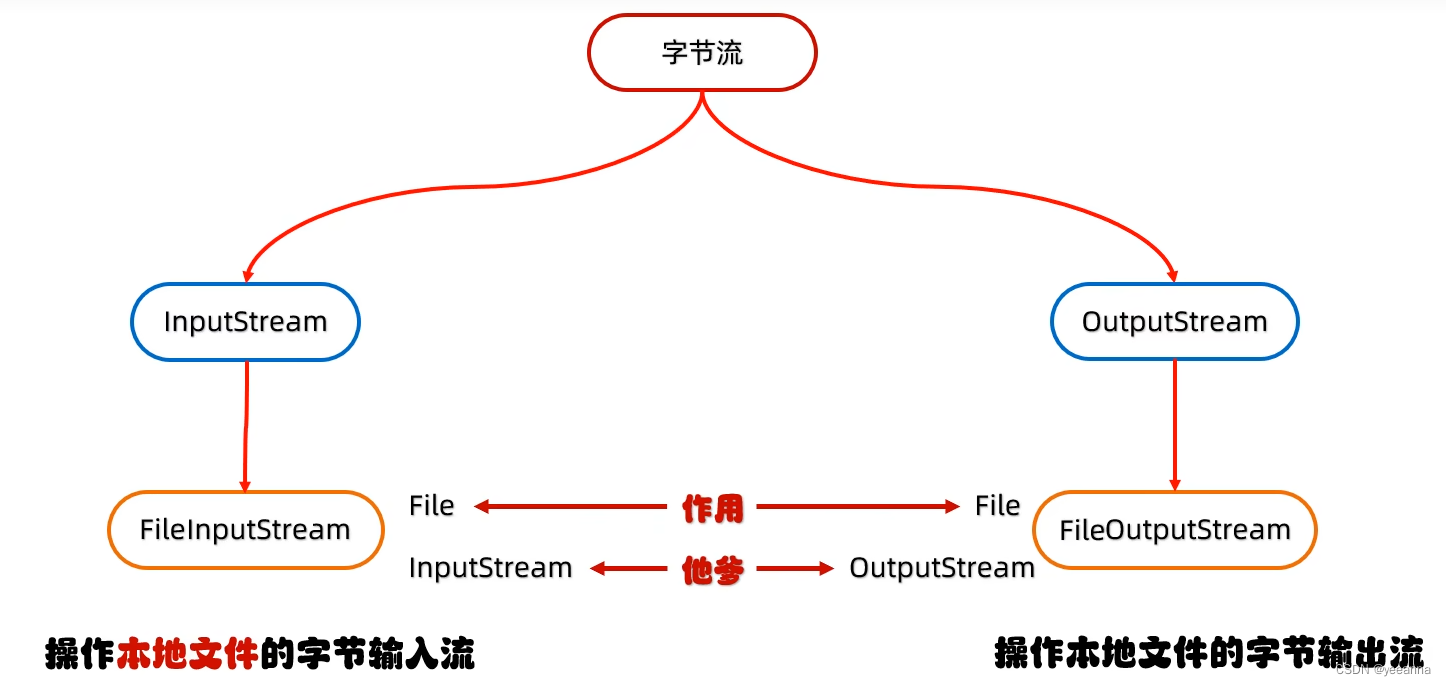
字节流
1.字节输出流
-
字节输出流FileOutputStream:操作本地文件的字节输出流,可以把程序中的数据写到本地文件中
书写步骤:- 创建字节输出流对象
- 写数据
- 创建资源
例子:写出一段文字到本地文件中。(暂时不写中文)
public static void main(String[] args) throws IOException { /* * 演示:字节输出流FileOutputStream * 实现需求:写出一段文字到本地文件中。(暂时不写中文) * * 实现步骤: * 创建对象 * 写出数据 * 释放资源 * */ //1.创建对象 //写出 输出流 OutputStream //本地文件 File // 注:FileOutputStream 要抛出异常IOException FileOutputStream fos = new FileOutputStream("myio\\a.txt"); //2.写出数据 fos.write(97); //a //3.释放资源 fos.close(); } -
字节输出流的细节:
- 创建字节输出流对象
细节1:参数是字符串表示的路径或者是File对象都是可以的
细节2:如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的。
细节3:如果文件已经存在,则会清空文件 - 写数据
细节:write方法的参数是整数,但是实际上写到本地文件中的是整数在ASCII上对应的字符
如果真的要写数字,就要把每个数字位看成字符,写数字的ASCII码
‘9’:57
‘7’:55 - 释放资源
每次使用完流之后都要释放资源,否则建立连接的通道不会关闭,占用内存
- 创建字节输出流对象
-
FileOutputStream写数据的3种方式:
 (注意第三种方式的参数可能和你想的不一样,第二个参数是起始索引,第三个参数是长度)
(注意第三种方式的参数可能和你想的不一样,第二个参数是起始索引,第三个参数是长度)public static void main(String[] args) throws IOException { /* void write(int b) 一次写一个字节数据 void write(byte[] b) 一次写一个字节数组数据 void write(byte[] b, int off, int len) 一次写一个字节数组的部分数据 参数一: 数组 参数二: 起始索引 0 参数三: 个数 3 */ //1.创建对象 FileOutputStream fos = new FileOutputStream("myio\\a.txt"); //2.写出数据 //fos.write(97); // a //fos.write(98); // b byte[] bytes = {97, 98, 99, 100, 101}; /* fos.write(bytes);*/ fos.write(bytes,1,2);// b c //3.释放资源 fos.close(); } -
两个问题:如何换行?如何续写?
-
换行写:
再次写出一个换行符就可以了windows: \r\n Linux: \n Mac: \r- 细节
在windows操作系统当中,java对回车换行进行了优化。
虽然完整的是\r\n,但是我们写其中一个\r或者\n,
java也可以实现换行,因为java在底层会补全。 - 建议:
不要省略,还是写全了。
- 细节
-
续写:
如果想要续写,打开续写开关即可
开关位置:创建对象的第二个参数
默认false:表示关闭续写,此时创建对象会清空文件
手动传递true:表示打开续写,此时创建对象不会清空文件
public static void main(String[] args) throws IOException { /* 换行写: 再次写出一个换行符就可以了 windows: \r\n Linux: \n Mac: \r 细节: 在windows操作系统当中,java对回车换行进行了优化。 虽然完整的是\r\n,但是我们写其中一个\r或者\n, java也可以实现换行,因为java在底层会补全。 建议: 不要省略,还是写全了。 续写: 如果想要续写,打开续写开关即可 开关位置:创建对象的第二个参数 默认false:表示关闭续写,此时创建对象会清空文件 手动传递true:表示打开续写,此时创建对象不会清空文件 */ //1.创建对象 FileOutputStream fos = new FileOutputStream("myio\\a.txt",true); //2.写出数据 String str = "kankelaoyezuishuai"; byte[] bytes1 = str.getBytes(); fos.write(bytes1); //再次写出一个换行符就可以了 String wrap = "\r\n"; byte[] bytes2 = wrap.getBytes(); fos.write(bytes2); String str2 = "666"; byte[] bytes3 = str2.getBytes(); fos.write(bytes3); //3.释放资源 fos.close(); } -
2.字节输入流
- 字节输出流FileInputStream:操作本地文件的字节输入流,可以把本地文件中的数据读到程序中
书写步骤:- 创建字节输出流对象
- 细节:如果文件不存在,直接报错
- 读数据
- 细节1:一次读一个字节,读出来的数据是在ASCII上对应的数字,如果想显示原内容,可以用(char)强转
- 细节2:读到文件末尾了,read方法返回-1.
- 创建资源
- 每次使用完流必须释放资源
- 创建字节输出流对象
例子:读文本中的数据
public static void main(String[] args) throws IOException {
/*
* 演示:字节输入流FileInputStream
* 实现需求:读取文件中的数据。(暂时不写中文)
*
* 实现步骤:
* 创建对象
* 读取数据
* 释放资源
* */
//1.创建对象
FileInputStream fis = new FileInputStream("myio\\a.txt");
//2.读取数据
int b1 = fis.read();
System.out.println((char)b1);
int b2 = fis.read();
System.out.println((char)b2);
int b3 = fis.read();
System.out.println((char)b3);
int b4 = fis.read();
System.out.println((char)b4);
int b5 = fis.read();
System.out.println((char)b5);
int b6 = fis.read();
System.out.println(b6);//-1
//3.释放资源
fis.close();
}
-
FileInputStream循环读取
public static void main(String[] args) throws IOException { /* 字节输入流循环读取 */ //1.创建对象 FileInputStream fis = new FileInputStream("myio\\a.txt"); //2.循环读取 int b; while ((b = fis.read()) != -1) { System.out.println((char) b); } //3.释放资源 fis.close(); }问题:不定义变量b可不可以?
/* * read :表示读取数据,而且是读取一个数据就移动一次指针 * * */ FileInputStream fis = new FileInputStream("myio\\a.txt"); //2.循环读取 while ((fis.read()) != -1) { System.out.println(fis.read());//98 100 -1 } //3.释放资源 fis.close();答:不可以。因为 read读取数据,读取一个数据就移动一次指针,因此调用两次fis.read()后指针移动了两次,不能完整输出数据
-
文件拷贝
细节:先打开的后关闭
(以下代码边读边写,一个字节一个字节读写,效率太低,只能拷贝小文件)public static void main(String[] args) throws IOException { /* * 练习: * 文件拷贝 * 把D:\itheima\movie.mp4拷贝到当前模块下。 * * 注意: * 选择一个比较小的文件,不要太大。大文件拷贝我们下一个视频会说。 * * * * 课堂练习: * 要求统计一下拷贝时间,单位毫秒 * */ long start = System.currentTimeMillis(); //1.创建对象 FileInputStream fis = new FileInputStream("D:\\itheima\\movie.mp4"); FileOutputStream fos = new FileOutputStream("myio\\copy.mp4"); //2.拷贝 //核心思想:边读边写 int b; while((b = fis.read()) != -1){ fos.write(b); } //3.释放资源 //规则:先开的最后关闭 fos.close(); fis.close(); long end = System.currentTimeMillis(); System.out.println(end - start); }解决方式: public int read(byte[] buffer) 一次读一个字节数组数据,返回值是读取的字节长度
如果读到最后不够字节数组的长度了,那么只会读取剩下的字节,返回的是剩下的字节长度。此时数组里面还存在上次读取的字节,这样最后一次就会多拷贝出来一些东西。因此用String str1 = new String(bytes,0,len1)、fos.write(bytes, 0, len)确保最后一次读取的是正确的字节数。public static void main(String[] args) throws IOException { /* public int read(byte[] buffer) 一次读一个字节数组数据 */ //1.创建对象 FileInputStream fis = new FileInputStream("myio\\a.txt"); //2.读取数据 byte[] bytes = new byte[2]; //一次读取多个字节数据,具体读多少,跟数组的长度有关 //返回值:本次读取到了多少个字节数据 int len1 = fis.read(bytes); System.out.println(len1);//2 String str1 = new String(bytes,0,len1); System.out.println(str1); int len2 = fis.read(bytes); System.out.println(len2);//2 String str2 = new String(bytes,0,len2); System.out.println(str2); int len3 = fis.read(bytes); System.out.println(len3);// 1 String str3 = new String(bytes,0,len3); System.out.println(str3);// ed //3.释放资源 fis.close(); }拷贝大文件:
public static void main(String[] args) throws IOException { /* * 练习: * 文件拷贝 * 把D:\itheima\movie.mp4 (16.8 MB) 拷贝到当前模块下。 * * */ long start = System.currentTimeMillis(); //1.创建对象 FileInputStream fis = new FileInputStream("D:\\itheima\\movie.mp4"); FileOutputStream fos = new FileOutputStream("myio\\copy.mp4"); //2.拷贝 int len; byte[] bytes = new byte[1024 * 1024 * 5]; while((len = fis.read(bytes)) != -1){ fos.write(bytes,0,len); } //3.释放资源 fos.close(); fis.close(); long end = System.currentTimeMillis(); System.out.println(end - start); } -
IO流try…catch异常处理注意事项(了解):释放资源语句要放在finally里确保一定会被执行。
无论try里有没有异常,finally里的代码一定会被执行,除非虚拟机停止
public static void main(String[] args) {
/*
* 利用try...catch...finally捕获拷贝文件中代码出现的异常
*/
//1.创建对象
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("D:\\itheima\\movie.mp4");
fos = new FileOutputStream("myio\\copy.mp4");
//2.拷贝
int len;
byte[] bytes = new byte[1024 * 1024 * 5];
while((len = fis.read(bytes)) != -1){
fos.write(bytes,0,len);
}
} catch (IOException e) {
//e.printStackTrace();
} finally {
//3.释放资源
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//如果创建fis/fos的路径不存在时就不会创建字节流,这样fis和fos就还是null
//如果不加以判断就会出现空指针异常的错误,所以要加个非空判断
if(fis != null){
try {
//fis.close()也会有异常出现,所以在finally里又嵌套了一个try catch捕获异常
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
上述代码的简化:AutoCloseable,不需要写finally,自动释放
JDK7:实现了AutoCloseable的类才能在try()中创建对象
JDK9:JDK7不好阅读,所以把创建流对象放外面了

public static void main(String[] args) {
/*
*
* JDK7:IO流中捕获异常的写法
*
* try后面的小括号中写创建对象的代码,
* 注意:只有实现了AutoCloseable接口的类,才能在小括号中创建对象。
* try(){
*
* }catch(){
*
* }
*
* */
try (FileInputStream fis = new FileInputStream("D:\\itheima\\movie.mp4");
FileOutputStream fos = new FileOutputStream("myio\\copy.mp4")) {
//2.拷贝
int len;
byte[] bytes = new byte[1024 * 1024 * 5];
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
字符集
计算机存储规则:任意数据都是以二进制形式存储的
字节:计算机中最小的存储单位,1字节(byte)=8比特(bit)
存储英文一个字节就够了(ASCII码只有128个)
- ASCII码存储规则:


咱汉字怎么存?
1、GB2312字符集,1980年发布,1981年5月1日实施的简体中文汉字编码国家标准。收录7445个图形字符,其中包括6763个简体汉字
2、BIG5字符集:台湾地区繁体中文标准字符集,共收录13053个中文字,1984年实施。
3、GBK字符集,2000年3月17日发布,收录21003个汉字。
包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
windows系统默认使用的就是GBK。系统显示:ANSI
4、Unicode字符集:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
简体中文版Windows用GBK字符集。GBK字符集完全兼容ASCII字符集。
- GBK存储规则:

 制定上述规则的原因:
制定上述规则的原因:
规则1:2个字节是2^16=65535,能容纳所有汉字。一个字节不够用,三个字节浪费,两个字节刚刚好。
规则2:最高位是1还是0用于区分中文还是英文。
如:下面三个字节很容易看出来是一个一个汉字和一个英文
10111010 10111010 01100001

总结:
1.在计算机中,任意数据都是以二进制的形式来存储的
2.计算机中最小的存储单元是一个字节
3.ASCII字符集中,一个英文占一个字节
4.简体中文版Windows,默认使用GBK字符集
5. GBK字符集完全兼容ASCII字符集
一个英文占一个字节,二进制第一位是0
一个中文占两个字节,二进制高位字节的第一位是1
1990年,国际组织研发了Unicode编码来同一各国编码。
- Unicode编码
UTF-16:16个bit(2字节)存储(浪费空间)
UTF-32:32个bit(4字节)存储(浪费空间)
UTF-8:1~4个字节保存。不同的语言用不同字节数保存。在UTF-8编码中,英文占1个字节,中文占3个字节。中文第一个字节的首位是1,英文是0。

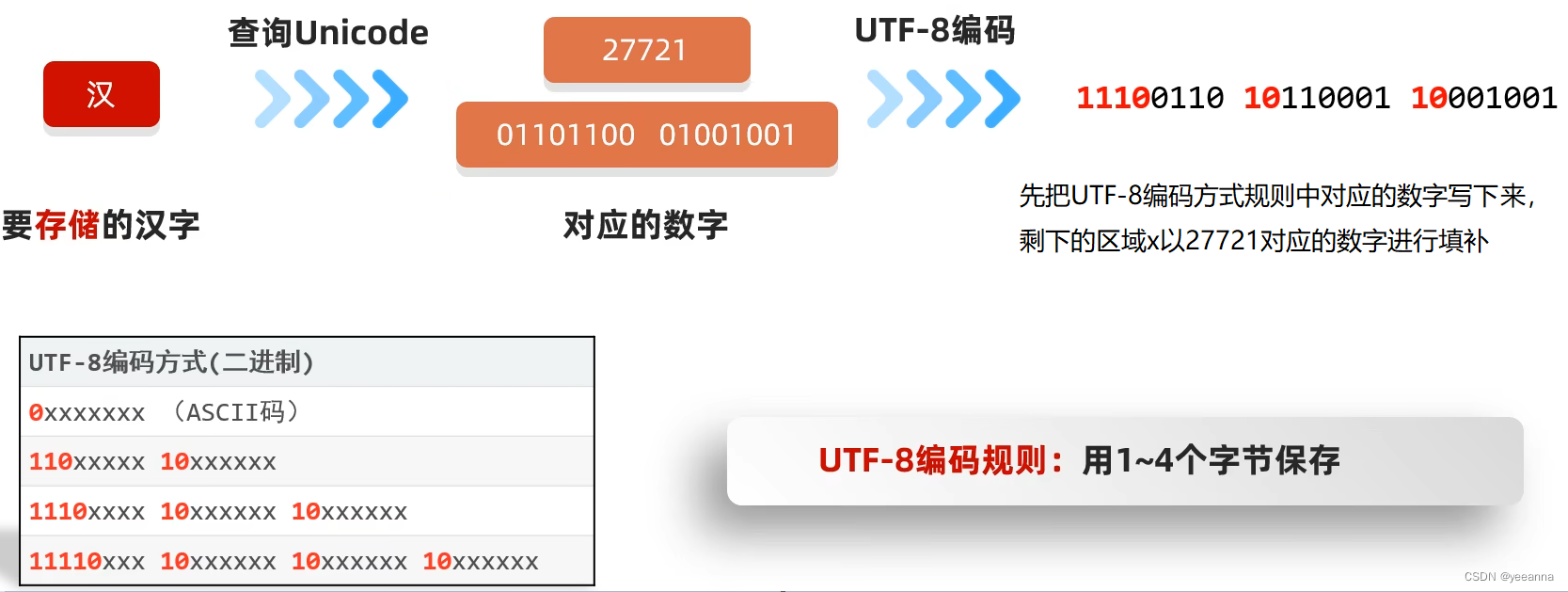
问:1、UTF-8是一个字符集吗?
不是,UTF-8是Unicode字符集的一种编码方式。
2、以下Unicode字符集UTF-8编码规则,有几个中文几个英文?
01001010 01100001 01110110 01100001 4个英文
01001010 01001010 11100110 11001000 11100001 2个英文1个中文
乱码出现的原因:
读取数据时未读完整个汉字
编码和解码时的方式不统一