目录
- 赛题链接
- 赛题背景
- 数据集探索
- 合并多个类别CSV数据集
- 数据建模 (pytorch)
赛题链接
https://www.kaggle.com/competitions/quickdraw-doodle-recognition/overview/evaluation
数据集从上述链接中找
赛题背景
'Quick,Draw!'作为实验性游戏发布,以有趣的方式向公众宣传 AI 的工作原理。游戏提示用户绘制描绘特定类别的图像,例如“香蕉”、“桌子”等。游戏生成了超过 1B 幅图画,其中的一个子集被公开发布,作为本次比赛训练集的基础。该子集包含 5000 万张图纸,涵盖 340 个标签类别。
听起来很有趣,对吧?挑战在于:由于训练数据来自游戏本身,绘图可能不完整或可能与标签不匹配。您需要构建一个识别器,它可以有效地从这些嘈杂的数据中学习,并在来自不同分布的手动标记的测试集上表现良好。
您的任务是为现有的 Quick, Draw! 构建一个更好的分类器。数据集。通过在此数据集上推进模型,Kagglers 可以更广泛地改进模式识别解决方案。这将对手写识别及其在 OCR(光学字符识别)、ASR(自动语音识别)和 NLP(自然语言处理)等领域的稳健应用产生直接影响。

属于多分类问题
数据集探索
字段解释:
| Key | Type | Description |
|---|---|---|
| key_id | 64 位无符号整数 | 所有图纸的唯一标识符。 |
| word | string | 玩家绘制的类别。 |
| recognized | boolean | 该词是否被游戏识别。 |
| timestamp | datetime | 创建绘图时间 |
| countrycode | string | 玩家所在位置的两个字母国家代码 |
| drawing | string | 表示矢量绘图的 JSON 数组 |
example:
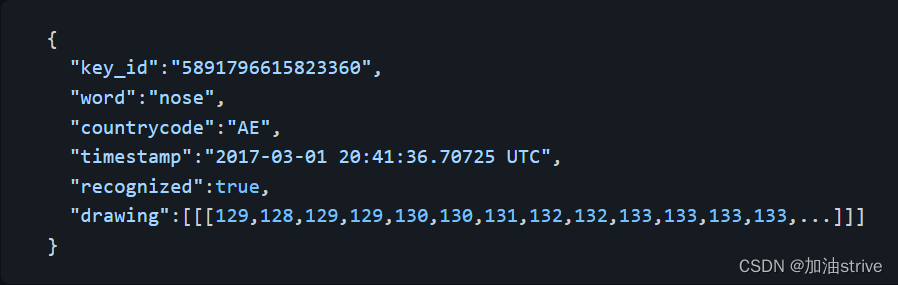
根据矢量绘图的JSON数组画图
def show_imale(n,owls,drawing):
fig,axs = plt.subplots(nrows=n,ncols=n,sharex=True,sharey=True,figsize = (16.10))
for i , drawing in enumerate(owls,drawing):
ax = axs[i//n,i%n]
for x,y in drawing:
ax.plot(x,-np.array(y),lw=3)
fig.savefig('owls.png',dpi=200)
plt.show();

赛题建模思路:
- 读取数据并转化为图像
- 构建分类模型
- 确定训练细节和数据扩增方法;
- 对测试集完成预测并完成模型集成
数据集的文件结构:
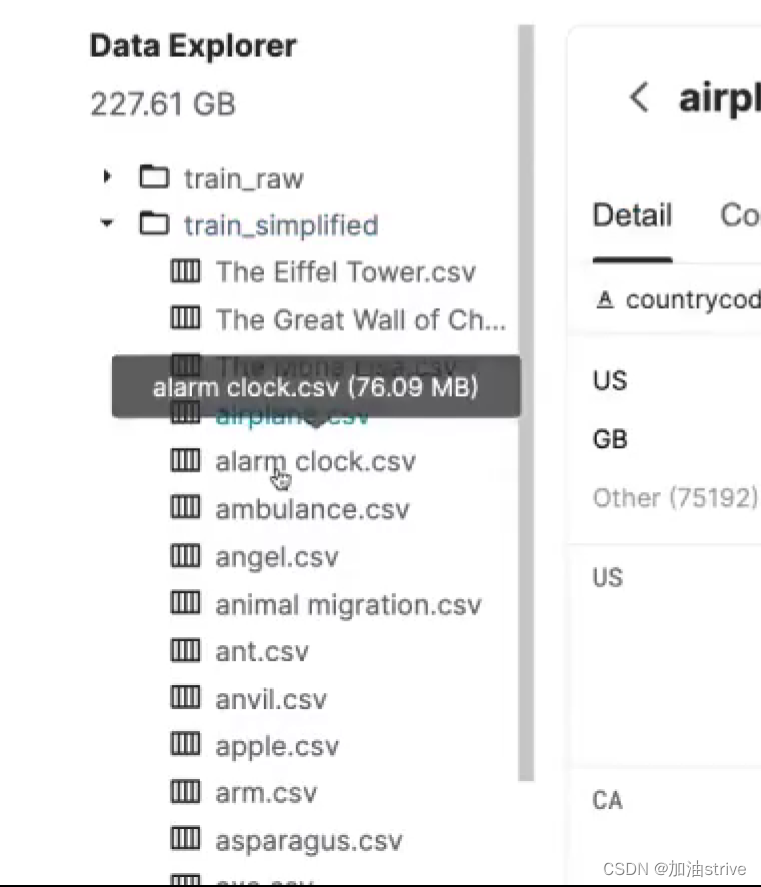
每一种类型的数据图片,都放在一个单独的csv中,下面要对整个数据集进行处理。
合并多个类别CSV数据集
import os, sys, codecs, glob
import numpy as np
import pandas as pd
import cv2
import timm
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 读取单个csv文件
def read_df(path, nrows):
print('Reading...', path)
if nrows.isdigit():
return pd.read_csv(path, nrows=int(nrows), parse_dates=['timestamp'])
else:
return pd.read_csv(path, parse_dates=['timestamp'])
# 读取多个csv文件
def contcat_df(paths, nrows):
dfs = []
for path in paths:
dfs.append(read_df(path, nrows))
return pd.concat(dfs, axis=0, ignore_index=True)
def main():
if not os.path.exists('./data'):
os.mkdir('./data')
CLASSES_CSV = glob.glob('../input/train_simplified/*.csv')
CLASSES = [x.split('/')[-1][:-4] for x in CLASSES_CSV]
print('Reading data...')
# 读取指定行数的csv文本,并进行拼接
df = contcat_df(CLASSES_CSV, number)
# 数据打乱
df = df.reindex(np.random.permutation(df.index))
lbl = LabelEncoder().fit(df['word'])
df['word'] = lbl.transform(df['word'])
if df.shape[0] * 0.05 < 120000:
df_train, df_val = train_test_split(df, test_size=0.05)
else:
df_train, df_val = df.iloc[:-500000], df.iloc[-500000:]
print('Train:', df_train.shape[0], 'Val', df_val.shape[0])
print('Save data...')
df_train.to_pickle(os.path.join('./data', 'train_' + str(number) + '.pkl'))
df_val.to_pickle(os.path.join('./data', 'val_' + str(number) + '.pkl'))
# python 1_save2df.py 50000
# python 1_save2df.py all
if __name__ == "__main__":
number = str(sys.argv[1])
main()
其中glob的作用如下注释所示
import glob
#获取指定目录下的所有图片
print (glob.glob(r"/home/qiaoyunhao/*/*.png"),"\n")#加上r让字符串不转义
#获取上级目录的所有.py文件
print (glob.glob(r'../*.py')) #相对路径
得到的结果如下所示:
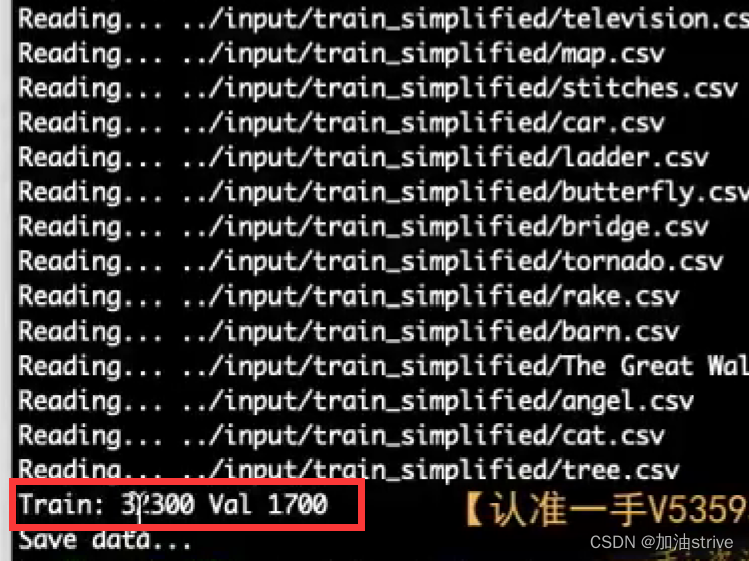
32300个训练集,1700个测试集
这里我们是先采用少量数据集训练,试一下数据是否拟合,若拟合
数据建模 (pytorch)
导入所需库
import os, sys, codecs, glob
from PIL import Image, ImageDraw
import numpy as np
import pandas as pd
import cv2
import torch
torch.backends.cudnn.benchmark = False
import timm
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
import logging
logging.basicConfig(level=logging.DEBUG, filename='example.log',
format='%(asctime)s - %(filename)s[line:%(lineno)d]: %(message)s')
将绘图的轨迹转变为图片
这里用的是opencv,cv的处理速度大于pillow
def draw_cv2(raw_strokes, size=256, lw=6, time_color=True):
BASE_SIZE = 299
img = np.zeros((BASE_SIZE, BASE_SIZE), np.uint8)
for t, stroke in enumerate(eval(raw_strokes)):
str_len = len(stroke[0])
for i in range(len(stroke[0]) - 1):
# 数据集随机丢弃一些像素,属于数据集的drop out,防止过拟合
if np.random.uniform() > 0.95:
continue
color = 255 - min(t, 10) * 13 if time_color else 255
_ = cv2.line(img, (stroke[0][i] + 22, stroke[1][i] + 22),
(stroke[0][i + 1] + 22, stroke[1][i + 1] + 22), color, lw)
if size != BASE_SIZE:
return cv2.resize(img, (size, size))
else:
return img
计算topk准确率
def accuracy(output, target, topk=(1,)):
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
# print(correct.shape)
res = []
for k in topk:
# print(correct[:k].shape)
correct_k = correct[:k].float().sum()
res.append(correct_k.mul_(100.0 / batch_size))
# print(res)
return res
数据扩展
class QRDataset(Dataset):
def __init__(self, img_drawing, img_label, img_size, transform=None):
self.img_drawing = img_drawing
self.img_label = img_label
self.img_size = img_size
self.transform = transform
def __getitem__(self, index):
img = np.zeros((self.img_size, self.img_size, 3))
img[:, :, 0] = draw_cv2(self.img_drawing[index], self.img_size)
img[:, :, 1] = img[:, :, 0]
img[:, :, 2] = img[:, :, 0]
img = Image.fromarray(np.uint8(img))
if self.transform is not None:
img = self.transform(img)
label = torch.from_numpy(np.array([self.img_label[index]]))
return img, label
def __len__(self):
return len(self.img_drawing)
载入模型
def get_resnet18():
model = models.resnet18(True)
model.avgpool = nn.AdaptiveAvgPool2d(1) # 匹配不固定的输入尺寸
model.fc = nn.Linear(512, 340)
return model
def get_resnet34():
model = models.resnet34(True)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(512, 340)
return model
def get_resnet50():
model = models.resnet50(True)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(2048, 340)
return model
def get_resnet101():
model = models.resnet101(True)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(2048, 340)
图片mixup操作
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
# x 是一个batch 一批的输入
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
主函数
- 数据扩展
def main():
df_train = pd.read_pickle(os.path.join('./data', 'train_' + dataset + '.pkl'))
# df_train = df_train.reindex(np.random.permutation(df_train.index))
df_val = pd.read_pickle(os.path.join('./data', 'val_' + dataset + '.pkl'))
train_loader = torch.utils.data.DataLoader(
QRDataset(df_train['drawing'].values, df_train['word'].values, imgsize,
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
# transforms.RandomAffine(5, scale=[0.95, 1.05]),
transforms.ToTensor(),
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
),
batch_size=200, shuffle=True, num_workers=5,
)
val_loader = torch.utils.data.DataLoader(
QRDataset(df_val['drawing'].values, df_val['word'].values, imgsize,
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
),
batch_size=200, shuffle=False, num_workers=5,
)
载入模型
if modelname == 'resnet18':
model = get_resnet18()
elif modelname == 'resnet34':
model = get_resnet34()
elif modelname == 'resnet50':
model = get_resnet50()
elif modelname == 'resnet101':
model = get_resnet101()
else:
model = timm.create_model(modelname, num_classes=340, pretrained=True, in_chans=3)
设置优化器等损失函数
# model = nn.DataParallel(model).cuda()
# nvismodel.load_state_dict(torch.load('./resnet50_64_7_0.pt'))
# model.load_state_dict(torch.load('./data/resnet18_64_16_110.pt'))
model = model.cuda()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[2, 3, 5, 7, 8], gamma=0.1)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=len(train_loader) / 10, gamma=0.95)
print('Train:', df_train.shape[0], 'Val', df_val.shape[0])
print('Epoch/Batch\t\tTrain: loss/Top1/Top3\t\tTest: loss/Top1/Top3')
训练50次
for epoch in range(50):
train_losss, train_acc1s, train_acc5s = [], [], []
for i, data in enumerate(train_loader):
scheduler.step()
model = model.train()
train_img, train_label = data
optimizer.zero_grad()
# TODO: data paraell
# train_img = Variable(train_img).cuda(async=True)
# train_label = Variable(train_label.view(-1)).cuda()
train_img = Variable(train_img).cuda()
train_label = Variable(train_label.view(-1)).cuda()
# 加入mixup
if np.random.randint(1, 10) >= 5:
mixed_x, y_a, y_b, lam = mixup_data(train_img, train_label)
output = model(mixed_x)
train_loss = mixup_criterion(loss_fn, output, y_a, y_b, lam)
else:
output = model(train_img)
train_loss = loss_fn(output, train_label)
# output = model(train_img)
# train_loss = loss_fn(output, train_label)
train_loss.backward()
optimizer.step()
train_losss.append(train_loss.item())
if i % 5 == 0:
logging.info('{0}/{1}:\t{2}\t{3}.'.format(epoch, i, optimizer.param_groups[0]['lr'], train_losss[-1]))
if i % int(10) == 0:
val_losss, val_acc1s, val_acc5s = [], [], []
with torch.no_grad():
train_acc1, train_acc3 = accuracy(output, train_label, topk=(1, 3))
train_acc1s.append(train_acc1.data.item())
train_acc5s.append(train_acc3.item())
for data in val_loader:
val_images, val_labels = data
# val_images = Variable(val_images).cuda(async=True)
# val_labels = Variable(val_labels.view(-1)).cuda()
val_images = Variable(val_images).cuda()
val_labels = Variable(val_labels.view(-1)).cuda()
output = model(val_images)
val_loss = loss_fn(output, val_labels)
val_acc1, val_acc3 = accuracy(output, val_labels, topk=(1, 3))
val_losss.append(val_loss.item())
val_acc1s.append(val_acc1.item())
val_acc5s.append(val_acc3.item())
logstr = '{0:2s}/{1:6s}\t\t{2:.4f}/{3:.4f}/{4:.4f}\t\t{5:.4f}/{6:.4f}/{7:.4f}'.format(
str(epoch), str(i),
np.mean(train_losss, 0), np.mean(train_acc1s, 0), np.mean(train_acc5s, 0),
np.mean(val_losss, 0), np.mean(val_acc1s, 0), np.mean(val_acc5s, 0),
)
torch.save(model.state_dict(), './data/{0}_{1}_{2}_{3}.pt'.format(modelname, imgsize, epoch, i))
print(logstr)
运行
# python 2_train.py 模型 数量 图片尺寸
# python 2_train.py resnet18 5000 64
if __name__ == "__main__":
modelname = str(sys.argv[1]) # 模型名字
dataset = str(sys.argv[2]) # 数据集规模
imgsize = int(sys.argv[3]) # 图片的尺寸
main()