前言
数据保存在
https://github.com/harkbox/DataAnalyseStudy
数据名称:快餐数据.tsv
(tsv是用\t作为字符分隔符的文件格式;csv是逗号)
因此可以用pandas的read_csv函数读取数据
1.读取数据
import pandas as pd
import matplotlib.pyplot as plot
chipo=pd.read_csv(data_file_name,delimiter='\t')
2.获得数据的一些基本信息
# 查看数据的前5项
chipo.head()
chipo.info()
#产看数据的信息,尤其是缺失值
#产看摘要信息
chipo.describe()
从上述的信息可以发现价格的类型是字符,如果需要用价格进行计算的话,还需要将其转变为float
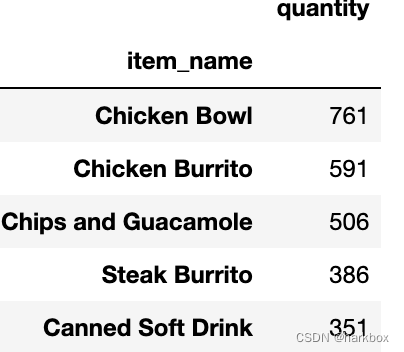
第一个问题:## 1.下单数最多的商品是什么
将商品按照item_name分组,求和,并且排序就能找到最多的商品是什么
chipo_=chipo[['item_name','quantity']].groupby(by='item_name').sum()
chipo_.sort_values('quantity',inplace=True,ascending=False)
chipo_.head()
第二个问题: 在item_name这一列中,一共有多少种商品被下单?
#分组后计数
chipo_.count()
#nunique
chipo['item_name'].nunique()
#unique
len(chipo['item_name'].unique())
第三个问题:将item_price转换为浮点数?
def convert_f(x):
return float(x.strip().replace('$',''))
chipo['item_price']=chipo['item_price'].apply(convert_f)
#2.使用字符串的规律
def convert_f(x):
return float(x[1:-1])
#3.使用str函数里面的strip
chipo['item_price'] =chipo['item_price'].str.strip('$').astype(float)
第四个问题:在该数据集对应的时期内,收入(revenue)是多少?
生成一个新的列,代表总价
chipo['item_total']=chipo['quantity']*chipo['item_price']
chipo['item_total'].sum()
第五个问题: 每一单(order)对应的平均总价是多少?
先对order进行分组,然后计算平均值
chipo[['order_id','item_total']].groupby(by='order_id').mean()
![YOLOv8_obb预测流程-原理解析[旋转目标检测理论篇]](https://img-blog.csdnimg.cn/direct/03ddebdec3124153b1101c6e9606766f.png)