本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html
电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python,机器学习,计算机视觉,深度学习,神经网络,数据挖掘领域.https://blog.csdn.net/LIANG674027206?type=download
这篇论文的核心内容是提出了一种基于麻雀搜寻优化算法(Improved Sparrow Search Algorithm, ISSA)的代理购电用户用电量多维度协同校核方法。该方法旨在提高智能电网中用电量预测的准确性,降低电网企业在代理购电业务中的成本。以下是该论文的主要内容概述:
研究背景与意义:
- 随着市场化政策的推进,代理购电成为电网公司或售电公司的主要业务之一。
- 负荷预测的精准性是降低交易成本与市场风险的关键要素。
研究创新点:
- 提出基于预测结果校核预测误差的方法,通过构建偏差概率模型,分析各个维度的偏差概率分布,实现有效偏差识别。
- 基于偏差概率分布,采用ISSA优化算法优化多维度权重,构建多维度协同校核模型,提高用户用电量预测精度。
研究方法:
- 偏差概率分布模型:使用核密度估计法确定用电量预测偏差的概率密度分布,进行有效偏差识别。
- ISSA优化算法:用于优化多维度权重配比,最小化预测误差。
- 多维度协同校核模型:结合预测值和权重值,通过线性加权计算方法确定最终校核后的预测值。
实验与结果:
- 采用某省代理购电用户用电量数据进行验证。
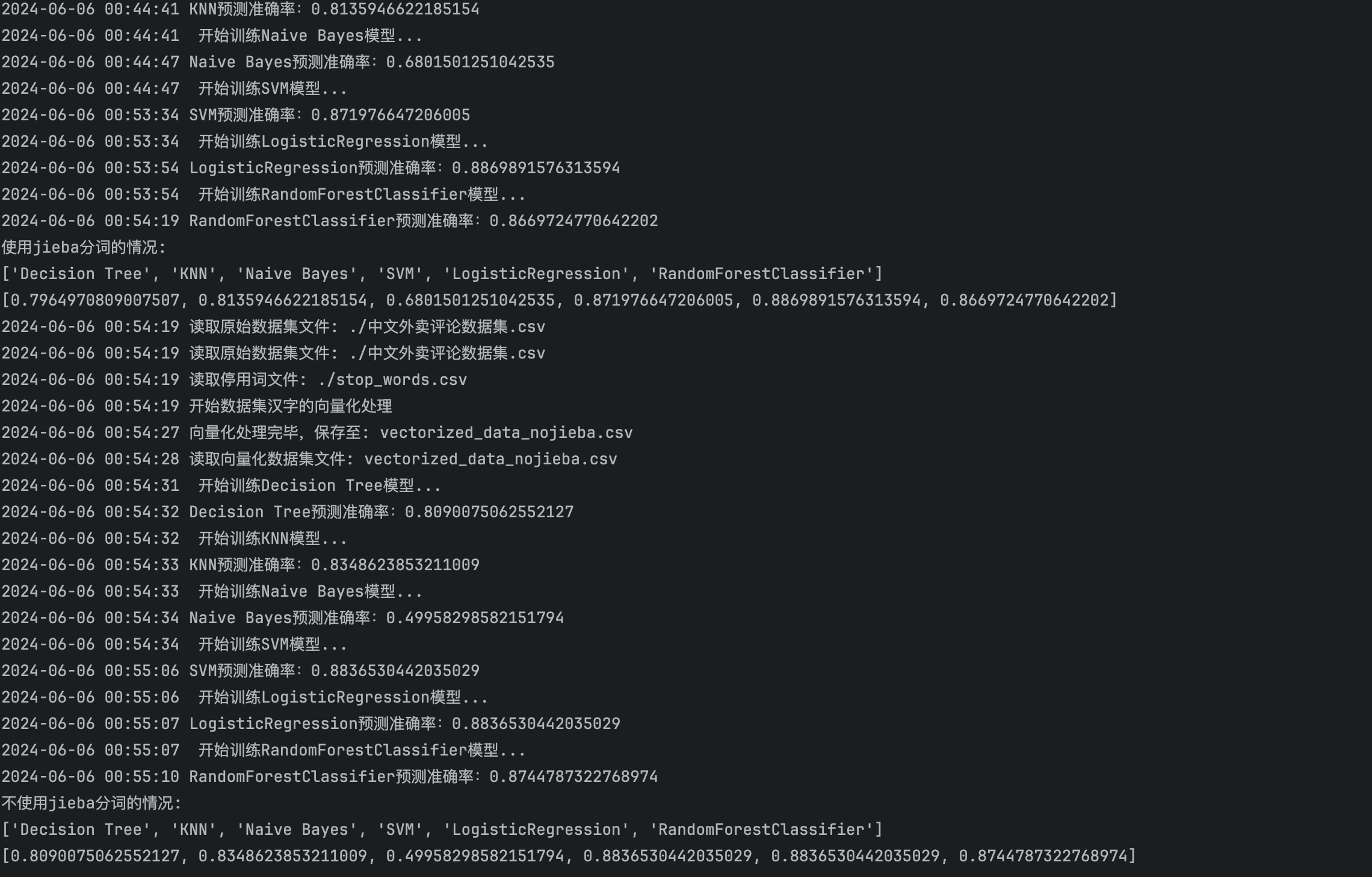
- 基于ISSA优化算法的多维度协同校核方法显著降低了平均绝对误差和均方根误差,提高了预测精度。
结论:
- 多维度协同校核方法能有效提高代理购电用户用电量预测的准确性,降低电网企业在代理购电业务中的成本。
关键词:
- 代理购电
- 误差校核
- ISSA优化算法
- 组合权重
- 均方根误差
论文通过实际案例验证了所提方法的有效性,并展示了通过ISSA算法优化权重后预测精度的提升。这项研究为电力行业提供了一种新的多维度协同校核方案,有助于提高用电量预测的精确度。

基于论文描述,以下是复现仿真的大致思路,以及使用伪代码表示的程序结构:
复现仿真思路:
-
环境准备:
- 安装必要的软件和库,如Matlab或Python环境,以及优化算法库。
-
数据收集:
- 收集代理购电用户的用电量数据,包括区域、行业、电压等级三个维度。
-
偏差概率分布模型建立:
- 使用核密度估计法(KDE)对每个维度的用电量预测偏差进行建模。
-
有效偏差识别:
- 通过KDE模型识别有效偏差,确定偏差的概率分布特征。
-
ISSA优化算法实现:
- 编写或使用现有的ISSA优化算法代码,用于权重优化。
-
多维度协同校核模型构建:
- 结合预测值和优化后的权重,构建多维度协同校核模型。
-
误差评估:
- 使用均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)评估预测精度。
-
仿真实验:
- 运行仿真实验,对比单一维度校核和多维度协同校核的效果。
程序伪代码:
# 导入必要的库
import numpy as np
from scipy.stats import gaussian_kde
from your_issa_implementation import ImprovedSparrowSearchAlgorithm
# 1. 环境准备
# 安装Matlab或Python,确保所有库都已正确安装
# 2. 数据收集
# 收集用电量数据
data = collect_data('regional', 'industry', 'voltage_level')
# 3. 偏差概率分布模型建立
def build_deviation_model(data):
kde = gaussian_kde(data)
return kde
# 4. 有效偏差识别
def identify_effective_deviation(kde, data):
# 使用KDE分析数据分布,识别有效偏差
deviation_distribution = kde.evaluate(data)
# 识别逻辑...
return effective_deviation
# 5. ISSA优化算法实现
def optimize_weights_with_issa(objectives, constraints, max_iterations):
issa = ImprovedSparrowSearchAlgorithm(max_iterations)
optimal_weights = issa.optimize(objectives, constraints)
return optimal_weights
# 6. 多维度协同校核模型构建
def build_multidimensional_calibration_model(predictions, weights):
calibrated_predictions = {}
# 根据权重和预测值构建校核模型
for dimension, prediction in predictions.items():
calibrated_predictions[dimension] = prediction * weights[dimension]
return calibrated_predictions
# 7. 误差评估
def evaluate_errors(true_values, predictions):
# 计算误差指标
errors = {}
for dimension in true_values:
rmse = np.sqrt(np.mean((true_values[dimension] - predictions[dimension])**2))
mae = np.mean(np.abs(true_values[dimension] - predictions[dimension]))
errors[dimension] = {'RMSE': rmse, 'MAE': mae}
return errors
# 8. 仿真实验
def simulation_experiment(data, true_values):
# 建立偏差模型
kde_models = {dim: build_deviation_model(data[dim]) for dim in data}
# 识别有效偏差
effective_deviations = {dim: identify_effective_deviation(kde_models[dim], data[dim]) for dim in data}
# 优化权重
objectives = define_objectives() # 定义目标函数
constraints = define_constraints() # 定义约束条件
optimal_weights = optimize_weights_with_issa(objectives, constraints, 1000)
# 构建校核模型
predictions = {dim: data[dim] for dim in data}
calibrated_predictions = build_multidimensional_calibration_model(predictions, optimal_weights)
# 误差评估
errors = evaluate_errors(true_values, calibrated_predictions)
return errors
# 主程序
if __name__ == "__main__":
true_values = collect_true_values() # 收集真实值
errors = simulation_experiment(data, true_values)
print(errors)请注意,这是一个高层次的伪代码示例,实际编程时需要详细定义每个函数的内部逻辑,包括数据结构的定义、模型的数学表达、求解器的调用等。此外,具体的库函数调用和参数设置需要根据实际的编程环境和数据来进行调整。
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html
电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python,机器学习,计算机视觉,深度学习,神经网络,数据挖掘领域.https://blog.csdn.net/LIANG674027206?type=download