目录
什么是Function Calling
示例 1:调用本地函数
Function Calling 的注意事项
支持 Function Calling 的国产大模型
百度文心大模型
MiniMax
ChatGLM3-6B
讯飞星火 3.0
通义千问
几条经验总结
什么是Function Calling
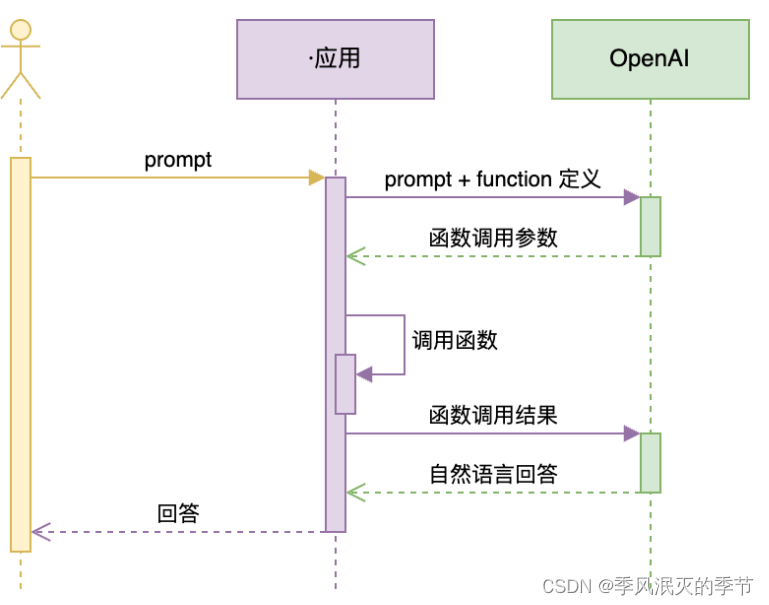
Function Calling 是一种函数调用机制,在使用 大模型进行prompt 提问时,大模型现有的知识库不一定有能力立即回答你的问题,但我们在提问时可以告诉大模型,我们有几个函数,让它结合我们的提问告诉程序,应该去调用哪个函数,并从给的提问中解析出参数。程序会根据大模型返回的函数和入参生成一个结果。然后程序将 最初的提问和函数调用结果一并发给 大模型进行 prompt ,这个时候,大模型就能回答出我们的问题了。
举例:
1. 我们调用API向大模型提问:推荐北京五道口附近的咖啡店。同时告诉大模型,我们定义了一个函数,这个函数需要参数是:地名、关键词
2. 大模型从我们的提问中解析出地名、关键词和函数的对应关系返回。如:地点搜索函数,入参是 北京五道口,咖啡店。
3. 程序根据大模型返回的参数调用 高德API返回咖啡店的位置信息。、
4. 程序将咖啡店的位置信息和最初的提问一并告诉大模型。
5. 大模型基于程序给的信息就能回答出这个问题了。
Function Calling 完整的官方接口文档:https://platform.openai.com/docs/guides/function-calling
示例 1:调用本地函数
需求:实现一个回答问题的 AI。题目中如果有加法,必须能精确计算。
# 初始化
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
import json
_ = load_dotenv(find_dotenv())
client = OpenAI()
def print_json(data):
"""
打印参数。如果参数是有结构的(如字典或列表),则以格式化的 JSON 形式打印;
否则,直接打印该值。
"""
if hasattr(data, 'model_dump_json'):
data = json.loads(data.model_dump_json())
if (isinstance(data, (list))):
for item in data:
print_json(item)
elif (isinstance(data, (dict))):
print(json.dumps(
data,
indent=4,
ensure_ascii=False
))
else:
print(data)
def get_completion(messages, model="gpt-3.5-turbo"):
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7,
tools=[{ # 用 JSON 描述函数。可以定义多个。由大模型决定调用谁。也可能都不调用
"type": "function",
"function": {
"name": "sum",
"description": "加法器,计算一组数的和",
"parameters": {
"type": "object",
"properties": {
"numbers": {
"type": "array",
"items": {
"type": "number"
}
}
}
}
}
}],
)
return response.choices[0].message
from math import *
prompt = "Tell me the sum of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10."
# prompt = "桌上有 2 个苹果,四个桃子和 3 本书,一共有几个水果?"
# prompt = "1+2+3...+99+100"
# prompt = "1024 乘以 1024 是多少?" # Tools 里没有定义乘法,会怎样?
# prompt = "太阳从哪边升起?" # 不需要算加法,会怎样?
messages = [
{"role": "system", "content": "你是一个数学家"},
{"role": "user", "content": prompt}
]
response = get_completion(messages)
# 把大模型的回复加入到对话历史中。必须有
messages.append(response)
print("=====GPT 第一次回复=====")
print_json(response)
# 如果返回的是函数调用结果,则打印出来
if (response.tool_calls is not None):
# 是否要调用 sum
tool_call = response.tool_calls[0]
if (tool_call.function.name == "sum"):
# 调用 sum
args = json.loads(tool_call.function.arguments)
result = sum(args["numbers"])
print("=====函数返回结果=====")
print(result)
# 把函数调用结果加入到对话历史中
messages.append(
{
"tool_call_id": tool_call.id, # 用于标识函数调用的 ID
"role": "tool",
"name": "sum",
"content": str(result) # 数值 result 必须转成字符串
}
)
# 再次调用大模型
print("=====最终 GPT 回复=====")
print(get_completion(messages).content)=====GPT回复=====
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"id": "call_4Crnxkt4kj0bOspDxIiAJ6lD",
"function": {
"arguments": "{\"numbers\":[1,2,3,4,5,6,7,8,9,10]}",
"name": "sum"
},
"type": "function"
}
]
}
=====函数返回=====
55
=====最终回复=====
The sum of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10 is 55.
划重点:
- Function Calling 中的函数与参数的描述也是一种 Prompt
- 这种 Prompt 也需要调优,否则会影响函数的召回、参数的准确性,甚至让 GPT 产生幻觉
Function Calling 的注意事项
划重点:
- 只有
gpt-3.5-turbo-1106和gpt-4-1106-preview及更高版本的模型可用本次课介绍的方法 - 使用模型别名
gpt-3.5-turbo和gpt-4-turbo会调用最新模型,但要防范模型升级带来的负面效果,做好充足测试 - 函数声明是消耗 token 的。要在功能覆盖、省钱、节约上下文窗口之间找到最佳平衡
- Function Calling 不仅可以调用读函数,也能调用写函数。但官方强烈建议,在写之前,一定要有真人做确认
支持 Function Calling 的国产大模型
- 国产大模型基本都支持 Function Calling 了
- 不支持 FC 的大模型,某种程度上是不大可用的
百度文心大模型
官方文档:文心千帆文档首页-百度智能云
百度文心 ERNIE-Bot 系列大模型都支持 Function Calling,参数大体和 OpenAI 一致,支持 examples。
MiniMax
官方文档:MiniMax-与用户共创智能
- 这是个公众不大知道,但其实挺强的大模型,尤其角色扮演能力
- 如果你曾经在一个叫 Glow 的 app 流连忘返,那么你已经用过它了。现在叫「星野」
- 应该是最早支持 Function Calling 的国产大模型
- V2 版 Function Calling 的 API 和 OpenAI 完全一样,但其它 API 有很大的特色
ChatGLM3-6B
官方文档:ChatGLM3/tools_using_demo at main · THUDM/ChatGLM3 · GitHub
- 最著名的国产开源大模型,生态最好
- 早就使用
tools而不是function来做参数,其它和 OpenAI 1106 版之前完全一样
讯飞星火 3.0
官方文档:星火认知大模型Web API文档 | 讯飞开放平台文档中心
和 OpenAI 1106 版之前完全一样
通义千问
官方文档:如何使用通义千问API_模型服务灵积(DashScope)-阿里云帮助中心
和 OpenAI 接口完全一样。
几条经验总结
在传统与 AI 之间徘徊:
- 详细拆解业务 SOP,形成任务 flow。每个任务各个击破,当前别幻想模型一揽子解决所有问题
- 不是所有任务都适合用大模型解决。传统方案,包括传统 AI 方案,可能更合适
- 一定要能评估大模型的准确率(所以要先有测试集,否则别问「能不能做」)
- 评估 bad case 的影响面
- 大模型永远不是 100% 正确的,建立在这个假设基础上推敲产品的可行性