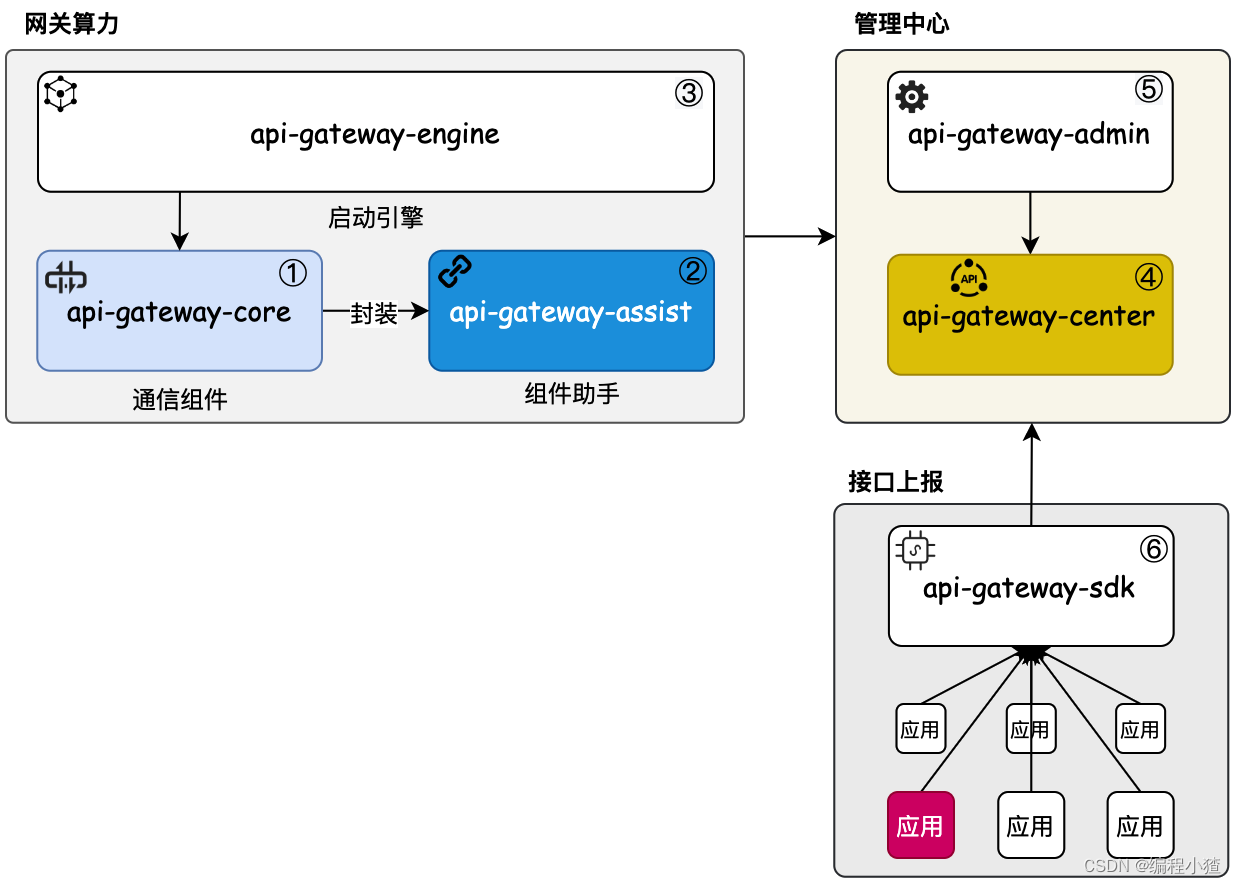
先了解一些时域抗锯齿的方法:
TAA:
抖动
TAA 的主要原理是跨帧计算多个子像素样本,然后将它们组合成一个最终像素。最简单的方案是在像素内生成随机样本,但有更好的方法来生成固定序列的样本。选择一个好的序列以避免聚集非常重要,并且在序列中选择离散数量的样本:通常 4-8 个样本效果较好。在实践中,这对于静态图像比动态图像更重要。下面是一个具有 4 个样本的像素。

为了在像素内生成随机子样本,我们将投影矩阵沿视锥平面平移一个像素的一部分。抖动偏移的有效范围(相对于像素中心)是屏幕尺寸的像素数的倒数的一半,因此 [−1/2, 1/2]w 和 [−1/2, 1/2]h。
解析
下一阶段是解析过程。我们将收集样本并将它们合并在一起。解析过程可以采取两种形式,使用累积缓冲区或多个过去的缓冲区。累积缓冲区存储多个帧的结果,并通过混合当前抖动帧的一小部分(例如 10%)来每帧更新。这对于静态相机应该足够了。
鬼影
我们之所以会看到拖尾现象,是因为我们在当前帧的位置采样了前一帧。结果是图像的叠加,随着我们积累新帧而逐渐消失。由于问题是由相机移动引起的,让我们首先解决这个问题。对于不透明物体,相机运动相对简单,因为我们知道它们的世界空间位置可以使用深度缓冲区和相机投影的逆矩阵重建。这个过程称为重投影,涉及以下步骤:
- 从当前相机 C 生成的当前深度缓冲区读取深度
- 使用视图投影矩阵的逆矩阵进行反投影,将我们的屏幕空间位置转换为世界空间
- 使用先前的视图投影矩阵投影到先前相机 P 的屏幕空间
- 将屏幕空间位置转换为 UV 并采样累积纹理
深度拒绝
深度拒绝的想法是,我们可以假设深度值非常不同的像素属于不同的表面。为此,我们需要存储前一帧的深度缓冲区。这对于第一人称射击游戏效果很好,因为枪和环境相距很远。然而,在多种场景中可能会出错,例如植被或具有大量深度复杂性的噪声几何体。
模板拒绝
模板拒绝是一种定制的解决方案,适用于有限的内容集。其想法是用不同于背景的模板值标记“特殊”对象。这可以是主角、汽车等。为此,我们需要存储前一帧的模板缓冲区。在解析时,我们丢弃任何具有不同模板值的表面。需要特别注意避免硬边。
速度拒绝
基于速度拒绝表面在我看来更为稳健,因为根据定义,遮挡是由两个对象相对于相机的相对运动差异引起的。如果两个表面在两帧之间具有非常不同的速度,那么要么加速度很大,要么对象以不同的速度移动,并且一个突然变得可见。为此,我们需要存储前一帧的速度缓冲区。过程如下:
- 读取当前速度
- 使用速度确定先前的位置
- 将位置转换为 UV
- 读取先前的速度
混合因子衰减
这会在某些情况下修改混合因子。UE4 提到他们检测到即将发生的限制事件并减少混合因子。然而,这会重新引入抖动,必须谨慎处理。
强度/颜色加权
由于闪烁的原因是连续邻域中的高差异,强度加权试图衰减强度高的像素。这会稳定图像,但会以镜面高光为代价(它们变得更暗,因此对于像闪烁的沙子之类的东西,可以在 TAA 之后增强强度或在 TAA 之后添加它们)。对数加权将颜色转换为对数空间然后再进行任何线性操作,这偏向于低强度值。
纹理模糊
纹理模糊是 TAA 的另一个点。纹理在 mipmapping 过程中已经被模糊化,运行时被调整为选择适当的 mipmap,以最小化锯齿同时保持细节清晰。屏幕空间中的抖动在纹理空间中导致进一步的模糊。
透明度
透明度是一个棘手的问题,因为透明对象通常不会渲染到深度。低分辨率效果如烟雾和灰尘通常不受 TAA 影响,颜色限制也能很好地完成任务。然而,更一般的透明度如玻璃、全息图等,如果没有正确重投影,可能会受到影响并显得很差。有几种解决方案,这取决于内容:
- 将混合运动矢量写入速度缓冲区。这取决于内容,但它可以工作。实际上,即使将运动矢量写成实心物体也可以工作,如果对象的不透明度足够高的话。
- 引入每像素累积因子:这就是 UE4 所谓的“ResponsiveAA”。本质上,它会以像素抖动换取鬼影。对于非常详细的 VFX 很有用,如此处所示。
- 在 TAA 之后渲染透明度。这不推荐,除非你可能将它们渲染到一个离屏缓冲区,用边缘检测解决方案如 FXAA 或 SMAA 进行抗锯齿,然后合成回去。它可能会在边缘抖动,因为它是与抖动的深度缓冲区进行比较的。
相机切换
使用 TAA 时,相机切换会带来挑战。相机切换迫使我们使历史缓冲区无效,因为其内容不再代表当前渲染的帧。因此,我们不能依赖历史来生成一个漂亮的抗锯齿图像。这里有一些解决方法:
- 偏向收敛以加速过程。在相机切换后,我们需要尽快积累内容。
- 使用淡出和淡入。TAA 会在黑色部分积累,并在淡入时收敛。
- 在前几帧应用另一种形式的 AA 或模糊,以使收敛不那么突兀。
总而言之,这些都是一些权宜之计,但需要解决。另一个需要记住的是,帧率越高,这个问题就越小。
UE的TAAU:
核心步骤
图形时域混合 Shader 的逻辑可以抽象为以下三步:
- 读取历史颜色
- 用当前帧邻域 Clamp 历史颜色
- 加权 Blend 混合
1. 读取历史颜色
在读取历史颜色时,需要找到两个 UV 坐标:
- 历史帧位置:通过相机重投影和速度矢量(Velocity)计算得到。虽然视口相同,但 UV 坐标可能不对齐(例如帧间旋转)。
- 当前着色位置:通过 Jitter 和上采样计算得到,UV 坐标一定对齐。
2. 用当前帧邻域 Clamp 历史颜色
在这一步中,当前帧邻域是唯一必须的邻域读取,其他地方不强制需要 Filter。标准流程中历史帧的 Filter 没有意义,因为邻域不一定是有效信息,UV 也无法对齐。深度邻域虽然不是刚需,但可以用来找最近像素采样 Velocity。
3. 加权 Blend 混合
TAA 的 Jitter 加在着色位置上,与输入的 UV 有关,和输出无关。权重分为 Clamp 和 Blend 两部分:Clamp 防拖影,Blend 防闪烁。历史帧越稳定,历史帧 Blend 权重越高,当前帧 Blend 权重越低,闪烁越少。Clamp 力度越大,贴近当前帧越多,拖影越少,但闪烁会增加。邻域范围越大,邻域越精准,Clamp 力度应该越大。
深度读取的作用
深度读取有两个作用:
- Velocity 的 2x2 取最近
- 重投影遮挡检测
慎重加深度双边权重,因为颜色信号是空间低频的,相邻像素有效性和深度最近输入坐标中心用于对齐。
具体实现细节
流程
-
参数初始化:分为逐帧和逐像素
- 逐帧:目前只有曝光参数,要存进共享标量寄存器
- 逐像素:PPCo 与 PPCk 这些 UV 参数,以及判断像素是否 ResponsiveAA
- PPCk 的 UV 作为默认采样位置
- ResponsiveAA 标记是 UE 用来解决半透模糊和拖影的,存储在 Stencil 第三位,被标记的像素将当前帧基础权重提高为 0.25(默认是 0.04)
-
采样历史帧颜色
- 先缓存深度进 LDS
- 最近深度采样 Velocity(斜对角 5 点)
- 增广深度,减少低分辨率着色深度带来的锯齿状碎边,默认速度来自前景物体
- 后续用不到深度了,同一个 LDS 缓冲区改成当前帧颜色
- 采样历史帧颜色,使用 4x4 BiCubic,忽略四角,5 次双线性采样,卷积核用 CatRom 锐化
- 历史帧拒绝条件:只有离屏检测没有遮挡检测(TSR 和 FSR 都有独立遮挡检测)
-
Filter + Clamp
- Filter 就是上采样计算当前输出点颜色,用的不是锐化卷积核
- 有两套运行顺序:
- 不升采样:1. Filter 2. Clamp
- 升采样:1. Clamp 2. Filter
-
Blend
- 速度越快,升采样像素中心越近,亮度变化越少(防闪烁),当前帧权重越高
Bi-Cubic 历史帧采样
对应原文件 SampleHistory()。对于 Bi-Cubic 采样和 CatRom 卷积核不了解的同学,推荐一篇知乎文章:
- 简单说就是用 5 次双线性采样模拟一个 4x4 的卷积区域,信息量更大加上锐化卷积核,自然清晰。
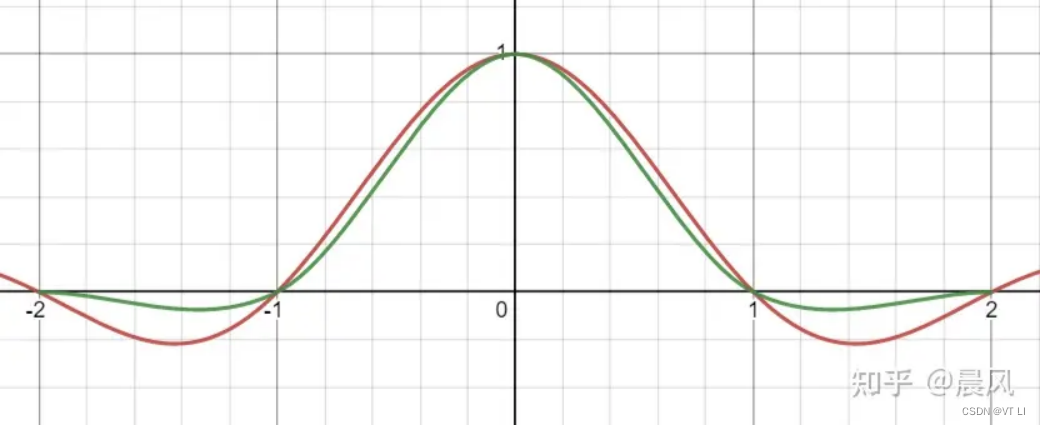
Catmull-Rom绿线,Lanczos红线
上采样 Filter 插值权重
TAAU 和 TSR 用的是同一个函数的小改版本
为了保证权重不为 0:
- TSR 直接在输出的时候给最小阈值 0.005
- 函数输入参数 x 和距离相关:x = PixelDelta * UpscaleFactor * InvFilterScaleFactor
- PixelDelta = dKO - offset
- UpscaleFactor = 1 / ScreenPercentage
- InvFilterScaleFactor = max(1 - (Velocity / ScreenPercentage) * 0.1, ScreenPercentage)
采样效率与 LDS 缓存
LDS 缓存对 SM 吞吐量有显著提升(测试约 50%->80%)。标准升采样流程中采样次数与顺序:
- 深度 5 次点采样:重投影 1 次 + 增广速度 4 次
- 历史帧颜色 5 次双线性:省略 4 个角的 4x4 Bi-Cubic 采样
- 当前帧颜色 18 次点采样:Clamp 9 次 + Filter 9 次,是同一个 3x3 区域
使用缓存后:
- 深度:每四个点一次 Gather,组内平均每线程 0.5 次采样,10 倍优化
- 颜色:平均每个点两次采样,9 倍优化(其实是 4.5,因为关了 LDS 默认退化为 VGRP 缓存)
PC 默认使用 CS 组内 LDS 缓存而不是 wave 广播(移动端走 PS 直接采样)。深度和颜色可共享同一个缓冲区(采样到颜色时深度信息已经无用了)。CS 组大小设置为 8x8,每线程两次采样满足 3x3 邻域缓存(缓存区域 10x10)。
UE的TSR:
TSR截帧总览
TSR共有8步,将传统TAA的低频计算与高频输出拆开。以下是每一步的详细解析:
1. TSR DilateVelocity 增广速度
从这里开始都是在后处理了。生成外扩几个像素的速度和深度:TSR.Velocity.Dilated和TSR.ClosestDepthTexture。这一步对应传统TAA的增广速度采样,减少低频着色深度带来的锯齿。顺便给全屏加上了重投影相机位移,是个性能优化。
2. TSR RejectShading 拒绝着色
这是低频TAA,完成了几乎所有Filter操作,耗时很少。输出包括:
- 用当前帧对楼上投影后的低频历史帧重新着色,补全。
- 当前帧亮度,包括半透。
- RG8
TSR.HistoryRejection历史拒绝,最终高频混合用的参数。
3. TSR SpatialAntiAliasing 空间抗锯齿
边缘检测,顺便做了一个FXAA。左下是FXAA,存的是对PPCo的UV偏移量。右下边缘检测,影响最终上采样插值卷积核宽度。
4. TSR FilterAntiAliasing 滤波抗锯齿
对上一步FXAA结果进行Filter。先时域再空间是光追降噪的常见操作,注意空间抗锯齿的结果必须每帧丢弃,不能在Blend之后再混合进输出历史帧,否则会在时域上叠加Blur越来越糊。
5. TSR UpdateHistory 更新历史
类似分帧SMAA,占半数以上时间消耗。TSR只有这一步是高频的,输出是屏幕物理分辨率的四倍。如果缩放比例0.5,输出就是渲染分辨率的16倍。除了颜色外,还有一张R8的TSR.History.Metadata,代表逐像素可信度。
RejectShading 低频时域
对应文件:TSRRejectShading.usf。流程上对应传统TAA:从历史帧采样结束开始,上采样插值和计算Clamp范围,计算各种权重,截止到Blend之前。
计数淡入权重 CountFadeIn
当前帧和历史帧一起Blur
Blur之后再Clamp一次历史帧,这次才是对应标准TAA里面的ClampBB。
计算Clamp变化量和正常范围
Clamp变化量:上一步Clamp前后历史帧的颜色变化。再额外Filter一下(3x3取中值再取最大),输出Filter前后两个值分别用于Clamp和Blend。
UpdateHistory 高频时域
高频时域混合,分帧SMAA,对应文件TSRUpdateHistory.usf。全流程不需要相邻线程数据,所以不需要LDS/Wave。
采样辅助Texture
重投影高频历史帧,统一曝光,获取当前帧颜色。应用上一步的FXAA,计算Min Max。计算上采样插值卷积核参数。
高频时域混合
在高频时域混合部分,TSR使用了一种类似于分帧SMAA的方法。以下是具体步骤:
- Process texture fetches:采样辅助Texture。
- Reproject history:重投影高频历史帧。
- Correct history:统一曝光。
- Filter input scene color at predictor frequency:获取当前帧颜色。
- Pixel coordinate of the center of output pixel O in the input viewport:应用上一步的FXAA。
- Issues overlapped texture fetches:上采样颜色插值,计算Min Max。
- Compute upscaling kernel size based on the rejections and number of samples already in history:计算上采样插值卷积核参数。
- Contribute current frame input into the predictor for next frame:最终混合,计算可信度。
- Compute final output:最终输出,包括格式转换和量化误差。
上采样半径
在TSR中,有两个半径:
- Blend:用于最终混合时当前帧权重
CurrentWeight,输入dKO,代表着色点和输出点的距离权重。 - 插值函数:和TAAU用的一样(
1−1.9∗x^2+0.9∗x^4),半径选取逻辑如下图所示:
以0.5缩放为例:1个渲染像素 -> 2x2输出像素 -> 4x4高频TSR中间超分像素。
历史权重总和
历史权重总和(CurrentWeight + PrevWeight)汇总为一个额外的R8图,叫TSR.History.Metadata,用于记录每个像素时域上积累了多少有效信息,越亮表示有效信息越多。
FSR2:
简述
FSR2 是 AMD 开源的超分辨率方案,通过复用历史帧的信息,从低分辨率图像重建高分辨率图像。它能够显著提升渲染性能,尤其是在光线追踪等对性能影响较大的场景中。FSR2 需要引擎传入一些低分辨率的 Buffer 和 Mask,最终输出一张高分辨率的图像。
算法结构
FSR2 算法主要包含六个阶段:
- Compute luminance pyramid
- Reconstruct & dilate
- Depth clip
- Create locks
- Reproject & accumulate
- Robust Contrast Adaptive Sharpening (RCAS)
接下来,我们将逐一解析这些阶段的具体实现和作用。
1. Compute Luminance Pyramid
在这个阶段,FSR2 生成一个亮度金字塔用于后续检测 shading 结果变化程度,同时生成一张 1x1 的曝光纹理以供后续阶段使用。
亮度金字塔通过 FidelityFX 的 Single Pass Downsampler(一次 Dispatch 生成 mipmap 链的优化技术)实现。SPD 可以为任意纹理生成一组特定的 mipmap 链,并将数据存储到特定的 mipmap level 里。FSR2 通过 SPD 计算 Luminance 并降采样到第 4、5 层 mipmap,后续阶段将用这张图来检测历史帧的变化。
2. Reconstruct & Dilate
这个阶段生成一张重投影的深度图,并将深度图和运动矢量进行膨胀,最后根据 ColorBuffer 计算出一张亮度图。
首先,根据当前帧的深度图和运动矢量计算膨胀的深度图和运动矢量。由于深度图和运动矢量在几何体边缘存在锯齿,膨胀处理可以有效解决这一问题。FSR2 通过选择每个像素周围 3x3 的深度值中最近的深度值,采用这个离相机最近的像素的深度和运动矢量进行膨胀计算。
接下来,通过膨胀的运动矢量和两帧的投影矩阵重投影 DepthBuffer 到上一帧的位置。由于可能会有多个像素重投影到同一个像素位置,使用原子操作 InterlockedMax 或 InterlockedMin 保留投影过来离相机最近的深度值。
3. Depth Clip
在这个阶段,FSR2 通过计算每个像素的深度差异来生成 Disocclusion mask。
通过计算当前帧和上一帧相机位置的深度差异,生成 Disocclusion mask。这个过程需要对比当前帧和上一帧的深度值,并根据深度差异生成遮挡剔除遮罩。
4. Create Locks
当渲染画面中出现稀疏特征的高频信息(例如只有一两个像素宽的线)时,FSR2 引入了锁的机制,通过锁定这些稀疏特征的像素来阻止 color clamp。
创建 Lock 时,FSR2 检测像素周围 3x3 区域的亮度,当周围像素与中间像素没有组成 2x2 的像素块时,为这个像素加上一个锁。
5. Reproject & Accumulate
这是 FSR2 算法中最复杂、最耗时的阶段,前面的所有阶段都是为这个阶段做准备。
这个阶段分为多个步骤:
- 使用 Lanczos filter 对当前帧颜色缓冲进行上采样。
- 上一帧的输出颜色和 Lock Stat 将会被重投影。
- 对历史帧颜色数据进行 Clear。
- 计算 Luma 不稳定性。
- 累积历史帧颜色数据和当前帧颜色数据。
首先,检测每个像素的 Shading 变化。如果像素处于锁定区域,则将创建锁定时的亮度与 FSR2 明暗变化阈值进行对比。如果像素不在锁定区域,则用当前帧和历史帧的亮度进行对比。Shading 变化检测是一个关键步骤,为后续步骤提供信息。
接下来,对调整过的颜色进行上采样,使用 Lanczos resampling。重投影是这个阶段的另一个关键部分,需要对膨胀运动矢量进行采样,将其应用于 FSR 上一帧的颜色缓冲。重投影的结果是显示分辨率的图像,包含了所有可以投影到前一帧的所有数据。由于 FSR2 有 Lock 的机制,所以需要重投影的不只是颜色缓冲,还需要将上一帧的 LockStatus 重新投影到当前帧。
最后,更新 LockStatus,采样 New lock,如果像素是 New lock 就将当前帧的亮度值写入到重投影的 LockStatus 的 G 通道。
6. Robust Contrast Adaptive Sharpening (RCAS)
RCAS 是 FSR2 算法的最后一个阶段,主要用于对图像进行锐化处理。
RCAS 使用自适应对比度锐化算法,对累积的颜色缓冲进行锐化处理,最终输出高质量的图像。
DLSS:
在现代游戏图形技术中,NVIDIA 的深度学习超级采样 (DLSS) 技术无疑是一个革命性的突破。DLSS 利用 AI 技术,通过超分辨率、抗锯齿和帧生成等特性,为游戏玩家提供了前所未有的图像质量和性能提升。
DLSS 特性概述
DLSS 技术主要包括以下几个核心特性:
- 超分辨率与深度学习
- 抗锯齿 (DLAA)
- 帧生成
- 光线重建
这些特性分别适用于不同的 GeForce RTX GPU 系列,并且通过不断的技术更新和优化,DLSS 已经成为提升游戏体验的重要工具。
超分辨率与深度学习
DLSS 超分辨率技术通过使用较低分辨率内容作为输入,并运用 AI 技术输出高分辨率帧,从而提升所有 GeForce RTX GPU 的性能。具体来说,DLSS 会对多个分辨率较低的图像进行采样,并使用先前帧的运动数据和反馈来重建原生质量图像。
这种技术不仅提升了图像的清晰度,还显著提高了游戏的帧率,使得玩家能够在高分辨率下享受流畅的游戏体验。
深度学习抗锯齿 (DLAA)
DLAA 是一种基于 AI 的抗锯齿技术,旨在为所有 GeForce RTX GPU 提供更高的图像质量。DLAA 与 DLSS 使用同样的超分辨率技术,重建原生分辨率图像,从而以更大限度提升图像质量。
通过 DLAA,游戏中的锯齿现象得到了有效的抑制,图像边缘更加平滑,细节更加清晰。
帧生成
DLSS 帧生成利用 AI 技术生成更多帧,以此提升性能,并通过 NVIDIA Reflex 保持出色的响应速度。DLSS 会借助 GeForce RTX 40 系列 GPU 所搭载的全新光流加速器分析连续帧和运动数据,进而生成其他高质量帧,同时不会影响图像质量和响应速度。
这种技术使得游戏在高帧率下运行更加流畅,尤其是在动作快速的场景中,玩家可以体验到更加顺畅的视觉效果。
光线重建
DLSS 光线重建利用 AI 为密集型光线追踪场景生成更多像素,从而为所有 GeForce RTX GPU 提升画质。借助 NVIDIA 超级计算机训练的 AI 网络,DLSS 可取代需要人工设计的降噪器,在被采样的光线之间生成更高质量的像素。
光线重建技术使得光线追踪效果更加逼真,光影细节更加丰富,极大地提升了游戏的视觉效果。
利用 AI 实现性能的成倍提升
DLSS 技术不仅提升了图像质量,还显著提高了游戏性能。通过开启 DLSS,玩家可以在多款热门游戏中体验到性能的成倍提升。
例如,在《微软模拟飞行》、《战锤 40K:暗潮》、《赛博朋克 2077》等游戏中,DLSS 技术显著提升了游戏的帧率,使得玩家能够在高分辨率下享受流畅的游戏体验。
超级计算机性能
DLSS 利用 NVIDIA 超级计算机的强大性能,训练并定期改进其 AI 模型。更新后的模型将通过 Game Ready 驱动传输给您的 GeForce RTX PC。然后,Tensor Core 使用专属的 AI 性能做浮点运算来实时运行 DLSS 人工智能网络。
这意味着,您可以利用 DLSS 超级计算机网络的强大功能来帮助自己提升性能和分辨率,其效果也会随时间提升。
结语
DLSS 技术通过超分辨率、抗锯齿、帧生成和光线重建等特性,为游戏玩家提供了前所未有的图像质量和性能提升。随着越来越多的游戏和应用支持 DLSS,玩家可以在更多的游戏中体验到这一革命性技术带来的优势。无论是追求极致画质的玩家,还是希望在高分辨率下享受流畅游戏体验的玩家,DLSS 都是一个不可或缺的工具。