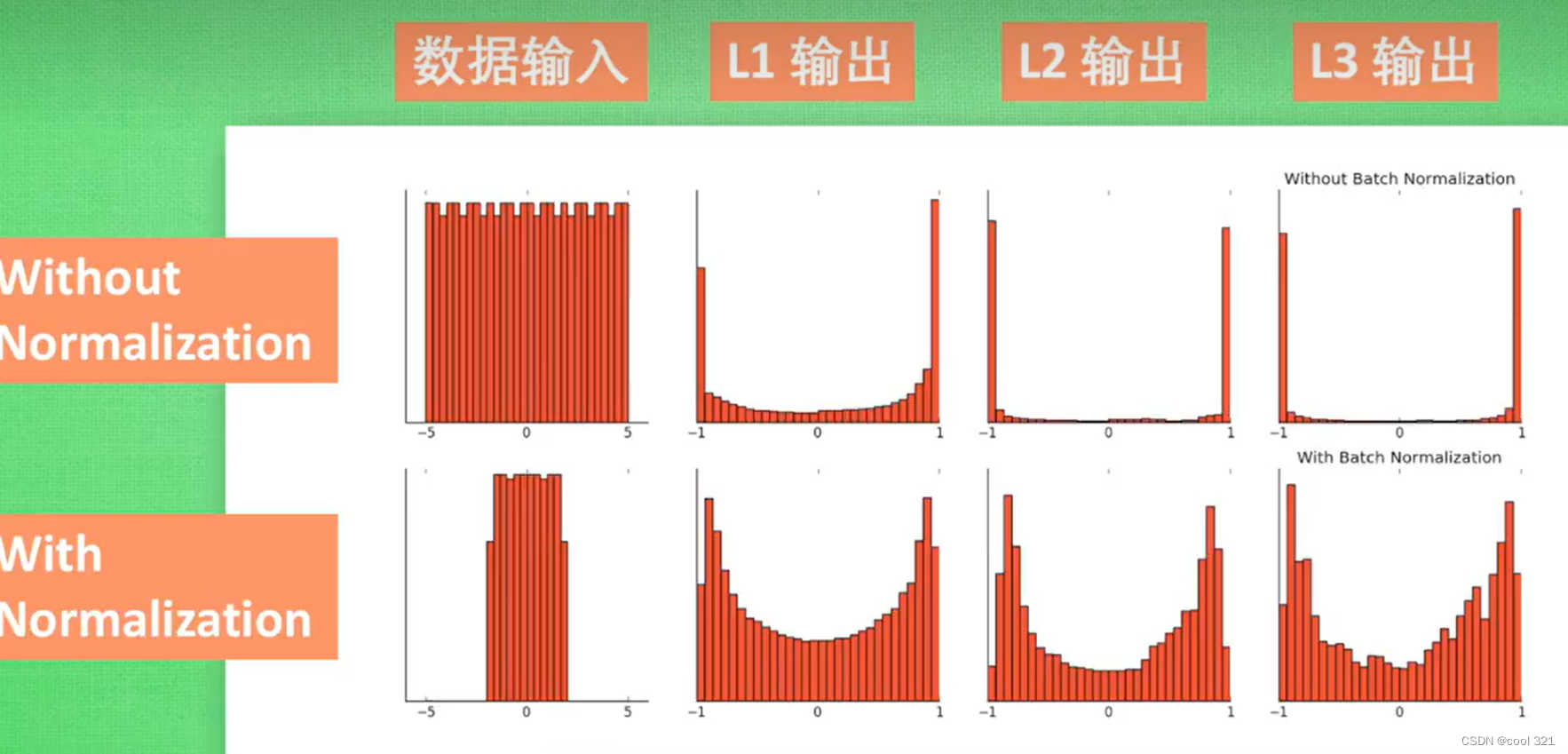
在实际的项目中开发过程中,会有很多的对象,如何高效、方便的管理这些对象,是影响程序性能与可维护性的重要环节。在Java语言中为这个问题提供了一套完美的解决方案,也就是接下来要介绍的集合框架。
1.1 集合框架的结构
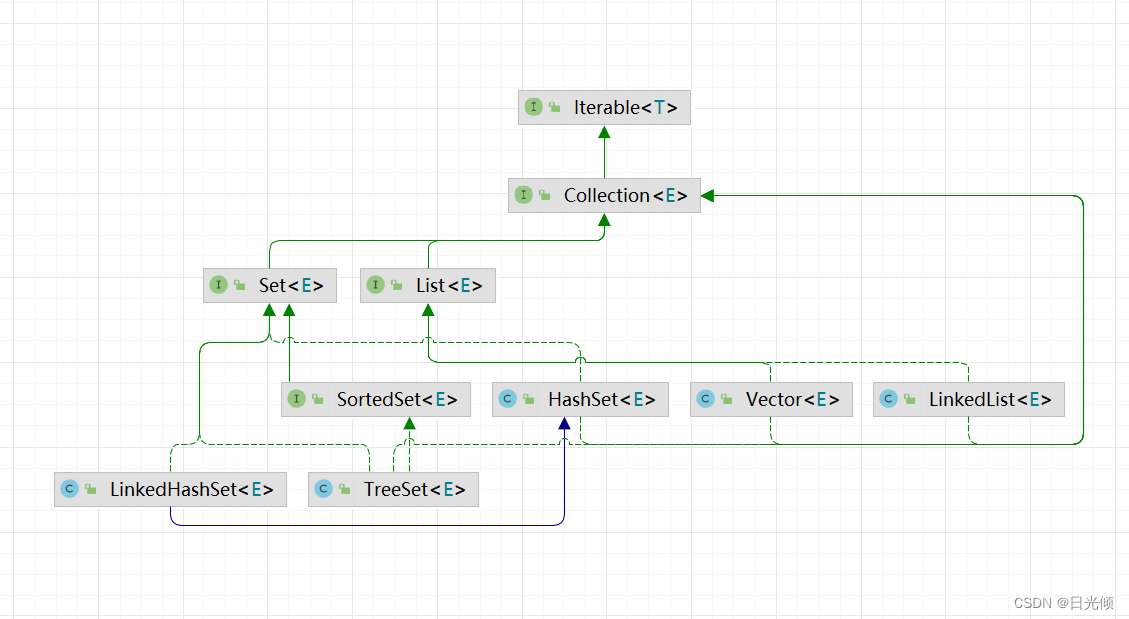
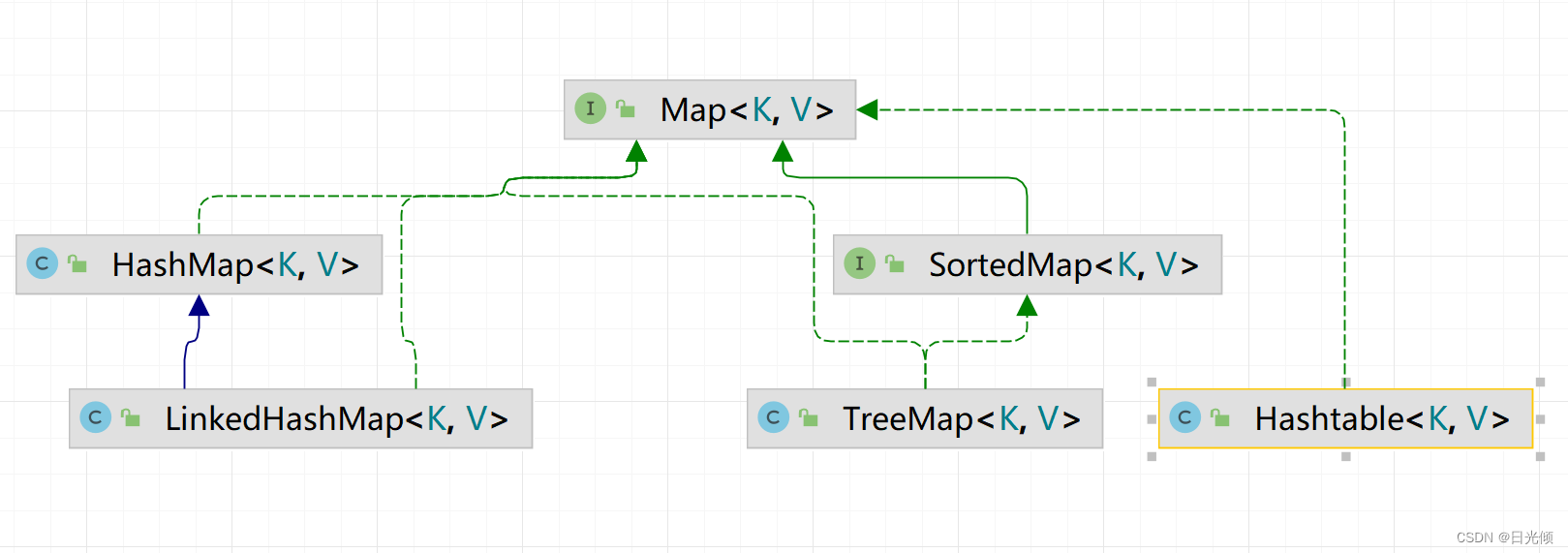
从Collection接口 继承而来的一般被称为聚焦(有时也被宽泛的称为集合),从Map接口继承来的一般被称为映射。
在Set和Map接口中,都有一个继承自他们的SortedXXX子接口(XXX = Set/Map)
1.2 列表
1.2.1 List(列表)接口
List接口继承自Collection接口,代表列表的功能(角色),其中的元素可以按索引的顺序访问,所以也可以称为有索引的Collection。实现该接口的类均属于Ordered
类型,具有列表的功能,其元素顺序均是按照添加(索引)的先后进行排列的
List接口的常用方法
(略)
与数组一样,列表中的索引是从0开始的,实现了List接口的类也可以被看做可变长度的数组来使用。
List接口中的方法很注重索引。如果开发人员需要对其中每个元素的插入位置进行精准的控制,并且需要根据元素的整数索引访问元素,或搜索列表中的元素,则可以使用实现了该类的接口类。
1.2.2 数组实现列表
ArrayList,是List接口最常用的实现之一。可以向其中添加包括null值在内的所有对象引用型的元素。甚至该对象引用自己也可以作为其中的元素。这样可以方便的搭建一个树状结构的集合。
该类内部类实际上是依赖数组实现的,因此对元素进行随机访问的性能很好,但如果进行大量的插入、删除操作,该类性能很差,
ArrayList中,功能方法大都实现自List接口。
package list;
import java.util.ArrayList;
//一个使用ArrayList的例子
public class Sample1 {
public static void main(String[] args) {
//创建列表ArrayList对象
ArrayList al = new ArrayList();
//初始化ArrayList中的元素
for(int i = 0;i<50;i++) {
al.add(String.valueOf(i));
}
//对arrlist进行操作
for(int i = 60;i<75;i++) {
al.set(i-45, String.valueOf(i));
}
//打印ArrayList列表里的内容
System.out.println("这是ArrayList操作后的结果:");
System.out.println(al);
//取出指定元素并进行处理
Object o = al.get(22);
String s = (String)o;
System.out.println("索引为22的元素长度为:"+s.length());
}
}

- 将ArrayList中从索引15开始之后长度为15区间内的元素依次设置为数字60~74的字符串,
- 头文件:java.util.*
- 在没有使用泛型的情况下,无论放进集合的是什么元素,取出的都是Object类型的引用,
ArrayList中并不真正存放对象,而只是存放对象的引用,所有集合框架中的类都如此
1.3 链接实现列表
指LinkedList类,功能与ArrayList类相同,都是列表List的实现。由于其内部是依赖双链表来实现的,因此具有很好的插入、删除性能。但随机访问元素相对较差。适合用在插入、删除多,元素随机访问少的场合。
package list;
import java.util.LinkedList;
public class Sample2 {
public static void main(String[] args) {
//创建列表LinkedList对象
LinkedList ll = new LinkedList();
//初始化LinkedList对象
for(int i = 0;i<50;i++) {
ll.add(String.valueOf(i));
}
//对LinkedList进行插入操作
for(int i = 15;i<30;i++) {
ll.add(i,String.valueOf(30-i+15));
}
//打印LinkedList列表
System.out.println("这是LinkedList操作后的结果");
System.out.println(ll);
}
}

在LinkedList索引为15的地方插入15个元素,其中内容为30-16的字符串。
1.3.1 依赖性倒置原理
依赖项倒置原理:依赖应尽量在抽象层进行,避免在具体层进行。
在实际开发中的含义就是应该尽量使用接口类型的引用,避免使用具体类型的引用。
package list;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
public class MyClass {
//声明具体类类型的引用
public LinkedList firstList = new LinkedList();
//声明具体类类型入口参数的方法
public void printLinkedList(LinkedList ll) {
System.out.println(ll);
}
//声明接口类型的引用
public List lastList = new Vector();
//声明接口类型入口参数的方法
public void printAllKindsOfList(List l) {
System.out.println(l);
}
}
-firstList是具体类类型的引用,在未来如果需要改变为其他类型,则会严重影响依赖他的代码。而LastList是接口类型的引用,在未来如果需要,可以指向任何实现了该接口的类的对象,对外面依赖它的代码没有任何影响。
-printLinkedList()方法的入口参数书具体类型的,只能接收一种类型的参数。而printAllKindsOfList()方法的入口参数是接口类型的,可接收任何实现了该接口类型的引用。灵活性更大。
1.3.2 将数组转换成列表
使用Java类库中Java.util.Arrays类的静态方法asList()
package list;
import java.util.Arrays;
import java.util.List;
public class Sample3 {
public static void main(String[] args) {
//创建一维字符串数组对象
String[] s = {"tom","jerry","lucy","jc"};
//将一维字符串数组转换为列表
List l = Arrays.asList(s);
System.out.println("这是将字符串数组转化为列表后的结果"+l);
}
}

1.4 集合
Set接口及其子接口与实现了这些接口的类都可以被称为是集合(Set)
1.4.1 Set接口
Set接口继承自Collection接口,和同样继承自Collection接口的List接口的不同之处在于:
- List接口按顺序将对象引用添加进去,对引用指向的对象没有特别的要求,Set接口不允许有重复的元素。
- List接口中的元素有顺序,就是添加的顺序,set接口中元素没有顺序,可以按照顺义顺序进行存放。
1.4.2 HashSet接口
HashSet类是Set接口最常用的实现之一。实际上,HashSet存储对象引用是按照哈希策略来实现的。另外,可以向HashSet中添加null值,但只能添加一次。
package list;
import java.util.HashSet;
public class Sample4 {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(5);
hs.add(1);
hs.add(3);
hs.add(2);
hs.add(4);
//移除5
hs.remove(5);
//添加1
hs.add(1);
//添加null
hs.add(null);
//打印
System.out.println("这时HashSet操作后的结果");
System.out.println(hs);
}
}
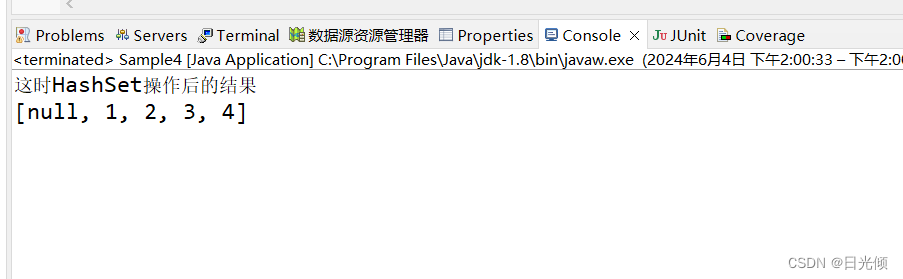
- HashSet对象并不保证元素的存储数据,相同的元素在Hash对象中只能出现一次,同时HashSet对象中允许存放null值。
1.4.3 equals()与Hashcode()方法重写的作用。
package list;
import java.util.HashSet;
public class Sample5 {
public static void main(String[] args) {
//创建空HashSet对象。
HashSet hs = new HashSet();
//向空HashSet中添加名字为tom的Student对象
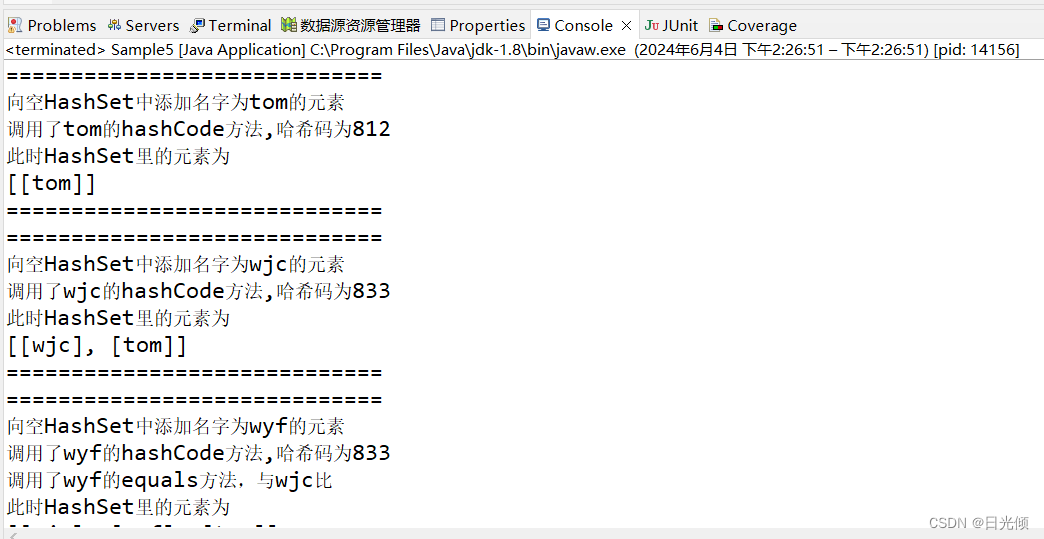
System.out.println("=============================");
System.out.println("向空HashSet中添加名字为tom的元素");
hs.add(new Student("tom"));
System.out.println("此时HashSet里的元素为");
System.out.println(hs);
System.out.println("=============================");
//向空HashSet中添加名字为wjc的Student对象
System.out.println("=============================");
System.out.println("向空HashSet中添加名字为wjc的元素");
hs.add(new Student("wjc"));
System.out.println("此时HashSet里的元素为");
System.out.println(hs);
System.out.println("=============================");
//向空HashSet中添加名字为wyf的Student对象
System.out.println("=============================");
System.out.println("向空HashSet中添加名字为wyf的元素");
hs.add(new Student("wyf"));
System.out.println("此时HashSet里的元素为");
System.out.println(hs);
System.out.println("=============================");
//向空HashSet中再次添加名字为wjc的Student对象
System.out.println("=============================");
System.out.println("向空HashSet中再次添加名字为wjc的元素");
hs.add(new Student("wjc"));
System.out.println("此时HashSet里的元素为");
System.out.println(hs);
System.out.println("=============================");
}
}
class Student{
//学生的姓名成员
private String name;
public Student(){}
public Student(String name) {
this.name = name;
}
//重写toString()方法
public String toString() {
//返回属性值的字符串
return "["+this.name+"]";
}
//重写equals()方法
public boolean equals(Object o) {
//打印显示调用信息
System.out.println("调用了"+this.name+"的equals方法,与"+((Student)o).name+"比");
//测试是否指向同一个对象
if(this==o) {return true;}
//测试引用o是否为null
if(o==null) {return false;}
//测试o是否同Student的instanceof测试
if(!(o instanceof Student)) {return false;}
//将引用类型进行强制转换
Student s = (Student)o;
//测试内容是否相同
if(this.name.equals(s.name)) {return true;}
else {return false;}
}
//重写hashcode()方法
public int hashCode() {
//计算哈希码
int hc = 7*this.name.charAt(0);
//打印显示调用信息
System.out.println("调用了"+this.name+"的hashCode方法,哈希码为"+hc);
return hc;
}
}
总结
因为采用的存储策略是哈希的,所以每次添加元素,都必须调用hashcode方法;由于有了hashCode与equals方法的约定,不再一只哈希桶中的元素equals一定不会返回true,这就避免了大量无谓的equals比较,提高了执行效率。
1.4.4 LinkedHashSet
LinkedHashSet类是Ordered的,其采用双链表实现,元素在其中的存储有固定的顺序,也就是插入元素的顺序。其他方法的特性与HashSet类均相同,也就是Set接口。
package list;
import java.util.LinkedHashSet;
public class Sample6 {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(String.valueOf(5));//OK
linkedHashSet.add(String.valueOf(1));//OK
linkedHashSet.add(String.valueOf(3));//OK
linkedHashSet.add(String.valueOf(2));
linkedHashSet.add(String.valueOf(4));//OK
linkedHashSet.remove(String.valueOf(5));
linkedHashSet.add(null);
System.out.println("linkedHashSet=" + linkedHashSet);
}
}

元素输出顺序与linkedHashSet中插入元素的先后顺序完全相同
1.5 映射
1.5.1 MAP接口
Map也被称为键/值集合,因为在实现了该接口的集合元素中都是成对出现的,一个被称为键,一个被称为值。键和值都是对象。键对象用来在Map中唯一标识一个值对象。键对象在Map中不能重复出现。
1.5.2 HashMap类
HashMap类是Map接口最常用实现之一。该类通过对键计算哈希码来决定值的存储,不保证键的存储数据。键值允许为null,但只能出现一次。
package list;
import java.util.HashMap;
public class Sample7 {
public static void main(String[] args) {
//创建HashMap对象。
HashMap hm = new HashMap();
hm.put(Integer.valueOf(97005), "tom");
hm.put(Integer.valueOf(97003), "Jerry");
hm.put(Integer.valueOf(97004), "Lucy");
hm.put(Integer.valueOf(97001), "Smith");
hm.put(Integer.valueOf(97002), "JC");
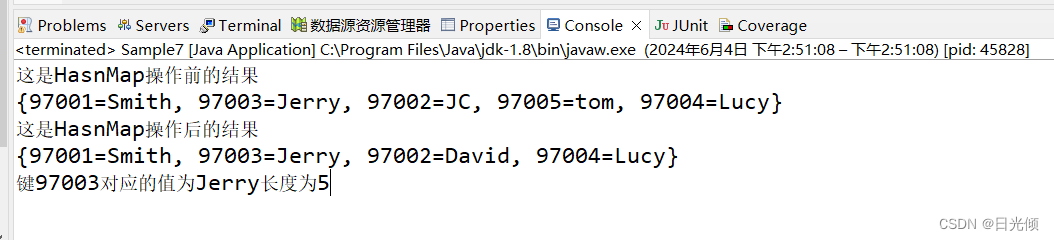
System.out.println("这是HasnMap操作前的结果");
System.out.println(hm);
hm.remove(Integer.valueOf(97005));//删除
hm.put(Integer.valueOf(97002), "David");//替换
//打印
System.out.println("这是HasnMap操作后的结果");
System.out.println(hm);
//取出指定键对应的值
Object o = hm.get(97003);
String s = (String)o;
System.out.println("键97003对应的值为"+s+"长度为"+s.length());
}
}
1.5.3 HashTable类
早起Java遗留下来的,功能特性与HashMap基本上是想听的,不同之处是该类对元素操作的方法是同步方法,在运行的时候可能会损失一些性能。因此,一般使用HashMap
package list;
import java.util.HashMap;
import java.util.Hashtable;
public class Sample8 {
public static void main(String[] args) {
//创建HashMap对象。
Hashtable ht = new Hashtable();
ht.put(Integer.valueOf(97005), "tom");
ht.put(Integer.valueOf(97003), "Jerry");
ht.put(Integer.valueOf(97004), "Lucy");
ht.put(Integer.valueOf(97001), "Smith");
ht.put(Integer.valueOf(97002), "JC");
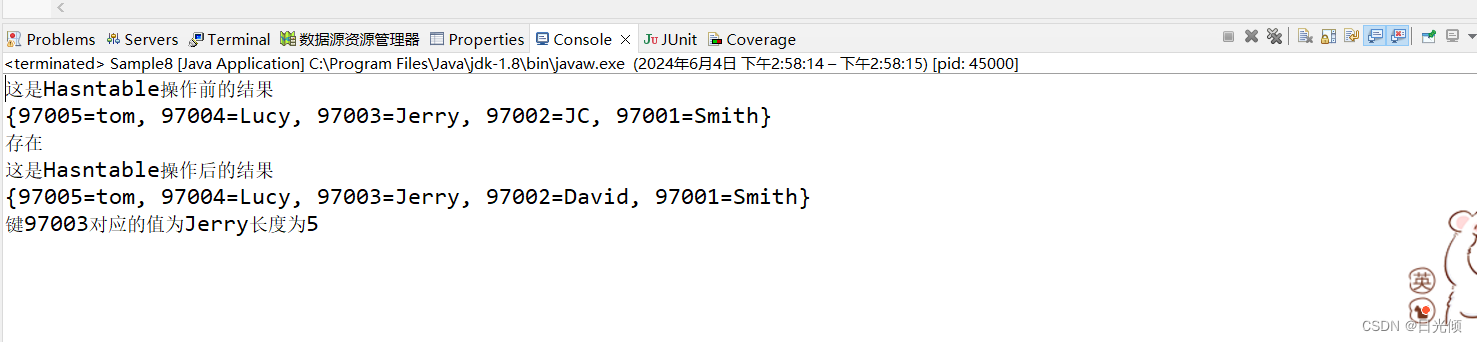
System.out.println("这是Hasntable操作前的结果");
System.out.println(ht);
//判断HashTable对象中是否存在键位97001的值
boolean b = ht.containsKey(97001);
System.out.println((b)?"存在":"不存在");
ht.put(Integer.valueOf(97002), "David");//替换
//打印
System.out.println("这是Hasntable操作后的结果");
System.out.println(ht);
//取出指定键对应的值
Object o = ht.get(97003);
String s = (String)o;
System.out.println("键97003对应的值为"+s+"长度为"+s.length());
}
}
1.5.4 LinkedHashMap类
LinkedHashMap类是通过双链表的方式实现的Map,这一点与LinkedHashSet类相同。LinkedHashMap类的基本功能与HashMap基本相同。插入/删除效率略差,遍历效率略高。
package list;
import java.util.LinkedHashMap;
public class Sample9 {
public static void main(String[] args) {
//创建LinkedHashMap对象
LinkedHashMap lhm = new LinkedHashMap();
lhm.put(Integer.valueOf(97005), "tom");
lhm.put(Integer.valueOf(97003), "Jerry");
lhm.put(Integer.valueOf(97004), "Lucy");
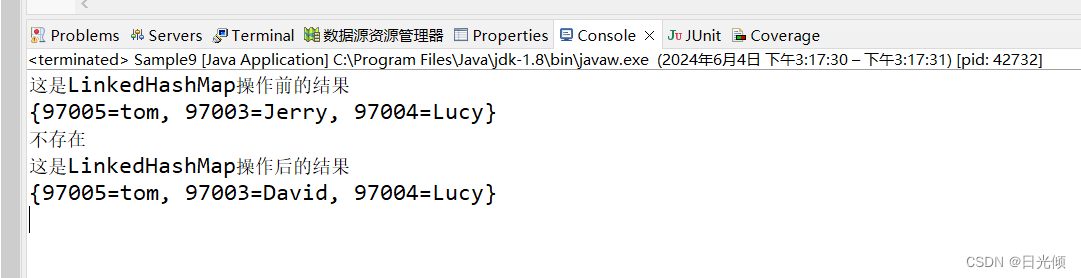
System.out.println("这是LinkedHashMap操作前的结果");
System.out.println(lhm);
lhm.put(Integer.valueOf(97003), "David");//替换
//对象中是否存在键位97001的值
boolean b = lhm.containsValue("Jerry");
System.out.println((b)?"存在":"不存在");
System.out.println("这是LinkedHashMap操作后的结果");
System.out.println(lhm);
}
}
1.6 集合元素的常用操作
在实际开发过程中,经常要对集合中的元素进行排序、搜索等操作,为了简化开发,java中提供了一个java.util.Collections类。
Collections是一个工具类。提供的功能方法是静态方法。
1.6.1 元素排序
sort() 方法主要有如下两种重载形式。
void sort(List list):根据元素的自然顺序对集合中的元素进行升序排序。
void sort(List list,Comparator comparator):按 comparator 参数指定的排序方式对集合中的元素进行排序。
package list;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Sample10 {
public static void main(String[] args) {
//创建ArrayList对象
ArrayList al = new ArrayList();
//为ArrayList初始化随机整数
for(int i = 0 ;i<50;i++) {
al.add(Integer.valueOf((int)(Math.random()*100)));
}
System.out.println("这是ArrayList排序前的结果");
System.out.println(al);
Collections.sort(al);
System.out.println("这是ArrayList排序后的结果");
System.out.println(al);
//使用比较器进行排序
Collections.sort(al,new MyComparator());
System.out.println("这是使用比较器排序之后ArrayList中的元素");
System.out.println(al);
}
}
class MyComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
// TODO Auto-generated method stub
Integer i1 = (Integer)o1;
Integer i2 = (Integer)o2;
return i2.intValue() - i1.intValue();
}
}

1.6.2 搜索特定的元素
package list;
import java.util.ArrayList;
import java.util.Collections;
public class Sample11 {
public static void main(String[] args) {
ArrayList al = new ArrayList();
//为ArrayList初始化随机整数
for(int i = 0 ;i<50;i++) {
al.add(Integer.valueOf((int)(Math.random()*100)));
}
Collections.sort(al);
//查找指定元素
int index = Collections.binarySearch(al, Integer.valueOf(20));
if(index<0) {
System.out.println("没有找到打印的结果");
}else {
System.out.println("找到了元素,索引是"+index);
for(int i = 0;i<al.size();i++) {
if(i==index) {
System.out.print("["+al.get(i)+"]");
}else {
System.out.print(al.get(i)+",");
}
}
}
}
}

1.7 技术解惑
1.7.1 ArrayList为什么是线程不安全的
ArrayList在添加一个元素的时候,可能会通过两步来完成
(1)在Items[Size]的位置存放此元素。
(2) 增大size的值。
在单线程情况下,如果Size = 0,那么添加一个元素后,此元素位置在0,而且size = 1
而在多线程运行的情况下,比如有两个线程,线程A先将元素存放在位置0,但此时CPU调度线程A,线程A暂停运行,线程B得到运行的机会。线程B也向此ArrayList添加元素。因为此时Size仍然等于0(添加一个元素需要两个步骤,而线程A仅仅完成了第一步),所以线程B也将元素存放在位置0.然后线程A和线程B都继续运行,都增加size的值。此时,ArrayList中元素只有一个存放在位置0,但Size却等于2.这就是线程不安全、
1.7.2 使用LinkedList来模拟一个堆栈或者队列数据结构
堆栈:先进后出 ,First In Lat Out,FILO
队列:先进先出 First In First Out,FIFO
public class QUEUE{
private LinkedList link;
public Queue(){
link = new LinkedList();
}
public void push(Object obj){
link.addLast(obj);
}
public Object pop(){
return link.removeFirst();
}
public boolean isEmpty(){
return link.isEmpty();
}
}