简介:
MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):

关于每个顶级元素 具体属性的详解,请移步官网: mybatis – MyBatis 3 | XML 映射器
本文只是针对新手开发中常见的几个问题,如何处理进行讲解:
1、自定义映射resultMap
1.1 resultMap处理字段和属性的映射关系
若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射
官方介绍中说,resultMap属性是对 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。
resultMap 是Select标签中一个重要的属性之一:如下图
<select
id="selectPerson"
parameterType="int"
parameterMap="deprecated"
resultType="hashmap"
resultMap="personResultMap"
flushCache="false"
useCache="true"
timeout="10"
fetchSize="256"
statementType="PREPARED"
resultSetType="FORWARD_ONLY">之前你已经见过简单映射语句的示例,它们没有显式指定 resultMap。比如:
<select id="selectUsers" resultType="map">
select id, username, password
from t_user
where id = #{id}
</select>或者,我们用一个实例对象 来接收数据库的查询结果
<select id="selectUsers" resultType="User">
select *
from t_user
where id = #{id}
</select>但是,上述条件是 数据库 表的列名 与 实例对象的属性名是一致的情况。如果二者不一致呢?该如何去做?
我们面试的时候,经常会遇到有面试官会问,数据库表的字段名和 实体对象的属性名不一致,我们如何操作,
其实解决这个问题有很多办法。
比如 利用SQL语法里的 as
<select id="selectUsers" resultType="User">
select
user_id as "id",
user_name as "userName",
user_password as "password"
from some_table
where id = #{id}
</select>我们还可以显示的配置一个外部resultMap 这也是解决列名不匹配的另外一种方式。
<!--
resultMap:设置自定义映射
属性:
id:表示自定义映射的唯一标识
type:查询的数据要映射的实体类的类型
子标签:
id:设置主键的映射关系
result:设置普通字段的映射关系
association:设置多对一的映射关系
collection:设置一对多的映射关系
属性:
property:设置映射关系中实体类中的属性名
column:设置映射关系中表中的字段名
-->
<resultMap id="userMap" type="user">
<id property="id" column="id"></id>
<result property="userName" column="username"></result>
<result property="passWord" column="password"></result>
<result property="age" column="age"></result>
<result property="gender" column="gender"></result>
</resultMap>
<select id="getMohu" resultMap="userMap" >
<!-- select * from t_user where gender like '%${keyword}%'-->
<!--select * from t_user where username like concat('%',#{keyword},'%')-->
select * from t_user where email like "%"#{keyword}"%"
</select>若字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用_),实体类中的属性 名符合Java的规则(使用驼峰)
此时也可通过以下两种方式处理字段名和实体类中的属性的映射关系:
1、可以通过为字段起别名的方式,保证和实体类中的属性名保持一致
2、可以在MyBatis的核心配置文件中设置一个全局配置信息mapUnderscoreToCamelCase,可 以在查询表中数据时,自动将_类型的字段名转换为驼峰
例如:字段名user_name,设置了mapUnderscoreToCamelCase,此时字段名就会转换为 userName
1.2、多对一映射处理
场景模拟: 查询员工信息以及员工所对应的部门信息
1.2.1 级联方式处理映射信息
我们先看一下 用原生Sql语句实现的效果:
SELECT emp.* ,dept.* FROM t_emp emp LEFT JOIN t_dept dept ON emp.`dept_id`=dept.`dept_id` WHERE emp.`emp_id`=1;

代码实现:
public class Emp{
private Integer eid;
private String ename;
private Integer age;
private String gender;
private Dept dept;
@Override
public String toString() {
return "Emp{" +
"eid=" + eid +
", ename='" + ename + '\'' +
", age=" + age +
", dept=" + dept +
", gender='" + gender + '\'' +
'}';
}
public Integer getEid() {
return eid;
}
public void setEid(Integer eid) {
this.eid = eid;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
}
public class Dept {
private Integer did;
private String dname;
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
@Override
public String toString() {
return "dept{" +
"did=" + did +
", dname='" + dname + '\'' +
'}';
}
}
接口添加方法:
Emp getEmpAndDeptByEid(@Param("id")int id); <resultMap id="empDeptMap" type="Emp">
<id column="emp_id" property="eid"></id>
<result column="emp_name" property="ename"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<result column="dept_id" property="dept.did"></result>
<result column="dept_name" property="dept.dname"></result>
</resultMap>
<!-- getEmpAndDeptByEid-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
SELECT emp.* ,dept.* FROM t_emp emp LEFT JOIN t_dept dept ON emp.`dept_id`=dept.`dept_id` WHERE emp.`emp_id`=#{id}
</select>
测试输出:

输出:
Emp{eid=1, ename='小黑', age=20, dept=dept{did=1, dname='A'}, gender='女'}
1.2.2、使用association处理映射关系
<resultMap id="empDeptMap" type="Emp">
<id column="emp_id" property="eid"></id>
<result column="emp_name" property="ename"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<association property="dept" javaType="Dept">
<id column="dept_id" property="did"></id>
<result column="dept_name" property="dname"></result>
</association>
</resultMap>1.2.3 分步查询
建立两个实体 Emp 和 Dept 分别代表 员工和 部门。
建立对应的mapper接口。
创建对应的接口映射文件
此处我作为简化,把分步查询放在了同一个接口 和映射文件中 (EmpMapper.java 和 EmpMapper.xml)
①查询员工信息
public interface EmpMapper {
/**
* 通过分步查询查询员工信息
* 分步查询:查询员工以及所在部门信息的第一步
* @param eid
* @return
*/
Emp getEmpByStep1(@Param("eid") int eid);
/**
* 分步查询的第二步: 根据员工所对应的dept_id 查询部门信息
* @param did
* @return
*/
Dept getEmpDeptByStep2(@Param("did") int did);
}<resultMap id="empDeptStepMap" type="Emp">
<id column="emp_id" property="eid"></id>
<result column="emp_name" property="ename"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<!--
select:设置分步查询,查询某个属性的值的sql的标识(namespace.sqlId)
column:将sql以及查询结果中的某个字段设置为分步查询的条件
-->
<association property="dept" fetchType="eager"
select="com.alex.mybatis.mapper.EmpMapper.getEmpDeptByStep2" column="dept_id" ></association>
</resultMap>
<!--Emp getEmpByStep1(@Param("eid") int eid);-->
<select id="getEmpByStep1" resultMap="empDeptStepMap">
select * from t_emp where emp_id = #{eid}
</select>
<!--Dept getEmpDeptByStep2(@Param("did") int did);-->
<resultMap id="deptMap" type="Dept">
<id column="dept_id" property="did"></id>
<result column="dept_name" property="dname"></result>
</resultMap>
<select id="getEmpDeptByStep2" resultMap="deptMap" >
select * from t_dept where dept_id = #{did}
</select>可以这样理解:
t_emp和t_dept 是外键包含关系,传统意义上来说,我们查询的时候,要进行外连接。
我们现在如果想得到员工的个人信息,以及所在部门的个人信息(以实体对象的形式获得查询结果),可以分步进行。
1)我们根据 eid 获取 从 t_emp 表中查询到的 员工数据 执行 step1方法,构建 员工实体对象 emp
2) 由于Emp实体对象里,包含一个属性 Dept 类型的 dept对象, 而表数据,只能给到我们 具体的部门编号did。( did 是Dept对象的属性之一)
3)所以,我们要拿着这个did 去部门表t_dept 里查询部门信息。此时 就利用了 association 标签里的 select 去执行 step2方法 (column =dept_id 填写的是 分步查询条件的数据库字段名,property 填写的是 Emp对象 当前要被分步查询的属性名)
4)Emp实例对象构建完成,返回最终执行结果
Emp{eid=1, ename='小黑', age=20, dept=Dept{did=1, dname='A'}, gender='女'}
注意事项: 一定要 注意,对象属性名是否与表字段名一一对应,否则很有可能会报nullPoint 或查不到数据,
1.3 一对多映射处理
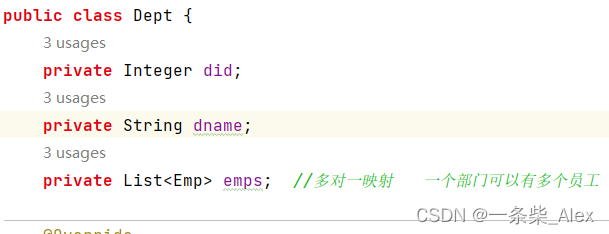
修改 Dept 如下
import java.util.List;
public class Dept {
private Integer did;
private String dname;
private List<Emp> emps; //多对一映射 一个部门可以有多个员工
@Override
public String toString() {
return "Dept{" +
"did=" + did +
", dname='" + dname + '\'' +
", emps=" + emps +
'}';
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
}
1.3.1、collection
public interface DeptMapper {
/**
* 根据部门id查新部门以及部门中的员工信息
* * @param did
* * @return
*/
Dept getDeptEmpById(@Param("did") int did);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.alex.mybatis.mapper.DeptMapper">
<resultMap id="DeptMap" type="Dept">
<id property="did" column="dept_id"></id>
<result property="dname" column="dept_name"></result>
<!--
ofType:设置collection标签所处理的集合属性中存储数据的类型
-->
<collection property="emps" ofType="Emp">
<id property="eid" column="emp_id"></id>
<result property="ename" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="gender" column="gender"></result>
<!-- <result property="dept.did" column="dept_id"></result>-->
<!-- <result property="dept.dname" column="dept_name"></result>-->
</collection>
</resultMap>
<select id="getDeptEmpById" resultMap="DeptMap">
select dept.*,emp.* from t_dept dept left join t_emp emp on dept.dept_id = emp.dept_id where dept.dept_id =#{did}
</select>
</mapper>输出结果
Dept{did=1, dname='A', emps=[Emp{eid=1, ename='小黑', age=20, dept=null, gender='女'}, Emp{eid=4, ename='赵六', age=26, dept=null, gender='男'}]}
1.3.2 分步查询
我们捋一捋思路:
现在 两个关系中,谁是多,谁是1?
根据部门编号,查询该部门全部员工,显然 部门是1,员工是多。
而且我们在Dept类中也表现出来了:
这种分步查询,其实效果类似子查询,更具体的说是一种相关子查询。
t_dept 的数据要代入到 t_emp中查询结果,所以 t_emp是被驱动表,t_dept 是驱动表。 小表驱动大表
那么,我们分步查询的步骤就是这样:
1)先查询t_dept 的 部门信息
2)再将dept_id的值带入 t_emp 查询员工信息。
DeptMapper 接口
/**
* 分步查询1: 根据did 查询部门信息
*/
Dept getDeptEmpStep1(@Param("did") int did);EmpMapper 接口
/**
*
* 通过分步查询 部门的具体信息(该部门的所有信息包括员工信息)
*/
Emp getDeptEmpStep2(@Param("did") int did);DeptMapper.xml
!-- 分步查询 查询部门全部信息-->
<resultMap id="DeptEmpMap" type="Dept">
<id property="did" column="dept_id"></id>
<result property="dname" column="dept_name"></result>
<collection property="emps" fetchType="eager"
select="com.alex.mybatis.mapper.EmpMapper.getDeptEmpStep2" column="dept_id"></collection>
</resultMap>
<select id="getDeptEmpStep1" resultMap="DeptEmpMap">
select * from t_dept where dept_id =#{did}
</select>EmpMapper.xml
<!-- 2分步查询 查询部门全部信息-->
<resultMap id="empDeptMap" type="Emp">
<id column="emp_id" property="eid"></id>
<result column="emp_name" property="ename"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<association property="dept" javaType="Dept">
<id column="dept_id" property="did"></id>
<result column="dept_name" property="dname"></result>
</association>
</resultMap>
<select id="getDeptEmpStep2" resultMap="empDeptMap">
select * from t_emp where dept_id =#{did}
</select>测试输出:

Dept{did=1, dname='A',
emps=[Emp{eid=1, ename='小黑', age=20, dept=Dept{did=1, dname='null', emps=null}, gender='女'},
Emp{eid=4, ename='赵六', age=26, dept=Dept{did=1, dname='null', emps=null}, gender='男'}]}
代码仓库:https://github.com/Chai-Feng/git-demo01.git