1、Flume集群安装部署
1.1、安装地址
- Flume官网地址:http://flume.apache.org/
- 文档查看地址:http://flume.apache.org/FlumeUserGuide.html
- 下载地址:http://archive.apache.org/dist/flume/
1.2、安装部署
- 将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/software目录下

2. 解压apache-flume-1.9.0-bin.tar.gz到/opt/model/目录下
[song@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/model/
- 修改apache-flume-1.9.0-bin的名称为flume
[song@hadoop102 model]$ mv /opt/model/apache-flume-1.9.0-bin /opt/model/flume
- 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[song@hadoop102 model]$ rm /opt/model/flume/lib/guava-11.0.2.jar
注意:删除guava-11.0.2.jar的服务器节点,一定要配置hadoop环境变量。否则会报如下异常。
Caused by: java.lang.ClassNotFoundException: com.google.common.collect.Lists
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 1 more
- 修改conf目录下的log4j.properties配置文件,配置日志文件路径
[song@hadoop102 conf]$ vim log4j.properties
flume.log.dir=/opt/module/flume/logs
2、Kafka集群安装部署
2.1、集群规划

2.2、集群部署
- 官方下载地址:http://kafka.apache.org/downloads.html
- 解压安装包
[song@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/model/
- 修改解压后的文件名称
[song@hadoop102 model]$ mv kafka_2.12-3.0.0/ kafka
- 进入到/opt/model/kafka目录,修改配置文件
[song@hadoop102 kafka]$ cd config/
[song@hadoop102 config]$ vim server.properties
#输入以下内容:
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/model/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
- 分发安装包
[song@hadoop102 model]$ xsync kafka/
- 分别在hadoop103和hadoop104上修改配置文件/opt/model/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复,整个集群中唯一。
[song@hadoop103 model]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
[atguigu@hadoop104 model]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
- 配置环境变量
(1)在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
[song@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
增加如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/model/kafka
export PATH=$PATH:$KAFKA_HOME/bin
(2)刷新一下环境变量。
[song@hadoop102 model]$ source /etc/profile
(3)分发环境变量文件到其他节点,并source。
[song@hadoop102 model]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
[song@hadoop103 model]$ source /etc/profile
[song@hadoop104 model]$ source /etc/profile
- 启动集群
(1)先启动Zookeeper集群,然后启动Kafka。
[song@hadoop102 kafka]$ zk.sh start
(2)依次在hadoop102、hadoop103、hadoop104节点上启动Kafka。
[song@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[song@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[song@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
注意:配置文件的路径要能够到server.properties。
- 关闭集群
[song@hadoop102 kafka]$ bin/kafka-server-stop.sh
[song@hadoop103 kafka]$ bin/kafka-server-stop.sh
[song@hadoop104 kafka]$ bin/kafka-server-stop.sh
2.3、集群启停脚本
- 在/home/song/bin目录下创建文件mykafka.sh脚本文件
[song@hadoop102 bin]$ vim kf.sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
- 添加执行权限
[song@hadoop102 bin]$ chmod +x kf.sh
- 启动集群命令
[song@hadoop102 ~]$ kf.sh start
- 停止集群命令
[song@hadoop102 ~]$ kf.sh stop
注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
3、Maxwell安装部署
3.1、Maxwell简介
3.1.1、Maxwell概述
Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变更数据以 JSON 格式发送给 Kafka、Kinesi等流数据处理平台。官网地址:http://maxwells-daemon.io/
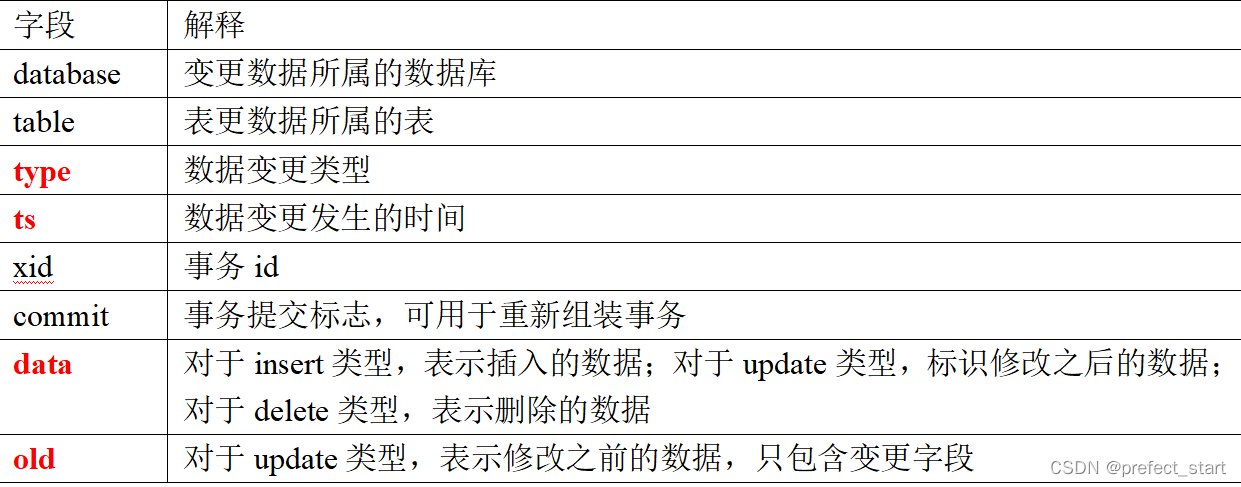
3.1.2、Maxwell输出数据格式

注:Maxwell输出的json字段说明:
3.2、Maxwell原理
Maxwell的工作原理是实时读取MySQL数据库的二进制日志(Binlog),从中获取变更数据,再将变更数据以JSON格式发送至Kafka等流处理平台。
3.2.1、MySQL二进制日志
二进制日志(Binlog)是MySQL服务端非常重要的一种日志,它会保存MySQL数据库的所有数据变更记录。Binlog的主要作用包括主从复制和数据恢复。Maxwell的工作原理和主从复制密切相关。
3.2.2、MySQL主从复制
MySQL的主从复制,就是用来建立一个和主数据库完全一样的数据库环境,这个数据库称为从数据库。
- 主从复制的应用场景如下:
- 做数据库的热备:主数据库服务器故障后,可切换到从数据库继续工作。
- 读写分离:主数据库只负责业务数据的写入操作,而多个从数据库只负责业务数据的查询工作,在读多写少场景下,可以提高数据库工作效率。
- 主从复制的工作原理如下:
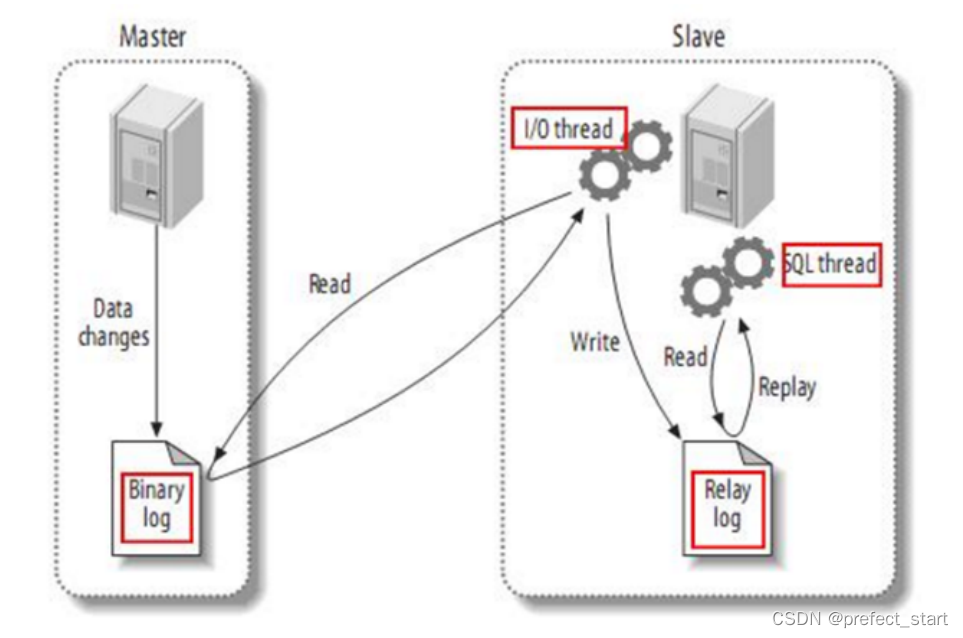
- Master主库将数据变更记录,写到二进制日志(binary log)中
- Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
- Slave从库读取并回放中继日志中的事件,将改变的数据同步到自己的数据库。
3.2.3、Maxwell原理
将自己伪装成slave,并遵循MySQL主从复制的协议,从master同步数据。
3.3、Maxwell部署
3.3.1、安装Maxwell
- 下载安装包
地址:https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
注:Maxwell-1.30.0及以上版本不再支持JDK1.8。- 将安装包上传到hadoop102节点的/opt/software目录
注:此处使用教学版安装包,教学版对原版进行了改造,增加了自定义Maxwell输出数据中ts时间戳的参数,生产环境请使用原版。
- 将安装包解压至/opt/model
[song@hadoop102 maxwell]$ tar -zxvf maxwell-1.29.2.tar.gz -C /opt/model/
- 修改名称
[song@hadoop102 model]$ mv maxwell-1.29.2/ maxwell
3.3.2、配置MySQL
3.3.2.1、启用MySQL Binlog
MySQL服务器的Binlog默认是未开启的,如需进行同步,需要先进行开启
- 修改MySQL配置文件/etc/my.cnf
[song@hadoop102 ~]$ sudo vim /etc/my.cnf
- 增加如下配置
[mysqld]
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall
注:MySQL Binlog模式
- Statement-based:基于语句,Binlog会记录所有写操作的SQL语句,包括insert、update、delete等。
优点: 节省空间
缺点: 有可能造成数据不一致,例如insert语句中包含now()函数。 - Row-based:基于行,Binlog会记录每次写操作后被操作行记录的变化。
优点:保持数据的绝对一致性。
缺点:占用较大空间。 - mixed:混合模式,默认是Statement-based,如果SQL语句可能导致数据不一致,就自动切换到Row-based。
注意:Maxwell要求Binlog采用Row-based模式。
- 重启MySQL服务
[song@hadoop102 ~]$ sudo systemctl restart mysqld
3.3.2.2、创建Maxwell所需数据库和用户
Maxwell需要在MySQL中存储其运行过程中的所需的一些数据,包括binlog同步的断点位置(Maxwell支持断点续传)等等,故需要在MySQL为Maxwell创建数据库及用户。
- 创建数据库
msyql> CREATE DATABASE maxwell;
- 调整MySQL数据库密码级别
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
- 创建Maxwell用户并赋予其必要权限
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
3.3.2.2、配置Maxwell
- 修改Maxwell配置文件名称
[song@hadoop102 maxwell]$ cd /opt/model/maxwell
[song@hadoop102 maxwell]$ cp config.properties.example config.properties
- 修改Maxwell配置文件
[song@hadoop102 maxwell]$ vim config.properties
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
#目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=maxwell
#MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
4、Maxwell使用
4.1、启动Kafka集群
若Maxwell发送数据的目的地为Kafka集群,则需要先确保Kafka集群为启动状态。
4.2、Maxwell启停
- 启动Maxwell
[song@hadoop102 ~]$ /opt/model/maxwell/bin/maxwell --config /opt/model/maxwell/config.properties --daemon
- 停止Maxwell
[song@hadoop102 ~]$ ps -ef | grep maxwell | grep -v grep | grep maxwell | awk '{print $2}' | xargs kill -9
- Maxwell启停脚本
- 创建并编辑Maxwell启停脚本
[song@hadoop102 bin]$ vim mxw.sh
- 脚本内容如下
#!/bin/bash
MAXWELL_HOME=/opt/module/maxwell
status_maxwell(){
result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`
return $result
}
start_maxwell(){
status_maxwell
if [[ $? -lt 1 ]]; then
echo "启动Maxwell"
$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemon
else
echo "Maxwell正在运行"
fi
}
stop_maxwell(){
status_maxwell
if [[ $? -gt 0 ]]; then
echo "停止Maxwell"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
else
echo "Maxwell未在运行"
fi
}
case $1 in
start )
start_maxwell
;;
stop )
stop_maxwell
;;
restart )
stop_maxwell
start_maxwell
;;
esac
4.3、增量数据同步
- 启动Kafka消费者
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic maxwell
- 模拟生成数据
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar
- 观察Kafka消费者
{"database":"gmall","table":"comment_info","type":"insert","ts":1634023510,"xid":1653373,"xoffset":11998,"data":{"id":1447825655672463369,"user_id":289,"nick_name":null,"head_img":null,"sku_id":11,"spu_id":3,"order_id":18440,"appraise":"1204","comment_txt":"评论内容:12897688728191593794966121429786132276125164551411","create_time":"2020-06-16 15:25:09","operate_time":null}}
{"database":"gmall","table":"comment_info","type":"insert","ts":1634023510,"xid":1653373,"xoffset":11999,"data":{"id":1447825655672463370,"user_id":774,"nick_name":null,"head_img":null,"sku_id":25,"spu_id":8,"order_id":18441,"appraise":"1204","comment_txt":"评论内容:67552221621263422568447438734865327666683661982185","create_time":"2020-06-16 15:25:09","operate_time":null}}
4.4、历史数据全量同步
使用Maxwell实时增量同步MySQL变更数据的功能。但有时只有增量数据是不够的,我们可能需要使用到MySQL数据库中从历史至今的一个完整的数据集。这就需要我们在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。
4.4.1、Maxwell-bootstrap
Maxwell提供了bootstrap功能来进行历史数据的全量同步,命令如下:
[song@hadoop102 maxwell]$ /opt/model/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/model/maxwell/config.properties
4.4.2、boostrap数据格式
采用bootstrap方式同步的输出数据格式如下:
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-start",
"ts": 1450557744,
"data": {}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "hello"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "bootstrap!"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-complete",
"ts": 1450557744,
"data": {}
}
注意事项:
- 第一条type为bootstrap-start和最后一条type为bootstrap-complete的数据,是bootstrap开始和结束的标志,不包含数据,中间的type为bootstrap-insert的数据才包含数据。
- 一次bootstrap输出的所有记录的ts都相同,为bootstrap开始的时间。