技术群里的朋友遇到了这个问题,起初的原因是他对文件增加了一个属性配置
fileResult.EnableRangeProcessing = true;
这个属性我从未遇到过,然后,去F1查看这个属性的描述信息也依然少的可怜,只有简单的描述为(获取或设置为 启用范围处理 FileResult的值)。
范围处理,很容易理解,可能就是实现分片下载的关键,但是,是不是就很简单配置就可以了呢,我对此十分感兴趣,就开始查询它的实际信息。
EnableRangeProcessing 属性的含义
经查看Asp.net Core 源码可以看到,它实际上只是配置了一个头信息。
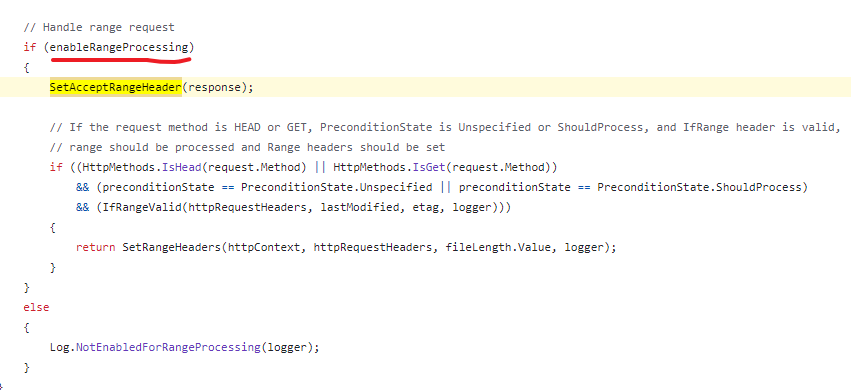
具体的方法内部,只是一个赋值
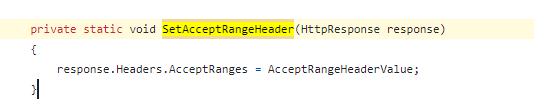
赋值的是什么呢,其实就是一个HTTP 头标记

所以,实际上,它只做了一件事情,那就是把请求的头变成以下的样子。
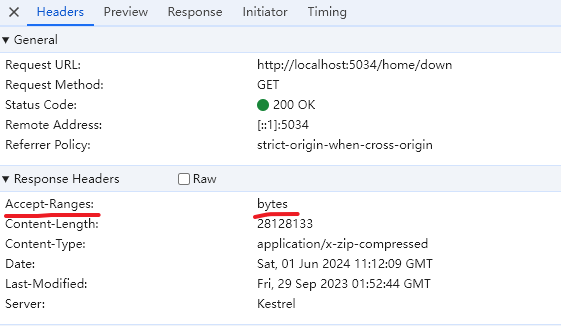
是的,它只是做了这一件事情,那就是把请求头 Accept-Ranges 的值设置为了 bytes 。
HTTP 协议头之 Accept-Ranges
经查寻,此头就是表示着 (Accept-Ranges HTTP 响应标头是服务器使用的一个标记,用于向客户端宣传其对文件下载的部分请求的支持。此字段的值表示可用于定义范围的单位。 )
当存在 Accept-Ranges 标头时,浏览器可能会尝试恢复中断的下载,而不是尝试重新启动下载。
所以,设置它就相当于设置了Asp.net Core 支持分片下载。
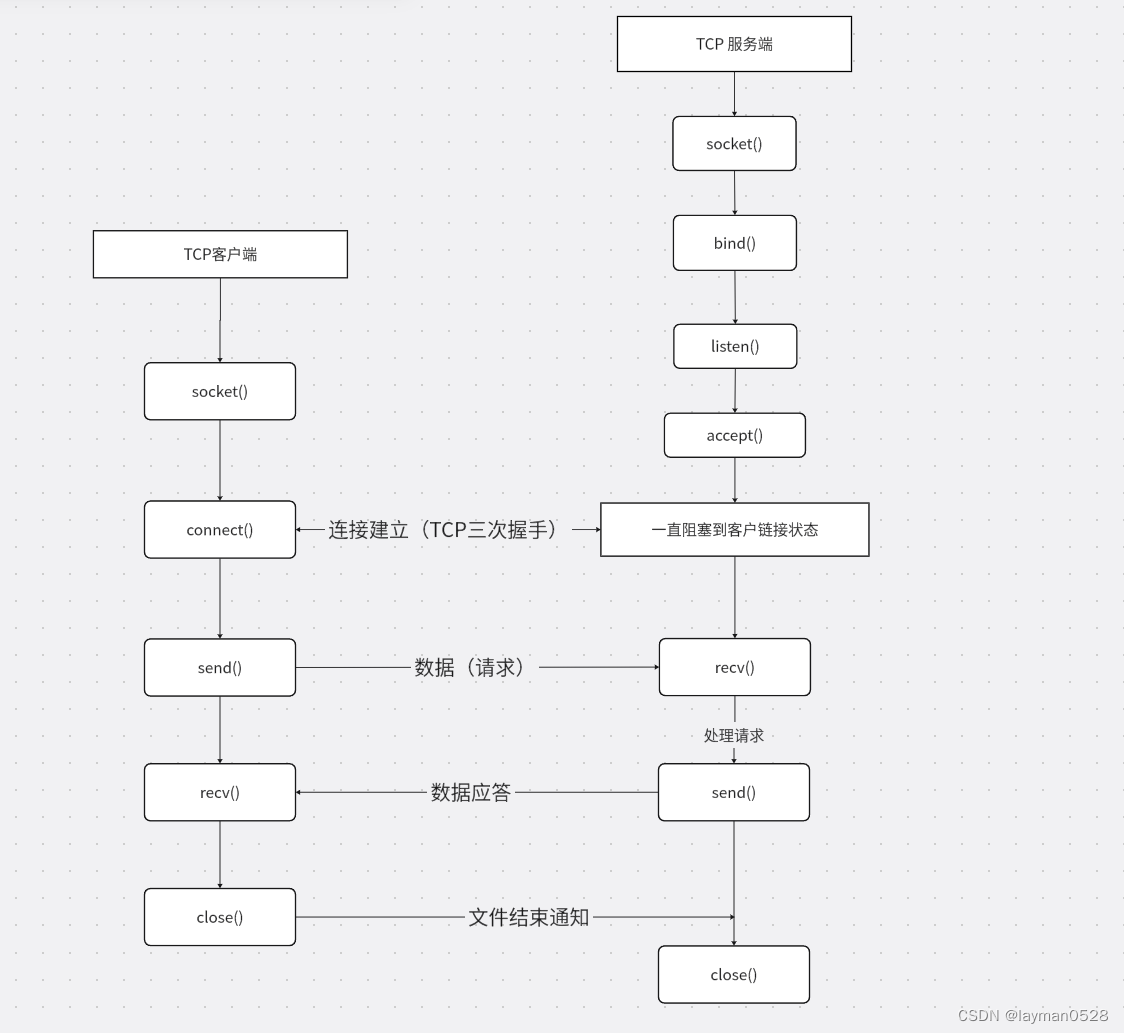
Asp.net Core 分片下载实际案例
主要分为服务端和客户端,服务端设置允许分片下载,客户端则需要按照分片进行多线程下载,我这里实际通过并行下载实现。
最后的验证,能运行它或者打开它即可(比如zip格式等)。
服务端代码
服务端异常的简单,新建一个Asp.net Core 项目即可,其他都默认。
我们要做的事情只是在 HomeController 里增加以下代码
private FileExtensionContentTypeProvider provider = new FileExtensionContentTypeProvider();
public IActionResult Down()
{
var file = @"H:\百度网盘\ubuntu.zip";
provider.TryGetContentType(file, out var contentType);
var result = PhysicalFile(file, contentType);
result.EnableRangeProcessing = true;
result.FileDownloadName = Path.GetFileName(file);
return result;
}
里面有几个点
- 设置文件的类型可以用 FileExtensionContentTypeProvider 这个类来的,不用自己写(特殊类型它不支持)
- 设置EnableRangeProcessing 为 true ,才能实现分片下载
- 设置FileDownloadName为具体的下载文件名,才可以在客户端知道你下载的文件名的名字,很重要。
客户端代码
客户端稍微复杂一些,得获取文件的大小和名字,然后,进行多线程下载,我这边会进行一个简单的模拟。
直接下载文件的逻辑
public static async Task DownUrl(string url)
{
var result = await client.SendAsync(new HttpRequestMessage(HttpMethod.Get, url), HttpCompletionOption.ResponseHeadersRead);
if (result.IsSuccessStatusCode)
{
var filename = "temp.zip";
using (var contentStream = await result.Content.ReadAsStreamAsync())
{
using (var file = File.OpenWrite(filename))
{
await contentStream.CopyToAsync(file);
}
}
}
}
当然,如果不想分片下载,可以直接下载即可。
获取文件大小以及名字
public static async Task<(long? length, string filename)> GetFileLengthandName(string url)
{
var result = await client.SendAsync(new HttpRequestMessage(HttpMethod.Get, url), HttpCompletionOption.ResponseHeadersRead);
if (result.IsSuccessStatusCode)
{
return (result.Content.Headers.ContentLength, result.Content.Headers.ContentDisposition.FileName);
}
return (null, null);
}
主要就是通过httpclient 自带的头信息,直接获取即可。挺简单的。
分片下载核心
首先是对获取到的文件大小进行一个范围的分割
public struct BytesRange
{
public long Start { get; set; }
public long End { get; set; }
public long Length { get { return End - Start + 1; } }
public override string ToString()
{
return $"{Start} {End} : {Length}";
}
public static List<BytesRange> GetRanges(long length, long BufferSize = 1 * 1024 * 1024)
{
List<BytesRange> list = new List<BytesRange>();
long count = length / BufferSize;
long Lost = length - BufferSize * count;
if (Lost > 0)
{
list.Add(new BytesRange() { Start = count * BufferSize, End = count * BufferSize + Lost - 1 });
}
if (count > 0)
{
for (long i = 0; i < count; i++)
{
list.Add(new BytesRange() { Start = i * BufferSize, End = (i + 1) * BufferSize - 1 });
}
}
else
{
list.Add(new BytesRange() { Start = 0, End = Lost - 1 });
}
list.OrderByDescending(t => t.Start);
return list;
}
}
这样就可以获取具体的分片信息,具体每片的大小。
public static async Task<byte[]> GetBytesAsync(string url, BytesRange range)
{
var request = new HttpRequestMessage(HttpMethod.Get, url);
request.Headers.Add("Range", $"bytes={range.Start}-{range.End}");
using (HttpResponseMessage response = await client.SendAsync(request))
{
using (Stream stream = await response.Content.ReadAsStreamAsync())
{
if (range.Length != stream.Length)
{
throw new Exception("数据不匹配!");
}
byte[] bytes = new byte[stream.Length];
stream.Read(bytes, 0, bytes.Length);
return bytes;
}
}
}
GetBytesAsync 就是按照指定的大小分为进行请求,并返回所需的文件大小。
实际代码
static HttpClient client = new HttpClient();
static object lockObj = new object();
static async Task Main(string[] args)
{
var url = "http://localhost:5034/home/down";
Stopwatch stopwatch = Stopwatch.StartNew();
await DownUrl(url);
stopwatch.Stop();
Console.WriteLine($"单线程 直接下载耗时:{stopwatch.Elapsed.TotalSeconds}");
stopwatch.Restart();
(long? length, string filename) = await GetFileLengthandName(url);
if (length.HasValue)
{
var number = 10;
//获取分片大小,默认1M 缓存区,太小又太慢 设置成5M。
var list = BytesRange.GetRanges(length.Value, 5 * 1024 * 1024);
Console.WriteLine($"分片数:{list.Count} 每片大小:5MB 并发数:{number}");
var path = Path.Combine(AppContext.BaseDirectory, filename);
using (var write = File.OpenWrite(path))
{
write.SetLength(length.Value);
await write.FlushAsync();
// 并行下载,每秒默认10并发
Parallel.ForEach(list, new ParallelOptions() { MaxDegreeOfParallelism = number }, range =>
{
//Console.WriteLine($"{DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss.fff")} {range}");
var bytes = GetBytesAsync(url, range).Result;
lock (lockObj)
{
write.Seek(range.Start, SeekOrigin.Begin);
write.Write(bytes);
}
});
}
Console.WriteLine("下载完毕,请验证!");
}
else
{
Console.WriteLine("没有获取到下载文件的信息!");
}
stopwatch.Stop();
Console.WriteLine($"并发下载 耗时:{stopwatch.Elapsed.TotalSeconds}秒");
Console.ReadLine();
}
验证结果
先运行服务端
再运行下载客户端
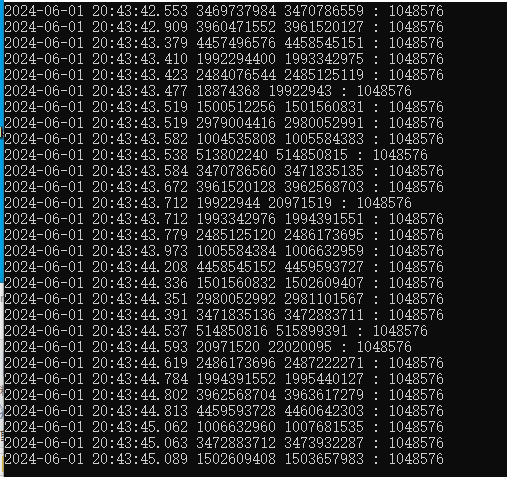
看到结果后,有点差异
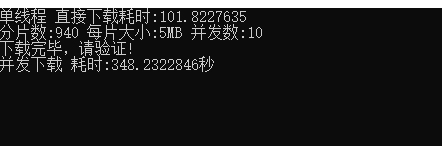
从结果上来看,直接下载是最快的,应该是少了分片的开销,而且服务都是在本机上,各种IO的限制基本上只有文件IO,带宽IO影响最小。
总结
虽然直接下载是最快的,但是,如果网络中断的话,基本得重新下载,所以,它的风险反而是最高的,而分片下载虽然有了分片的开销的,但是可以从断点处继续下载,风险反而最低,各有优势。
代码地址
https://github.com/kesshei/WebDown.git
https://gitee.com/kesshei/WebDown.git
参考资料地址
《enableRangeProcessing 的代码地址》
https://github.com/dotnet/aspnetcore/blob/53db4d97d7c77d13e20e58a98f104e88d6af6040/src/Shared/ResultsHelpers/FileResultHelper.cs#L141
《Accept-Ranges 》
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Accept-Ranges
阅
一键三连呦!,感谢大佬的支持,您的支持就是我的动力!