1、 前言
打算写一个系列的文章,主要是mysql底层解析。
很多时候,程序员对mysql处于频繁使用,但都一知半解的程度,除了会加个索引,貌似也没啥优化的技能了。事实上,mysql能有今日的成就,必然不是靠个索引就吃饭的。更何况很多情况下,索引什么的应用层面也解决不了实际问题。那么,我们就需要深入到mysql内部去一探究竟。
分层架构
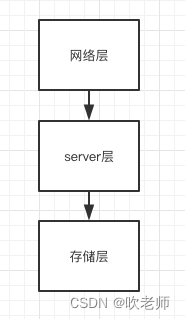
大多数数据库都是这样的结构,mysql作为一个插件式的数据库,在存储层支持多种引擎,譬如默认的innodb,和之前版本默认的MyIsam。存储层相对来说还比较好理解,由不同的引擎提供相同的接口给server层调用,来完成数据的增删改查。
server层是mysql比较复杂的地方,里面包含了大量的逻辑,譬如语义分析、查询优化、日志、缓存等等。
网络层就比较简单一些,就是提供socket连接的地方。
网络层
在mysql的网络层,我们主要关注3个地方
1 》Poll、Select模型
2》 Max-connections
3》 connection复用
mysql在启动后,创建了socket server,绑定了3306端口,并对其进行监听。和java里的写法类似,用一个while循环来监听新来的connection,如果有了新连接,就创建一个新的连接线程去处理(不能超过max-connections)。
这种就是典型的BIO的模式,为每一个连接创建一个线程。并且,mysql在这里采用了IO多路复用,会有一个if语句来判断当前系统是否支持Poll模式,否则就走Select模型(各个系统默认都有实现)。
Poll模型和Select非常类似,只是少了1024个fd的限制,都是采用遍历数组轮询有没有新IO事件的方式,在连接数较少的情况下,性能优异,要好于epoll。
关于BIO和poll、select、epoll,如果不太了解,可以看这一篇。
mysql基于BIO,本质上是不接受大量的socket连接的,原因懂BIO的都知道,所以设置了max-connections这个限制,超过设置的max,那么新来的连接会被拒绝。那么,我们迎来了第一个问题,为什么是BIO,而不是可以承受更大连接数的NIO和AIO呢?是否用NIO就会更好呢?
mysql的BIO
先来看看bio和nio的区别,在BIO模式下,调用read,如果发现没数据,就会Block住。在NIO模式下,调用read,如果发现没数据,就会立刻返回-1, 并且errno被设为EAGAIN。
做server开发的都知道,tomcat、netty之类的web服务器,都是基于NIO+IO多路复用的模式,来大幅提升性能,承载高并发访问的。但是到了DB层,就变成了hakiri、druid之类的线程池,开启10个线程去连接mysql,反复复用这个线程池。
首先要理解一个概念,NIO+IO多路复用并不是指多个用户socket共享一个IO,从而使得服务端的socket数量大减。而是把多个socket连接,归并到一个进程进行管理,譬如用一个大数组来聚合起来,然后循环遍历这个数组,来一次性把多个连接的事件通知业务代码进行处理。这个很好理解,之前是给每个孩子分配一个老师,孩子没事时,老师也跟着闲着等待。现在是,把一大堆孩子归一个老师管,老师每次都从头到尾问一遍,有没有事,有事了再处理。这样就大幅减少了server的压力,高效利用资源。
对mysql来说,一般都会有多个连接,毕竟并发肯定是要有的。不可能做个查询,也要大家一起排队等上一个人查询完。所以线程池和并发是一定的。
mysql和web Server有一个重大区别,一个Web请求,往往是无状态的,一问一答的时候居多,请求也往往比较短促,对于顺序性也不是十分严格,哪怕是后请求的响应比先请求的提前到,也是有可能的。而DB就不一样了,DB采用session作为一个连接会话,这一个session里,SQL的执行必须是串行、同步、有序的,而不能是异步乱序的。原因都明白,一个session内可能有多个操作,增删改查、事务隔离,必须保证顺序不能乱。DB维护这样一个session,是要花费远大于web Server处理一个请求的资源才能完成的。
那么对于DB来说,连接是非常耗资源的事情,限制连接数是非常有必要的。绝不是平时当你连接mysql出问题时,就听别人的,随便加大应用服务的连接池和增大mysql的max-connection。往往你做的这些,不能改善mysql的性能。后面会有例子,来讲当进行非常密集的数据库操作时,连接池的数量对性能产生的巨大影响。
扯了这么多,貌似没有讲为什么用BIO,而不是NIO。
原因很简单,JDBC不支持,JDBC出现了20年了,它是一个标准,在它被提出时,只有BIO模型一家,还没有别的IO呢,你用个毛线。各家数据库驱动对JDBC的实现都是BIO的形式,你的mysql驱动connector早早地实现了JDBC标准,就是采用阻塞的方式。当你进行一个select查询,在查询没有完成之前,整个调用线程会被卡住,等到天荒地老也要等下去,绝不是一请求立马收到返回,然后等mysql回调你结果。
民间也有人修改了mysql的协议,增加了NIO+多路复用的功能,但是本身形不成气候,根本原因还是mysql和web server功能意义都不一样,确切地说,90%的场景下,你不需要一个NIO的数据库。
BIO+连接池已经发展了很多年,大部分问题都已经解决,在目前的java环境中,是非常靠谱的方案。已经出现了很多优秀的连接池框架,你只需要配置好账号密码和连接池数量,就能很开心的使用mysql了。
而从mysql的角度来说,客户端多是一些IO密集型的应用,在一个线程里频繁做大量IO操作,而不是说有巨多的客户端来反复连接我。毕竟,mysql的用户是你写的几个程序应用,而web server的用户是千千万的吃瓜群众。
连接池
mysql能支撑的连接数是有限的,那么就需要应用程序来利用好连接池。对于连接池来说,就是做好这10个连接的管理就好。
对于mysql来说,管理好自己的所有连接也是很重要,哪些空闲的该休息就休息,让出资源,该复用就复用,避免创建太多线程。
要记住一个基本原则,IO密集的时候,要减少连接数。譬如你要读写几千万数据,非常密集的IO操作,那么你可以尝试一下开启少量的mysql连接(和cpu的核数相同)和开启大量的连接(成百上千),来做同样的事。你会发现,更少的连接数,会给你带来几百倍的性能提升。
原因也很简单,你有4辆车(4核),要从仓库里拉一大堆货物到另一个地方。如果只有4条路,那么很简单,一个车走一路,反复折返跑就是了。现在有了100条路,你还是4个车,你的车要频繁的在100条路上来回切换,每条路都必须要走到,你说哪个快。
线程间的轮转会耗费大量的资源,尤其在密集操作时。但是当不密集时,情况就变了,大量的线程处于休息状态,那么你即便多开了几个连接,CPU还是能很快的照顾到你,并没有什么大的影响。
网络协议
这个就不多说了,作为RPC的连接,肯定是要有个自己的协议的,mysql作为数据库肯定是不能用http那种比较臃肿的方式。那么就有自己的rpc数据协议,收发两端做好解码转码就好了,对用户是透明的。
这一篇主要讲网络层,对于网络层相对比较简单,需要关注的也主要是连接数。