原课程链接: 嵌入式开发系统学习路线 从基础到项目 精品教程 单片机工程师必备课程 物联网开发 c语言 2022追更
前言
在学习过程中,老师提到了一个很重要的思想:主要从学习嵌入式的角度学习各项技能。比如c语言,语法有很多,但是其中可能有的在嵌入式开发中并不常用。如果是抱着高中备考的态度去学,搞懂每一个知识点,会浪费大量的精力。而且适用相关方面有基础的人。因此,如果读者把其中某一部分拿出来单独学习(比如为了学习c语言而学习C语言章节)并不合适。
像以往一样,我只是整理了供自己学习的学习笔记,希望读者多多支持原作者~ 也希望我的理解对你有帮助。
C 语言开发基础
本章节主要学习与嵌入式开发相关的 C语言基础知识。最终成果期望能做出 Zlog 的日志框架和 google test 的自测框架。
基本数据类型
char short int。
unsigned char: 0x00~0xff
unsigned short: 0x0000~0xffff
unsigned int: 0x00~0xffff ffff.
要熟悉一些类型的转换。
应用:比如Unix时间戳,可以转换为8位的16进制数(如:AAAA AAAA)。服务器可能发送一个一维长度为4的 unsigned char 数组给我们,我们要通过移位运算合并。
unsigned char time_stamp_arr[4]=[0XAA,0XAA,0XAA,0XAA];
unsigned int time_stamp=(((((time_stamp_arr[0]<<8)|time_stamp_arr[1])<<8)|time_stamp[2])<<8)|time_stamp[3];
判断
判断当然非常常用。点灯可能就用的到判断。
主要就是 if 和 switch 的语法。多判断当然更推荐 switch。
循环
遍历当然用途也很广。比如一直循环查看有无新订单。
for 和 while 的语法。
static
首先,static 可以限制作用域。被 static 限制的函数不能被其他文件使用。除非这个函数在同一个文件中被非 static 的函数引用了,然后别的文件引用那个非 static 的函数来间接引用这个函数。
vscode 怎么运行多个源代码文件?比如要运行 Main.c,Main.c 中引用了 PrintMessage.c 中的内容,就可以输入gcc Main.c PrintMessage.c -o Main来链接多个源代码文件并生成可执行文件Main.exe. 注意这里没有 -c,-c 后跟多个文件会报错。
然后进行本例的测试。我在 PrintMessage.c 中这样写:
#include<stdio.h>
#include"PrintMessage.h"
void printMessage(){
printMessage1();
}
static void printMessage1(){
printf("hello world");
}
在 PrintMessage.h 中这样声明:
#ifndef _PRINTMESSAGE_H
#define _PRINTMESSAGE_H
#include<stdio.h>
void printMessage();
void printMessage1();
#endif
注意这里如果 printMessage1() 声明也是 static 类型,Main 就会报错直接找不到这个函数。如果 .h 声明中没有 static 关键字,Main 会正常提示:这个函数是 static 的,你别的文件用不了。但是通过 printMessage() 间接调用 printMessage1() 是可以的。
static 还可以声明变量,被 static 修饰的变量指挥被定义一次,下次访问时仍然继承上次的值。比如我们要统计一台坏掉的打印机被访问了几次:
void printMessage(){
static int i=0;
printf("i=%d\n",i++);
}
当这个函数被 Main.c 访问5次,输出并不是00000每次重新定义,而是01234值一直继承。
define typedef
就是同内容替换。比如区分测试和发布版本,或者开启关闭日志功能可能有用。
比如:
#define LOG_OPEN 1//这一句没有被注释,才能输出当前版本信息。注释掉了就说明关闭日志了,不会开启选择结构
#define VERSION_PRE 1
//#define VERSION_POST 1
//#define VERSION GLOD 1
#ifdef LOG_OPEN
#ifdef VERSION_PRE
printf("This is a pre version!\n");
#ifdef VERSION_POST
printf("This is a post version!\n");
#elif VERSION_GLOD//正式版
printf("This is a glod version!\n");
#endif
通过这种方式首先选择开启还是关闭日志。如果开启,区分是测试版,发布版还是正式版,并执行相应的代码。发布的时候我们就可以直接修改 define 发布。
define 和 typedef 的区别:define 就直接在原文中替换了,typedef 是别名的意思。比如:
#define PCHAR1 char *
PCHAR1 c1,c2;//相当于:char *c1, c2; 实际上 c1 是指针,c2 是 char 类型。
typedef char * PCHAR2
PCHAR2 c3,c4;//相当于:char *c1;char *c2;
typedef 常用于类型定义,比如比较经典的单片机定义:unsigned char => u8, unsigned short => u16, unsigned int =>u32。
enum
比如我们要确认当前网络连接状态,可能有四种:初始化,连接中,连接成功,连接失败。我们可以给这四种状态定义值=1 2 3 4。
int net_status=2;
switch(net_status){
case 1:
printf("NETWORK INITING");
break;
case 2:
printf("NETWORK CONNECTING");
break;
case 3:
printf("NETWORK CONNECT SUCCESS");
break;
case 4:
printf("NETWORK CONNECT FAIL");
break;
default:
printf("ERROR OCCURRED!\n");
break;
}
1 2 3 4 挺难理解的。我们就可以用上刚刚学到的 #define,赋予 1 2 3 4 意义。
#define NET_CONNECT_INIT 1
#define NET_CONNECT_ING 2
#define NET_CONNECT_SUCCESS 3
#define NET_CONNECT_FAIL 4
int net_status=NET_CONNECT_ING;
switch(net_status){
case NET_CONNECT_INIT:
printf("NETWORK INITING");
break;
case NET_CONNECT_ING:
printf("NETWORK CONNECTING");
break;
case NET_CONNECT_SUCCESS:
printf("NETWORK CONNECT SUCCESS");
break;
case NET_CONNECT_FAIL:
printf("NETWORK CONNECT FAIL");
break;
default:
printf("ERROR OCCURRED!\n");
break;
}
这样可读性高多了。但是如果能给 status 加些限制就更好了,让其值只能从4种 define 中选择。
typedef enum{
NET_CONNECT_INIT,
NET_CONNECT_ING,
NET_CONNECT_SUCCESS,
NET_CONNECT_FAIL,
}E_NET_STATUS;
struct
自己定义一种结构类型。比如一个学生有姓名年龄性别等属性。一台售货机有各种传感器、各种设备的属性。定义为一个结构体方便管理。
typedef struct {
/* data */
char *name;
int age;
enum{f,m,} sex;
}Student;
void main(){
Student s1;
s1.age=19;
s1.sex=f;
s1.name="girl";
printf("s1.name=%s",s1.name);
}
指针
普通变量是为了表示数据而生,指针变量是为了传递数据而生。指针变量指明了一个变量数据的地址,所有人拿到那个地址之后都可以去那个地址找那个变量读写,而不像普通的函数传参,得到的变量只是复制了一份,修改也不是修改的原来的变量。
比如最经典的 swap 函数,直接传普通的变量原变量值并不会被修改。
void swap(int *a, int *b){
int temp=*a;
*a=*b;
*b=temp;
}
int main(){
int a=10;
int b=20;
swap(&a,&b);
printf("a=%d\nb=%d\n",a,b);
}
同类型的多个数据可以用数组存储。
回调函数
菜鸟教程上的使用例:
#include<stdio.h>
int Callback_1(int x) // Callback Function 1
{
printf("Hello, this is Callback_1: x = %d ", x);
return 0;
}
int Callback_2(int x) // Callback Function 2
{
printf("Hello, this is Callback_2: x = %d ", x);
return 0;
}
int Callback_3(int x) // Callback Function 3
{
printf("Hello, this is Callback_3: x = %d ", x);
return 0;
}
int Handle(int y, int (*Callback)(int))
{
printf("Entering Handle Function. ");
Callback(y);
printf("Leaving Handle Function. ");
}
int main()
{
int a = 2;
int b = 4;
int c = 6;
printf("Entering Main Function. ");
Handle(a, Callback_1);
Handle(b, Callback_2);
Handle(c, Callback_3);
printf("Leaving Main Function. ");
return 0;
}
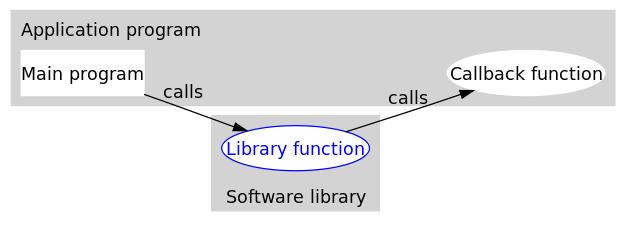
可见,回调函数的一个特点是耦合性低。针对不同的回调函数我们使用同一个函数接口。
另一个特点:类似中断处理,可以在发生某事件时主动调用该函数。
比如,我们想让自动售货机货空的时候发消息提示我们:没有货物啦。要补货。怎样实现?
第一种实现方式:我们写一个循环 while(1) 函数,在里面一直一直判断if(good_num==0),变为0的时候输出信息“要补货”。
死循环好吗,不好。浪费系统资源。
第二种实现方式:我们不必被动的一遍遍检查当前货物有没有=0,我们可以在货物=0时主动调用回调函数输出信息“要补货”。在货物=0时调用 Handle 函数,传入回调函数指针和货物数:0,主动访问该函数。
数据结构基本概念
有时候我们可能需要做数据拷贝。
malloc 函数裸机不建议使用。因为无法利用碎片化空间,只能直接申请一整块空间。带操作系统的计算机可以。
为了实现数据拷贝,我们还是有必要了解一些数据结构的。
数组:批量的同类型数据。
栈:比如程序执行了一半,一个中断进来了,我们要把原来执行了一半的程序存储到栈里。栈最主要的特点就是先进后出。
队列:先入先出。比如批量处理用户的订单。
链表:可以插队,比如有vip用户要先处理,插入队首。并且只要知道链表首地址就知道整个链表所有元素的地址。
树:树的排列一般是由特征的,可以找到相应特征的元素,比如二叉树找最大的。
实战1:Zlog 日志框架
下面做一个简单的项目,一个低配版 Zlog 日志框架。
首先,日志会输出一些信息,这自然不用多说。但是并不是所有情况下我们都希望日志信息输出的,比如发布版和正式版我们不希望用户看到日志信息。
解决方法很简单,之前在 define 部分也有学习到。就是在文件开头定义当前文件所处的模式,下面通过ifdef来判断现在所处的模式,进而决定要不要输出日志文件。
#ifdef OPEN_LOG
printf();
printf();
printf();
#endif
我们可以把这一部分封装到函数里。C 语言有一种变参函数,支持传入不同长度的参数。是 stdarg.h 下的 type va_arg(va_list ap, type) 函数。
菜鸟教程上的实例程序如下:
#include <stdarg.h>
#include <stdio.h>
int sum(int, ...);
int main()
{
printf("15 和 56 的和 = %d\n", sum(2, 15, 56) );
return 0;
}
int sum(int num_args, ...)
{
int val = 0;
va_list ap;
int i;
va_start(ap, num_args);
for(i = 0; i < num_args; i++)
{
val += va_arg(ap, int);//va_arg返回的是不固定的参数部分,固定的部分就是num_args,不用通过这个函数获取了。
}
va_end(ap);
return val;//因此最后获取到的 val 值只是不固定的参数的求和,即15+56
}
传入的参数们 num_args 通过 va_start函数初始化成一个va_list类型的对象 ap,ap 通过va_arg(va_list, 数据类型)遍历。
因此我们可以如法炮制,写一个print_log函数,传入一串不固定长度的要输出的参数。首先要在函数里用ifdef判断一下当前是否是日志模式。
如果是日志模式,则可以继续输出,先利用va_start初始化 va_list 列表,再逐个获取参数并输出。
#include<stdio.h>
#include<stdarg.h>
#define OPEN_LOG 1
void printLog(int num_args,...){//这里的第一个参数也不一定非要是 num_args,这里只是一种用法,方便知道传入了几个参数。
#ifdef OPEN_LOG
va_list ap;
int i=0;
va_start(ap,num_args);
for(;i<num_args;i++){
char * str=va_arg(ap,char *);
printf("\t%s\n",str);
}
va_end(ap);
#endif
}
int main(){
printf("Log:\n");
printLog(3,"123","123","789");
return 0;
}
实际上,我们学习C语言的第一个程序 hello world 里面就有一个变参函数: pintf。其中第一个参数是固定的 char * 字符串,后面的参数都是替换字符串中的类型符的参数。
printf 是直接把内容输出到屏幕,sprintf(char *str, const char * format, ...) 是将 format 字符串输出到 str 字符串中,后面的可变参数是用来替换 format 字符串中的类型符的。而 snprintf(char *str, size_t size, const char *format, ...) 是限定输出最大 size 长度。而 vsnprintf 功能与 snprintf 完全一致,只是把参数列表替换为 va_list 类型。
因此利用这两种函数,我们可以不直接输出日志字符串,而是先将要打印的信息输出到变参函数中,在函数中利用 vsnprintf 将要打印的信息合并成一整个字符串,再进行输出。
#include<stdio.h>
#include<stdarg.h>
#define OPEN_LOG 1
void printLog(char *fmt,...){
#ifdef OPEN_LOG
va_list arg;
va_start(arg,fmt);
char str[1+vsnprintf(NULL,0,fmt,arg)];//通过这条语句获取 fmt 的长度并定义相应长度的字符数组
vsnprintf(str,sizeof(str),fmt,arg);//vsprintf 自然也可以,vsnprintf 保险一些
printf("%s",str);
va_end(arg);
#endif
}
int main(){
printf("Log:\n");
printLog("\t%s\n\t%s\n\t%s\n","123","123","789");
return 0;
}
接下来是限制不同版本的日志输出信息。比如我们设置四种日志输出等级:debug, info, warn. error。我们希望输出等级是层层递增的,比如调试版本四种信息都会输出,正常版本只会输出 info, warn, error 信息,发布版本只会输出 error 信息。用之前 define 章节学到的版本定义非常容易实现。
#define OPEN_LOG 1//设置开启日志
//设置当前日志版本
#define LOG_LEVEL LOG_DEBUG
// #define LOG_LEVEL LOG_INFO
// #define LOG_LEVEL LOG_WARN
// #define LOG_LEVEL LOG_ERROR
typedef enum{
LOG_DEBUG=0,
LOG_INFO,
LOG_WARN,
LOG_ERROR,
}E_LOGLEVEL;//四个值分别是0 1 2 3 4
//printLog 函数中做一些改动。首先开头不只是一个固定参数,而是两个固定参数,第一个是版本号,比如是 LOG_ERROR 就代表这条信息是 ERROR 等级下要输出的。第二个代表 fmt 原字符串。
//然后要 printf 输出之前先判断一下当前版本与要输出的信息的版本。比如当前版本是 INFO 版本,要输出的信息是 LOG_DEBUG 的信息,那么这条信息就不用输出。
void printLog(const int level, const char *fmt,...){
#ifdef OPEN_LOG
va_list arg;
va_start(arg,fmt);
char str[1+vsnprintf(NULL,0,fmt,arg)];
vsnprintf(str,sizeof(str),fmt,arg);
if(level>=LOG_LEVEL)//注意看,这句是关键
printf("%s",str);
va_end(arg);
#endif
}
int main(){
printf("Log:\n");
printLog(LOG_DEBUG,"\t%s VERSION MESSAGE: %s\n","LOG_DEBUG","123");
printLog(LOG_INFO,"\t%s VERSION MESSAGE: %s\n","LOG_INFO","456");
printLog(LOG_WARN,"\t%s VERSION MESSAGE: %s\n","LOG_WARN","789");
printLog(LOG_ERROR,"\t%s VERSION MESSAGE: %s\n","LOG_ERROR","012");
return 0;
}
这样执行输出的会是四条语句。也可以切换当前日志等级。
在调试过程中,输出一些代码相关信息如当前所处函数、当前所处行数等。
void printLog(const int level, const char * function, const int line, const char *fmt,...){
#ifdef OPEN_LOG
va_list arg;
va_start(arg,fmt);
char str[1+vsnprintf(NULL,0,fmt,arg)];
vsnprintf(str,sizeof(str),fmt,arg);
if(level>=LOG_LEVEL)
printf("Function: %s; Line: %d\n%s",function, line, str);
va_end(arg);
#endif
}
#define PRINT_LOG(level, fmt...) printLog(level, __FUNCTION__, __LINE__, fmt)

在整个的 printLog 函数结尾还可以增加一个状态:日志已保存 isSaved,代表整个字符串已经顺利写入 str 缓冲数组中。
最后一步就是把所有的函数声明、define、typedef 提出来放到 .h 文件中,方便管理。
实战2:google 测试框架
随着需求不断变化,版本也会不断更迭,难免会对一些函数做修改。
如果对函数做的操作使得函数违背了最初期望实现的功能呢?应该增加一些限制,比如修改完函数后对函数进行测试。如果结果符合预期,再保留修改。
比如写一个最简单的 sum 函数进行两数求和,我们可以通过测试函数比较输入 a b 后函数的返回值和 a+b 的值是否相等。
#include<stdio.h>
#include<stdlib.h>
typedef struct{
int a;
int b;
int output;
int (*TestEMFunc)(int,int);//这里代表一个有两个 int 参数的 返回值为 int 类型的函数
}GTest;
GTest *addFunc(int (*TestEMFunc)(int,int),int a,int b, int output){//这里传入的 output 是程序员自己给的,期望的结果。
GTest *m_EMTest=(GTest *)malloc(sizeof(GTest));
m_EMTest->a=a;
m_EMTest->b=b;
m_EMTest->TestEMFunc=TestEMFunc;
m_EMTest->output=output;
return m_EMTest;
}
int add(int a, int b){return a+b;}
void runGTest(GTest *gTest){
if(gTest!=NULL){
int temp=gTest->TestEMFunc(gTest->a, gTest->b);//这里 temp 计算得出的结果是函数的返回值。
if(temp==gTest->output)printf("测试成功!\n");
else printf("测试失败!建议重新修改函数\n");
}
}
void main(){
GTest *gTest=addFunc(add, 2, 3, 5);
runGTest(gTest);
return;
}
当然这只是最基础的一个形式。github 上有 google 测试框架,把此例弄懂后去理解 google 测试框架会更加容易。