此时 x 和 y 的真实关系为
y
=
e
(
x
+
1
)
y=e^{(x+1)}
y=e(x+1)
但如果以线性方程来进行预测,即:
y
=
w
T
⋅
x
+
b
y= w^T \cdot x + b
y=wT⋅x+b
当然,我们可以令
w
^
=
[
w
1
,
w
2
,
.
.
.
w
d
,
b
]
T
\hat w = [w_1,w_2,...w_d, b]^T
w^=[w1,w2,...wd,b]T,
x
^
=
[
x
1
,
x
2
,
.
.
.
x
d
,
1
]
T
\hat x = [x_1,x_2,...x_d, 1]^T
x^=[x1,x2,...xd,1]T,从而将上述方程改写为:
y
=
w
^
T
⋅
x
^
y= \hat w^T \cdot \hat x
y=w^T⋅x^
则模型输出结果为:
np.linalg.lstsq(x, y, rcond=-1)[0]#array([[ 30.44214742],# [-22.37576724]])
即
y
=
30.44
x
−
22.38
y=30.44x-22.38
y=30.44x−22.38
而这种连接线性方程左右两端、并且实际上能够拓展模型性能的函数,就被称为联系函数,而加入了联系函数的模型也被称为广义线性模型。广义线性模型的一般形式可表示如下:
g
(
y
)
=
w
^
T
⋅
x
^
g(y)=\hat w^T \cdot \hat x
g(y)=w^T⋅x^
等价于
y
=
g
−
1
(
w
^
T
⋅
x
^
)
y = g^{-1}(\hat w^T \cdot \hat x)
y=g−1(w^T⋅x^)
其中
g
(
⋅
)
g(·)
g(⋅) 为联系函数(link function),
g
−
1
(
⋅
)
g^{-1}(·)
g−1(⋅) 为联系函数的反函数。而如上例中的情况,也就是当联系函数为自然底数的对数函数时,该模型也被称为对数线性模型(logit linear model)。
这里需要注意,一般来说广义线性模型要求联系函数必须是单调可微函数。
从广义线性模型的角度出发,当联系函数为
g
(
x
)
=
x
g(x)=x
g(x)=x 时,
g
(
y
)
=
y
=
w
^
T
⋅
x
^
g(y)=y=\hat w^T \cdot \hat x
g(y)=y=w^T⋅x^,此时就退化成了线性模型。而能够通过联系函数拓展模型捕捉规律的范围,这也就是广义的由来。
二、对数几率模型与逻辑回归
逻辑回归也被称为对数几率回归。接下来,我们从广义线性模型角度理解逻辑回归。
1. 对数几率模型(logit model)
几率(odd)与对数几率
几率不是概率,而是一个事件发生与不发生的概率的比值。
假设某事件发生的概率为 p,则该事件不发生的概率为 1-p,该事件的几率为:
o
d
d
(
p
)
=
p
1
−
p
odd(p)=\frac{p}{1-p}
odd(p)=1−pp
在几率的基础上取(自然底数的)对数,则构成该事件的对数几率(logit):
l
o
g
i
t
(
p
)
=
l
n
p
1
−
p
logit(p) = ln\frac{p}{1-p}
logit(p)=ln1−pp
这里需要注意的是,logit 的是 log unit 对数单元的简写,和中文中的逻辑一词并没有关系。对数几率模型也被称为对数单位模型(log unit model)。
对数几率模型
如果我们将对数几率看成是一个函数,并将其作为联系函数,即
g
(
y
)
=
l
n
y
1
−
y
g(y)=ln\frac{y}{1-y}
g(y)=ln1−yy,则该广义线性模型为:
g
(
y
)
=
l
n
y
1
−
y
=
w
^
T
⋅
x
^
g(y)=ln\frac{y}{1-y}=\hat w^T \cdot \hat x
g(y)=ln1−yy=w^T⋅x^
此时模型就被称为对数几率回归(logistic regression),也被称为逻辑回归。
2. 逻辑回归与 Sigmoid 函数
对数几率函数与 Sigmoid 函数
如果我们希望将上述对数几率函数反解出来,也就是改写为
y
=
f
(
x
)
y=f(x)
y=f(x) 形式,则可参照下述形式:
方程左右两端取自然底数:
y
1
−
y
=
e
w
^
T
⋅
x
^
\frac{y}{1-y}=e^{\hat w^T \cdot \hat x}
1−yy=ew^T⋅x^
方程左右两端 +1 可得:
y
+
(
1
−
y
)
1
−
y
=
1
1
−
y
=
e
w
^
T
⋅
x
^
+
1
\frac{y+(1-y)}{1-y}=\frac{1}{1-y}=e^{\hat w^T \cdot \hat x}+1
1−yy+(1−y)=1−y1=ew^T⋅x^+1
方程左右两端取倒数可得:
1
−
y
=
1
e
w
^
T
⋅
x
^
+
1
1-y=\frac{1}{e^{\hat w^T \cdot \hat x}+1}
1−y=ew^T⋅x^+11
1- 方程左右两端可得:
y
=
1
−
1
e
w
^
T
⋅
x
^
+
1
=
e
w
^
T
⋅
x
^
e
w
^
T
⋅
x
^
+
1
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
=
g
−
1
(
w
^
T
⋅
x
^
)
\begin{aligned} y &= 1-\frac{1}{e^{\hat w^T \cdot \hat x}+1}\\ &=\frac{e^{\hat w^T \cdot \hat x}}{e^{\hat w^T \cdot \hat x}+1} \\ &=\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} = g^{-1}(\hat w^T \cdot \hat x) \end{aligned}
y=1−ew^T⋅x^+11=ew^T⋅x^+1ew^T⋅x^=1+e−(w^T⋅x^)1=g−1(w^T⋅x^)
因此,逻辑回归基本模型方程为:
y
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
y = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}
y=1+e−(w^T⋅x^)1
同时我们也能发现,对数几率函数的反函数为:
f
(
x
)
=
1
1
+
e
−
x
f(x) = \frac{1}{1+e^{-x}}
f(x)=1+e−x1
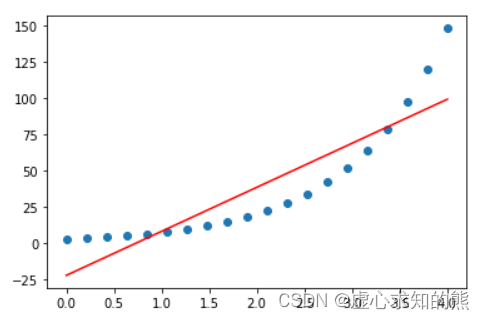
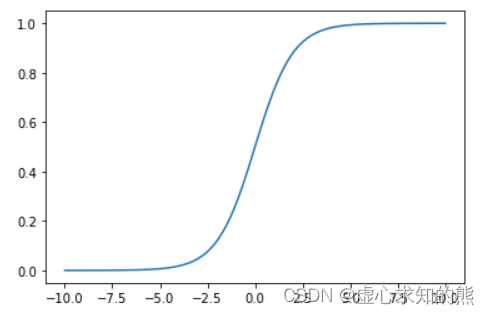
我们可以简单观察该函数的函数图像:
np.random.seed(24)
x = np.linspace(-10,10,100)
y =1/(1+ np.exp(-x))
plt.plot(x, y)
能够看出该函数的图像近似 S 形,这种类似 S 形的函数,也被称为 Sigmoid 函数。
注:Sigmoid 严格定义是指形如 S 型的函数,并不是特指某个函数。
也就是说,从严格意义来讨论,函数
f
(
x
)
=
1
1
+
e
−
x
f(x) = \frac{1}{1+e^{-x}}
f(x)=1+e−x1 只能被称为是 Sigmoid 函数的一种。但实际上,由于该函数是最著名且通用的 Sigmoid 函数,因此大多数时候,我们在说Sigmoid函数的时候,其实就是在指
f
(
x
)
=
1
1
+
e
−
x
f(x) = \frac{1}{1+e^{-x}}
f(x)=1+e−x1 函数。
令:
S
i
g
m
o
i
d
(
x
)
=
1
1
+
e
−
x
Sigmoid(x) = \frac{1}{1+e^{-x}}
Sigmoid(x)=1+e−x1
对其求导可得:
S
i
g
m
o
i
d
′
(
x
)
=
(
1
1
+
e
−
x
)
′
=
(
(
1
+
e
−
x
)
−
1
)
′
=
(
−
1
)
(
1
+
e
−
x
)
−
2
⋅
(
e
−
x
)
′
=
(
1
+
e
−
x
)
−
2
(
e
−
x
)
=
e
−
x
(
1
+
e
−
x
)
2
=
e
−
x
+
1
−
1
(
1
+
e
−
x
)
2
=
1
1
+
e
−
x
−
1
(
1
+
e
−
x
)
2
=
1
1
+
e
−
x
(
1
−
1
1
+
e
−
x
)
=
S
i
g
m
o
i
d
(
x
)
(
1
−
S
i
g
m
o
i
d
(
x
)
)
\begin{aligned} Sigmoid'(x) &= (\frac{1}{1+e^{-x}})' \\ &=((1+e^{-x})^{-1})' \\ &=(-1)(1+e^{-x})^{-2} \cdot (e^{-x})' \\ &=(1+e^{-x})^{-2}(e^{-x}) \\ &=\frac{e^{-x}}{(1+e^{-x})^{2}} \\ &=\frac{e^{-x}+1-1}{(1+e^{-x})^{2}} \\ &=\frac{1}{1+e^{-x}} - \frac{1}{(1+e^{-x})^2} \\ &=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}}) \\ &=Sigmoid(x)(1-Sigmoid(x)) \end{aligned}
Sigmoid′(x)=(1+e−x1)′=((1+e−x)−1)′=(−1)(1+e−x)−2⋅(e−x)′=(1+e−x)−2(e−x)=(1+e−x)2e−x=(1+e−x)2e−x+1−1=1+e−x1−(1+e−x)21=1+e−x1(1−1+e−x1)=Sigmoid(x)(1−Sigmoid(x))
如果我们将逻辑回归模型输出结果视作样本属于1类的概率,则可将逻辑回归模型改写成如下形式:
p
(
y
=
1
∣
x
^
;
w
^
)
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
p(y=1|\hat x;\hat w) =\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}
p(y=1∣x^;w^)=1+e−(w^T⋅x^)1
p
(
y
=
0
∣
x
^
;
w
^
)
=
e
−
(
w
^
T
⋅
x
^
)
1
+
e
−
(
w
^
T
⋅
x
^
)
p(y=0|\hat x;\hat w) =\frac{e^{-(\hat w^T \cdot \hat x)}}{1+e^{-(\hat w^T \cdot \hat x)}}
p(y=0∣x^;w^)=1+e−(w^T⋅x^)e−(w^T⋅x^)
当然,距离计算有很多种方法,此处简单进行介绍,假设 x 和 y 是两组 n 维数据如下所示:
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x=(x_1, x_2, ..., x_n)
x=(x1,x2,...,xn)
y
=
(
y
1
,
y
2
,
.
.
.
,
y
n
)
y=(y_1,y_2,...,y_n)
y=(y1,y2,...,yn)
欧式距离计算公式如下:
d
(
x
,
y
)
=
∑
i
=
1
n
(
x
i
−
y
i
)
2
d(x, y) = \sqrt{\sum_{i = 1}^{n}(x_i-y_i)^2}
d(x,y)=i=1∑n(xi−yi)2
即对应位置元素依次相减后取其平方和再开平方。
街道距离计算公式如下:
d
(
x
,
y
)
=
∑
i
=
1
n
(
∣
x
i
−
y
i
∣
)
d(x, y) =\sum_{i = 1}^{n}(|x_i-y_i|)
d(x,y)=i=1∑n(∣xi−yi∣)
即对应位置元素依次相减后取其绝对值的和。
闵可夫斯基距离计算公式如下:
d
(
x
,
y
)
=
∑
i
=
1
n
(
∣
x
i
−
y
i
∣
)
n
n
d(x, y) = \sqrt[n]{\sum_{i = 1}^{n}(|x_i-y_i|)^n}
d(x,y)=ni=1∑n(∣xi−yi∣)n
目录一、初始化文档数据二、范围查询文档2.1、概述2.2、示例一、初始化文档数据 在 Postman 中,向 ES 服务器发 POST 请求 :http://localhost:9200/user/_doc/1,请求体内容为: {"name":"张三","age"…













![[QMT]03-让QMT支持从Tushare获取数据](https://img-blog.csdnimg.cn/img_convert/488eb5c3bb0755391c57635255de443d.png)