文章目录
- 1.数据仓库概述
- 1.1 数据仓库概念
- 1.2 数据仓库核心架构
- 2.数据仓库建模概述
- 2.1 数据仓库建模的意义
- 2.2 数据仓库建模方法论
- 2.2.1 ER模型
- 2.2.2 维度模型
- 3.维度建模理论之事实表
- 3.1 事实表概述
- 3.2 事实表分类
- 3.3 事务事实表
- 4.维度建模理论之维度表
- 5.数据仓库设计
- 5.1 数据仓库分层设计
- 5.2 数据仓库构建流程
- 5.2.1 数据调研
- 5.2.2 明确数据域
- 5.2.3 构建业务总线矩阵
- 5.2.4 明确统计指标
- 5.2.5 维度模型设计
- 5.2.6 汇总模型设计
1.数据仓库概述
1.1 数据仓库概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。
1.2 数据仓库核心架构
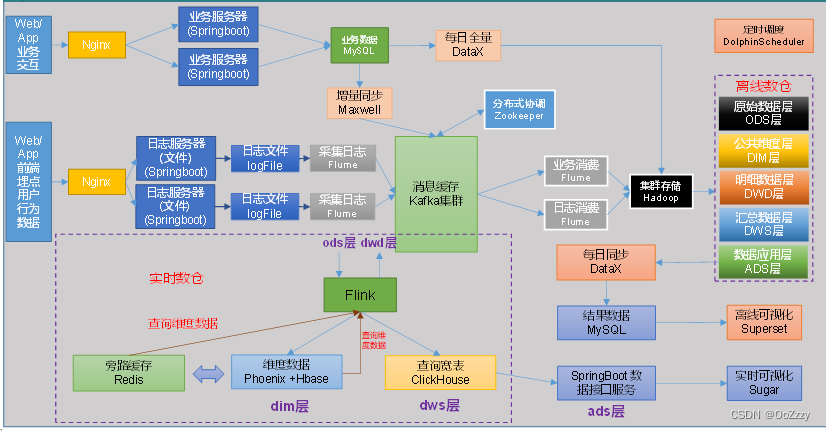
2.数据仓库建模概述
2.1 数据仓库建模的意义
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
- 高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
- 低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
- 高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
- 高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性。
2.2 数据仓库建模方法论
2.2.1 ER模型
实体关系(Entity Relationship,ER)模型来描述企业业务, 范式理论上符合3NF。
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
2.2.2 维度模型
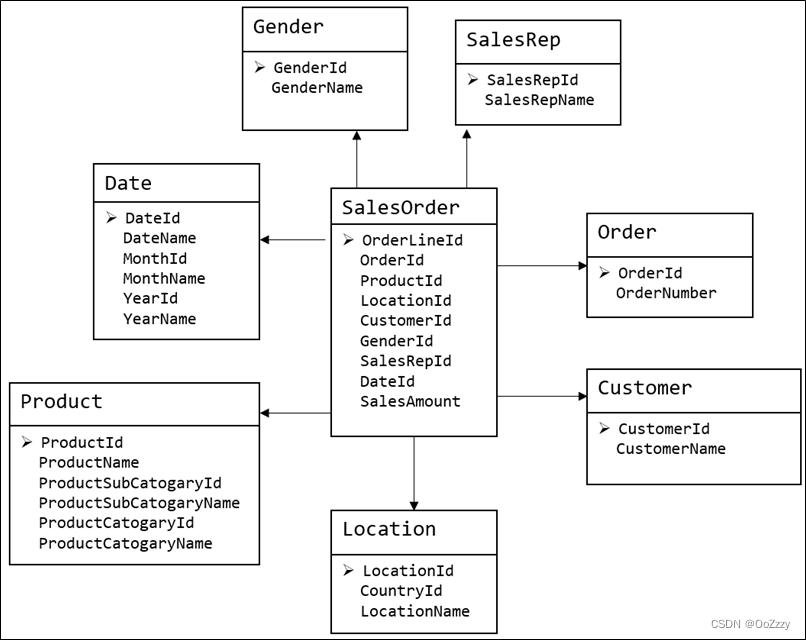
其中位于中心的SalesOrder为事实表, 保存的是下单这个业务过程的所有记录。周围的是维度表, Date(日期), Customer(顾客), Product(产品), Location(地区), 维度表组成了每个订单发生的所处环境, 即何人何时何地。
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能。
3.维度建模理论之事实表
3.1 事实表概述
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
3.2 事实表分类
事务事实表、周期快照事实表和累积快照事实表
3.3 事务事实表
事务事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。
事务型事实表可用于分析与各业务过程相关的各项统计指标,由于其保存了最细粒度的记录,可以提供最大限度的灵活性,可以支持无法预期的各种细节层次的统计需求。
选择业务过程→声明粒度→确认维度→确认事实
次数、个数、件数、金额等
4.维度建模理论之维度表
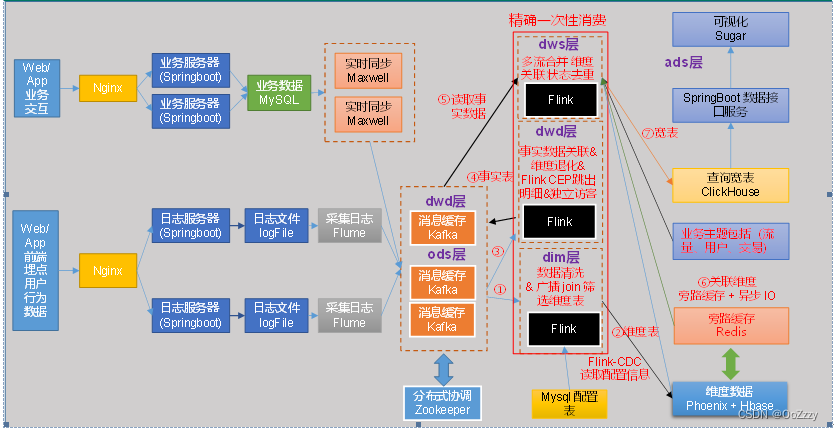
电商离线数仓中,普通维度表是通过主维表和相关维表做关联查询生成的。与之对应的业务数表数据是通过每日一次全量同步导入到 HDFS 的,只须每日做一次全量数据的关联查询即可。而实时数仓中,系统上线后我们采集的是所有表的变化数据,这样就会导致一旦主维表或相关维表中的某张表数据发生了变化,就需要和其它表的历史数据做关联。
此时我们会面临一个问题:如何获取历史数据
对于这个问题,一种思路是在某张与维度表相关的业务表数据发生变化时,执行一次 maxwell-bootstrap 命令,将相关业务表的数据导入 Kafka。但是这样做又会面临三个问题:a)Kafka 中存储冗余数据;b)maxwell-bootstrap 命令交给谁去执行?必然会面临谁去调度的问题;c)实时数仓中的数据是以流的形式存在的,如果不同流中数据进入程序的机器时间差异过大就会出现 join 不上的情况。如何保证导入的历史数据和变化数据可以关联上?势必要尽可能及时地执行历史数据导入命令且在 Flink 程序中设置足够的延迟。而前者难以保证,后者又会影响整个实时数仓的时效性。
基于上述分析,对业务表做 join 形成维度表的方式并不适用于实时数仓。
因此,在实时数仓中,我们不再对业务数据库中的维度表进行合并,仅对一些不需要的字段进行过滤,然后将维度数据写入 HBase 的维度表中,业务数据库的维度表和 HBase 的维度表是一一对应的。
写入维度数据使用 HBase 的 Phoenix 客户端提供的 upsert 语法,实现幂等写入。当维度数据发生变化时,程序会用变化后的新数据覆盖 Phoenix 维表中相同主键的旧数据。从而保证 Phoenix 表中保存的是一份全量最新的维度数据。
这样做会产生一个问题:实时数仓没有保存历史维度数据,与数仓特征(保存历史数据)相悖。那么,维度表可以按照上述思路设计吗
首先,我们要明确:数仓之所以要保存历史数据,是为了运用历史数据做一些相关指标的计算,而实时数仓本就是对最新的业务数据做分析计算,不涉及历史数据,因此无须保存历史数据。
此外,生产环境中实时数仓的上线通常不会早于离线数仓,如果有涉及到历史数据的指标,在离线数仓中计算即可。因此,实时数仓中只需要保留一份最新的维度数据,上述方案是切实可行的。
特别地,对于字典表,我们至多只会用到 dic_code,dic_name 和 parent_code 三个字段,建立单独的维度表意义不大,选择将维度字段退化到事实表中。
5.数据仓库设计
5.1 数据仓库分层设计

- ODS:原始数据层
- DWD:明细数据层
- DWS:汇总数据层
- DIM:公共维度层
- ADS:数据应用层
5.2 数据仓库构建流程
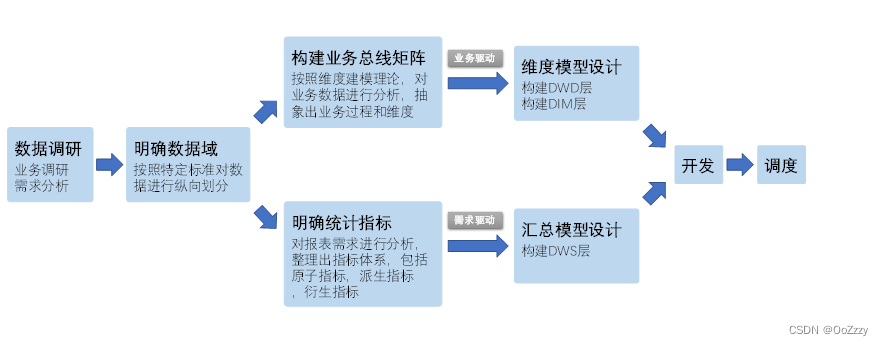
- 数据调研
- 明细数据域
- 构建业务总线矩阵
- 明确统计指标
- 维度模型设计
- 汇总模型设计
5.2.1 数据调研
业务调研和需求分析
业务调研的主要目标是熟悉业务流程、熟悉业务数据。
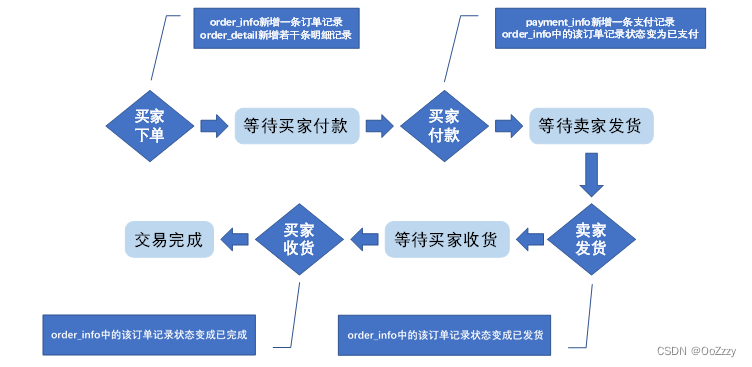
交易业务流程:
需求分析:
典型的需求指标如,最近一天各省份手机品类订单总额。
分析需求时,需要明确需求所需的业务过程及维度,例如该需求所需的业务过程就是买家下单,所需的维度有日期,省份,商品品类。
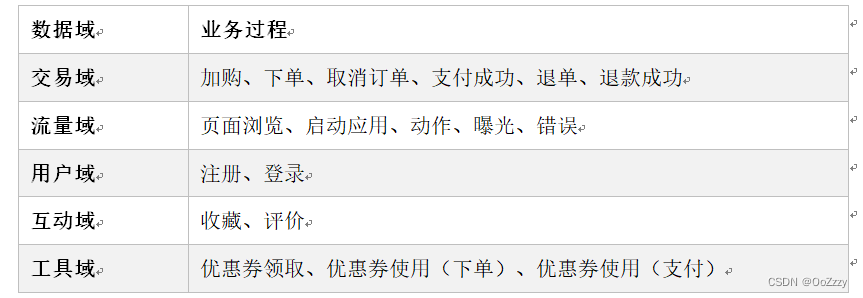
5.2.2 明确数据域
便于数据的管理和应用。
5.2.3 构建业务总线矩阵
矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。
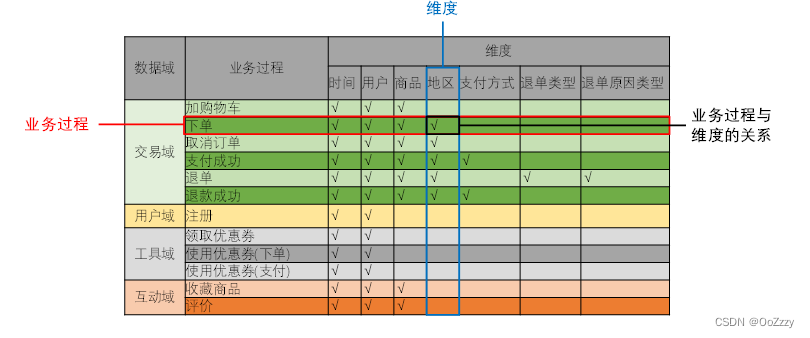
一个业务过程对应维度模型中一张事务型事实表,一个维度则对应维度模型中的一张维度表。所以构建业务总线矩阵的过程就是设计维度模型的过程。但是需要注意的是,总线矩阵中通常只包含事务型事实表,另外两种类型的事实表需单独设计。
选择业务过程 -> 声明粒度 -> 确认维度 -> 确认事实
5.2.4 明确统计指标
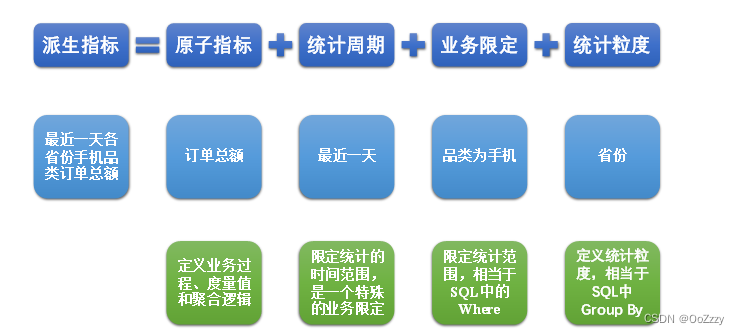
原子指标, 派生指标, 衍生指标
(1) 原子指标
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行了定义。我们可以得出结论,原子指标包含三要素,分别是业务过程、度量值和聚合逻辑。
例如订单总额就是一个典型的原子指标,其中的业务过程为用户下单、度量值为订单金额,聚合逻辑为sum()求和。需要注意的是原子指标只是用来辅助定义指标一个概念,通常不会对应有实际统计需求与之对应。
(2) 派生指标
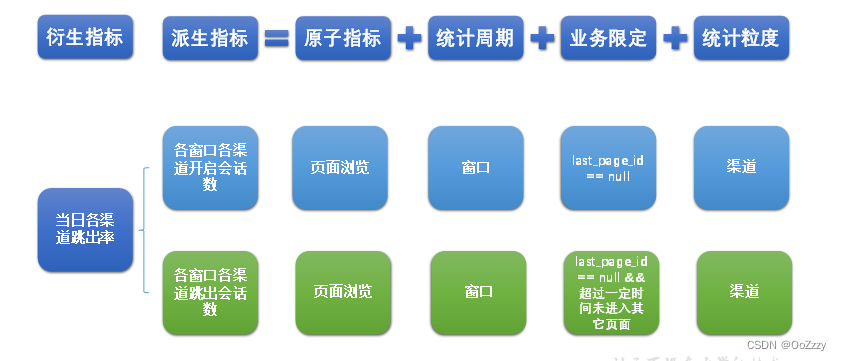
(3) 衍生指标
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的。例如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。
5.2.5 维度模型设计
维度模型的设计参照上述得到的业务总线矩阵即可。事实表存储在DWD层,维度表存储在DIM层。
5.2.6 汇总模型设计
汇总模型的设计参考上述整理出的指标体系(主要是派生指标)即可。汇总表与派生指标的对应关系是,一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标。
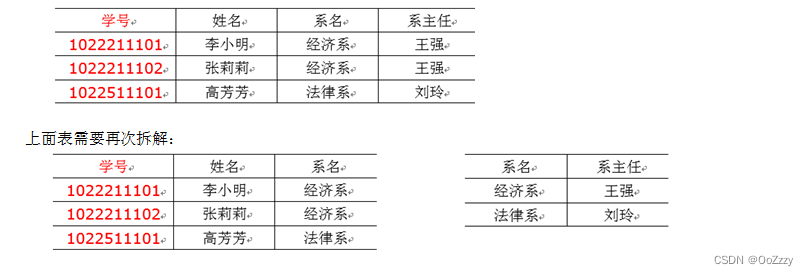
![[前端笔记——HTML 表格] 8.HTML 表格](https://img-blog.csdnimg.cn/b330ff0e83c5413ea1d75617b889ed2e.png)