深度卷积对抗神经网络 基础 第二部分 DC-GANs
DC-GANs (DC-GANs Deep convolutional GAN)是基于GANs的一种专门对图片生成的一种模型,其通过卷积操作来进行图片的一些基本操作来实现模型的功能。
激活函数 Activations
激活函数是任何输入的输出是一个区间内的函数。其必须是可导,并且是非线性的。
一些通用的激活函数包括:(Common activation functions)
-
线性整流函数 (ReLU): 负无穷的时候其值都为0 Rectified Linear Unit dying problem wiht 0 derivative
-
Leaky ReLU: 负无穷的时候,其值不断减小而不是0,其解决了训练饱和问题 X<0 a slope saturation problems
-
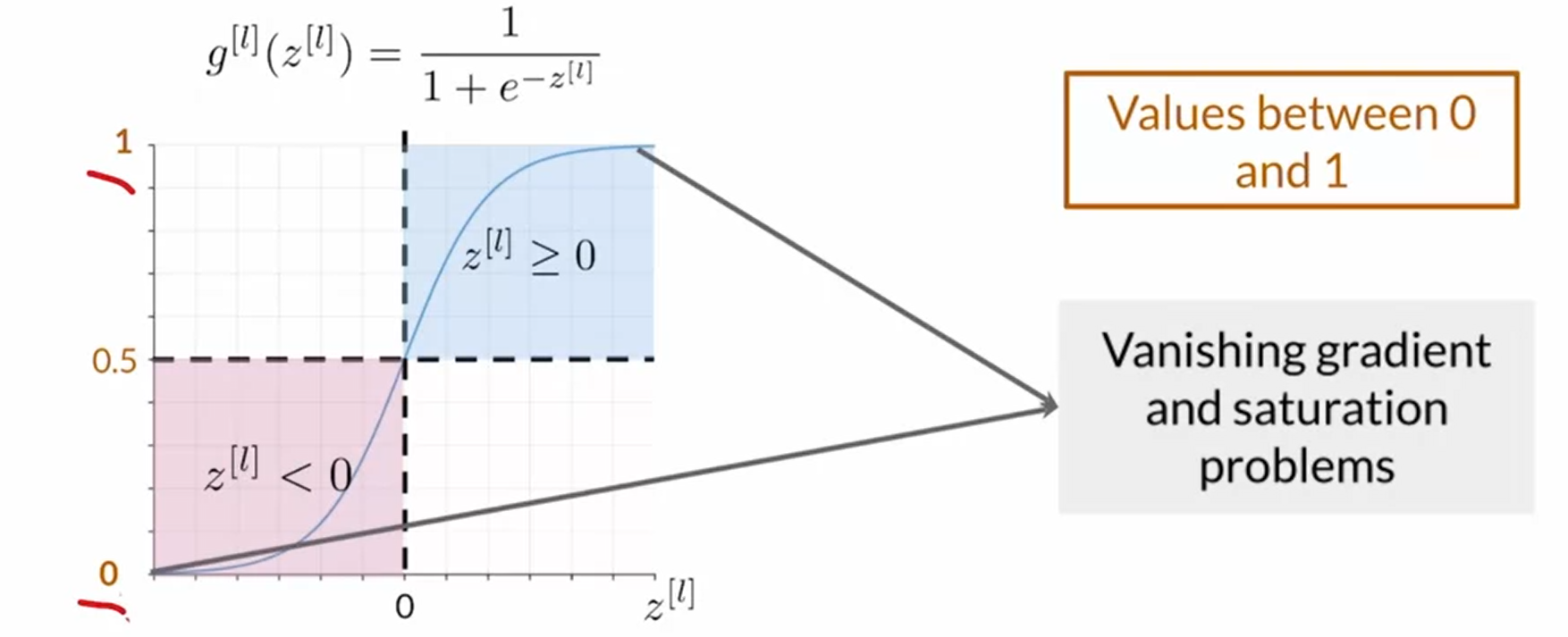
Sigmoid: $ \frac{1}{1+e^{-z}} $ 在classification中用于最后的计算概率,但是在hidden layer中不能使用他,是因为函数在正无穷或者负无穷会产生导数为零的点,这样也就造成了学习停止的问题。 Vanishing gradient and saturation problems
-
Tanh: 双曲正弦 hyperbolic tangent or tanh for short t a n h ( z ) tanh(z) tanh(z)
- 优点是保持了输出的正负号,其有时很重要。Keep the sign of input which is important in some application
- 会出现之前的梯度崩溃以及饱和的问题Same issues as sigmoid vanishing gradient and saturation problems

批标准化 Batch normalization - Using batch statistics
定义
批标准化(Batch Normalization )简称BN算法,是为了克服神经网络层数加深导致难以训练而诞生的一个算法。根据ICS理论,当训练集的样本数据和目标样本集分布不一致的时候,训练得到的模型无法很好的泛化。
而在神经网络中,每一层的输入在经过层内操作之后必然会导致与原来对应的输入信号分布不同,并且前层神经网络的增加会被后面的神经网络不断的累积放大。这个问题的一个解决思路就是根据训练样本与目标样本的比例对训练样本进行一个矫正,而BN算法(批标准化)则可以用来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差 。
当出现数据集的不同特征分布不同的情况时,那么cost function的最优解以及分布也会相应地移动,正如下图所示。这样会影响训练的整体有效性以及降低训练速度,因此通过batch normalization来解决这个问题。
优点
其优点包含如下:
- 稳定化模型并减少内部自己的本征移动,导致学习不准确。Stablize the model and reduce the internal covariate shift
- 可以平滑损失函数。 Smooths the cost function
- 加速学习速度。 Speed up learning
- 减少了参数的人为选择,可以取消dropout和L2正则项参数,或者采取更小的L2正则项约束参数。
- 减少了对学习率的要求。
- 可以不再使用局部响应归一化了,BN本身就是归一化网络。
- 更破坏原来的数据分布,一定程度上缓解过拟合(over-fitting)。

使用方法
使用方法便是一般用在非线性映射(激活函数)之前,对y= Wx + b进行规范化,是结果(输出信号的各个维度)的均值都为0,方差为1,让每一层的输入有一个稳定的分布会有利于网络的训练。 在神经网络收敛过慢或者梯度爆炸时的那个无法训练的情况下都可以尝试。
批标准化在训练好测试中的区别 (How they differ during training versus testing)
- 在这个训练过程中,每次的测试数据都会求 z ^ \hat{z} z^, 然后通过调整 γ \gamma γ和 β \beta β来调整实际分布。(mean and standard deviation of every batch)

- 而在测试的过程中,我们的均值和方差是确定的,我们取测试集整体的值。(running mean and standard deviation over the entire training)

个人的理解在于,由于每一个batch,也就是训练集所分出的每一个包,无论是如何分出的这个包(随机地或者是顺序的),那么每个包都会存在一个本征的分布,其并不是所研究对象的真实分布。比如说实际情况下,实际的美国人口分布中,白:黑:黄的比例是7:2:1,但是我们取出一个某个州的人口样本,他们的比例是白:黑:黄为 3:3:4,那么显然当神经网络模型想要才出实际的美国人口分布便会比较困难,也就是你的先验概率教不准确。这样,当将数据正交化后,其比例没有变化,我们还会有3:3:4的样本数据,但是当经过一层神经网络的计算之后,提取出部分有效信息,将其正交化为分布为N(0,1)的正态分布,使得每一层的输入都会有一个稳定的分布,这样会更有利于训练。
卷积计算的应用 Convolution
一些参数定义 Parameters
卷积通过一些卷积矩阵的运算来实现图像的各种处理。
- Stride: 扫描步长
- Padding: 填充边缘长度 , 保证每个数据可以等次地扫描到
- pooling: 池化,模糊化, 没有任何需要学习的参数
- max pooling: 最大化
- average pooling
- min pooling
- up-sampling; 超采样
- Nearest neighbor up-sampling
- linear and bi-linera interpolation
(反卷积,去卷积) Transposed convolutions or deconvolution
通过可学习的filter对输入图像进行操作来得到想要的更大的图片的过程叫做去卷积
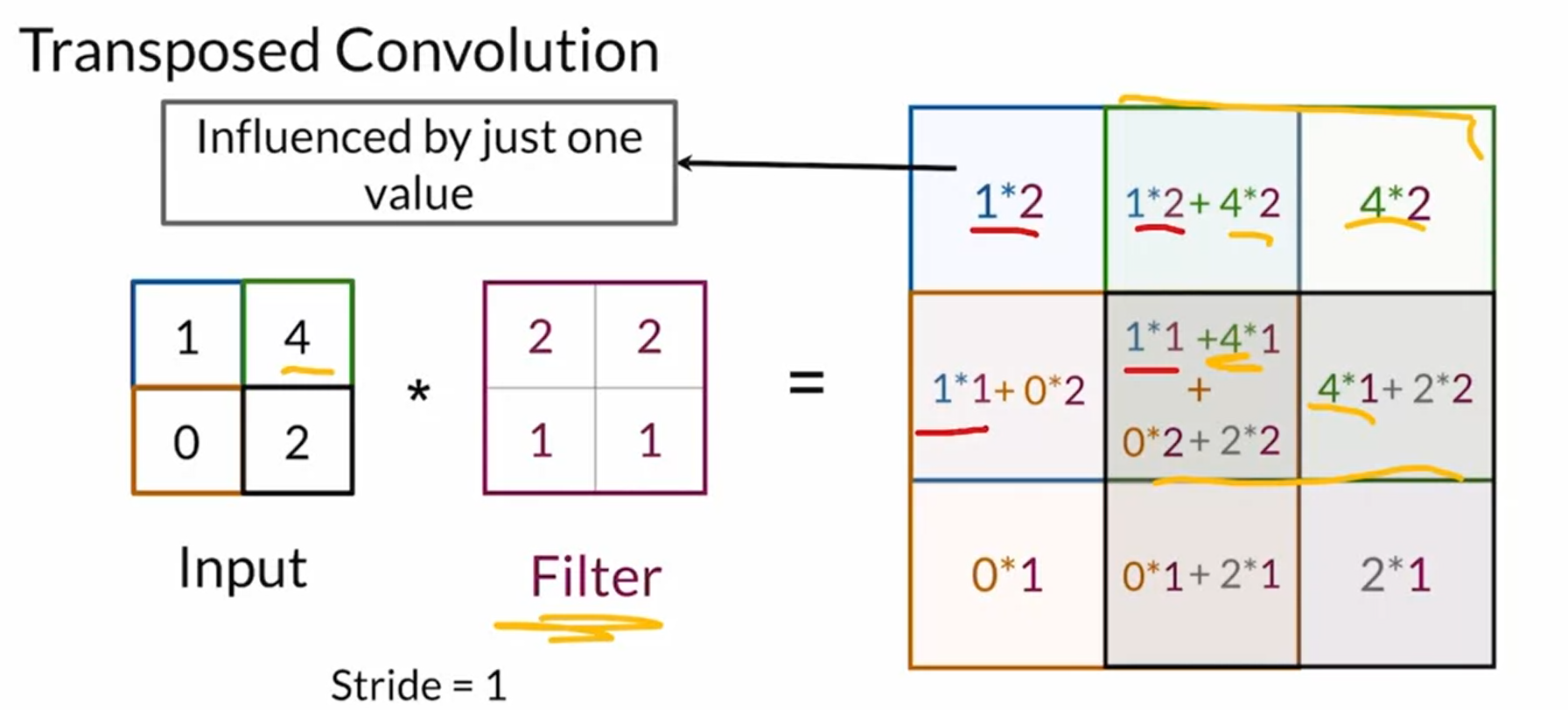
这会导致chekerboard问题,但是其filter是可以学习的。
pytroch 问题记录
当BatchNorm2d 加入affine==false之后,那么会出现 torch.nn.init 之后并没有实例化的情况,在此记录,之后会再次研究这个函数的作用。