文章目录
前言
目标检测论文中出现过很多容易混淆的评价指标,比如FLOPS、FLOPs、 GFLOPS,包括最基本的AP、mAP这些定义,索性将这些基本概念搞清楚,做个总结。
一、AP(Average Precision)
1.1 TP(True Positive)、FP(False Positive)、FN(False Negative)
TP:与真实目标框GT(Ground Truth)的 IoU大于指定阈值(比如0.5)的预测框(一个GT只计算一个TP)
FP:与真实目标框GT(Ground Truth)的 IoU小于等于指定阈值(比如0.5)的预测框(多余的TP也被认为是FP)
FN: 没有TP的真实目标框GT(Ground Truth)
一个GT只会计算一个TP,一个GT即使有5个IoU大于0.5的预测框,TP也只能等于1,剩下的4个都被认为是FP。按置信度排序选最大的作为TP

举个例子,以单张图片为例(目标检测任务中是所有的验证集图片),计算人这一类别的TP、FP、FN。首先,TP、FP、FN都是针对某一个类别来说(AP的计算也是如此),比如上图中车这个目标也是我们要检测出来的,所以车也可以计算TP、FP、FN。
将类别为人的预测框全部筛选出来(绿框表示),红色的为GT。预测框1与GT1的IoU大于0.5,故预测框1属于TP;预测框2与GT1的IoU小于0.5,故预测框2属于FP;预测框3与GT1的IoU大于0.5但已经有一个TP了,故预测框3属于FP;GT2没有TP,故属于FN。
故TP=1,FP=2,FN=1。
1.2 Precision(查准率)、Recall(召回率/查全率)
Precision= TP / (TP + FP)
Recall=TP / (TP + FN)
| - | 预测为正类 | 预测为负类 |
|---|---|---|
| 正类 | TP | FN |
| 负类 | FP | TN |
(TP + FP)就是所有生成的预测框数量,(TP + FN)在目标检测中就是GT的数量(因为一个GT只计算一个TP)。所以可以通俗的理解: Precision就是衡量误检程度,Recall是衡量漏检程度。
你可以让模型尽可能多地生成预测框,可以提高Recall。因为Recall只和GT和TP的数量有关。多生成预测框我每个GT都有一个TP的机会也更大,极端一点整张图片生成100000个预测框,保证每个GT都有一个TP,此时Recall为1,我的Recall仍然可以很大。
你可以让模型尽可能少地生成预测框,可以提高Precision。因为Precision只和 (TP + FP)就是所有生成的预测框数量有关。比如我只有一个TP,但是我总共只预测了2个框,我的Precision是0.5;如果我总共预测了4个框,我的Precision是0.25。
所以单一用Precision或者Recall是没有意义的,并不能实际反映出模型检测效果的好坏。
1.3 PR曲线
单一用Precision或者Recall是没有意义的,所以要综合考虑两者,也就是PR曲线:纵轴是Precision,横轴是Recall。用PR曲线下方的面积来衡量检测效果,也就是AP(Average Precision)。
AP是衡量单个类别检测效果的指标

以上图为例增加一个预测框,计算Precision和Recall,每预测一个框都会改变两者的值。
大概步骤如下:
节选自:知乎
我会依次遍历每个类别,在同一个类别下,按照置信度分数给你的pred_bbox从大到小排序,然后用一个匹配规则去确定你的pred_bbox中哪些是TP,哪些是FP,以及我的gt_bbox中哪些是FN。
为什么要按置信度排序?因为这样绘制出来的precision-recall曲线下的面积比按你直接给我的pred_bbox的顺序要大。毕竟我和你的目标是一样,你希望你的得分越高,我也希望你的得分越高,所以我就这样做了。
按照1步骤,我就可以逐个bbox计算出precision和recall,进而绘制出precision-recall曲线。
举个简单的例子,假设一共5个pred_bbox和4个gt_bbox,经过步骤1,5个pred_bbox被判定为「TP,TP,FP,TP,FP」,那么逐个bbox计算出的precision=「1/1,2/2,2/3,3/4,3/5」,recall=「1/4,2/4,2/4,3/4,3/4」。Precision和Recall组成坐标,得到逐个bbox的precision-recall曲线,我就可以计算这个曲线下的面积了,得到ap了。
| - | 置信度 | TP or FP | Precision | Recall |
|---|---|---|---|---|
| 预测框1 | 0.9 | TP | 1 | 0.5 |
| 预测框4 | 0.8 | TP | 1 | 1 |
| 预测框3 | 0.7 | FP | 0.66 | 1 |
| 预测框2 | 0.6 | FP | 0.5 | 1 |
可以看出随着预测框数量的增加,Precision是减少的,Recall是增加的。
但是PR曲线下面积的计算方式还有很多种做法(VOC和COCO数据集计算方法不一样),有插值、平滑,可以自行参考知乎问答:知乎问答
1.4 mAP(mean Average Precision)
PR曲线下方的面积就是AP(Average Precision),mAP就是所有类别的AP取平均就是mAP。比如Person的AP是0.6,Car的AP是0.8,那mAP就是(0.6+0.8)/2=0.7
AP是衡量单个类别检测效果的指标,mAP是衡量所有类别检测效果的指标
注:在COCO数据集中的AP就相当于mAP,COCO计算的AP就是所有类别的。
AP(mAP):COCO的AP是将以IoU阈值(即判断为TP的阈值)为0.5开始,以0.05递增到0.95,也就是以(0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95)为阈值共10个mAP取均值计算得来的。阈值越高,对模型精度要求也越高。
AP50:以IoU阈值为0.5判定为TP下的AP
AP75:以IoU阈值为0.75判定为TP下的AP
APs:小物体的AP
APm:中物体的AP
APL:大物体的AP
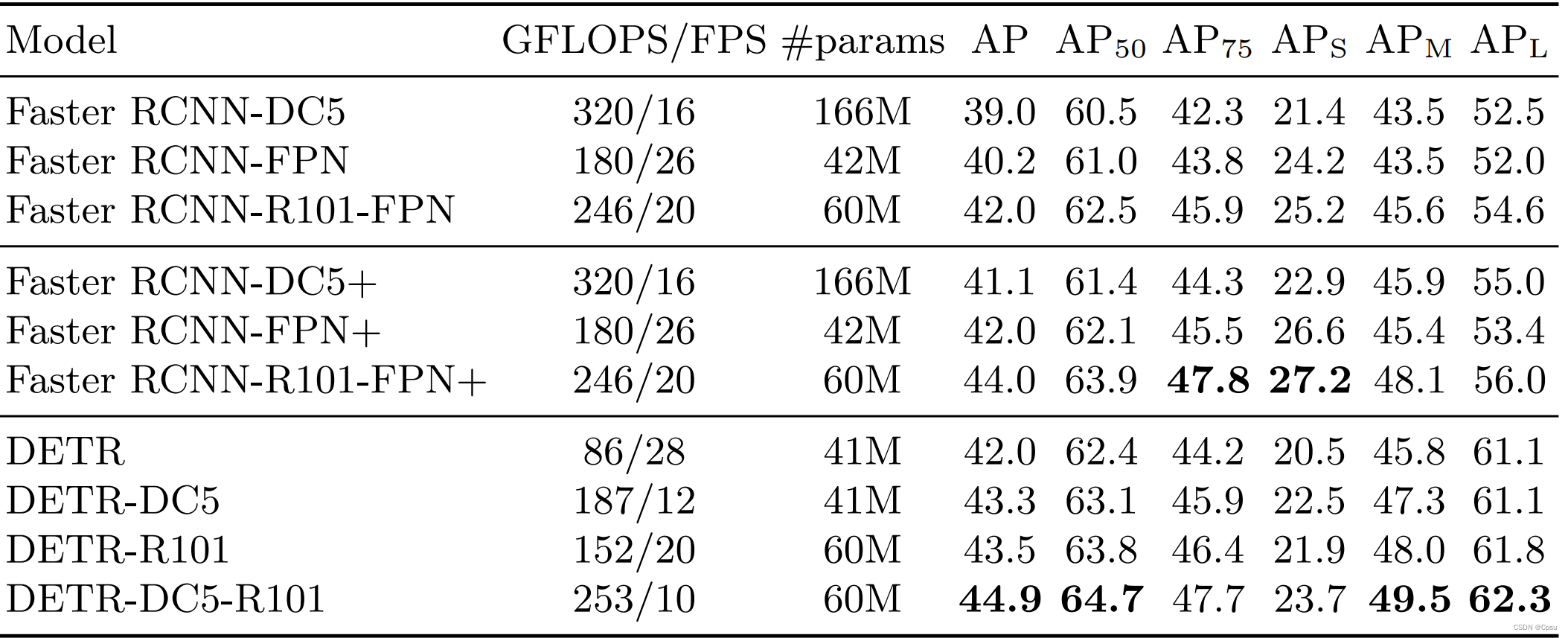
二、FLOPs、FLOPS
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
但是目前计算FLOPs还没有统一的标准,在torch中可以利用torchstat来计算复杂度。
安装使用参考github:torchstat
三、FPS
FPS就是目标网络每秒可以处理(检测)多少帧(多少张图片),FPS简单来理解就是图像的刷新频率,也就是每秒多少帧。假设目标检测网络处理1帧(一张图片)要0.02s,此时FPS就是1/0.02=50。以基础的DETR模型为例,FPS为28,那么处理一张图片要1/28s。
四、MACs
MACs(Multiply–Accumulate Operations):乘加累积操作数,常常被人们与FLOPs概念混淆实际上1MACs包含一个乘法操作与一个加法操作,大约包含2FLOPs。通常MACs与FLOPs存在一个2倍的关系。








![[hive]数仓分层|用户纬度拉链表|维度建模](https://img-blog.csdnimg.cn/img_convert/345dab024c1e40b496530982354a0b51.png)