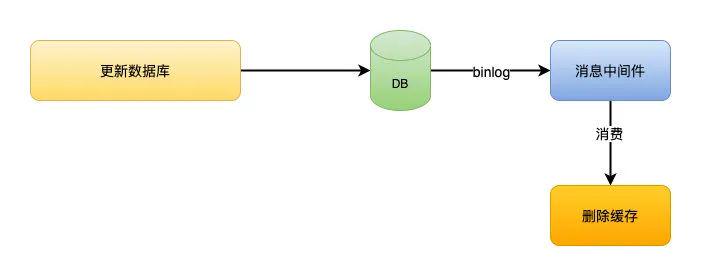
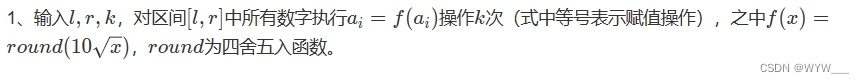Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition
- 1. Introduction
- 2. Related Work
- Residual Representations(剩余表示).
- Shortcut Connections(快捷连接).
- 3. Deep Residual Learning
- 3.1. Residual Learning
- 3.2. Identity Mapping by Shortcuts
- 3.3. Network Architectures
- Plain Network.
- image-20230119165226891Residual Network.
- 4. conclusion
Deep Residual Learning for Image Recognition
1. Introduction
- 本文提出了一个残差学习框架,以简化比以前使用的网络更深入的网络的训练 。在ImageNet数据集上,评估了深度为152层的残差网–比VGG网咯深8倍,但仍然具有较低的复杂度。
图一:在CIFAR-10数据集上使用20层和56层“普通”网络的训练错误(左)和测试错误(右)。
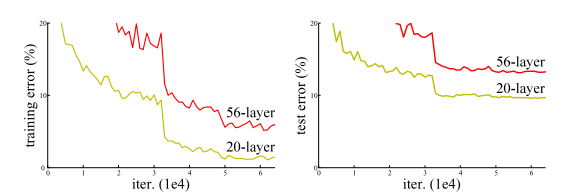
较深的网络具有较高的训练误差,从而产生较大的测试误差。 在图的ImageNet数据集上也出现了类似的现象 ,如下图所示:
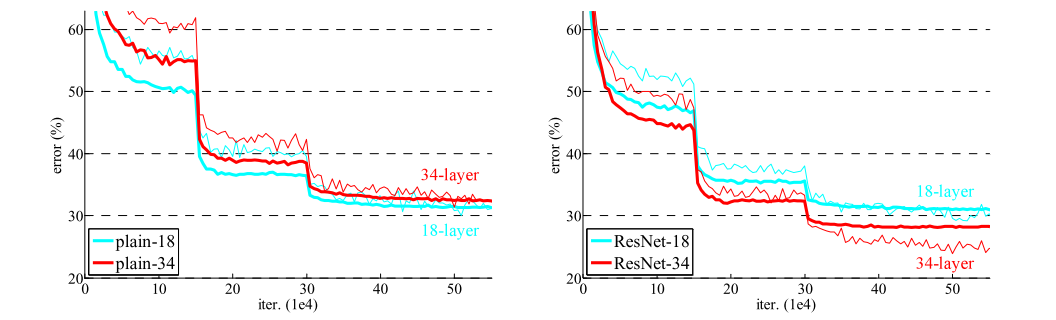
图四:
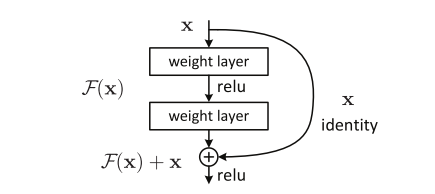
F(x)+x的公式可由“捷径连接”的前馈神经网络实现:
图二:剩余学习:一个构建块:
2. Related Work
请自行了解,本篇不过多赘述
Residual Representations(剩余表示).
Shortcut Connections(快捷连接).
3. Deep Residual Learning
3.1. Residual Learning
- 让我们把H(x)看作是一个底层映射,它需要由几个堆叠的层(不一定是整个网络)来拟合,其中x表示这些层中第一层的输入。如果假设多个非线性层可以渐近地逼近复杂函数,那么这就相当于假设它们可以渐近地逼近残差函数,即:H(x)− x(假设输入和输出的维数相同)。因此,我们不期望叠层近似H(x),而是显式地让这些叠层近似残差函数F(x):= H(x)− x。因此,原函数变为F(x)+x。虽然两种形式都应该能够渐近地逼近期望的函数(如假设的那样),但学习的容易程度可能不同。
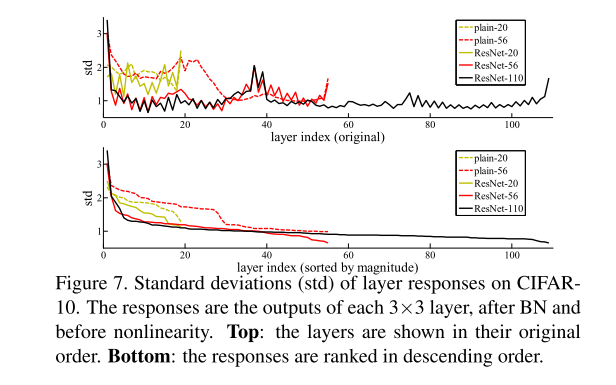
- 在真实的情况下,恒等映射不太可能是最优的,但是我们的重新表述可以帮助预处理这个问题。如果最优函数更接近恒等映射而不是零映射,那么求解器应该更容易根据恒等映射找到扰动,而不是将函数作为新函数来学习。我们通过实验(图7)表明,学习的残差函数通常具有较小的响应,这表明恒等映射提供了合理的预处理。
3.2. Identity Mapping by Shortcuts
我们对每几个堆叠的层采用剩余学习。构建块如图2所示。形式上,在本文中,我们考虑的构建块定义为:
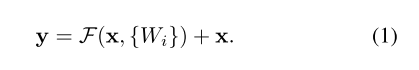
这里x和y是所考虑的层的输入和输出向量。函数F(x,{Wi})表示要学习的残差映射。对于图2中具有两层的示例,F = W2σ(W1 x),其中σ表示ReLU。运算F + x是通过一个快捷连接和逐元素加法来执行的。
3.3. Network Architectures
我们描述ImageNet的两个模型如下。
Plain Network.
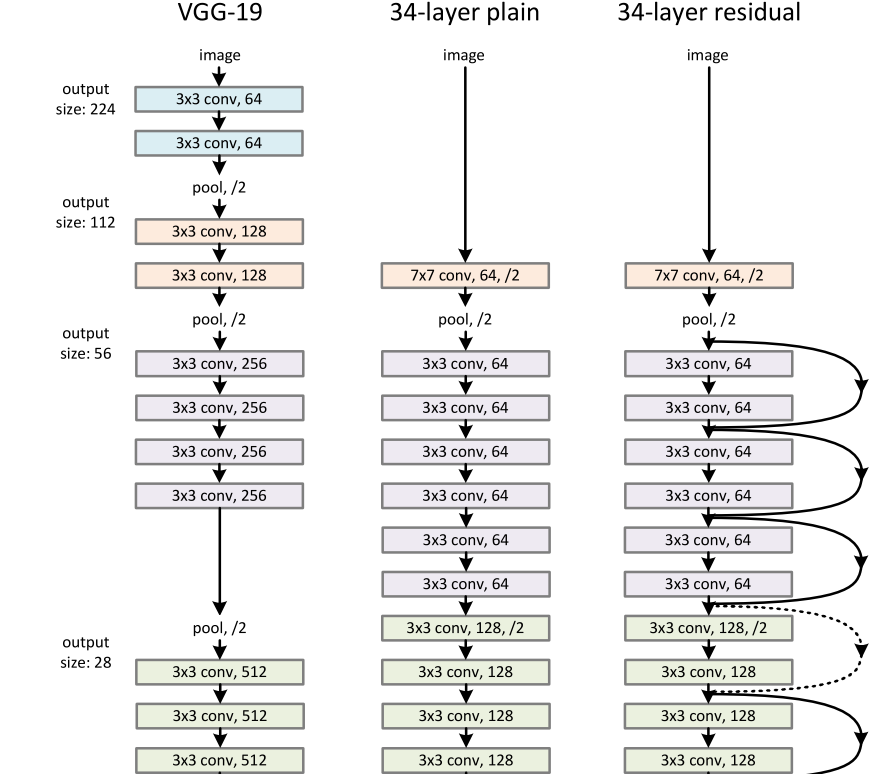
我们的普通基线(图3,中间)主要是受VGG网(图3,左)的启发。卷积层大多具有3×3滤波器,并遵循两个简单的设计规则:
(i)对于相同的输出特征地图大小,层具有相同数量的滤波器;
(ii)如果特征图大小减半,则滤波器的数量加倍,以便保持每层的时间复杂度。
我们直接通过步长为2的卷积层执行下采样。该网络以全局平均池层和使用softmax的1000路完全连接层结束。在图3(中间)中,加权层的总数为34。
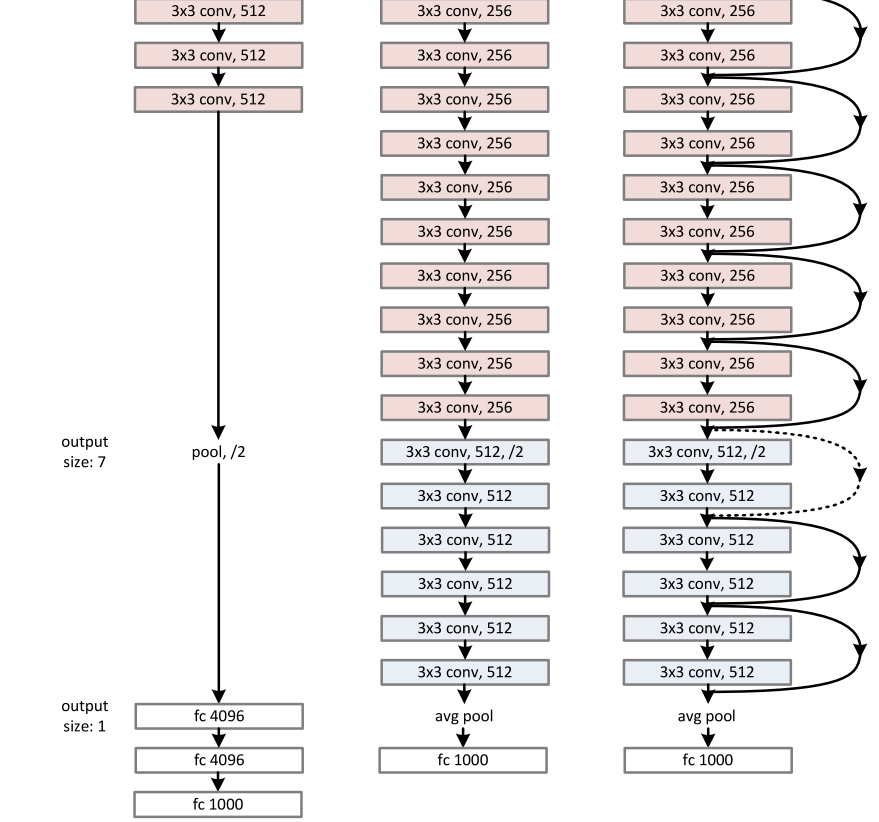 Residual Network.
Residual Network.
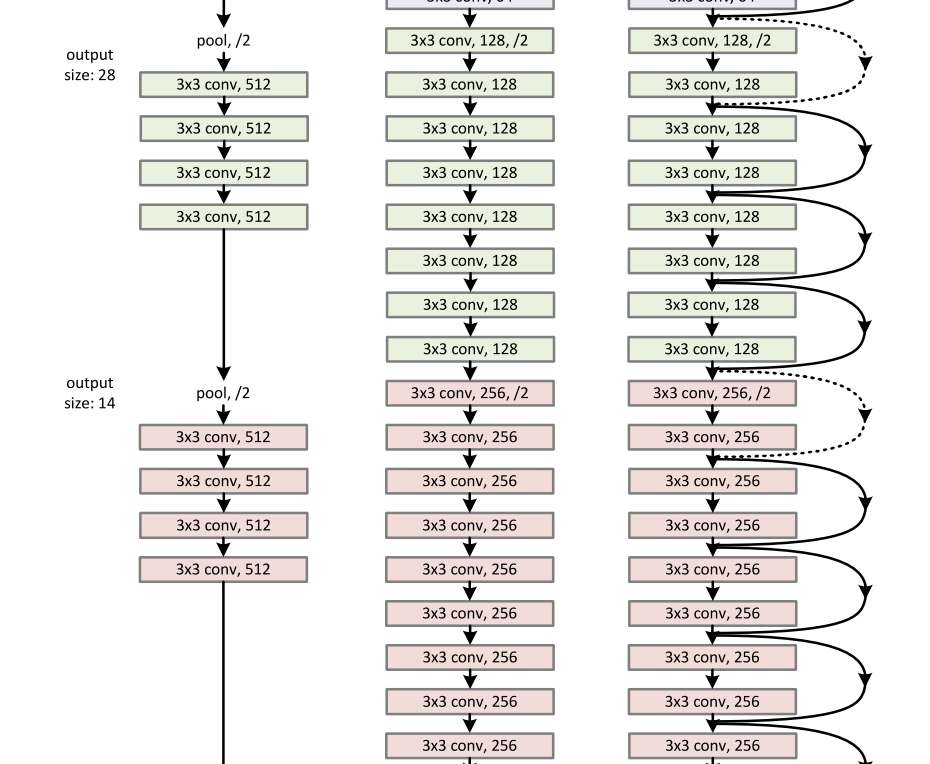
在上述简单网络的基础上,我们插入了捷径连接(图3,右图),将网络转化为对应的残差网络。标识快捷方式(公式(1))当输入和输出尺寸相同时,可以直接使用(图3中的实线快捷方式)。当尺寸增加时(图3中虚线快捷方式),我们考虑两种选择:(A)快捷方式仍然执行恒等映射,为增加的维度填充额外的零条目。此选项不引入额外参数;(B)方程中的投影捷径(2)用于匹配维度(通过1×1卷积完成)。对于这两个选项,当快捷键跨越两种大小的要素地图时,它们以步长2执行。
- 残差网络就介绍到这儿了,现在已经更新换代很多次了,可以从Residual Network这个关键词搜索更多更新的论文来学习神经网络。
4. conclusion
表征的深度对于许多视觉识别任务来说是至关重要的。仅由于我们的极深表示,我们获得了28%的相对改进的COCO对象检测数据集。深度残差网络是我们提交给ILSVRC & COCO 2015竞赛1的基础,我们还在ImageNet检测、ImageNet定位、COCO检测和COCO分割任务中获得了第一名。


![[从零开始]用python制作识图翻译器·五](https://img-blog.csdnimg.cn/5fae92e3897f4a2f875dcb71c2ebbc60.png)