数据库,计算机网络、操作系统刷题笔记34
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
文章目录
- 数据库,计算机网络、操作系统刷题笔记34
- @[TOC](文章目录)
- MySQL数据库
- 数据分析应用岗
- 不错的数据学习网站
- 探索分析与可视化
- 单因子分析:
- 单因子分析:集中趋势:均值啥的
- 单因子分析:离散离中趋势:方差啥的
- 单因子分析:数据分布,偏态和峰度
- 单因子分析:抽样理论
- 代码实现
- 分布函数的代码包:scipy包
- SDN-- 软件定义网络(Software Defined Network)
- 关于TCP协议的描述,以下错误的是?
- 服务与协议是完全不同的两个概念,下列关于它们的说法错误的是 () 。
- 快速以太网保留着10M以太网的最小帧长度以及最大帧长度
- DHCP:服务端发送的是offer,ack,客户端发送的是discover,request
- 在给FTP服务器设计ACL时,如果FTP服务器采用了的主动模式
- 显示器的分辨率是出厂就确定的硬件参数。和cpu型号没关系
- 此情况下()能提高CPU的利用率。
- 交换并未实现虚拟存储器
- 系统调用是系统提供给用户的系统子模块。用户对操作系统资源的申请都是通过系统调用的方式实现,保证了系统的安全性
- 在下列选项中,属于预防死锁的方法是()。
- 以下关于Linux操作系统内存的描述中,正确的有()
- 在计算机中, 系统调用 (英语:system call),又称为系统呼叫,指运行在使用者空间的程序向操作系统内核请求需要更高权限运行的服务。
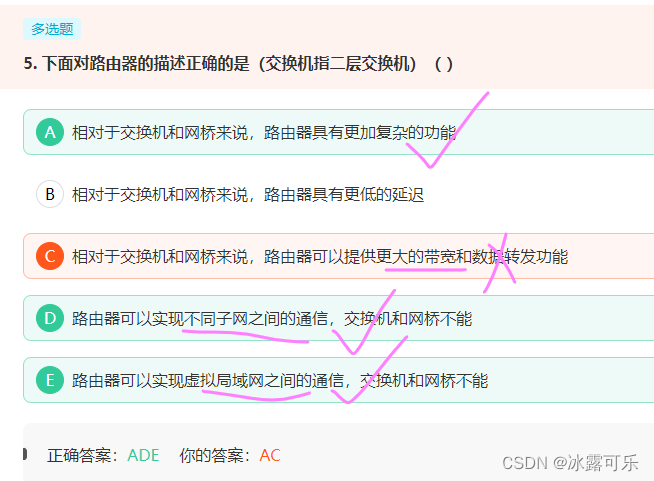
- 下面对路由器的描述正确的是(交换机指二层交换机)( )
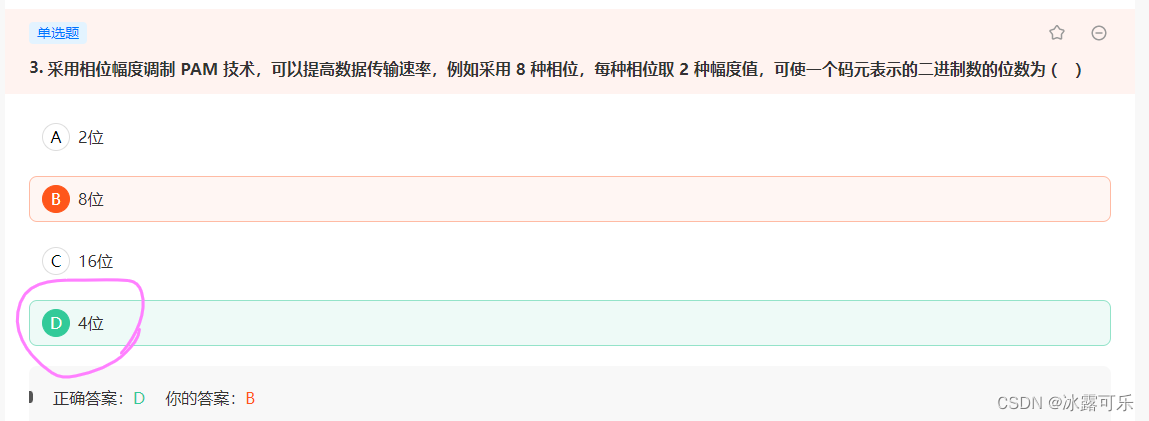
- 采用相位幅度调制 PAM 技术,可以提高数据传输速率,例如采用 8 种相位,每种相位取 2 种幅度值,可使一个码元表示的二进制数的位数为 ( )
- 下面哪个 IP 地址可用作本地广播地址? ______
- UDP报头中没有下面那些信息?()
- SYN Flood攻击(SYN洪水攻击)是基于连接的
- dp首部字段有8个字节,包括2字节的源端口号,2字节的目的端口号,2字节的包长度,2字节校验和,tcp首部字段20个字节
- 私有地址
- 对滑动窗口不正确的描述是:
- 虚拟内存只是将部分数据调入内存运行,其余留在外存,所以内存可以装更多数据,这样就显得内存扩大了不少。于是就存在内外存频繁换进换出数据的可能,这无疑增大了系统开销,降低系统效率。
- 操作系统的进程控制块。PCB
- 临界区是资源对象,只能被一个进程访问,不是内核对象
- 总结
文章目录
- 数据库,计算机网络、操作系统刷题笔记34
- @[TOC](文章目录)
- MySQL数据库
- 数据分析应用岗
- 不错的数据学习网站
- 探索分析与可视化
- 单因子分析:
- 单因子分析:集中趋势:均值啥的
- 单因子分析:离散离中趋势:方差啥的
- 单因子分析:数据分布,偏态和峰度
- 单因子分析:抽样理论
- 代码实现
- 分布函数的代码包:scipy包
- SDN-- 软件定义网络(Software Defined Network)
- 关于TCP协议的描述,以下错误的是?
- 服务与协议是完全不同的两个概念,下列关于它们的说法错误的是 () 。
- 快速以太网保留着10M以太网的最小帧长度以及最大帧长度
- DHCP:服务端发送的是offer,ack,客户端发送的是discover,request
- 在给FTP服务器设计ACL时,如果FTP服务器采用了的主动模式
- 显示器的分辨率是出厂就确定的硬件参数。和cpu型号没关系
- 此情况下()能提高CPU的利用率。
- 交换并未实现虚拟存储器
- 系统调用是系统提供给用户的系统子模块。用户对操作系统资源的申请都是通过系统调用的方式实现,保证了系统的安全性
- 在下列选项中,属于预防死锁的方法是()。
- 以下关于Linux操作系统内存的描述中,正确的有()
- 在计算机中, 系统调用 (英语:system call),又称为系统呼叫,指运行在使用者空间的程序向操作系统内核请求需要更高权限运行的服务。
- 下面对路由器的描述正确的是(交换机指二层交换机)( )
- 采用相位幅度调制 PAM 技术,可以提高数据传输速率,例如采用 8 种相位,每种相位取 2 种幅度值,可使一个码元表示的二进制数的位数为 ( )
- 下面哪个 IP 地址可用作本地广播地址? ______
- UDP报头中没有下面那些信息?()
- SYN Flood攻击(SYN洪水攻击)是基于连接的
- dp首部字段有8个字节,包括2字节的源端口号,2字节的目的端口号,2字节的包长度,2字节校验和,tcp首部字段20个字节
- 私有地址
- 对滑动窗口不正确的描述是:
- 虚拟内存只是将部分数据调入内存运行,其余留在外存,所以内存可以装更多数据,这样就显得内存扩大了不少。于是就存在内外存频繁换进换出数据的可能,这无疑增大了系统开销,降低系统效率。
- 操作系统的进程控制块。PCB
- 临界区是资源对象,只能被一个进程访问,不是内核对象
- 总结
MySQL数据库
你看到的网页,都是数据库读出来,然后展示给你
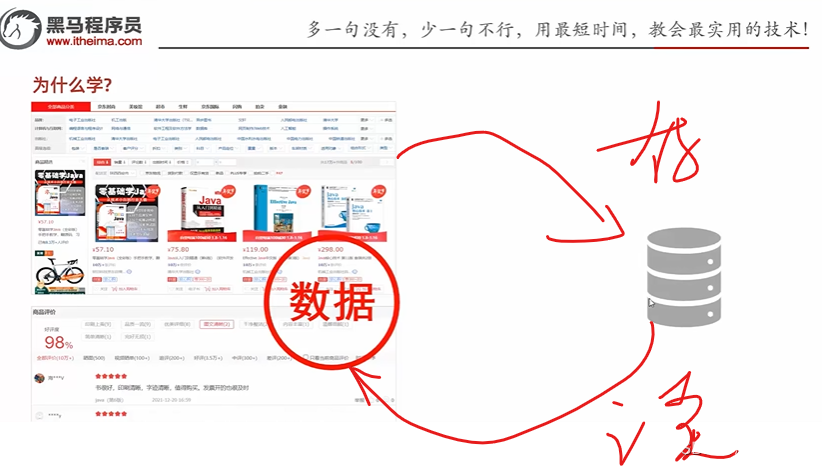
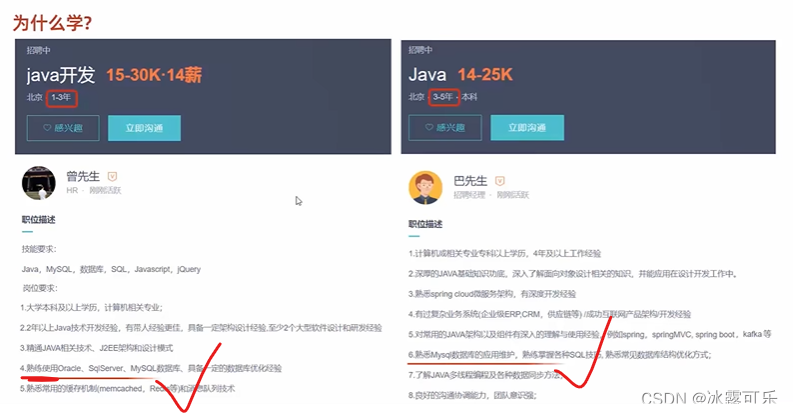
找工作最好是要熟练掌握数据库

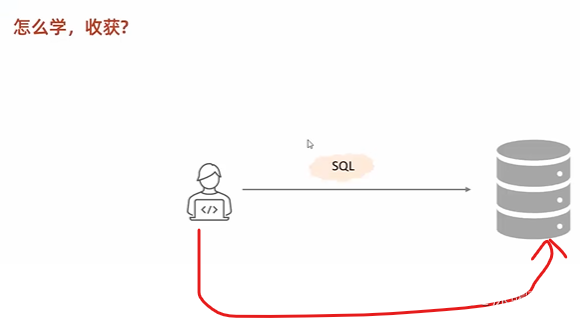
基础入门们

深入了解
企业需要搞集群的话,需要
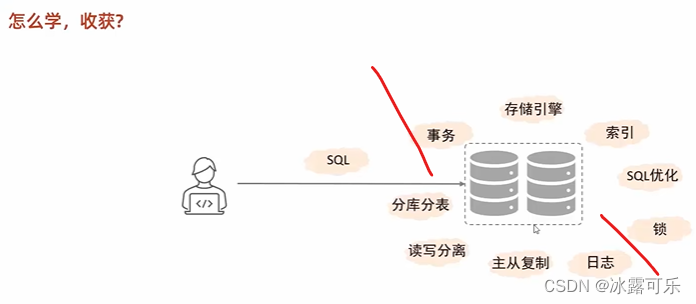
其余的你看我前面的Oracle数据库文章,我已经复习了2遍了
今天开始咱学数据分析应用岗的相关知识
毕竟国考考数据分析应用,数据库知识一点小基础
很重要的是数据处理和分析、建模等知识
数据分析应用岗

不错的数据学习网站

kaggle:
https://www.kaggle.com/
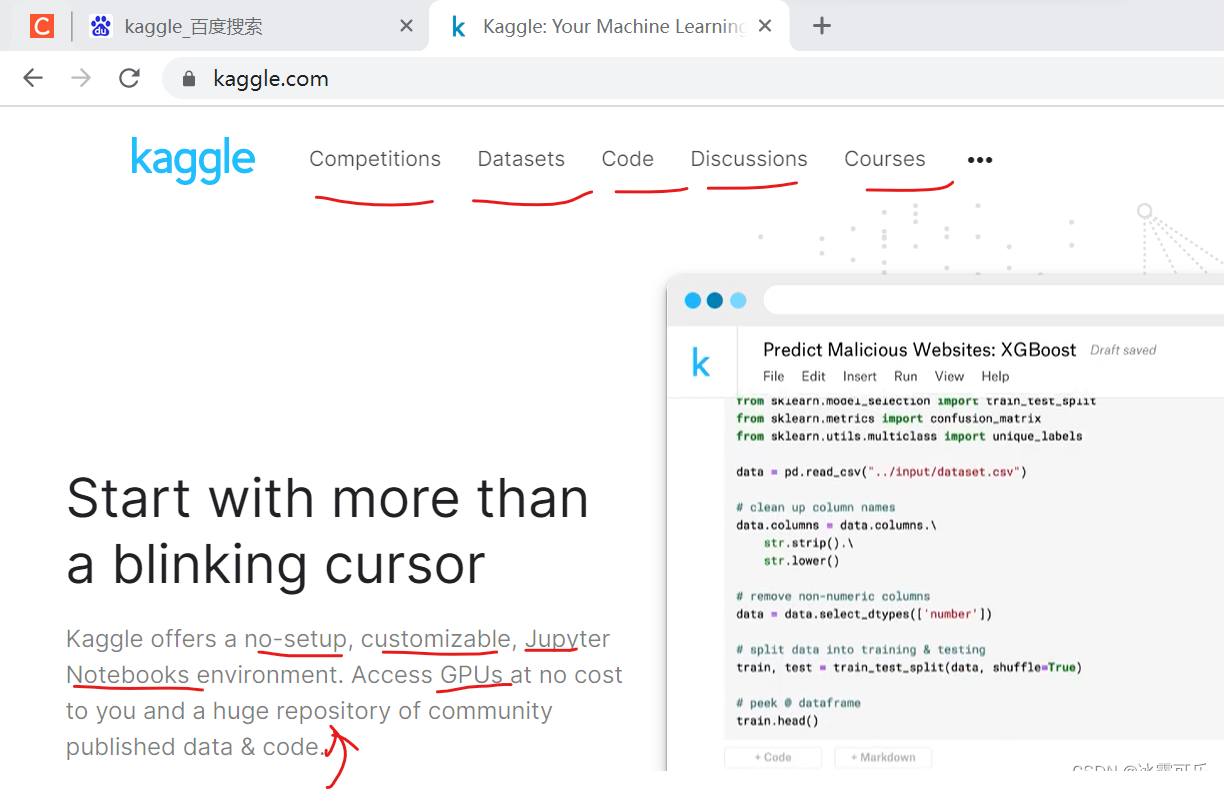
kaggle很丰富哦
天池比赛
https://tianchi.aliyun.com/
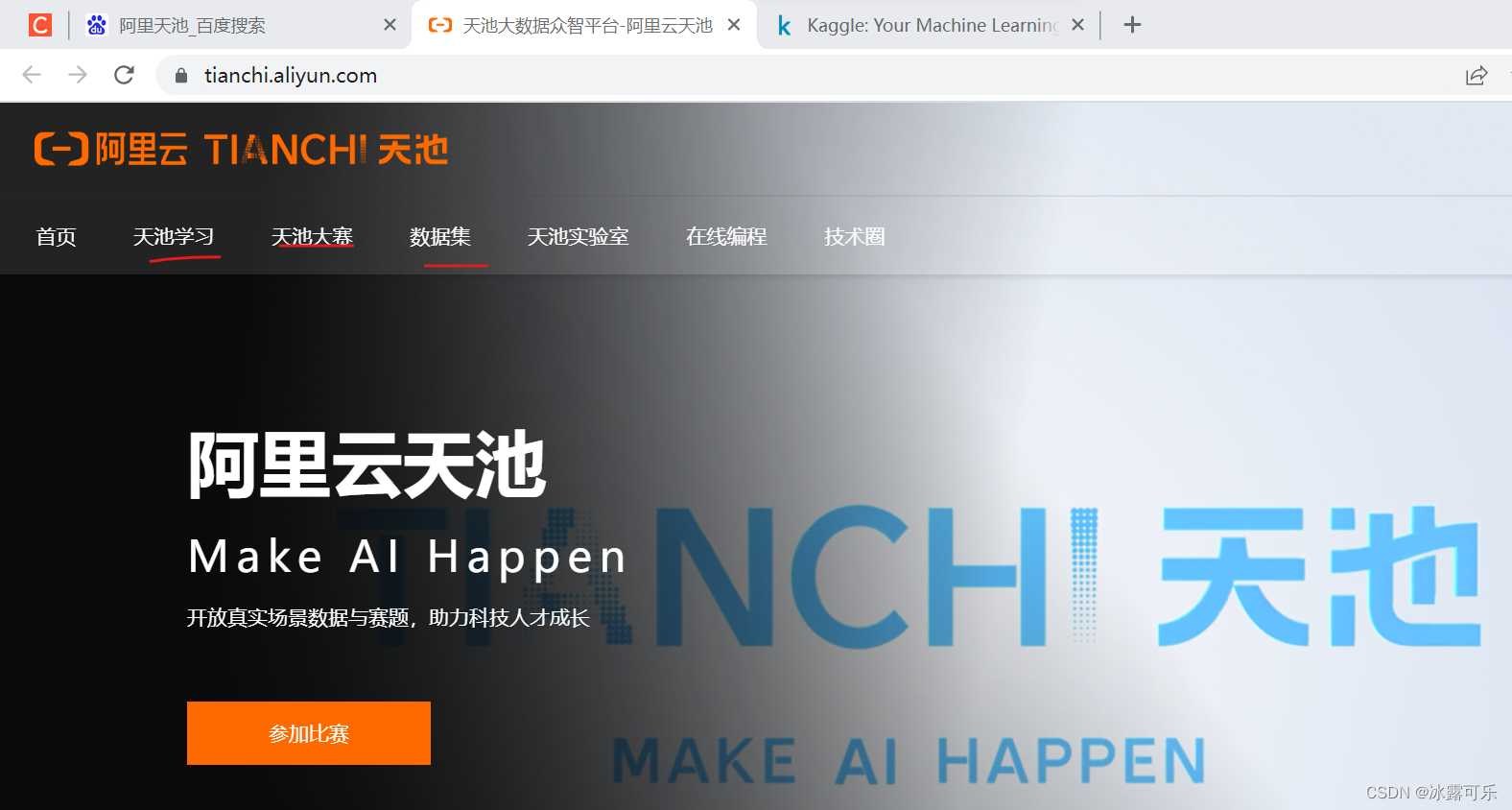
有很多数据集,很多建模任务
开源数据
众智
数据集的话
imageNet:
https://image-net.org/
等
探索分析与可视化


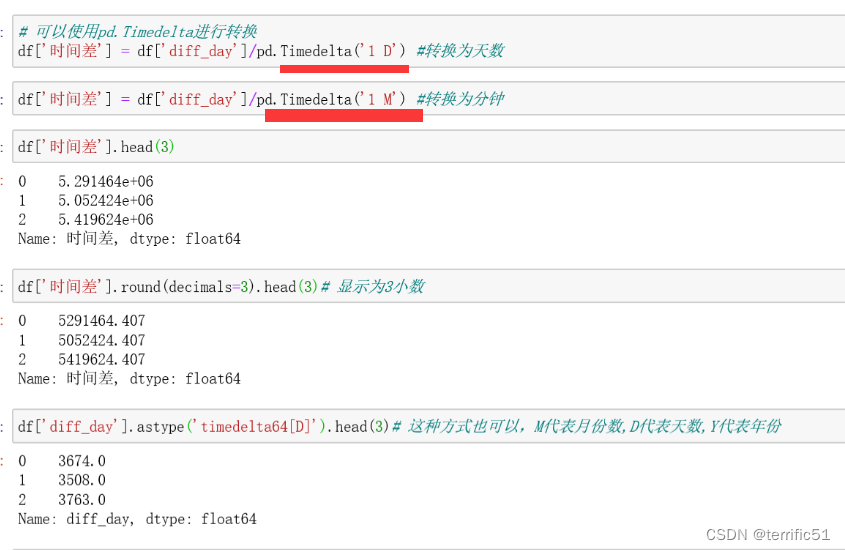
import pandas as pd
if __name__ == '__main__':
df = pd.read_csv('HR_comma_sep.csv')
print(df.head(10))
你自己去kaggle搜索hr.csv
去下载
然后打印看一波哈
单因子分析:

单因子分析:集中趋势:均值啥的
数据的数量???n


单因子分析:离散离中趋势:方差啥的

左右1sigma之间的概率69%
1.96sigma之间的概率95%
2.58sigma之间的概率99%
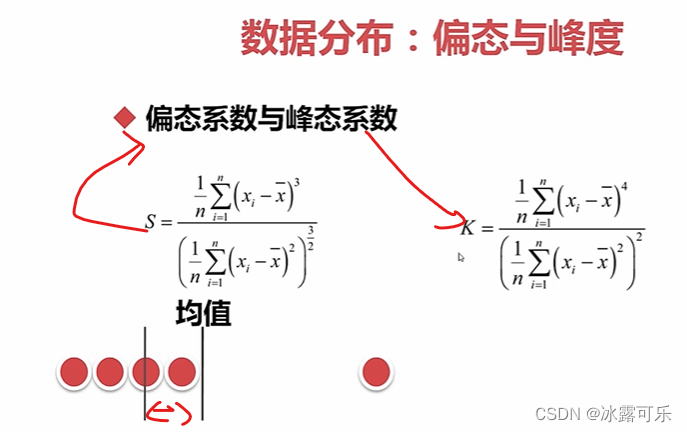
单因子分析:数据分布,偏态和峰度
非正泰分布的话,u是左右偏移的:相对于中位数来说,有偏差哦
sigma也是大小不同,高度不同
S越大,拖底越大
峰态:看看数据是否集中,K越大,高度越高
单因子分析:抽样理论
数量太大
只能抽样玩
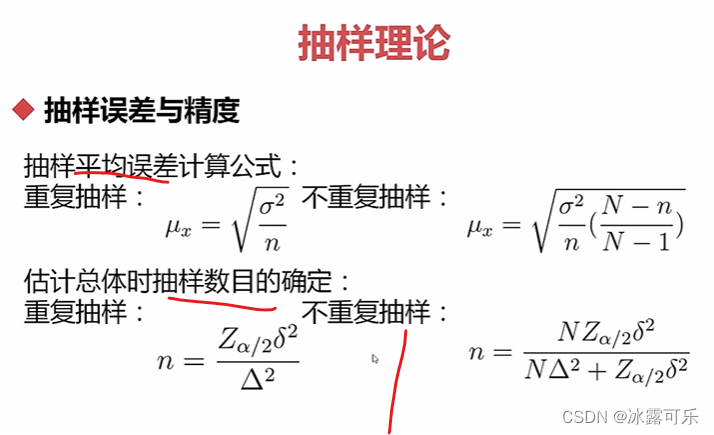
Z貌似要查的,有一个表

代码实现
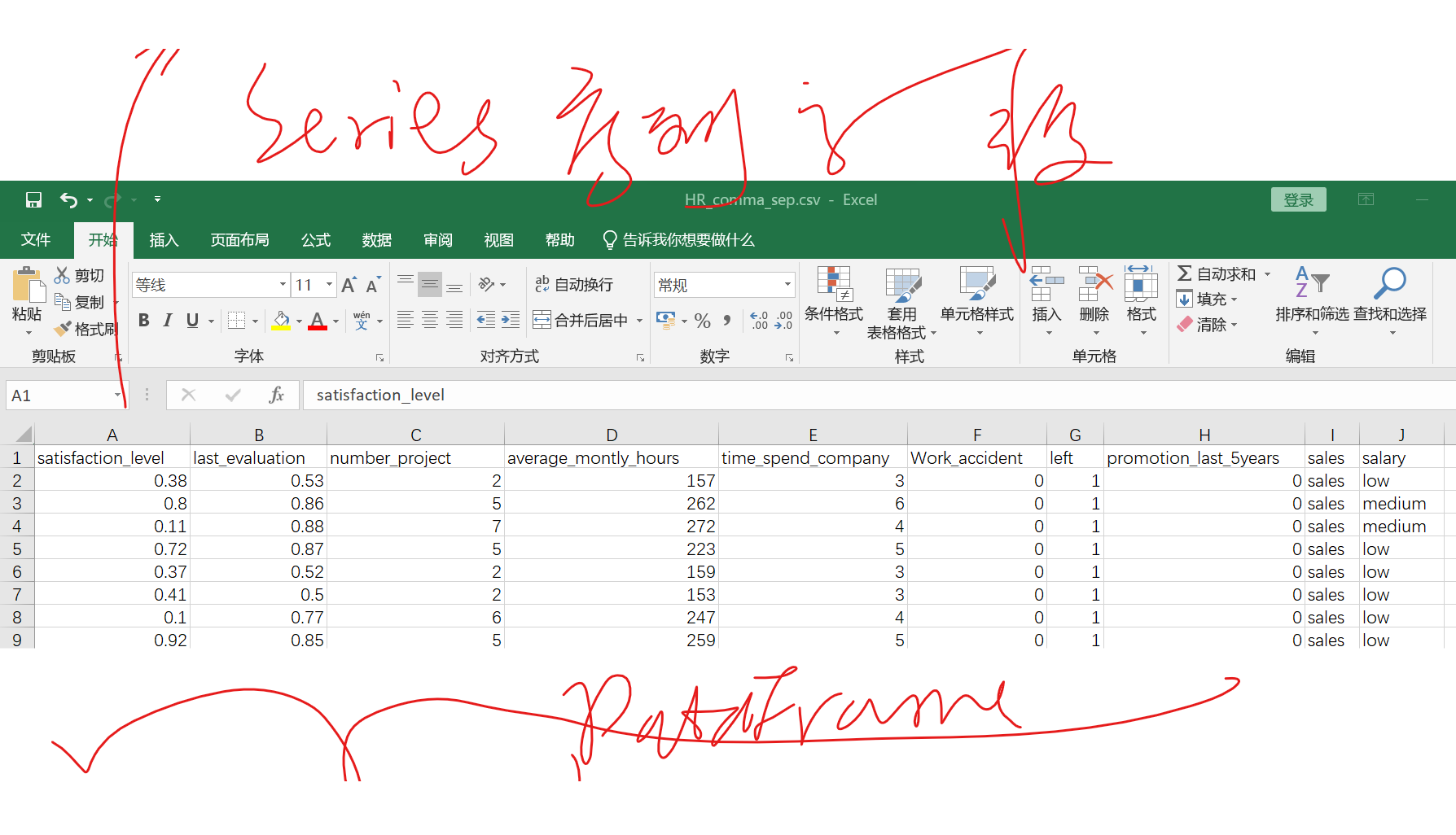
pandas最重要的俩数据结构
df = pd.read_csv('HR_comma_sep.csv')
print(type(df))
print(type(df['satisfaction_level']))
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
整个表示dataframe
而表中的一个字段叫序列
咱们来看看用整个表求均值啥的,会得到什么???
print(df.mean())
print(df.sum())
satisfaction_level 0.612834
last_evaluation 0.716102
number_project 3.803054
average_montly_hours 201.050337
time_spend_company 3.498233
Work_accident 0.144610
left 0.238083
promotion_last_5years 0.021268
dtype: float64
satisfaction_level 9191.89
last_evaluation 10740.8
number_project 57042
average_montly_hours 3015554
time_spend_company 52470
Work_accident 2169
left 3571
promotion_last_5years 319
sales salessalessalessalessalessalessalessalessaless...
salary lowmediummediumlowlowlowlowlowlowlowlowlowlowl...
dtype: object
如果求均值,它是每个字段的均值都给你求出来了
求和的话,每个字段给你求和
遇到字符串,给你拼接了+
骚
那如果我们用序列求和求均值呢?
print(df['satisfaction_level'].mean())
print(df['satisfaction_level'].sum())
0.6128335222348166
9191.89
这样就是一个序列的均值或者和了
和这么大,均值这么小
说明表中的数据量很大
至少1000条
类似的,中位数
print(df.median())
print(df.quantile(q=0.25)) # 分位数
print(df.quantile(q=0.5)) # 分位数
print(df.quantile(q=0.75)) # 分位数
print('/n')
# print(df['satisfaction_level'].mean())
# print(df['satisfaction_level'].sum())
print(df['satisfaction_level'].median())
print(df['satisfaction_level'].quantile(q=0.25)) # 分位数
print(df['satisfaction_level'].quantile(q=0.5)) # 分位数
print(df['satisfaction_level'].quantile(q=0.75)) #
satisfaction_level 0.64
last_evaluation 0.72
number_project 4.00
average_montly_hours 200.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
dtype: float64
satisfaction_level 0.44
last_evaluation 0.56
number_project 3.00
average_montly_hours 156.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
Name: 0.25, dtype: float64
satisfaction_level 0.64
last_evaluation 0.72
number_project 4.00
average_montly_hours 200.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
Name: 0.5, dtype: float64
satisfaction_level 0.82
last_evaluation 0.87
number_project 5.00
average_montly_hours 245.00
time_spend_company 4.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
Name: 0.75, dtype: float64
/n
0.64
0.44
0.64
0.82
仍然是表的话,按照字段去求
序列直接求
中位数是median
分位数是quantile,需要指定几分位数
参数为q,拿下
众数
print(df.mode()) # 众数
print(df['satisfaction_level'].mode())
satisfaction_level last_evaluation ... sales salary
0 0.1 0.55 ... sales low
1 NaN NaN ... NaN NaN
[2 rows x 10 columns]
0 0.1
dtype: float64
众数可能不是唯一的
不同的字段
出现得最多的那个
df = pd.read_csv('HR_comma_sep.csv')
print(df.var()) # 方差
print(df['satisfaction_level'].var()) # 方差
satisfaction_level 0.061817
last_evaluation 0.029299
number_project 1.519284
average_montly_hours 2494.313175
time_spend_company 2.131998
Work_accident 0.123706
left 0.181411
promotion_last_5years 0.020817
dtype: float64
0.061817200647087255
求方差和均值类似
用的是var
反正数据背后实现的算法,你都能搞出来
自己调用一下即可
print(df.skew()) # 偏态系数--负偏,正偏
print(df['satisfaction_level'].skew()) # 偏态系数--负偏,正偏
satisfaction_level -0.476360
last_evaluation -0.026622
number_project 0.337706
average_montly_hours 0.052842
time_spend_company 1.853319
Work_accident 2.021149
left 1.230043
promotion_last_5years 6.636968
dtype: float64
-0.4763603412839644
偏态系数skew
如果是小于0
说明绝大部分值都是小于均值的,否则差不会小于0的
峰态系数用Kurt
print(df.kurt()) # 峰态系数
print(df['satisfaction_level'].kurt()) # 峰态系数
satisfaction_level -0.670859
last_evaluation -1.239040
number_project -0.495478
average_montly_hours -1.134982
time_spend_company 4.773211
Work_accident 2.085320
left -0.487060
promotion_last_5years 42.054957
dtype: float64
-0.6708586220574557
峰态以标准正态分布为基准
如果峰态系数小于0
则说明它的峰值竟然比正态分布还要低
因此就比正态分布还要平缓
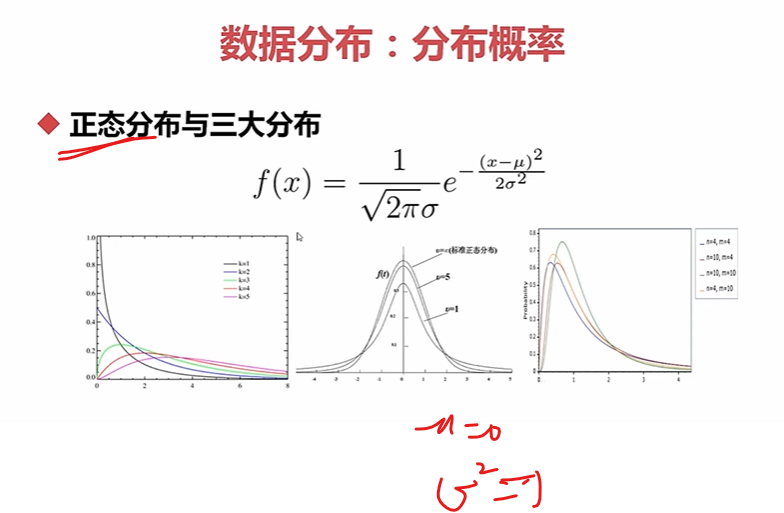
分布函数的代码包:scipy包
import pandas as pd
import scipy.stats as ss
df = pd.read_csv('HR_comma_sep.csv')
print(ss.norm) # 生成一个正态分布对象
print(ss.norm.stats(moments="mvsk")) # mean var skew kurt四个参数
<scipy.stats._continuous_distns.norm_gen object at 0x000001E033BD5E48>
(array(0.), array(1.), array(0.), array(0.))
它就是一个object对象
norm
内部有很多的函数,可以调用
比如stats展示四个参数
这就是标准的正态分布对象
pdf是它的分布函数
指定横坐标,它返回纵坐标
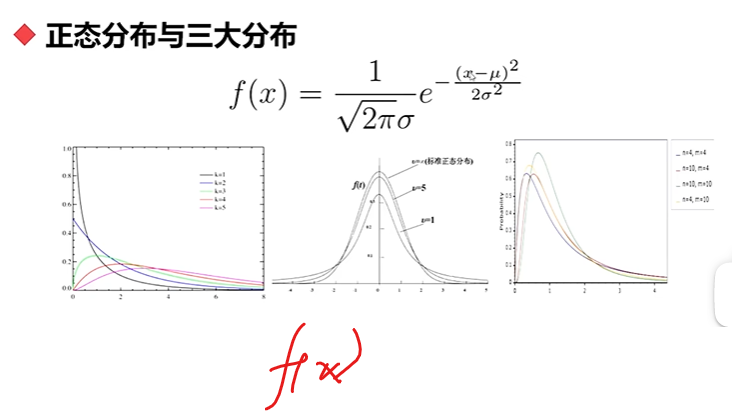
print(ss.norm.pdf(0)) # 概率函数fx
0.3989422804014327
懂?
ppf§
代表负无穷大到x之间之间概率的累计和为p时,返回这个x
x负无穷大到正无穷大之间的积分是1
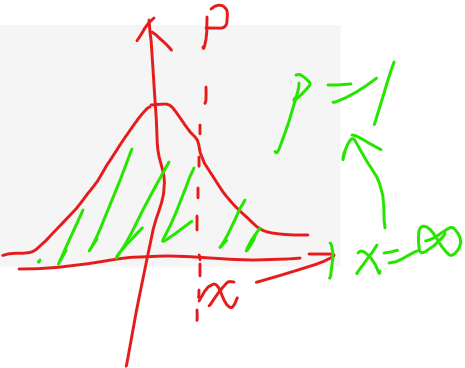
如果p放0.9的话,看看x在哪里
print(ss.norm.ppf(1)) # 代表负无穷大到x之间之间概率的累计和为p时,返回这个x
print(ss.norm.ppf(0.9)) # 代表负无穷大到x之间之间概率的累计和为p时,返回这个x
print(ss.norm.ppf(0.5)) # 代表负无穷大到x之间之间概率的累计和为p时,返回这个x
inf
1.2815515655446004
0.0
看见了吗
ppf是累计f多大情况下,我们反推x在哪个点
懂?
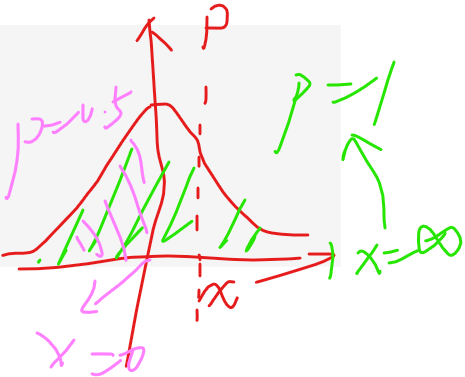
cdf(a)是x从负无穷累计到a,p概率累加和是多少?
import numpy as np
print(ss.norm.cdf(0)) # cdf(a)是x从负无穷累计到a,p概率累加和是多少?
print(ss.norm.cdf(np.inf)) # cdf(a)是x从负无穷累计到a,p概率累加和是多少?
print(ss.norm.cdf(2)) # cdf(a)是x从负无穷累计到a,p概率累加和是多少?
0.5
1.0
0.9772498680518208
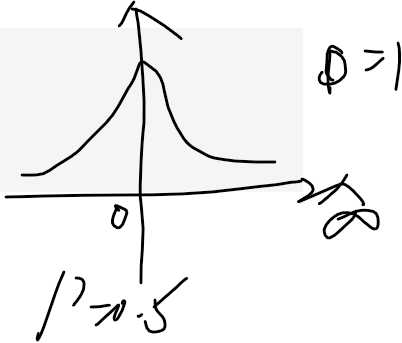
如果是1或者2sigma之间的概率累加呢
print(ss.norm.cdf(1)-ss.norm.cdf(-1)) # 1sigma中间的概率累计和
print(ss.norm.cdf(2)-ss.norm.cdf(-2)) # 2sigma中间的概率累计和
0.6826894921370859
0.9544997361036416
刚刚好
我们讲过,这俩区间的占比是固定的值

这玩意就是cdf算出来的
咱们弄几个正态分布的数据出来
用rvs函数
print(ss.norm.rvs(size=10)) # 产生正态分布数据
[-2.46827037 -0.9081473 0.45237675 -1.88215502 0.39799333 1.41524525
0.83309441 1.41375198 1.30330961 0.66591575]
美滋滋不
同理,这个是正态分布
要是其他的:
卡方分布
t分布
f分布
print(ss.chi2) # 卡方分布
print(ss.t) # t分布
print(ss.f) # f分布
<scipy.stats._continuous_distns.chi2_gen object at 0x00000195E6B3CF08>
<scipy.stats._continuous_distns.t_gen object at 0x00000195E6BD3C88>
<scipy.stats._continuous_distns.f_gen object at 0x00000195E6B54188>
不同的对象,上面的那些函数都有一份
操作相同的
给这个表抽样几行
好说
df = pd.read_csv('HR_comma_sep.csv')
print(df.sample(n=10)) # 抽n个
satisfaction_level last_evaluation ... sales salary
904 0.45 0.46 ... product_mng low
13597 0.92 0.60 ... IT low
13561 0.53 0.61 ... management high
5058 0.67 1.00 ... sales medium
4793 0.56 0.52 ... IT low
14674 0.80 0.85 ... management low
7961 0.90 0.62 ... sales medium
4604 0.93 0.68 ... sales low
13573 0.43 0.65 ... sales medium
11085 0.57 0.67 ... IT medium
[10 rows x 10 columns]
如果是按照总体的比例抽,就是frac占比
print(df.sample(frac=0.001)) # 抽千分之一的数据
satisfaction_level last_evaluation ... sales salary
9175 0.64 0.99 ... sales low
2179 0.89 0.47 ... technical low
2955 0.88 0.59 ... support medium
781 0.91 0.96 ... sales low
2681 0.89 0.67 ... sales medium
14086 0.42 0.47 ... technical low
3622 0.61 0.94 ... technical medium
3896 0.56 0.68 ... management medium
5751 0.35 0.81 ... sales high
10734 0.67 0.49 ... support low
2669 0.33 0.70 ... RandD low
12661 0.39 0.46 ... support medium
7348 0.61 0.63 ... sales low
9955 0.55 0.81 ... hr low
1242 0.10 0.85 ... sales high
[15 rows x 10 columns]
print(df['satisfaction_level'].sample(n=1)) # 抽n个
print(df['satisfaction_level'].sample(frac=0.1)) # 抽千分之一的数据
356 0.41
Name: satisfaction_level, dtype: float64
8423 0.92
8400 0.83
10507 0.54
11333 0.49
4974 0.14
...
13573 0.43
460 0.43
8281 0.21
13889 0.27
423 0.40
Name: satisfaction_level, Length: 1500, dtype: float64
得到的还是series
反正这些函数,和接口,都是查阅资料,使用时官网去学习
不需要我们记忆的
SDN-- 软件定义网络(Software Defined Network)
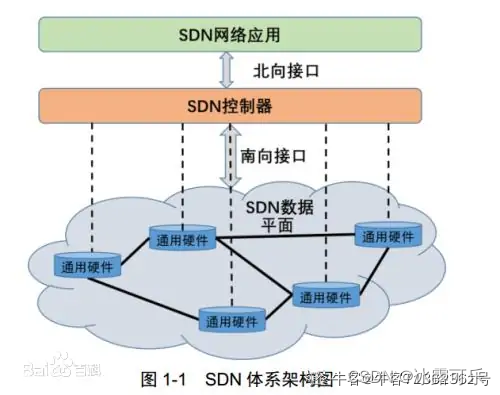
软件定义网络(Software Defined Network, SDN ),是由Emulex提出的一种新型网络创新架构,
其核心技术OpenFlow通过将网络设备控制面与数据面分离开来,
从而实现了网络流量的灵活控制,为核心网络及应用的创新提供了良好的平台。
从路由器的设计上看,它由软件控制和硬件数据通道组成。
软件控制包括管理(CLI,SNMP)以及路由协议(OSPF,ISIS,BGP)等。
数据通道包括针对每个包的查询、交换和缓存。
这方面有大量论文在研究,引出三个开放性的话题,即“提速2倍”,确定性的(而不是概率性的)交换机设计,以及让路由器简单。

关于TCP协议的描述,以下错误的是?
链接:https://www.nowcoder.com/questionTerminal/e8e8cf8124cf4a4cb6fc24ef8dc683ef
来源:牛客网
TCP最主要的特点:
(1) 1)TCP是面向连接的运输层协议。应用进程之间的通信像“打电话”:通话前要先拨号建立连接,通话结束后要挂机释放链接。(A选项,面向连接)
(2) 2)每一条TCP连接只能有两个端点(endpoint),点对点。(B选项,TCP只能提供点对点,不提供多播)
(3) 3)TCP提供可靠交付的服务。无差错、不丢失、不重复,并且按序到达。(C选项)(D选项,TCP提供的是可靠交付,所以TCP首部开销会大;UDP协议只是尽最大努力交付,UDP的首部开销小)
(4) 4)**TCP提供全双工通信。**双向通信.
(5) 5)面向字节流。“面向字节流“的含义是:虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来 的数据仅仅看成是一连串的无结构的字节流 。TCP并不知道所传送的字节流的含义。
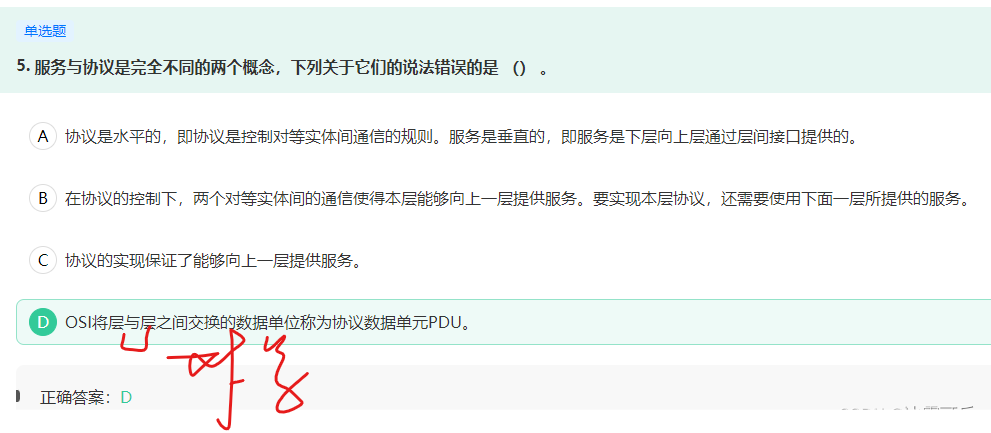
服务与协议是完全不同的两个概念,下列关于它们的说法错误的是 () 。
链接:https://www.nowcoder.com/questionTerminal/cb15914fbc234824a2a93fc396ad6f13
来源:牛客网
SDU(Service Data Unit)服务数据单元是OSI相邻上下层与层之间交换数据的单位 协议数据单元
PDU(Protocol Data Unit)协议数据单元是OSI对等层次之间传递的数据单位
快速以太网保留着10M以太网的最小帧长度以及最大帧长度
链接:https://www.nowcoder.com/questionTerminal/6c0318de982d49e8aa0df8659df3e291
来源:牛客网
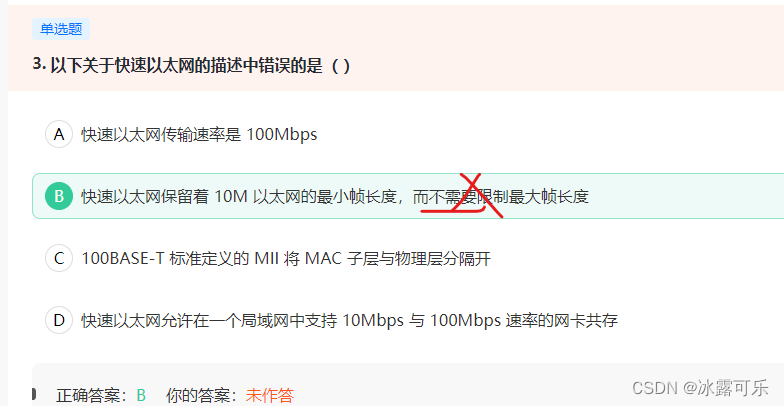
快速以太网(Fast Ethernet)是一种局域网(LAN)传输标准,
它提供每秒100兆的数据传输率(100BASE-T)。
有每秒10兆(10BASE-T)的以太网卡的工作站能连接到快速以太网。
(每秒100兆是一个共享的数据传输率;对每个工作站的输入由10Mbps卡限制。
大猫小猫都只需要一个门
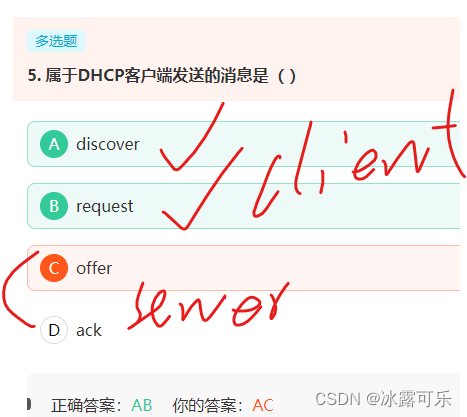
DHCP:服务端发送的是offer,ack,客户端发送的是discover,request
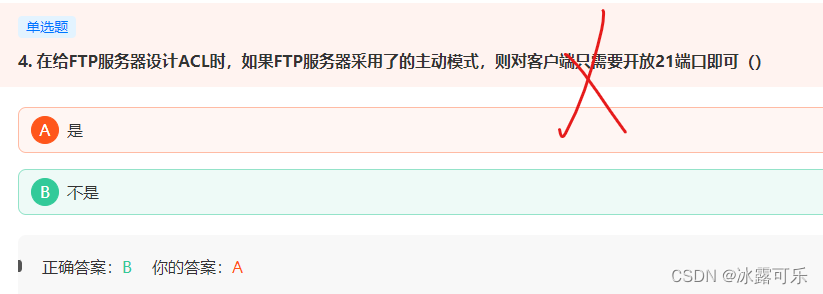
在给FTP服务器设计ACL时,如果FTP服务器采用了的主动模式
链接:https://www.nowcoder.com/questionTerminal/599b2cdddfe942beb520586c6f319a49
来源:牛客网
在控制方面,端口号为21,一般用于登录认证,
在数据传输方面,
若为主动模式,则端口号为20;
若为被动模式,则由服务端和客户端协商而定,故选B。
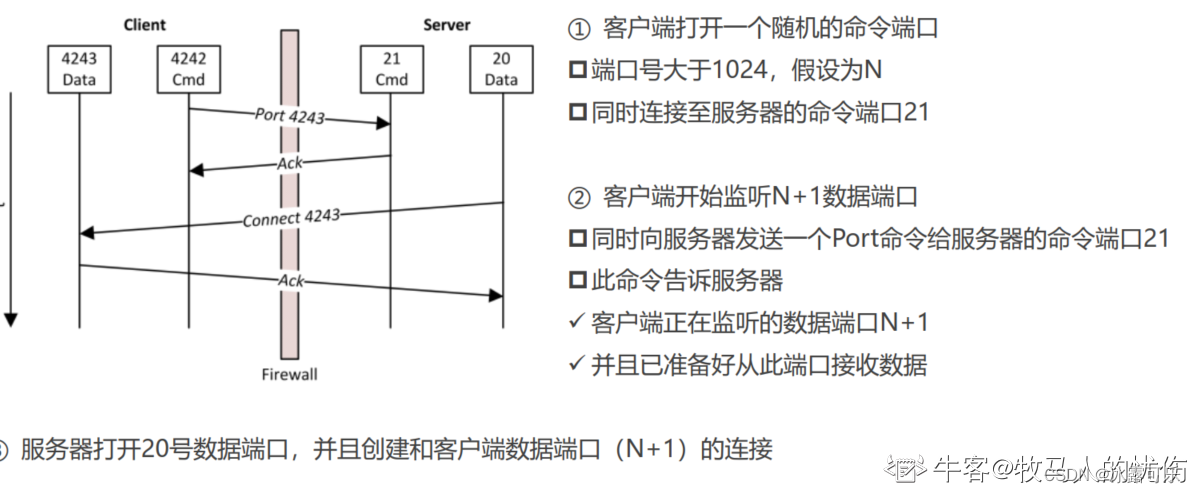
主动FTP:
命令连接【控制】:客户端 >1023端口 -> 服务器 21端口
数据连接【数据】:客户端 >1023端口 <- 服务器 20端口
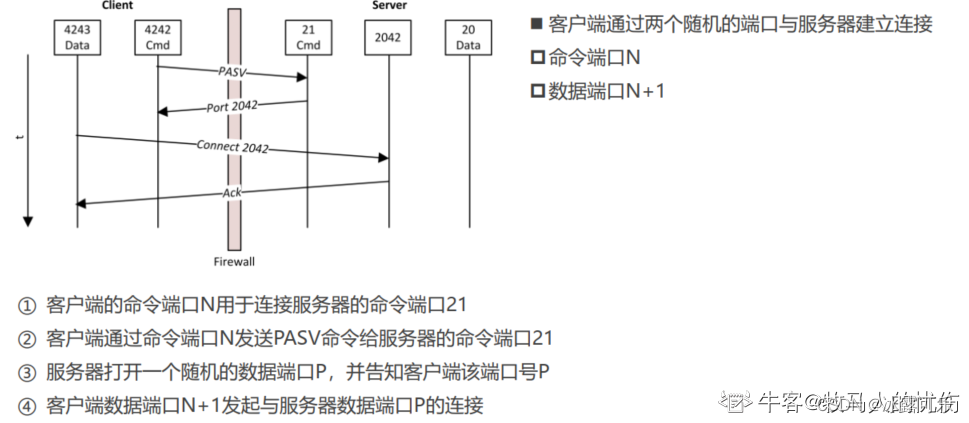
被动FTP:
命令连接【控制】:客户端 >1023端口 -> 服务器 21端口
数据连接【数据】:客户端 >1023端口 -> 服务器 >1023端口
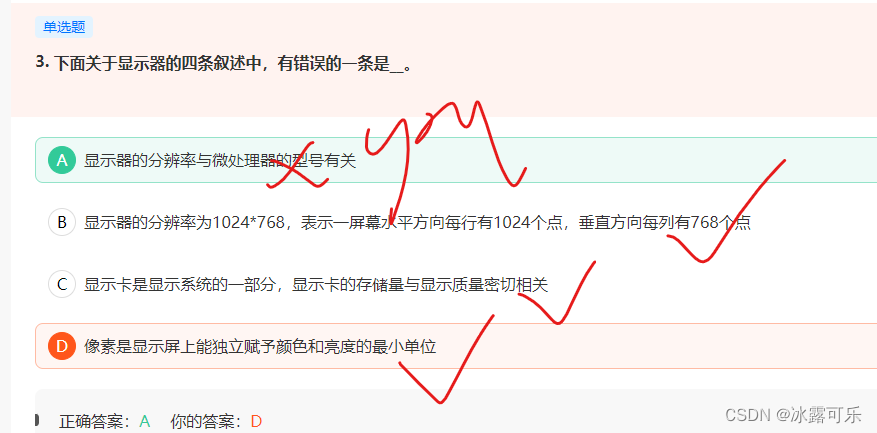
显示器的分辨率是出厂就确定的硬件参数。和cpu型号没关系
这俩本来就是独立的俩设备
毛关系没有啊
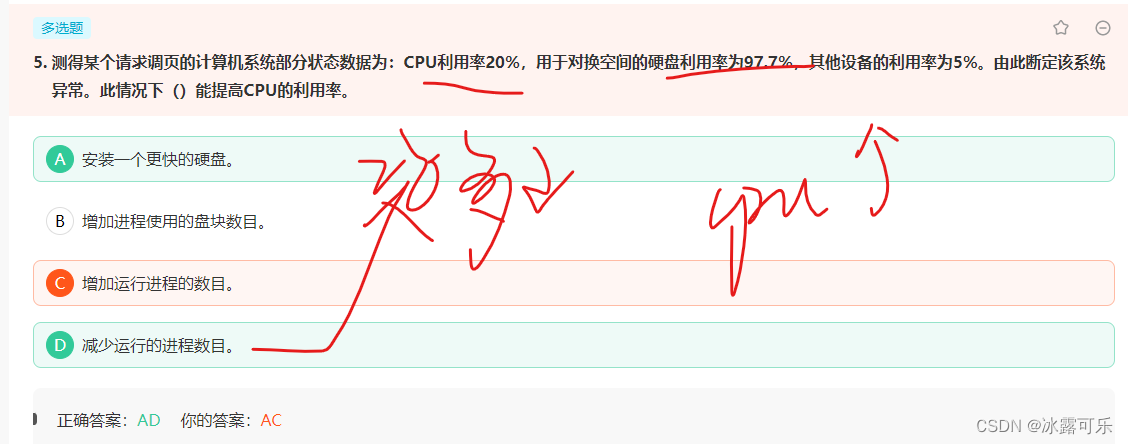
此情况下()能提高CPU的利用率。
链接:https://www.nowcoder.com/questionTerminal/62ae2a183ca64f72af1dbf94083747cc
来源:牛客网
D可以理解为,对IO频繁的进程减少后,因为等待硬盘IO导致的CPU等待时间也相应减少,从而CPU使用率上升了。
但是A呢,如果使用更快的硬盘,显然每个进程用于IO等待的时间也会减少,从而CPU的使用率肯定也会提升。
交换并未实现虚拟存储器
链接:https://www.nowcoder.com/questionTerminal/81ecc4c516be4c1999d5b408519d85c0
来源:牛客网
交换是把多个进程完整地调入内存,运行一段时间,再放回磁盘上。【这个不是虚拟存储】
虚拟存储器是使进程在只有一部分在内存的情况下也能运行。
虚拟存储器的基本思想是程序的大小可以超过物理内存的大小,
操作系统把程序的一部分调入主存来运行,而把其他部分保留在磁盘上。
故交换并未实现虚拟存储器。
系统调用是系统提供给用户的系统子模块。用户对操作系统资源的申请都是通过系统调用的方式实现,保证了系统的安全性
系统调用是一个用户调用的接口
在下列选项中,属于预防死锁的方法是()。
链接:https://www.nowcoder.com/questionTerminal/b8ade2458fe94e59827f8adbf58efe2c
来源:牛客网
1. 预防死锁。
这是一种较简单和直观的事先预防的方法。
方法是通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。
预防死锁是一种较易实现的方法,已被广泛使用。但是由于所施加的限制条件往往太严格,可能会导致系统资源利用率和系统吞吐量降低。
2. 避免死锁。
该方法同样是属于事先预防的策略,但它并不须事先采取各种限制措施去破坏产生死锁的的四个必要条件 ,而是在资源的动态分配过程中,用某种方法去防止系统进入不安全状态,从而避免发生死锁。【银行家算法】
很骚啊
3. 检测死锁。
这种方法并不须事先采取任何限制性措施,也不必检查系统是否已经进入不安全区,此方法允许系统在运行过程中发生死锁。但可通过系统所设置的检测机构,及时地检测出死锁的发生,并精确地确定与死锁有关的进程和资源,然后采取适当措施,从系统中将已发生的死锁清除掉。
4. 解除死锁。
这是与检测死锁相配套的一种措施。当检测到系统中已发生死锁时,须将进程从死锁状态中解脱出来。常用的实施方法是撤销或挂起一些进程,以便回收一些资源,再将这些资源分配给已处于阻塞状态的进程,使之转为就绪状态,以继续运行。死锁的检测和解除措施,有可能使系统获得较好的资源利用率和吞吐量,但在实现上难度也最大。
列举说明linux系统的各类异步机制
以下关于Linux操作系统内存的描述中,正确的有()
2错
在计算机中, 系统调用 (英语:system call),又称为系统呼叫,指运行在使用者空间的程序向操作系统内核请求需要更高权限运行的服务。
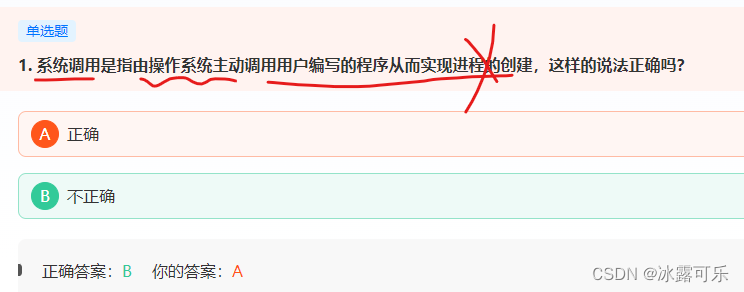
不是创建进程
是调用跟高权限的服务
下面对路由器的描述正确的是(交换机指二层交换机)( )
采用相位幅度调制 PAM 技术,可以提高数据传输速率,例如采用 8 种相位,每种相位取 2 种幅度值,可使一个码元表示的二进制数的位数为 ( )
log2(8*2)=log216=4位。
下面哪个 IP 地址可用作本地广播地址? ______

全0:本网络上的本主机”,只能用作源地址。
全1:本网络的广播地址
127.0.0.1是最常用的一种,表示本地计算机的IP地址,也可以用localhost表示。
UDP报头中没有下面那些信息?()
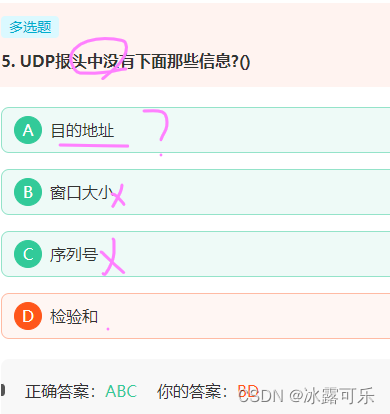
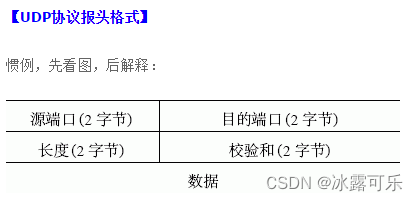
UDP包头包含,源端目的端口号,数据报长度,检验和
序列号和窗口大小是TCP的
UDP也没有地址
SYN Flood攻击(SYN洪水攻击)是基于连接的
链接:https://www.nowcoder.com/questionTerminal/4048c3110222428d8fa3b66bba429345
来源:牛客网

这是明显的TCP系列问题。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。
其中ACK报文是用来应答的,SYN报文是用来同步的。
但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,
所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。
只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
首先补充:MSL是TCP报文里面最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
或者换一种更舒服的解释方法:
1)、由于客户端A最后一个ACK可能会丢失,这样B服务端就无法正常进入CLOSED状态。于是B会重传请求释放的报文,而此时A如果已经关闭了,那就收不到B的重传请求,就会导致B不能正常释放。而如果A还在等待时间内,就会收到B的重传,然后进行应答,这样B就可以进入CLOSED状态了。
2)、在这2MSL等待时间里面,本次连接的所有的报文都已经从网络中消失,从而不会出现在下次连接中。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。
服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,
若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
【问题5】TCP最后一次ACK包没有送到就开始传输数据包,会发生什么?
服务端不会接收数据包,还会返回客户端一个RST包,也就是异常包。
dp首部字段有8个字节,包括2字节的源端口号,2字节的目的端口号,2字节的包长度,2字节校验和,tcp首部字段20个字节
私有地址
链接:https://www.nowcoder.com/questionTerminal/d2b4d609f8194ff5b397ae25bfb7ba27
来源:牛客网
A类地址中的私有地址和保留地址:
①10.0.0.0到10.255.255.255是私有地址(所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址)。
② 127.0.0.0到127.255.255.255是保留地址,用做循环测试用的。
B类地址的私有地址和保留地址
① 172.16.0.0到172.31.255.255是私有地址
②169.254.0.0到169.254.255.255是保留地址。
C类地址中的私有地址:
192.168.0.0到192.168.255.255是私有地址
对滑动窗口不正确的描述是:
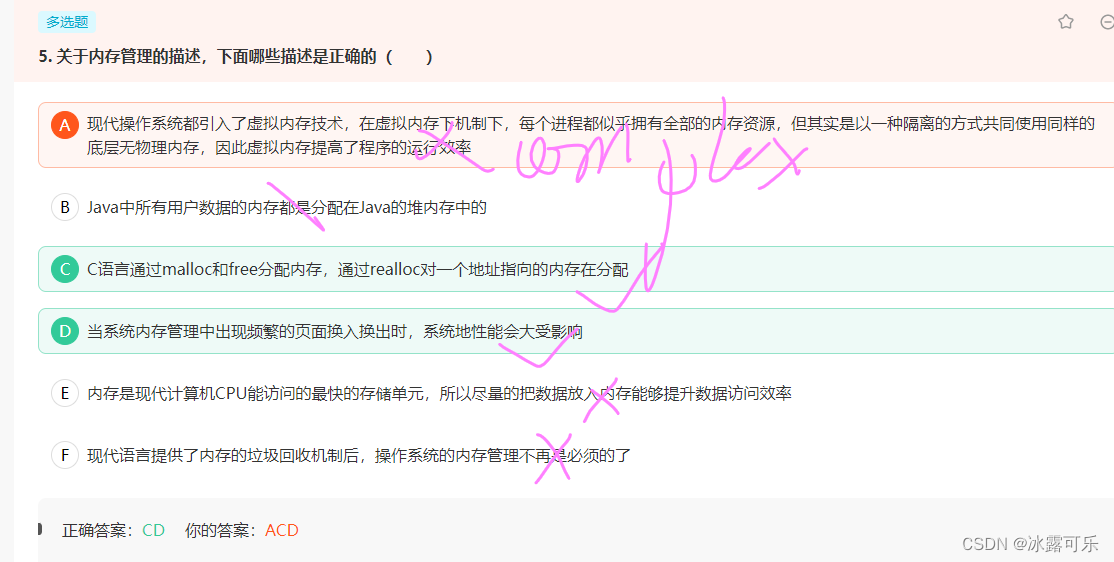
虚拟内存只是将部分数据调入内存运行,其余留在外存,所以内存可以装更多数据,这样就显得内存扩大了不少。于是就存在内外存频繁换进换出数据的可能,这无疑增大了系统开销,降低系统效率。
操作系统的进程控制块。PCB
链接:https://www.nowcoder.com/questionTerminal/0608e50a102548c392338026e6903fa6
来源:牛客网
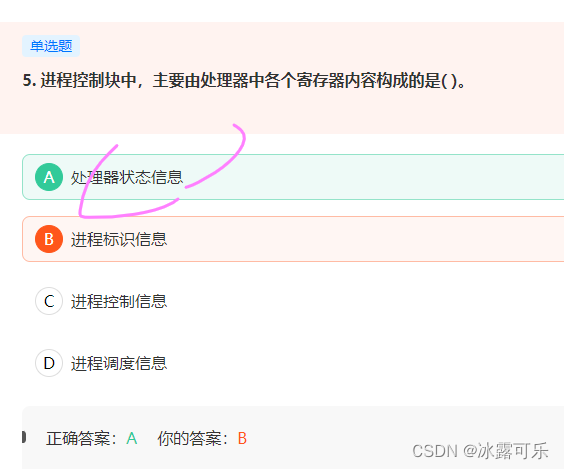
考察操作系统的进程控制块。
在进程控制块中,主要包括4方面用于描述和控制进程运行的信息,
分别是进程标识符信息、处理机状态信息、进程调度信息和进程控制信息。
其中,处理机状态信息主要是由处理机各种寄存器中的内容所组成。
处理机在运行时,许多信息新放在寄存器中,当处理机被中断时,所有这些信息都必须保存在被中断进程的PCB中,以便在该进程重新执行时,能从断点继续执行。
因此在进程控制块中,主要由处理器中寄存器内容构成的是处理器状态信息,因此本题选A。
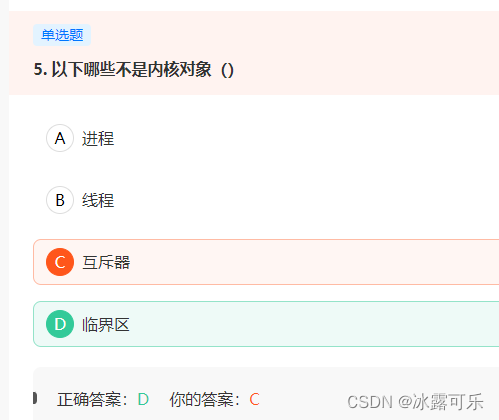
临界区是资源对象,只能被一个进程访问,不是内核对象
gg
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。