文章目录
- 摘要
- 1、简介
- 2 问题的表述和挑战
- 3 标准
- 3.1 数据集
- 3.2 评价标准
- 4 行人属性识别的常规流程
- 4.1 多任务学习
- 4.2 多标签学习
- 5 深度神经网络
🐇🐇🐇🐇🐇🐇 🐇 欢迎阅读 【AI浩】 的博客🐇 👍 阅读完毕,可以点点小手赞一下👍 🌻 发现错误,直接评论区中指正吧🌻 📆 这是一篇研究行人属性识别综述论文📆 💯论文链接: Pedestrian Attribute Recognition: A Survey💯
摘要
行人属性识别在视频监控中起着重要作用,是计算机视觉领域的一项重要任务。已经提出了许多算法来处理这个任务。本文的目的是回顾现有的使用传统方法或基于深度学习网络的工作。首先,介绍了行人属性识别研究的背景,包括行人属性的基本概念和面临的挑战;其次,介绍了现有的基准,包括流行的数据集和评估标准;然后,分析了多任务学习和多标记学习的概念,并解释了这两种学习算法与行人属性识别之间的关系;还回顾了一些在深度学习社区中广泛应用的流行网络架构。第四,分析了当前流行的解决方案,如属性组、基于部件等;第五,展示了一些考虑行人属性的应用,取得了较好的效果。最后进行总结,并给出了行人属性识别未来可能的研究方向。本文的项目页面可以在以下网站找到:
https://sites.google.com/view/ahu-pedestrianattributes/。

1、简介
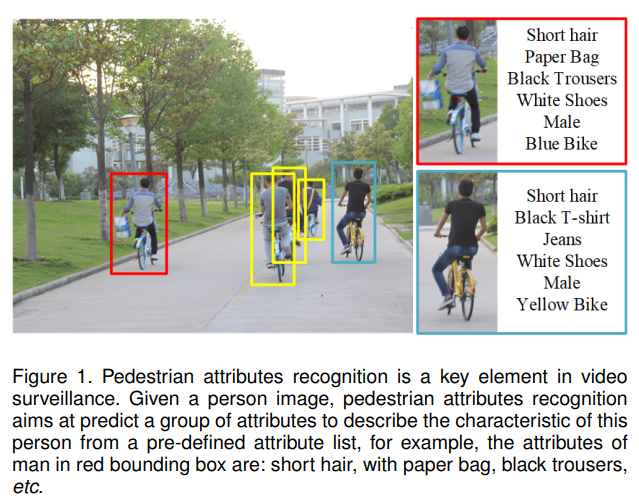
行人属性是一种可搜索的语义信息,可应用于行人再识别、人脸验证和身份识别等领域。行人属性识别(Pedestrian attributes recognition, PAR)旨在挖掘给定行人图像时目标人物的属性,如图1所示。与HOG、LBP或深度特征等底层特征不同,属性可以看作是高层语义信息,对视点变化和观察条件多样性具有更强的鲁棒性。因此,计算机视觉中的许多任务都将属性信息融入到算法中以获得更好的性能,如行人识别、行人检测等。然而,由于视角变化、低光照、低分辨率等具有挑战性的因素,行人属性识别仍然是一个尚未解决的问题。
传统的行人属性识别方法通常从手工特征、强大的分类器或属性关系的角度来开发鲁棒的特征表示。一些里程碑事件包括HOG[1]、SIFT[2]、SVM[3]或CRF模型[4]。然而,大规模的基准测试结果表明,这些传统算法的性能还远远不能满足实际应用的要求。
在过去的几年中,深度学习通过多层非线性变换在自动特征提取方面取得了令人印象深刻的成绩,特别是在计算机视觉、语音识别和自然语言处理方面。基于这些突破,已经提出了几种基于深度学习的属性识别算法,如[5][6][7][8][9][10][11][12][13][14][15][16][17][18][19][20][21][22][23][25][26][27][28][29][30][31][32][33]。
虽然已经有很多论文提出,但至今还没有工作对这些属性识别算法进行详细的综述、全面的评价和深入的分析。文中总结了现有的行人属性识别工作,包括传统方法和流行的基于深度学习的算法,以更好地理解该方向,并帮助其他研究人员快速捕捉主要流程和最新研究前沿。具体而言,本文试图解决以下几个重要问题:(1)传统和基于深度学习的行人属性识别算法之间的联系和区别是什么?从不同的分类规则分析传统和基于深度学习的算法,如基于部件、基于组或端到端学习;(2)行人属性如何帮助其他相关的计算机视觉任务?还回顾了一些由行人属性引导的计算机视觉任务,如行人再识别、目标检测、行人跟踪等,以充分证明该方法在其他许多相关任务中的有效性和广泛应用;(3)如何更好地利用深度网络进行行人属性识别,属性识别的未来发展方向是什么?通过评估现有的行人属性识别算法和一些排名靠前的基线方法,得出了一些有用的结论,并提出了一些可能的研究方向。
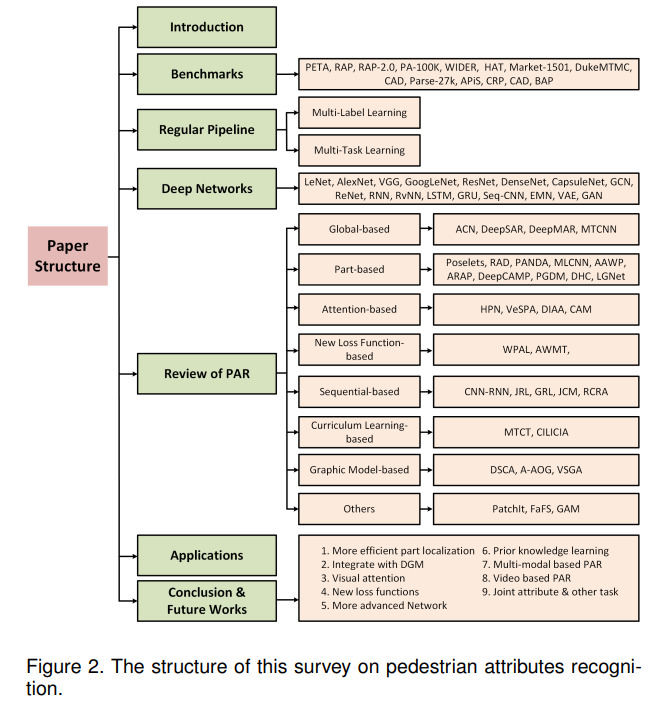
本文的其余部分组织如下。在第2节中,我们简要介绍了行人属性识别的问题表述和一些具有挑战性的因素。在第3节中,我们列出了这项任务的一些流行基准,并报告了基准方法的相应识别性能。然后,从不同的类别回顾了第4节和第6节中的现有方法。将这些方法分为8个领域,包括:基于全局的、基于局部部件的、基于视觉注意的、基于序列预测的、基于新设计的损失函数的、基于课程学习的、基于图模型的和其他算法。在第7节中,我们将展示一些示例,这些示例可以将属性纳入考虑,并取得更好的性能。最后,在第8节对全文进行了总结,并提出了该方向可能的研究方向。为了更好地可视化和理解本文的结构,我们给出了如图2所示的图。
2 问题的表述和挑战
给定一个人物图像 I \mathcal{I} I,行人属性识别旨在从预定义的属性列表 A = { a 1 , a 2 , … , a L } \mathcal{A}=\left\{a_{1}, a_{2}, \ldots, a_{L}\right\} A={a1,a2,…,aL}中预测出一组用于描述该人物特征的属性 a i a_i ai,如图1所示。这一任务可以用不同的方法来处理,如多标签分类、二分类等,已经提出了许多算法和基准。然而,由于属性类别的类内差异较大(外观多样性和外观模糊性[34]),这项任务仍然具有挑战性。我们列出可能明显影响最终识别性能的挑战性因素如下(见图3):
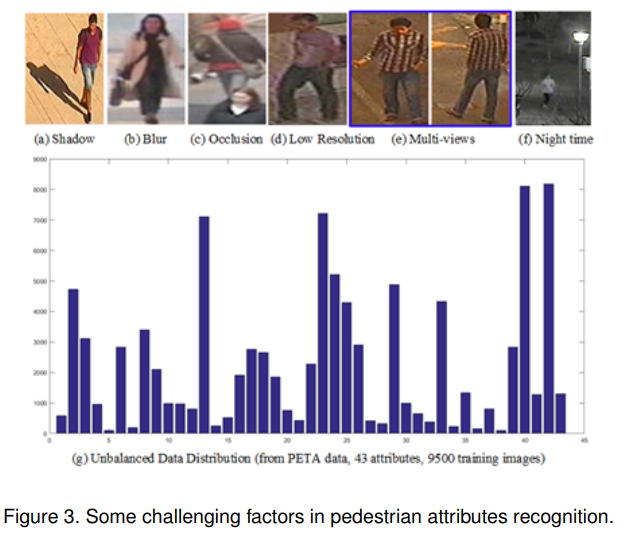
多视角。在许多计算机视觉任务中,相机从不同角度拍摄的图像会导致视点问题。由于人的身体不是刚性的,这进一步使得人的属性识别更加复杂。
遮挡。人体的一部分被他人或物体遮挡会增加人体属性识别的难度。因为被遮挡部分引入的像素值可能会使模型混淆,导致错误的预测。
数据分布不均衡。每个人具有不同的属性,属性的数量是可变的,导致数据分布不平衡。众所周知,现有的机器学习算法在这些数据集上表现不佳。
低分辨率。在实际应用场景中,由于高质量相机价格昂贵,导致图像分辨率较低。因此,需要在这种环境下进行人物属性识别。
光照。图像可以在24小时内的任何时间拍摄。因此,不同时间的光照条件可能不同。阴影也可能在人物图像中,而在夜间拍摄的图像可能完全无效。
模糊。当人在运动时,相机拍摄到的图像可能会模糊。在这种情况下,如何正确识别行人属性是一项非常具有挑战性的任务。
3 标准
与计算机视觉中的其他任务不同,对于行人属性识别,数据集的标注包含不同层次的标签。将发型和颜色、帽子、玻璃等作为特定的底层属性,对应图像的不同区域;将性别、方向、年龄等抽象概念作为高层属性,不对应图像的特定区域;此外,人体属性识别一般受到视角、遮挡、部位等环境或上下文因素的严重影响,为了方便研究,一些数据集提供了视角、部位边界框、遮挡等属性。
通过回顾近年来的相关工作,发现并总结了几个用于行人属性识别研究的数据集,包括PETA[34]、RAP[35]、RAP-2.0[36]、PA-100K[18]、WIDER[16]、Market-1501[37]、DukeMTMC[37]、Clothing属性数据集[38]、parse27k[5][39]、APiS[40]、HAT[41]、Berkeley-Attributes of People数据集[8]和CRP数据集[42]。由于篇幅有限,这些数据集的属性标签的详细信息可以在我们的项目页面中找到。
3.1 数据集
PETA数据集[34] PETA数据集由10个用于研究行人再识别的公开小规模数据集构建而成。该数据集由19000张图像组成,分辨率从17×39到169×365像素不等。这19000张图像包含8705个人,每个人标注了61个二值属性和4个多类属性,随机分为9500张用于训练,1900张用于验证,7600张用于测试。一个显著的限制是,通过随机选择一个样本图像,PETA数据集中的一个人的样本只被标注一次,因此具有相同的标注属性,即使其中一些可能不可见,而其他一些属性则被忽略。虽然这种方法有一定的合理性,但是对于视觉感知来说不是很合适。
PARSE-27K[5], [39] PARSE-27K数据集来自城市环境中移动摄像机拍摄的8个不同长度的视频序列。每15帧序列由DPM行人检测器[48]处理;它包含27,000名行人,并分为训练(50%)、验证(25%)和测试(25%)三个部分。每个样本被人工标注了10个属性标签,其中包括8个二元属性,如“是男?”左肩上有包吗?两个方向属性分别离散化4和8。在PARSE-27K数据集中,由于遮挡、图像边界或任何其他原因无法确定的属性称为N/A标签。
RAP[35] RAP数据集从真实的室内监控场景中采集,选取26个摄像头获取图像,包含41585个样本,分辨率从36×92到344×554,其中有33268张图像用于训练,其余图像用于测试。为该数据集的每个图像分配了72个细粒度属性(69个二进制属性和3个多类属性)。三个环境和上下文因素,即,视角,遮挡样式和身体部位,都有明确的注释。考虑6个部分(时空信息、全身属性、配饰、姿态动作、遮挡和部位属性)进行属性标注。
RAP- 2.0 [36] RAP-2.0数据集来自室内购物中心的真实高清(1280 × 720)监控网络,所有图像由25个摄像机场景捕获。该数据集包含84928张图像(2589个人物身份),分辨率从33 × 81到415 × 583。该数据集中的每个图像都有6种类型的标签,与RAP数据集相同,具有72个属性标签。所有样本分为三个部分,其中50957用于训练,16986用于验证,16985用于测试。
HAT数据集[41] HAT数据集源自流行的图像共享网站Flickr。该数据集包含9344个样本,其中用于训练、验证和测试的图像分别为3500、3500和2344张。这个数据集中的每个图像都有27个属性,并且在姿势(站立、坐着、跑步、转身等)、不同年龄(婴儿、青少年、青年、中年、老年人等)、穿着不同的衣服(t恤、西装、沙滩服、短裤等)和配饰(太阳镜、包等)方面显示了相当大的变化。
APiS数据集[40] APiS数据集来自四个来源:KITTI[44]数据集,CBCL街景45数据集,INRIA[1]数据库和SVS数据集(火车站监控视频序列)。使用行人检测方法[49]自动定位候选行人区域,删除误报和过小图像,最终得到3661幅图像,每张图像高度大于90像素,宽度大于35像素。对每幅图像标注"男性"、"长发"等11个二值属性和上半身颜色、下半身颜色等2个多值属性。“二义性”表示对应属性是否具有不确定性。该数据集被分成5个大小相等的子集,使用5折交叉验证来评估性能,并进一步平均5折中的5个结果以生成单个性能报告。
Berkeley-Attributes of People 数据集 BAP[8]该数据集来自H3D[46]数据集和PASCAL VOC 2010[47]训练和验证数据集。对于person类别,PASCAL中使用的低分辨率版本被Flickr上的全分辨率版本取代。所有图像被分割为2003张训练图像,2010张验证图像和4022张测试图像,确保不同集的裁剪图像没有来自同一源图像,并保持每个集中H3D和PASCAL图像的平衡分布。每张图像都标注了9个属性。如果5个标注者中至少有4人同意标签的值,则标签被认为是基本真理。当无法确定某个属性是否存在时,将其标注为“未指定”。
PA-100K[18] PA-100K数据集由598个真实的户外监控摄像头拍摄的图像构建,包含10万幅行人图像,分辨率从50 × 100到758 × 454,是目前最大的行人属性识别数据集。整个数据集按8:1:1的比例随机分为训练集、验证集和测试集。该数据集中的每个图像都被标记了26个属性,标签为0或1,分别表示相应属性的存在或不存在。
WIDER[16] WIDER数据集来自于50574张WIDER images[43],这些图像通常包含许多人和巨大的人类变化,共选择了13789张图像。每个图像都标注了边界框,但在人群图像中不超过20人(最高分辨率),因此总共有57524个框,平均每张图像有4+个框。每个人都有14个不同的属性,总共有805336个标签。该数据集分为5509张训练图像,1362张验证图像和6918张测试图像。
Market1501-attribute [50] 数据集Market-1501由清华大学超市前的6个摄像头采集。在这个数据集中有1501个身份和32,668个注释边界框。每个标注的身份存在于至少两个摄像头中。该数据集分为751个训练身份和750个测试身份,分别对应12936和19732张图像。在身份级别对属性进行标注,该数据集中的每个图像都被标注了27个属性。请注意,虽然下半身服装和上半身服装有7和8个属性,但只有一种颜色标记为yes。
DukeMTMC-attribute [50] dukemtmattribute数据集中的图像来自杜克大学。在DukeMTMC-attribute数据集中有1812个identity和34183个带注释的边界框。该数据集包含702个用于训练的身份和1110个用于测试的身份,分别对应于16522和17661张图像。在身份层对属性进行标注,该数据集中的每个图像都被标注了23个属性。
CRP [42] CRP数据集中的每个图像都是在野外捕获的,行人是从移动的车辆上“在野外”记录的。CRP数据集包含7个视频和27454个行人边界框。每位行人均被标记了四种属性:年龄(5类)、性别(2类)、体重(3类)和服装类型(4类)。该数据集分为包含4个视频的训练/验证集,其余3个视频形成测试集。
Clothing Attributes 数据集 CAD[28]服装属性数据集是从裁缝师y和Flickr上收集的。该数据集包含1856张图像,其中26个真实服装属性是使用Amazon Mechanical Turk收集的。所有标签按照图片1到1856的顺序排列。有些标签条目是“NaN”,这意味着6个人类工人在这个服装属性上无法达成一致。共有26个属性,包括23个二类属性(6个款式属性、11个颜色属性和6个杂项属性)和3个多类属性(袖长、领口形状和服装类别)。该数据集通过leave-1-out分割用于训练和测试。
| Dataset | #Pedestrians | #Attributes | Source | Project Page |
|---|---|---|---|---|
| PETA [34] | 19000 | 61 binary and 4 multi-class attributes | outdoor & indoor | http://mmlab.ie.cuhk.edu.hk/projects/PETA.html |
| RAP [35] | 41585 | 69 binary and 3 multi-class attributes | indoor | http://rap.idealtest.org/ |
| RAP-2.0 [36] | 84928 | 69 binary and 3 multi-class attributes | indoor | https://drive.google.com/file/d/1hoPIB5NJKf3YGMvLFZnIYG5JDcZTxHph/view |
| PA-100K [18] | 100000 | 26 binary attributes | outdoor | https://drive.google.com/drive/folders/0B5Ra3JsEOyOUlhKM0VPZ1ZWR2M |
| WIDER [16] | 13789 | 14 binary attributes | WIDER images [43] | http://mmlab.ie.cuhk.edu.hk/projects/WIDERAttribute.html |
| Market-1501 [37] | 32668 | 26 binary and 1 multi-class attributes | outdoor | https://github.com/vana77/Market-1501 Attribute |
| DukeMTMC [37] | 34183 | 23 binary attributes | outdoor | https://github.com/vana77/DukeMTMC-attribute |
| PARSE-27K [5] [39] | 27000 | 8 binary and 2 multi-class orientation attributes | outdoor | https://www.vision.rwth-aachen.de/page/parse27k |
| APiS [40] | 3661 | 11 binary and 2 multi-class attributes | KITTI [44] ,CBCL Street Scenes [45],INRIA [1] and SVS | http://www.cbsr.ia.ac.cn/english/APiS-1.0-Database.html |
| HAT [41] | 9344 | 27 binary attributes | image site Flickr | https://jurie.users.greyc.fr/datasets/hat.html |
| CRP [42] | 27454 | 1 binary attributes and 13 multi-class attributes | outdoor | http://www.vision.caltech.edu/∼dhall/projects/CRP/ |
| CAD [38] | 1856 | 23 binary attributes and 3 multi-class attributes | image site Sartorialist∗ and Flickr | https://purl.stanford.edu/tb980qz1002 |
| BAP [8] | 8035 | 9 binary attributes | H3D [46] dataset PASCAL VOC 2010 [47] | https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/shape/poselets/ |
3.2 评价标准
zhu等人[40]通过召回率和假阳率两个指标计算受试者工作特征(Receiver Operating Characteristic, ROC)和平均ROC曲线下面积(Area Under the average ROC Curve, AUC)来评估每个属性分类的性能。召回率(recall rate)是正确检测到的阳性样本占正样本总数的比例,假阳性率(false positive rate)是错误分类的阴性样本占负样本总数的比例。在不同的阈值设置下,可以通过绘制召回率和假阳性率绘制ROC曲线。此外,zhu 等人[40]还使用了平均ROC曲线下面积(Area Under the average ROC Curve, AUC)来进行更清晰的性能对比。
Deng等人在[34]中采用平均准确率(mA)来评价属性识别算法。对于每个属性,mA分别计算正样本和负样本的分类准确率,得到它们的平均值作为该属性的识别结果。最后,对所有属性进行平均得到识别率。评价标准可以通过下式计算:
m
A
=
1
2
N
∑
i
=
1
L
(
T
P
i
P
i
+
T
N
i
N
i
)
(1)
m A=\frac{1}{2 N} \sum_{i=1}^{L}\left(\frac{T P_{i}}{P_{i}}+\frac{T N_{i}}{N_{i}}\right) \tag{1}
mA=2N1i=1∑L(PiTPi+NiTNi)(1)
其中
L
L
L是属性的数量。
T
P
i
TP_i
TPi和
T
N
i
TN_i
TNi分别是正确预测的正例和负例的数量,
P
i
P_i
Pi和
N
i
N_i
Ni分别是正例和负例的数量。
上述评价准则独立地对待每个属性,忽略了多属性识别问题中自然存在的属性间相关性。Li 等人[35]将上述解决方案称为基于标签的评价准则,并提出使用基于实例的评价准则,其灵感来自于基于实例的评价能够更好地捕捉对给定行人图像预测的一致性[51]。目前广泛使用的基于实例的评价标准包括四个指标:准确率、精确率、召回率和F1值,定义如下:
Acc
exam
=
1
N
∑
i
=
1
N
∣
Y
i
∩
f
(
x
i
)
∣
∣
Y
i
∪
f
(
x
i
)
∣
(2)
\text { Acc }_{\text {exam }}=\frac{1}{N} \sum_{i=1}^{N} \frac{\left|Y_{i} \cap f\left(x_{i}\right)\right|}{\left|Y_{i} \cup f\left(x_{i}\right)\right|}\tag{2}
Acc exam =N1i=1∑N∣Yi∪f(xi)∣∣Yi∩f(xi)∣(2)
Prex exam = 1 2 N ∑ i = 1 N ∣ Y i ∩ f ( x i ) ∣ ∣ f ( x i ) ∣ (3) \text { Prex }_{\text {exam }}=\frac{1}{2 N} \sum_{i=1}^{N} \frac{\left|Y_{i} \cap f\left(x_{i}\right)\right|}{\left|f\left(x_{i}\right)\right|} \tag{3} Prex exam =2N1i=1∑N∣f(xi)∣∣Yi∩f(xi)∣(3)
Rec exam = 1 2 N ∑ i = 1 N ∣ Y i ∩ f ( x i ) ∣ ∣ Y i ∣ (4) \operatorname{Rec}_{\text {exam }}=\frac{1}{2 N} \sum_{i=1}^{N} \frac{\left|Y_{i} \cap f\left(x_{i}\right)\right|}{\left|Y_{i}\right|} \tag{4} Recexam =2N1i=1∑N∣Yi∣∣Yi∩f(xi)∣(4)
F
1
=
2
∗
Prec
exam
∗
Rec
exam
Prec
exam
+
Rec
exam
(5)
F 1=\frac{2 * \text { Prec }_{\text {exam }} * \text { Rec }_{\text {exam }}}{\text { Prec }_{\text {exam }}+\text { Rec }_{\text {exam }}} \tag{5}
F1= Prec exam + Rec exam 2∗ Prec exam ∗ Rec exam (5)
其中
N
N
N是示例的数量,
Y
i
Y_i
Yi是第i个示例的真实正标签,
f
(
x
)
f (x)
f(x)返回第i个示例的预测正标签。
∣
⋅
∣
|\cdot|
∣⋅∣表示集合的势。
4 行人属性识别的常规流程
实际视频监控中的行人属性可能包含几十个类别,正如许多流行的基准所定义的那样。独立地学习每个属性是一种直观的想法,但会造成冗余和低效。因此,研究者倾向于在一个模型中估计所有的属性,将每个属性估计视为一个任务。由于多任务学习的优雅和高效,它受到越来越多的关注。另一方面,该模型将给定的行人图像作为输入,输出相应的属性。行人属性识别也属于多标记学习领域。在本节中,我们将从多标签学习和多任务学习两个方面简要介绍用于行人属性识别的常规流程。
4.1 多任务学习
针对机器学习领域中的一项特定任务,传统的解决方案是设计一个评价标准,提取相关的特征描述符并构建单个或集成模型。利用特征描述子对模型参数进行优化,根据评价标准达到最佳效果,提高整体性能。该流水线在单个任务上可能取得令人满意的结果,但忽略了其他可能进一步提高评价标准的任务。
在现实世界中,许多事情都是相互关联的。一项任务的学习可能依赖或限制其他任务。即使一个任务被分解,但子任务之间仍然存在一定的相关性。独立处理单个任务容易忽略这种相关性,从而导致最终性能的提升可能遇到瓶颈。具体来说,行人属性之间是相互关联的,如性别、服装样式等。另一方面,监督学习需要大量的标注训练数据,且难以收集。因此,最流行的方法是联合学习多任务以挖掘共享的特征表示。它被广泛应用于自然语言处理、计算机视觉等多个领域。
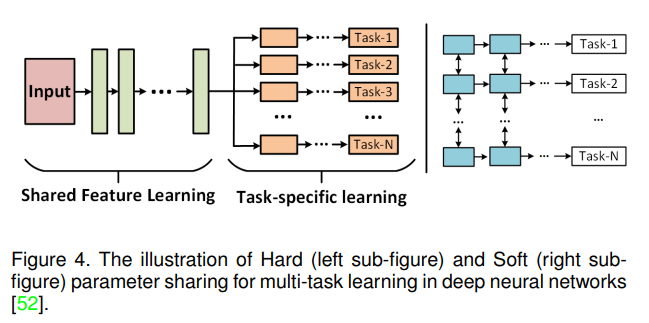
随着深度学习的发展,通过融合多任务学习和深度神经网络,许多高效的算法被提出。为了充分理解MTL高效背后的原因,我们需要分析它的具体机制。根据Ruder等人[52]的研究,其原因可以归结为以下五点:隐式数据增强、注意力聚焦、窃听、表示偏差、正则化。关于这些原因的详细信息,请参阅他们的原稿。一般来说,基于深度学习的多任务学习有两种方法,即硬参数共享和软参数共享。硬参数共享通常将浅层作为共享层来学习多个任务的共同特征表示,而将高层作为特定任务的层来学习更具判别性的模式。该模式是深度学习社区中最流行的框架。硬参数共享的说明可以在图4(左子图)中找到。对于软参数共享的多任务学习(如图4所示(右子图)),它们独立训练每个任务,但通过引入正则化约束,如L2距离[53]和迹范数[54],使不同任务之间的参数相似。
因此,将多任务学习应用于行人属性识别较为直观,基于该框架也提出了许多算法[5][6][7][8][9][10][11]。
4.2 多标签学习
对于多标签分类算法,可以归纳为以下三种学习策略,如[51]所述:1)一阶策略是最简单的形式,可以直接将多类问题转化为多个二分类问题;虽然取得了较好的效率,但该策略无法对多标签之间的相关性进行建模,导致泛型差;2)二阶策略,考虑了每个标签对之间的相关性,取得了比一阶策略更好的性能;3)高阶策略,考虑所有标签之间的关系,通过建模每个标签对其他标签的影响来实现多标签识别系统。该方法具有通用性,但复杂度高,在处理大规模图像分类任务时效果不佳。因此,通常采用以下两种方法进行模型构建:问题转换和算法自适应。图5展示了一些代表性的多标记学习算法,如[51]所示。
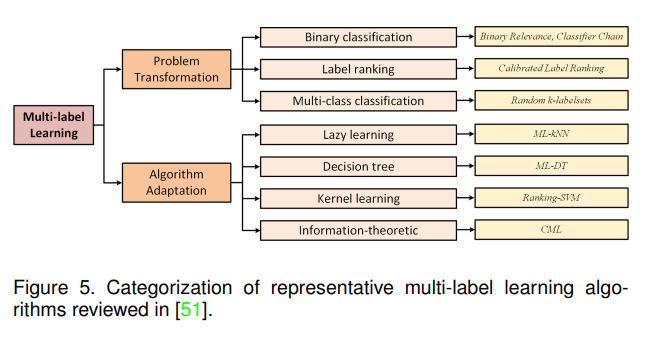
为了简化使用问题转换的多标签分类问题,可以采用现有的广泛使用的框架。具有代表性的算法有:1)二进制相关算法[55],该算法直接将多标记问题转化为多个二分类问题,最后将所有二分类器融合在一起进行多标签分类。该方法简单直观,但忽略了多个标签之间的相关性;2)分类器链算法[56],该算法的基本思想是将多标记学习问题转化为二分类链问题。每个二分类器都依赖于链中的前一个分类器;3)标记排序算法[57],该算法考虑了成对标记之间的相关性,将多标记学习转化为标记排序问题;4)随机k-标签集算法[58],将多标签分类问题转化为多个分类问题的集合,每个集合中的分类任务是一个多类分类器。而多类分类器需要学习的类别是所有类别的子集。
不同于问题转换,算法自适应直接改进现有算法并应用于多标签分类问题,包括:1)多标签k近邻(multi-label k-nearest neighbour, ML-kNN[59]),采用kNN技术处理多类别数据,并利用最大后验概率(maximum a posteriori, MAP)规则,根据邻居节点所蕴含的标记信息进行推理预测。2)多标签决策树(ML-DT[60])尝试用决策树来处理多标签数据,利用基于多标签熵的信息增益准则递归地构建决策树。3)排序支持向量机(ranking support vector machine, Rank-SVM[61])采用最大间隔策略来处理这个问题,其中一组线性分类器被优化以最小化经验排序损失,并能够使用核技巧处理非线性情况。4).集体多标签分类器CML[62]采用最大熵原则来处理多标签任务,其中标签之间的相关性被编码为结果分布必须满足的约束。
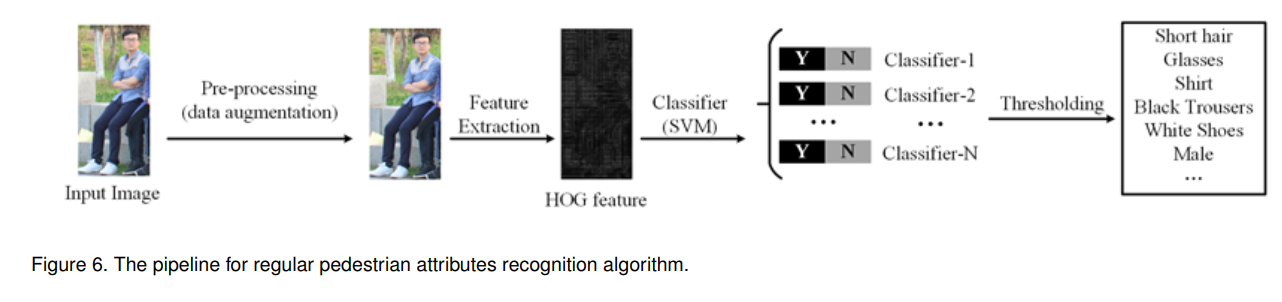
多标签行人属性识别的规则流程如图6所示。机器学习模型将人体图像(可选预处理)作为输入,并提取其特征表示(如HOG、SIFT或深度特征)。常用的预处理技术有归一化、随机裁剪、白化处理等。它旨在提高输入图像的质量,抑制不必要的变形或增强对后续操作重要的图像特征,以提高训练模型的通用性。之后,他们根据提取的特征训练一个分类器来预测相应的属性。现有的基于深度学习的PAR算法能够以端到端的方式联合学习特征表示和分类器,显著提高了最终的识别性能。
5 深度神经网络
在本小节中,我们将回顾深度学习社区中一些知名的网络架构,它们已经或可能用于行人属性识别任务。
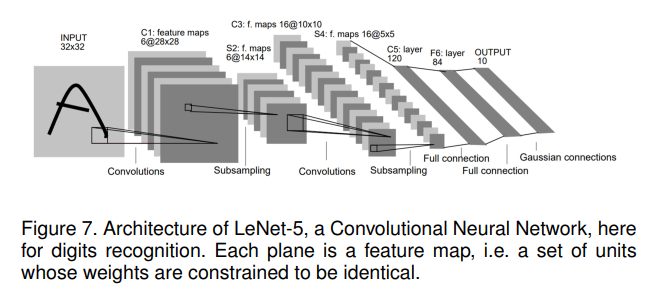
LeNet[63]最早由Yann LeCun等人在1998年提出。它最初是为手写体和机印字符识别而设计的,如网站z所示。LeNet的架构如图7所示。以32 × 32的单通道图像作为输入,使用2组卷积+最大池化层来提取其特征。分类由2个全连接层完成,并输出数字的分布。
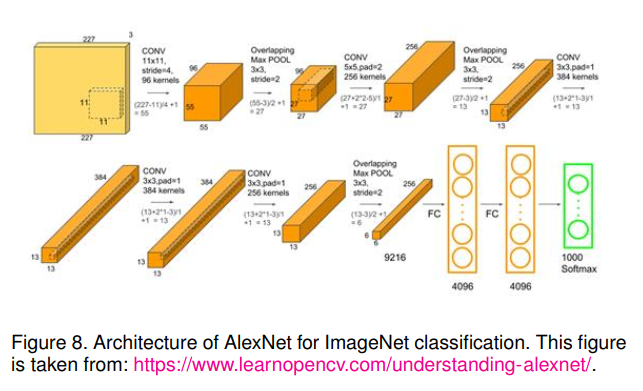
AlexNet[64]是Alex等人在2012年提出的深度学习历史上的一个里程碑,并以84.6%的TOP-5测试精度赢得了ILSVRC-2012。AlexNet比之前用于计算机视觉任务的cnn(如LeNet)大得多。它有6000万个参数和65万个神经元,如图8所示。它由5个卷积层、最大池化层、非线性校正线性单元(ReLUs)、3个全连接层和dropout单元组成。
VGG[65]是牛津大学的视觉几何组(VGG)提出的一种CNN模型。该网络使用了更多的卷积层(16,19层),在ILSVRC-2013上也取得了很好的效果。许多后续的神经网络都遵循这个网络。它首先在第一层使用具有小感受野的卷积层堆栈,而之前的网络都采用具有大感受野的层。较小的感受野可以更大范围地减少参数和更多的非线性,并使学习到的特征更具判别力,也更有效地进行训练。

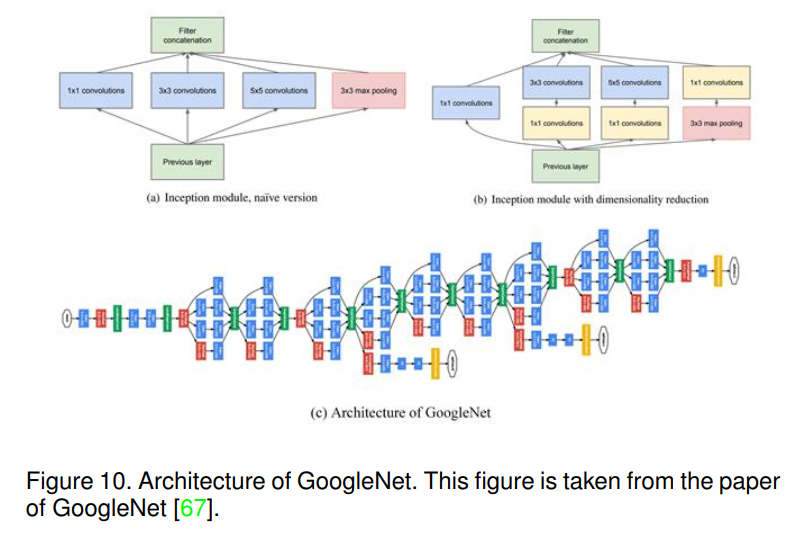
GoogleNet[67]是深度学习社区中的另一种流行的网络架构(22层)。与传统的顺序方式不同,该网络首次引入inception模块的概念,并在ILSVRC-2014竞赛中获胜。详情参见图10。GoogleNet包含一个网络中网络(NiN)层[68],一个池化操作,一个大尺寸的卷积层和一个小尺寸的卷积层。这些层可以并行计算,然后进行1 × 1卷积操作以降低维度。
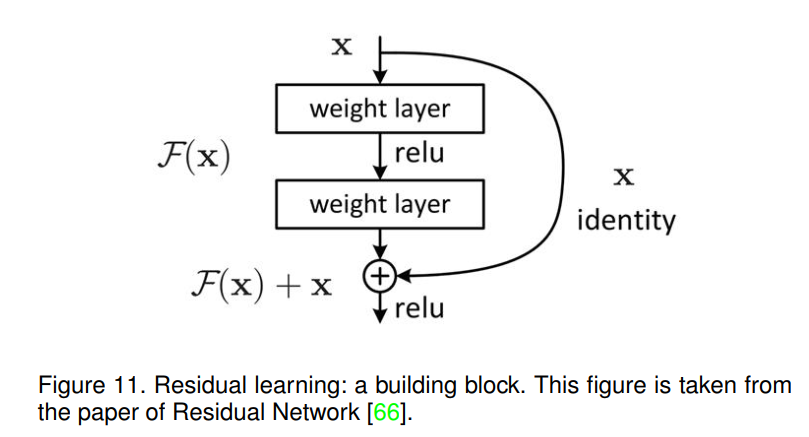
残差网络[66]首先以其超深的架构(超过1k层)而闻名,相比之下,之前的网络相当“浅”。该网络的主要贡献是引入了残差块,如图11所示。这种机制可以通过引入身份跳过连接并将输入复制到下一层来解决训练真正深层架构的问题。该方法可以在很大程度上解决梯度消失问题。
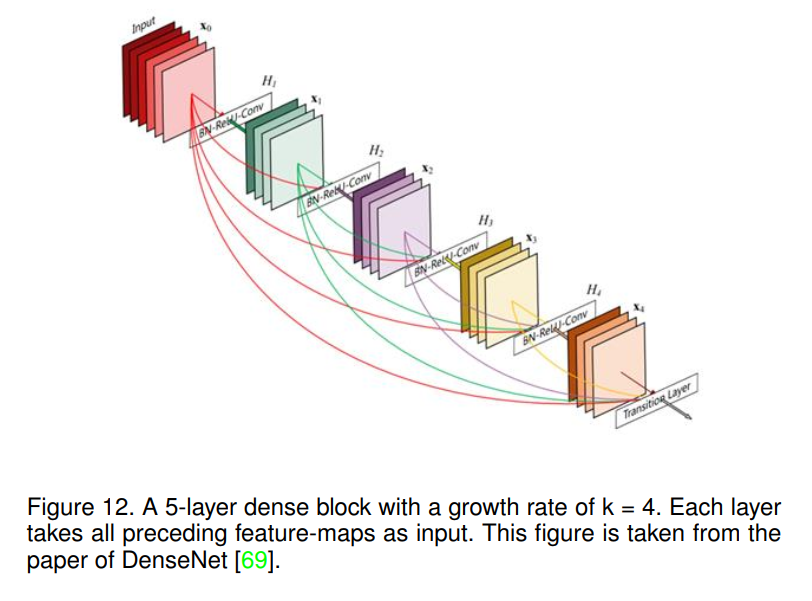
Dense Network[69]是Huang等人在2017年提出的。该网络进一步扩展了残差网络的思想,具有更好的参数效率,DenseNets的一个很大的优势是它们改进了整个网络的信息流和梯度,这使得它们易于训练。每一层都可以直接访问来自损失函数和原始输入信号的梯度,从而产生隐式的深度监督[70]。这有助于训练更深层次的网络架构。
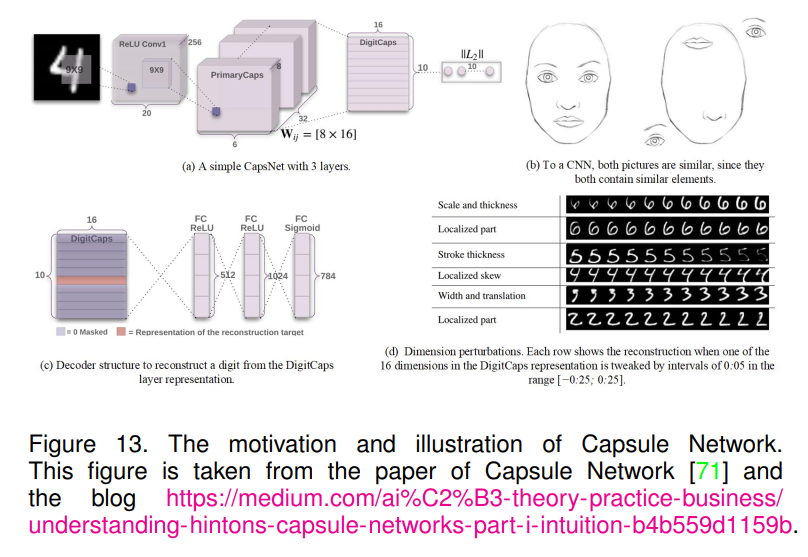
胶囊网络[71][72]是由Hiton等人在2017年提出的,用于处理标准CNN的局限性。众所周知,在标准CNN中使用最大池化层降低了之前卷积层生成的特征图的维度,并使特征学习过程更加高效。如图13 (b)所示,这两幅人脸图像与CNN相似,因为它们都包含相似的元素。然而,由于使用了最大池化层,标准CNN无法捕捉到两幅人脸图像之间的差异。为了解决这个问题,提出了胶囊网络,它放弃了最大池化层,并使用胶囊输出一个向量,而不是每个神经元的值。这使得使用强大的动态路由机制(“routingby-agreement”)可以确保胶囊的输出被发送到上面一层的近似父级。利用边际损失和重建损失对胶囊网络进行训练,验证了其有效性。一些消融研究也表明,每个数字的属性可以通过胶囊网络在输出向量中进行编码。
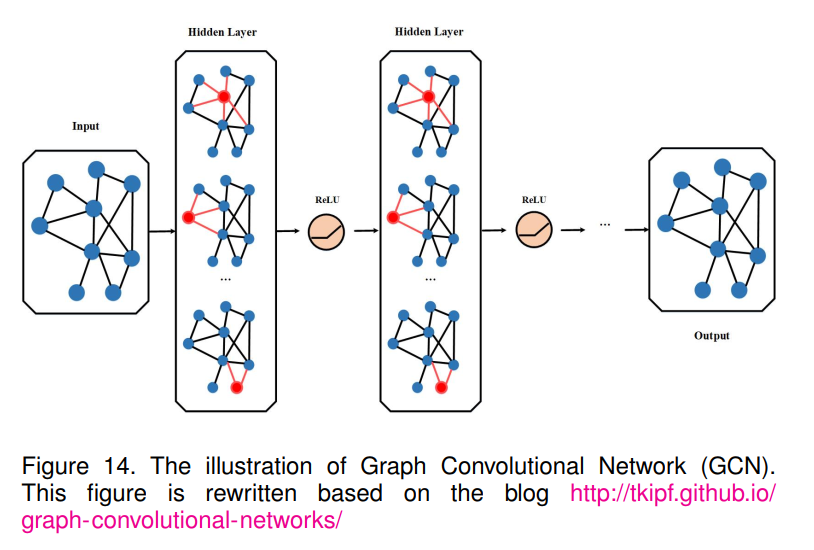
图卷积网络[73]由于图像/视频上的标准卷积操作不能直接用于图结构数据,因此尝试将CNN扩展到非网格数据。GCN的目标是学习图 G = ( V , E ) G = (V,E) G=(V,E)将每个节点i的特征描述 x i x_i xi和邻接矩阵A的代表性描述作为输入,产生节点级输出z。GCN的整体架构如图14所示。
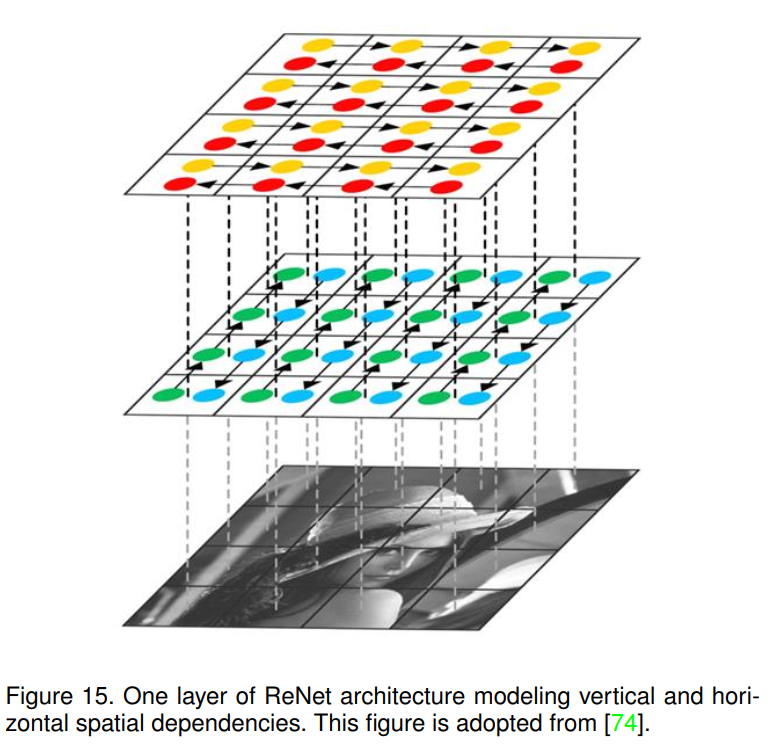
ReNet[74]为了将循环神经网络(RNNs)架构扩展到多维任务,Graves等人[75]提出了一种多维循环神经网络(MDRNN)架构,用d连接替换标准RNNs中的每个单一循环连接,其中d是时空数据维度的数量。基于这种初始方法,Visin el al.[74]提出了ReNet架构,在该架构中,他们一直使用通常的序列rnn,而不是多维rnn。这样,rnn的数量在每一层上就输入图像的维数d (2d)进行线性缩放。在这种方法中,每个卷积层(卷积+池化)被替换为四个rnn,在两个方向上垂直和水平扫描图像,我们可以在图15中看到。
循环神经网络(RNN)。传统的神经网络假设所有的输入和输出都是相互独立的,然而在许多任务中,例如句子翻译,这个假设可能并不成立。循环神经网络(Recurrent Neural Network, RNN)被提出用于处理涉及序列信息的任务。rnn之所以被称为递归,是因为它们对序列中的每个元素执行相同的任务,输出取决于之前的计算。另一种思考rnn的方式是,它们有一种“记忆”,可以捕捉到到目前为止计算的信息。理论上,rnn可以利用任意长的序列中的信息,但在实践中,它们仅限于回溯几步。

引入长短期记忆网络(Long Short-term Memory, LSTM)来解决RNN梯度消失或爆炸的问题。一个LSTM有三个这样的门,用于保护和控制单元状态,即遗忘门,输入门和输出门。具体来说,我们将输入序列表示为
X
=
(
x
1
,
x
2
,
…
,
x
N
)
\mathbf{X}=\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{N}\right)
X=(x1,x2,…,xN)。在每个位置
k
k
k,
k
∈
[
1
,
N
]
k \in [1,N]
k∈[1,N]时,有一组内部向量,包括一个输入门
i
k
i_k
ik、一个遗忘门
f
k
f_k
fk、一个输出门
o
k
o_k
ok和一个存储单元
c
k
c_k
ck。隐藏状态
h
k
h_k
hk可以由所有这些向量计算出来,如下所示:
i
k
=
σ
(
W
i
x
k
+
V
i
h
k
−
1
+
b
i
)
(6)
\mathbf{i}_{k} =\sigma\left(\mathbf{W}^{i} \mathbf{x}_{k}+\mathbf{V}^{i} \mathbf{h}_{k-1}+\mathbf{b}^{i}\right) \tag{6}
ik=σ(Wixk+Vihk−1+bi)(6)
f k = σ ( W f x k + V f h k − 1 + b f ) (7) \mathbf{f}_{k} =\sigma\left(\mathbf{W}^{f} \mathbf{x}_{k}+\mathbf{V}^{f} \mathbf{h}_{k-1}+\mathbf{b}^{f}\right) \tag{7} fk=σ(Wfxk+Vfhk−1+bf)(7)
o k = σ ( W o x k + V o h k − 1 + b o ) (8) \mathbf{o}_{k} =\sigma\left(\mathbf{W}^{o} \mathbf{x}_{k}+\mathbf{V}^{o} \mathbf{h}_{k-1}+\mathbf{b}^{o}\right) \tag{8} ok=σ(Woxk+Vohk−1+bo)(8)
c k = f k ⊙ c k − 1 + i k ⊙ tanh ( W c x k + V c h k − 1 + b c ) (9) \mathbf{c}_{k} =\mathbf{f}_{k} \odot \mathbf{c}_{k-1}+\mathbf{i}_{k} \odot \tanh \left(\mathbf{W}^{c} \mathbf{x}_{k}+\mathbf{V}^{c} \mathbf{h}_{k-1}+\mathbf{b}^{c}\right) \tag{9} ck=fk⊙ck−1+ik⊙tanh(Wcxk+Vchk−1+bc)(9)
h
k
=
o
k
⊙
tanh
(
c
k
)
(10)
\mathbf{h}_{k} =\mathbf{o}_{k} \odot \tanh \left(\mathbf{c}_{k}\right) \tag{10}
hk=ok⊙tanh(ck)(10)
其中σ是sigmoid函数,
⊙
\odot
⊙是两个向量的元素乘,所有的
W
∗
W^∗
W∗、
V
∗
V^∗
V∗、
b
∗
b^∗
b∗都是要学习的权重矩阵和向量。LSTM的详细信息请参见图17 (a)。
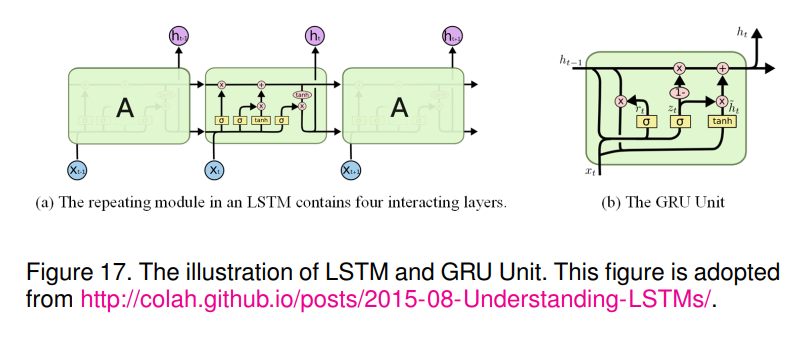
GRU。 LSTM上一个稍微更显著的变化是门控循环单元(Gated Recurrent Unit, GRU),由[76]引入。它将遗忘门和输入门组合成一个更新门。它还合并了单元状态和隐藏状态,并进行了一些其他更改。由此产生的模型比标准LSTM模型更简单,并且越来越受欢迎。详细的GRU单元可以在图17 (b)中找到。
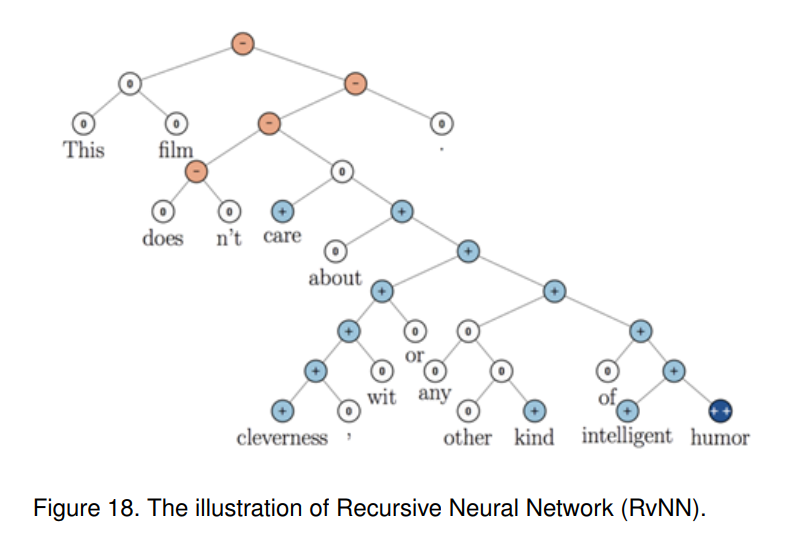
递归神经网络(RvNN)[77]如https://en.wikipedia.org/wiki/Recursive_neural_network中所指出的,递归神经网络是一种深度神经网络,通过在结构化输入上递归地应用相同的权重集来产生对可变大小输入结构的结构化预测,或通过按拓扑顺序遍历给定结构对其进行标量预测。rvnn在学习自然语言处理中的序列和树结构方面取得了成功,主要是基于词向量的短语和句子连续表示。RvNN的示意图如图18所示。
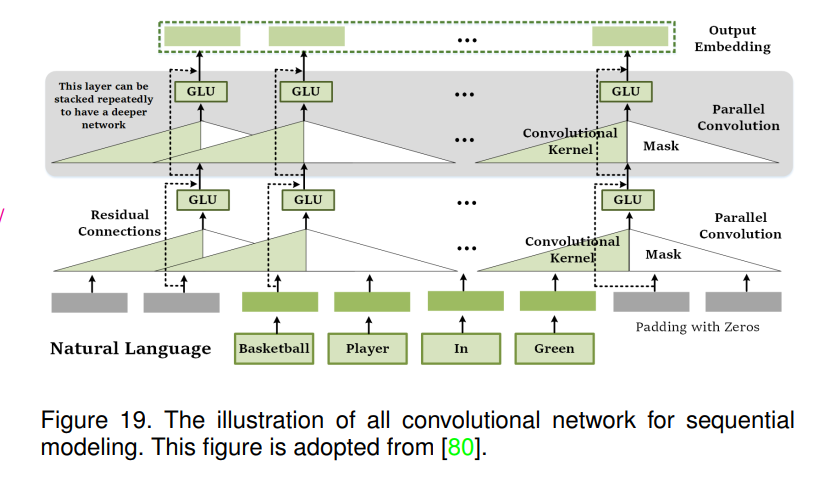
序列CNN。[78],[79]与使用RNN对时间序列输入进行编码的常规工作不同,研究人员还研究CNN以实现更高效的操作。使用序列CNN,可以在训练期间完全并行化所有元素的计算,以更好地利用GPU硬件,并且更容易进行优化,因为非线性的数量是固定的,且与输入长度无关[78]。
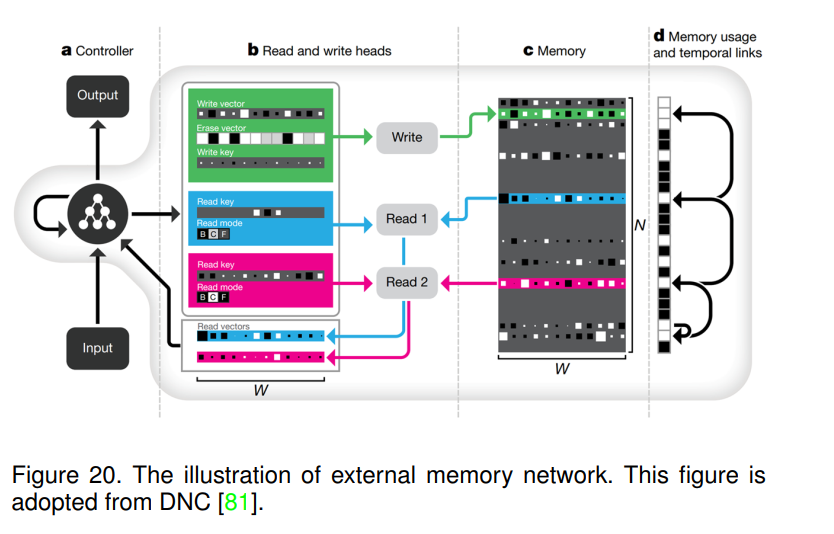
外部记忆网络。[81]视觉注意机制可以看作是将注意力分配到最近看到的输入特征上的一种短期记忆,而外部记忆网络可以通过读写操作提供长期记忆。它被广泛应用于许多应用中,如视觉跟踪[82],视觉问答[83],[84]。
深度生成模型。近年来,深度生成模型取得了很大的发展,并提出了许多流行的算法,如变分自编码器(variational auto-encoder, VAE)[85], GAN (generative adversarial networks, GAN)[86], CGAN (conditional generative adversarial network,条件生成对抗网络)[87]。这三种模型的示意图见图21。文中认为,基于属性的行人图像生成策略可以解决低分辨率、数据分布不平衡的问题,并显著增加训练数据集。