本篇博客基于哈工大发表在IJCAI上的论文:A Survey on Spoken Language Understanding - Recent Advances and New Frontiers。
论文链接
github链接
口语理解(SLU)旨在提取用户查询的语义框架,是面向任务的对话系统的核心组件。本文包括:(1) 新的分类方法:我们为SLU领域提供了一个新的视角,包括单一模型与联合模型、联合模型中的隐式联合建模与显式联合建模、非预训练范式与预训练范式;(2) 新领域:复杂SLU中的一些新兴领域以及相应的挑战;(3) 丰富的开源资源:将相关论文、基线项目和排行榜收集整理在 Awesome-SLU-Survey 上。
一、Introduction
口语理解(SLU)是面向任务的对话系统的核心组件,旨在捕获用户查询的语义。它通常包含两个任务:意图检测和插槽填充。输入一句话,输出包括一个意图类标签和一个插槽标签序列。
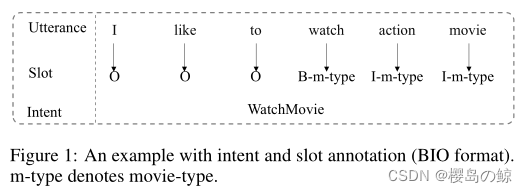
意图检测可以定义为一个句子分类问题(CNN、RNN),槽填充可以作为一种序列标记任务(CRF、RNN、LSTM)。传统的方法将槽填充和意图检测视为两个独立的任务,忽略了两个任务之间的共享知识。从直观上看,意图检测和插槽填充并不是独立的,而是高度联系在一起的。为此,文献中的主要模型采用联合模型来利用两个任务之间的共享知识。
- vanilla multi-task:
A joint model of intent determination and slot filling for spoken language understanding- slot-gated:
Slot-gated modeling for joint slot filling and intent prediction
A self-attentive model with gate mechanism for spoken language understanding- stack-propagation:
A stack-propagation framework with token-level intent detection for spoken language understanding- bi-directional interaction:
A novel bi-directional interrelated model for joint intent detection and slot filling
A co-interactive transformer for joint slot filling and intent detection
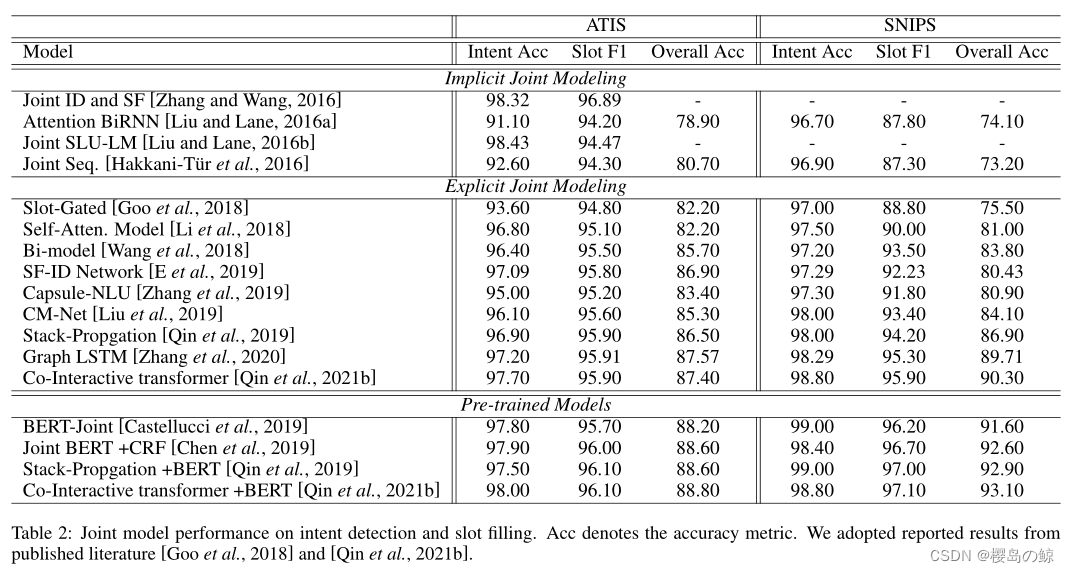
目前在ATIS上Intent Acc和Slot F1超过97%和98%,在SNIPS上超过97%和99%。但是,我们是否完美地完成了SLU任务呢?经过调查发现,目前的主流工作仍然是简单的设置:single domain和single turn,这还远远不能满足一些复杂应用的要求。
二、Background
1. Definition
- Intent Detection
给定输入话语 X = ( x 1 , . . . , x n ) X=(x_1,...,x_n) X=(x1,...,xn),意图检测可以被认为是决定意图标签 o I o^I oI 的句子分类任务,形式为: o I = I D ( X ) . o^I=ID(X). oI=ID(X). - Slot Filling
槽填充可以被看做是产生序列槽 o S = ( o 1 S , . . . , o n s ) o^S=(o^S_1,...,o^s_n) oS=(o1S,...,ons) 的序列标注任务,可以写成: o S = S F ( X ) . o^S=SF(X). oS=SF(X). - Joint Model
联合模型可以同时预测槽序列和意图,具有跨相关任务捕获共享知识的优势,使用: ( o I , o S ) = J M ( X ) . (o^I, o^S)=JM(X). (oI,oS)=JM(X).
2. Dataset
最广泛使用的数据集是 ATIS 和 SNIPS。
- ATIS
The A TIS spoken language systems pilot corpus.
ATIS数据集包含航班、预订的音频记录。有4478个话语用于训练,500个话语用于验证,500个话语用于测试。ATIS训练数据中包含120个槽标签和21种意图类型。 - SNIPS
Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces.
SNIPS是定制意图引擎。有13084个话语用于训练,700个话语用于验证,700个话语用于测试。共有72个槽标签和7种意图类型。
3. Evaluation Metrics
SLU最广泛使用的评估指标是 F1 scores、intent accuracy 和 overall accuracy。
- F1 Scores:
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition.
采用F1分数来评价槽填充的性能,F1分数是精度和召回率之间的调和平均分。当找到精确匹配时,插槽预测被认为是正确的。 - Intent Accuracy:
意图准确度用于评估意图检测的性能,计算正确预测意图的句子的比例。 - Overall Accuracy:
Slot-gated modeling for joint slot filling and intent prediction.
采用整体精度来计算句子中正确预测意图和插槽的句子比例。这个指标同时考虑了意图检测和插槽填充。
三、Taxonomy
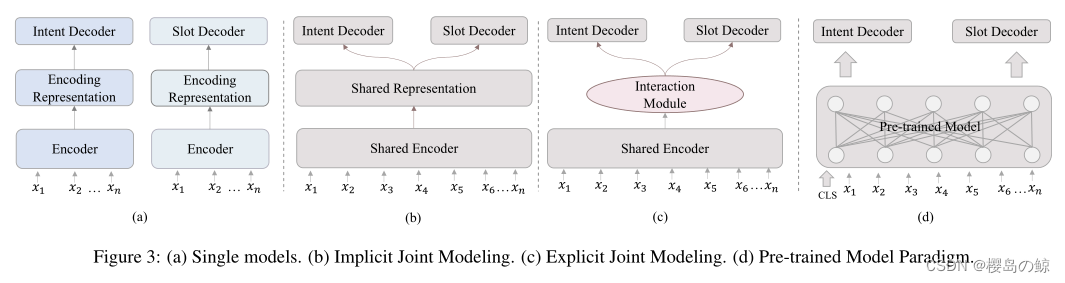
1. Single Model
单个模型分别训练每个任务进行意图检测和槽填充。由于单独训练,单个模型的意图检测和槽填充之间没有相互作用,导致两个任务之间的共享知识泄漏。
- Intent Detection:
Gradient-based learning applied to document recognition: 利用卷积神经网络(CNN)提取5-gram特征,并应用max-pooling来获得单词表示。
Recurrent neural network and lstm models for lexical utterance classification: 成功地将RNN和长短期记忆网络(LSTM)应用于ID任务,表明序列特征有利于意图检测任务。 - Slot Filling:
Recurrent neural networks for language understanding: 采用RNN语言模型(RNN-LMs)来预测槽标签而不是单词。此外,RNN-LMs还探索了将来的单词、命名实体、语法特征和词类信息。
Spoken language understanding using long short-term memory neural networks: 提出了一种用于槽填充任务的LSTM框架。
Using recurrent neural networks for slot filling in spoken language understanding: 应用Viterbi编码和循环crf来消除标签偏差问题。
Recurrent conditional random field for language understanding: 提出了R-CRF来解决标签偏见。
Recurrent neural network structured output prediction for spoken language understanding: 提出使用采样方法对槽标签依赖进行建模,将采样的输出标签(真或预测)反馈到序列状态。
Bi-directional recurrent neural network with ranking loss for spoken language understanding: 在SF中利用bi-RNN模型的排序损失函数,进一步提高了ATIS数据集的性能。
Leveraging sentence-level information with encoder LSTM for semantic slot filling: 利用来自编码器的句子级信息来提高SF任务的性能。
2. Joint Model
考虑到意图检测与插槽填充之间的密切相关性,文献中的主要工作采用联合模型来利用任务间的共享知识。现有的联合工作主要分为两大类:隐式联合建模和显式联合建模。
- Implicit Joint Modeling:
隐式联合建模表示模型仅采用共享编码器来捕获共享特征,没有任何显式交互。虽然隐式联合建模是一种直接纳入共享知识的方法,但它没有显式地对交互进行建模,从而导致低可解释性和低性能。
A joint model of intent determination and slot filling for spoken language understanding: 引入了一个共享的 RNNs (Joint ID and SF) 来学习意图和插槽之间的相关性。
Attention-based recurrent neural network models for joint intent detection and slot filling: 引入了一种具有注意机制(Attention BiRNN)的共享编码器解码器框架,用于意图检测和插槽填充。
Joint online spoken language understanding and language modeling with recurrent neural networks: 使用共享RNN联合进行SF、ID和语言建模(Joint SLU-LM),旨在提高在线预测能力。
Multi-domain joint semantic frame parsing using bi-directional rnn-lstm: 提出了一种用于联合建模的共享RNN-LSTM架构(Joint Seq)。 - Explicit Joint Modeling:
近年来,越来越多的人提出用显式交互模块显式地对意图检测和槽填充之间的交互进行建模,这种显式建模方式具有显式控制交互过程的优点。现有的显式联合建模方法可分为单流相互作用和双向流动相互作用两类。 -
- Single Flow Interaction:
目前单流交互研究主要考虑从意图到插槽的单信息流。
Slot-gated modeling for joint slot filling and intent prediction: 提出了一种槽门联合模型(Slot-Gated),该模型允许槽填充以学习意图为条件。
A self-attentive model with gate mechanism for spoken language understanding: 提出了一种新的自我关注模型(Self-Atten. Model),用意图增强的门控机制去引导槽内充填。
A stack-propagation framework with token-level intent detection for spoken language understanding: 提出了一种堆栈传播模型,直接使用意图检测结果来指导槽填充,并使用 token-level 意图检测来缓解错误传播,进一步提高了性能。
- Single Flow Interaction:
-
- Bidirectional Flow Interaction:
双向流动相互作用是指模型考虑了在意图检测和槽填充之间的交叉影响。简单的多任务框架只是通过共享潜在表示来隐式地考虑两个任务之间的相互连接,显式联合建模可以使模型完全捕获跨任务的共享知识,从而提高两个任务的性能。其次,明确控制两项任务的知识转移有助于提高可解释性,从而更容易分析SF和ID之间的影响。
A bi-model based RNN semantic frame parsing model for intent detection and slot filling: 提出了一个双模型架构,通过使用两个相关的双向LSTMs来考虑SF和ID之间的交叉影响。
A novel bi-directional interrelated model for joint intent detection and slot filling: 考虑到SF-to-ID和ID- to-SF的影响,提出了一种新的SF-ID网络,为SF和ID任务提供了双向关联机制。
Joint slot filling and intent detection via capsule neural networks: 引入了一种动态路由胶囊网络(Capsule-NLU),以融合两个任务之间的层次和相互关联的关系。
CM-net: A novel collaborative memory network for spoken language understanding: 提出了一种新的协同记忆网络(CM-Net),用于联合建模SF和ID。
Graph lstm with context-gated mechanism for spoken language understanding: 在将图LSTM引入SLU方面进行了探索,取得了很好的性能。
A co-interactive transformer for joint slot filling and intent detection: 提出了一种协同交互Transformer,通过在两个相关任务之间建立双向连接来考虑交叉影响。
- Bidirectional Flow Interaction:
3. Pre-trained Paradigm
最近,预训练语言模型(PLMs)在各种NLP任务中取得了惊人的结果,其中共享BERT被视为提取上下文表示的编码器。在基于Bert的模型中,每个话语以[CLS]开始,以[SEP]结束,其中[CLS]是表示整个序列的特殊符号,[SEP]是分离非连续标记序列的特殊符号。进一步,使用特殊令牌[CLS]的表示方式进行意图检测,采用其他令牌表示方式进行槽填充。预训练模型可以提供丰富的语义特征,有助于提高SLU任务的性能。
Bert for joint intent classification and slot filling: 将BERT用于提取共享上下文嵌入以进行意图检测和槽填充,与其他未预训练的模型相比,该模型获得了显著改进。
A stack-propagation framework with token-level intent detection for spoken language understanding: 使用预训练的嵌入编码器取代其注意力编码器(Stack-Propagation+BERT),进一步提高了模型的性能。
A co-interactive transformer for joint slot filling and intent detection: 还为SLU探索了BERT (Co-Interactive transformer BERT),实现了最先进的性能。
四、New Frontiers and Challenges
1. Contextual SLU
自然地,完成一个任务通常需要在用户和系统之间进行多次来回的对话,这要求模型考虑上下文SLU。与单回合SLU不同,上下文SLU面临着独特的歧义挑战,因为用户和系统可能会引用之前对话回合中引入的实体,从而引入歧义,这需要模型结合上下文信息来减轻歧义。
End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding: 提出了一个记忆网络来整合对话历史信息,表明他们的模型优于没有上下文的模型。
Sequential dialogue context modeling for spoken language understanding: 提出了一种顺序对话编码器网络,允许按照时间顺序对对话历史中的上下文进行编码。
How time matters: Learning time-decay attention for contextual spoken language understanding in dialogues: 基于端到端上下文语言理解模型设计并研究了各种时间衰减注意函数。
Cosda-ml: Multi-lingual code-switching data augmentation for zero-shot cross-lingual nlp: 提出了一种自适应融合层,动态考虑不同和相关的上下文信息来指导槽填充,实现细粒度的上下文信息传递。
主要的挑战是:1) Contextual Information Integration:正确区分不同对话历史与当前话语之间的相关性,并有效地将上下文信息整合到上下文SLU中是一个核心挑战。2) Long Distance Obstacle:由于一些对话具有非常长的历史,如何有效地建模远程对话历史并过滤无关噪声是一个有趣的研究课题。
2. Multi-Intent SLU
多意图SLU是指系统可以处理包含多个意图的话语及其对应的槽。在亚马逊内部数据集中显示52%的示例是多意图的,这表明多意图设置在现实场景中更实用。
Joint multiple intent detection and slot labeling for goal-oriented dialog: 探索了一个多任务框架,共同执行多意图分类和插槽填充。
AGIF: An adaptive graph-interactive framework for joint multiple intent detection and slot filling: 提出了一种自适应图交互框架,用于在每个令牌上建模多个意图和插槽之间的交互。
主要挑战:1) Interaction between Multiple Intents and Slots:与单意图SLU不同的是,如何有效地整合多意图信息来引导槽位预测是多意图SLU所面临的独特挑战。2) Lack of Data:目前还没有针对多目的SLU的人工注释数据,这可能是进展缓慢的另一个原因。
3. Chinese SLU
中文SLU是指用中文数据训练的SLU模型直接应用于中文社区。与英语SLU相比,汉语SLU面临着独特的挑战,因为它通常需要分词。
CM-net: A novel collaborative memory network for spoken language understanding: 为研究界贡献了一个新的语料库(CAIS)。此外,他们还提出了一种基于字符的联合模型来执行中文SLU,但基于字符的SLU模型的一个缺点是没有充分利用显式词序列信息,这可能是有用的。
Injecting word information with multi-level word adapter for chinese spoken language understanding: 提出了一种多级单词适配器,以有效地将单词信息合并到句子级意图检测和标记级插槽填充中。
主要挑战:1) Word Information Integration:如何有效地结合词汇信息来指导汉语语言学习是一个独特的挑战。2) Multiple Word Segmentation Criteria:由于存在多个分词标准,如何有效结合中文SLU的多个分词信息并非易事。
4. Cross Domain SLU
尽管现有的SLU模型在单个域设置中取得了很好的性能,但它依赖于大量带注释的数据,这限制了它们在新域和扩展域中的实用性。在实践中,为每个新领域收集丰富的标记数据集是不可行的。因此,有希望考虑跨域设置。该领域的知识转移方法可以归纳为两类:具有参数共享的 Implicit domain knowledge transfer 和 Explicit domain knowledge transfer。
隐式领域知识转移是指模型简单地结合多领域数据集进行训练以捕获领域特征。这种方法可以隐式地提取共享特征,但不能有效地捕获特定领域的特征。
Multi-domain joint semantic frame parsing using bi-directional rnn-lstm: 提出了混合多域数据集上的单一LSTM模型,该模型可以隐式学习域共享特征。
Onenet: Joint domain, intent, slot prediction for spoken language understanding: 采用一个网络联合建模槽填充、意图检测和域分类,隐式学习域共享和任务共享信息。
显式领域知识转移方法是指模型采用shared-private 框架,包括一个共享模块来获取领域共享特征,每个领域都有一个私有模块,具有显式区分共享知识和私有知识的优点。
Domain attention with an ensemble of experts: 使用注意力机制从专家模型在不同领域的反馈中学习加权组合。
Multi-domain adversarial learning for slot filling in spoken language understanding: 使用了共享LSTM来捕获领域共享知识,并使用私有LSTM来提取领域特定的特征,将它们结合起来进行多域槽填充。
Multi-domain spoken language understanding using domain- and task-aware parameterization: 提出了一种具有独立的领域特定参数和任务特定参数的模型,该模型能够捕获多域SLU的任务感知和领域感知特征。
主要挑战:1) Domain Knowledge Transfer:将知识从源领域转移到目标领域并非易事。此外,如何在细粒度级别上进行领域知识迁移,进行句子级意图检测和标记级槽填充也是一个难点。2) Zero-shot Setting:当目标领域没有训练数据时,如何将知识从源领域数据转移到目标领域是一个挑战。
5. Cross-Lingual SLU
跨语言SLU是指在英语基础上训练出来的SLU系统可以直接应用到其他低资源语言上,越来越受到人们的关注。
主要挑战:1) Domain Knowledge Transfer:将知识从源领域转移到目标领域并非易事。此外,如何在细粒度级别上进行领域知识迁移,进行句子级意图检测和标记级槽填充也是一个难点。2) Zero-shot Setting:当目标领域没有训练数据时,如何将知识从源领域数据转移到目标领域是一个挑战。
6. Low-resource SLU
SLU的显著进展很大程度上依赖于大量的标记训练数据,这在低资源环境下无法工作,因为可以访问的数据很少或为零。我们将讨论 low resource SLU 的趋势和进展,包括 Few-shot SLU、zero-shot SLU和 Unsupervised SLU。
- Few-shot SLU:
在某些情况下,一个槽或意图只有更少的实例,这使得传统的监督SLU模型无能。为了缓解这个问题,few-shot SLU 在这种情况下很有吸引力,因为它可以通过很少的示例快速适应新的应用程序。
Few-shot slot tagging with collapsed dependency transfer and label-enhanced task-adaptive projection network: 为 few-shot slot-tagging 提出了一种具有折叠依赖转移机制的 few-shot CRF模型。
Few-shot learning for multi-label intent detection: 开始探索 few-shot 多意图检测。 - Zero-shot SLU:
面对快速变化的应用,一个全新的应用可能会出现没有目标训练数据的情况。许多 zero-shot 方法都提供了一种通过发现插槽之间的共性来解决这个问题的方法。
Towards zero-shot frame semantic parsing for domain scaling: 提出了一种利用槽描述的方法,该方法携带槽的信息,通过不同的应用来获取和传递概念,增强了模型的 zero-shot 能力。
Coach: A coarse-to-fine approach for cross-domain slot filling: 采用了类似的架构,训练模型对槽描述的感知。
Robust zero-shot cross-domain slot filling with example values: 通过在训练期间添加插槽示例值和描述来解决错位重叠模式的问题。 - Unsupervised SLU:
近年来,无监督方法被提出用于自动提取槽值对,是将模型从繁重的人工注释中解放出来的一个有前途的方向。
Dialogue state induction using neural latent variable models: 提出了一种新的对话状态诱导任务(dialogue state induction),即自动识别对话状态槽值对。
主要挑战:1) Interaction on low-resource setting:如何充分利用低资源设置中意图与槽之间的连接,仍是一个有待探索的问题。2) Lack of Benchmark:在低资源设置方面缺乏公共基准,这可能会阻碍进展。







![[MRCTF2020]Ezaudit(随机数的安全)](https://img-blog.csdnimg.cn/f31b67a285c04e3287873c8e3458aad3.png)
