数据获取——》数据清洗——》数据转换——》数据分析
- 通过设置步长,有间隔的取元素
- 通过设置步长为-1,将元素颠倒

数据清洗工具
目前在Python中, numpy和pandas是最主流的工具。
- Numpy中的向量化运算使得数据处理变得高效;
- Pandas提供了大量数据清洗的高效方法。
在Python中,尽可能多的使用numpy和pandas中的函数,提高数据清洗的效率
一、Numpy
1.可以通过np.array([1,2,3,4])创建一维数组
2. np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])创建多维数组
3. 可以使用其他函数例如arange、linspace、zeros等创建 np.arange(0,10,1) np.linspace(1,10,10) np.zeros([2,3])
4. 常用方法
- ndim: 查看数组维度
- size:返回数组元素的个数
- dtype:返回数组中元素的类型
5.常用数据清洗函数
- np.sort(x) #从小到大排序
- argsort函数返回数据中从小到大的索引值
- sorted(x,reverse=True) #降序,从大到小
- axis=0 #0表示对列,1表示对行
- np.where(x>3,1,-1) #满足条件的赋值1,反之-1
- np.extract(x>3,x) #只输出满足条件的数据
二、Pandas
1.series序列
- pd.Series([1,2,3,4,5])
- pd.Series([1,2,3,4,5],index=[‘a’,‘b’,‘c’,‘d’,‘e’],name=‘这是一个series序列’)
- pd.Series[‘北京’:1,‘上海’:2,‘广东’:3,‘深圳’:4,‘浙江’:5]
2.series方法
- series.values
- series.index
3.dataframe


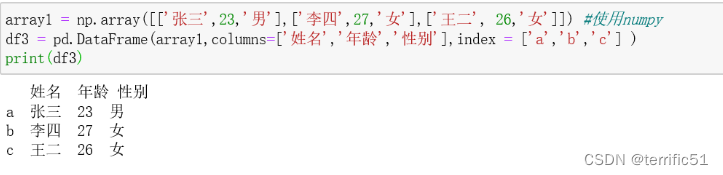
4.dataframe方法
- df.values

- df.index

- df.columns

- df.dtypes

- df.ndim
- df.size
三、文件操作(csv)
1.使用read_csv/read_excel方法读取,结果为dataframe格式
2.在读取csv文件时,文件名称尽量是英文
3.读取csv时,注意编码,常用编码为utf-8、gbk 、gbk2312和gb18030等
4.使用to_csv/to_excel方法快速保存
- data.to_csv(‘name.csv’,encoding=‘utf-8’,index=False) #建议用utf-8编码或者中文gbk编码,默认是utf-8编码, index=False表示不写出索引行
数据库文件
1.使用sqlalchemy建立连接
2.pandas中read_sql 函数读入,读取完以后是dataframe格式
3.dataframe的to_sql方法保存
df.to_sql(name, con=engine, if_exists=‘replace/append/fail’,index=False)
name:表名; con:连接;
if_exists:表如果存在怎么处理。三个选项 append代表追加, replace代表删除原表,建立新表,fail代表什么都不干;index=False:不插入索引index
4.建立连接
conn=create_engine(‘mysql+pymysql://root:passward@IP:3306/test01’)
root: 用户名;passward: 密码;IP : 服务器IP,本地电脑用localhost;3306: 端口号; test01 : 数据库名称
四、数据筛选方法
-
df.info() #查看数据
-
df.head(5) #查看前5行
-
df.tail(5) #查看后5行
-
df[‘id’] #简单索引
-
df[‘id’][1:5] #第二行到第五行
-
df[[‘id’,‘name’,‘score’]][:5] #多个变量选择,前5行
-
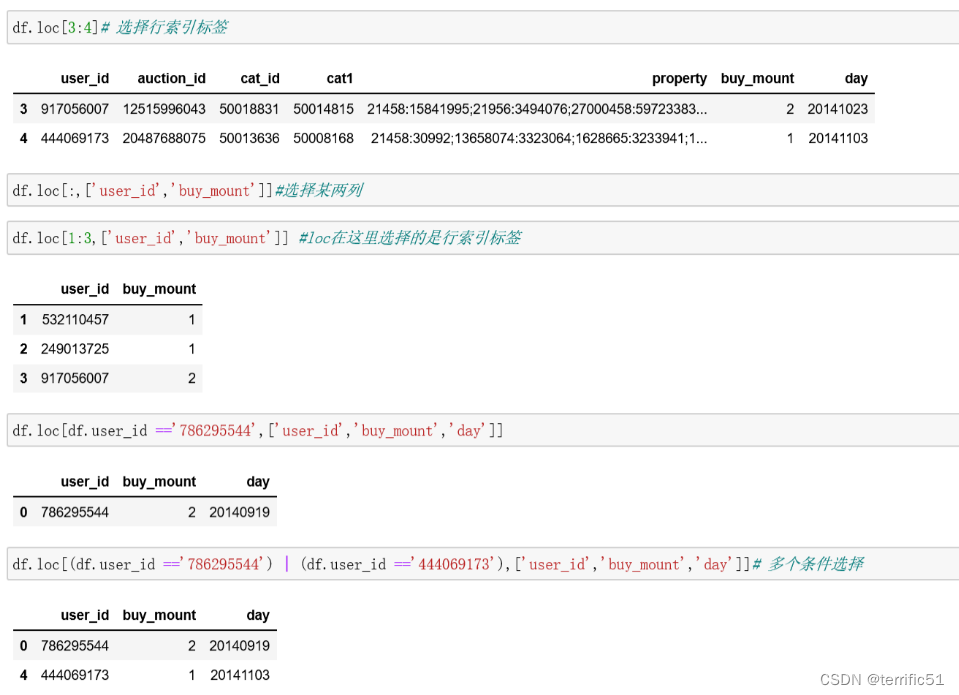
loc与iloc
loc
iloc
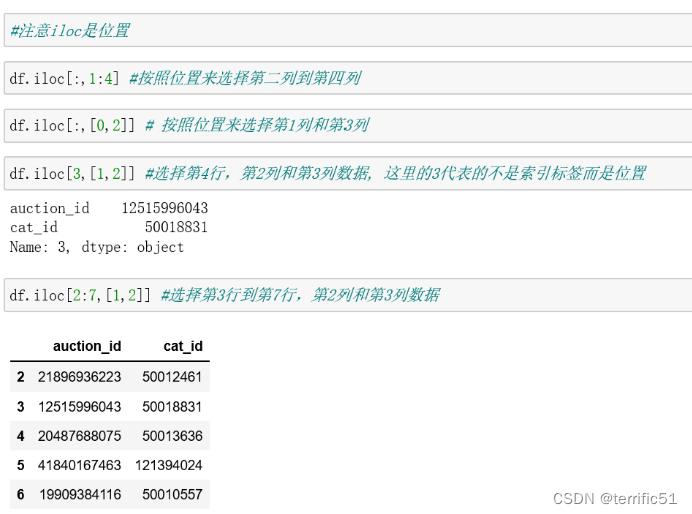
**loc 与 iloc区别** 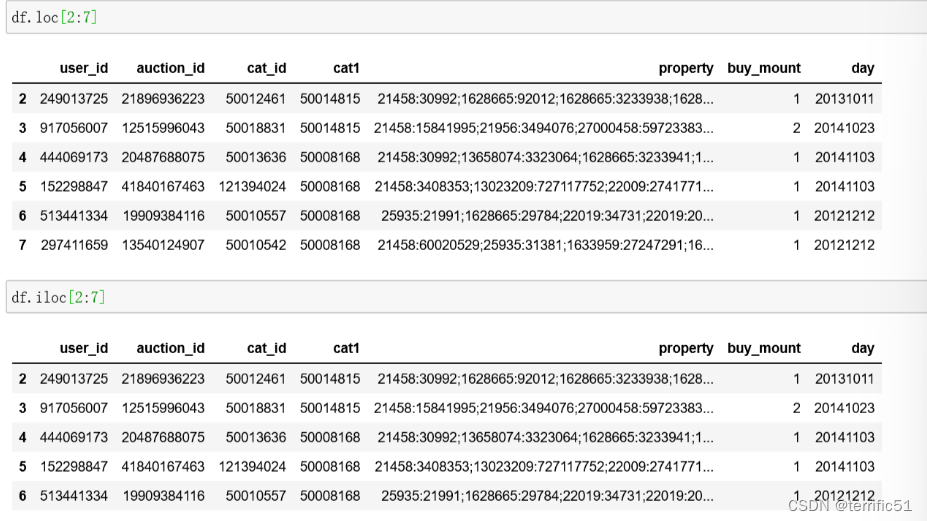
五、数据增加和删除
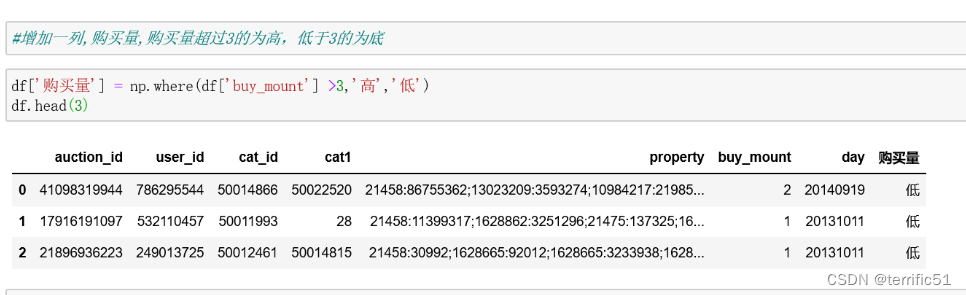
1.增加一列
- df[‘购买者’]=np.where(df[‘buy_mount’]>3,‘高’,‘低’)
2.插入一列
- df.insert(0,‘auction_id’,auction_id)
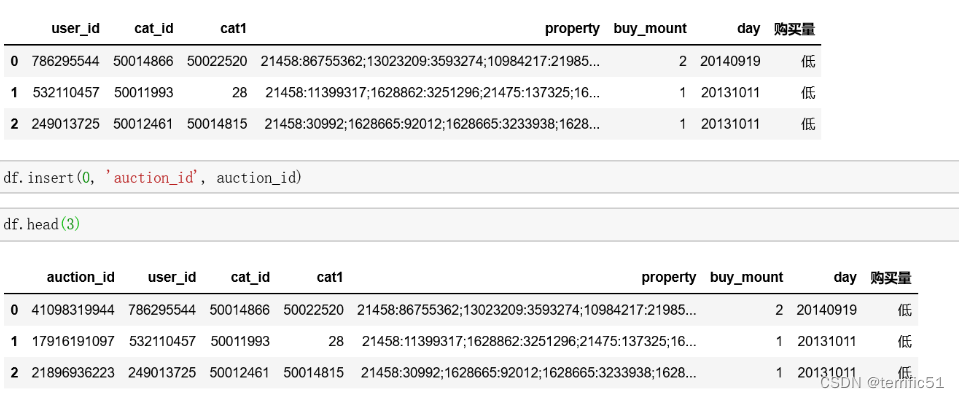
3.删除一列
- del df[‘auction_id’]
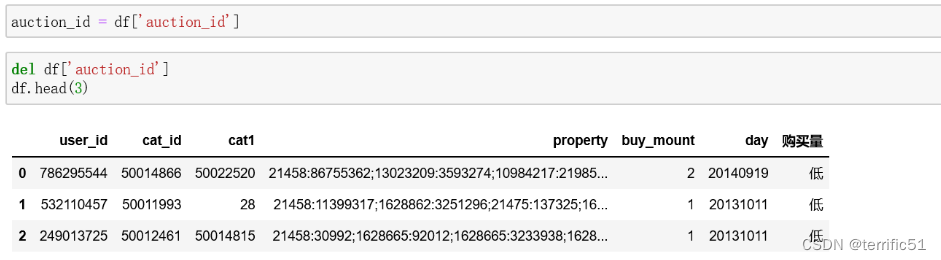
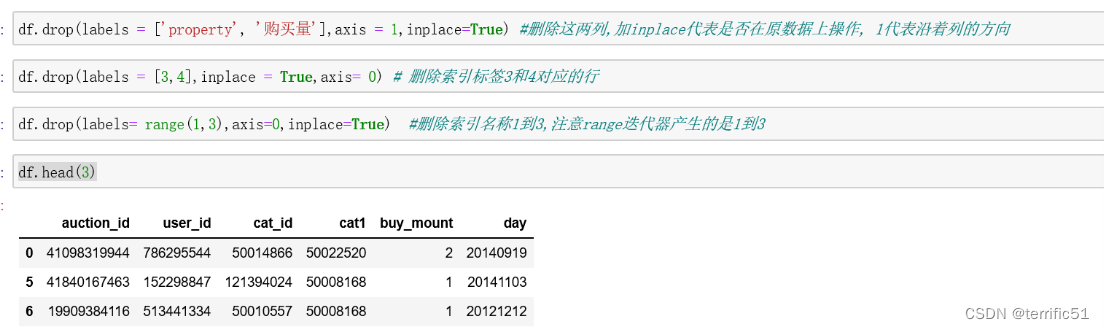
4.drop删除行和列
六、数据修改和查找
1.数据修改
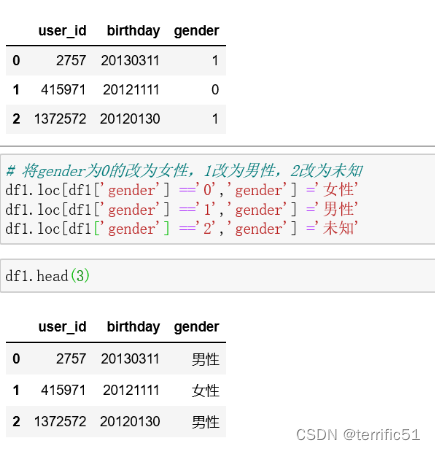
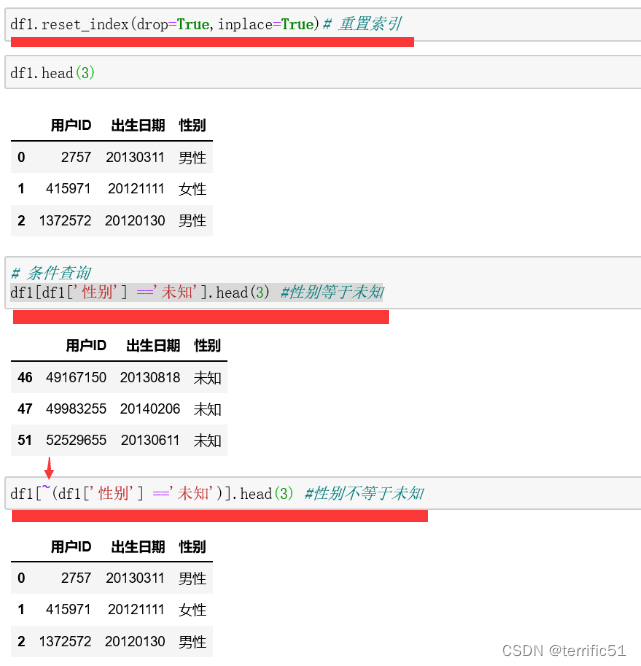
- df.rename(columns={‘user_id’:‘用户ID’,‘birthday’:‘出生日期’,‘gender’:‘性别’},inplace=True) #修改列标签
- df.rename(index={1:‘one’,10:‘ten’},inplace=True) #修改行索引名称
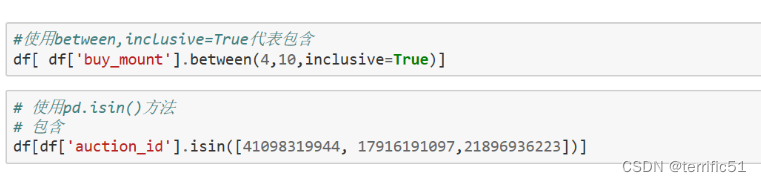
七、数据整理
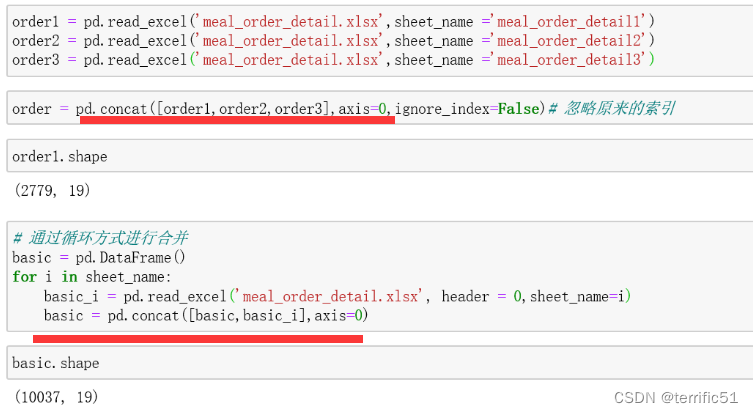
数据合并
一般均为纵向合并,即使用concat时,axis =1(0代表横向);注意join取inner或者outer时,分别代表交集和并集
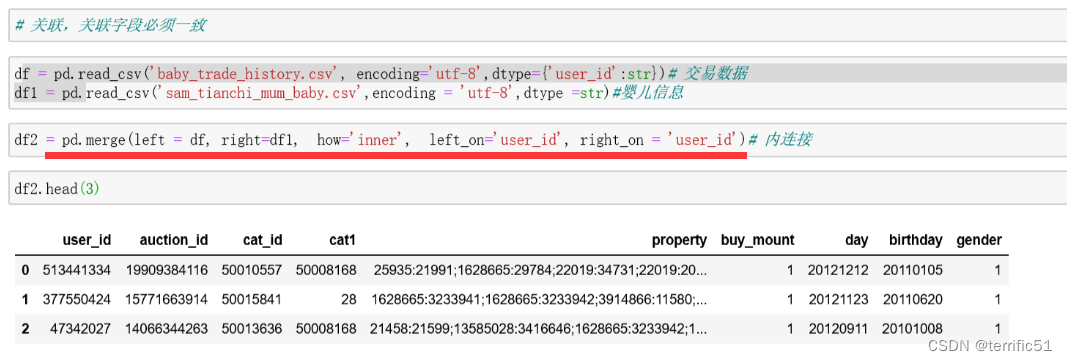
八、层次化索引
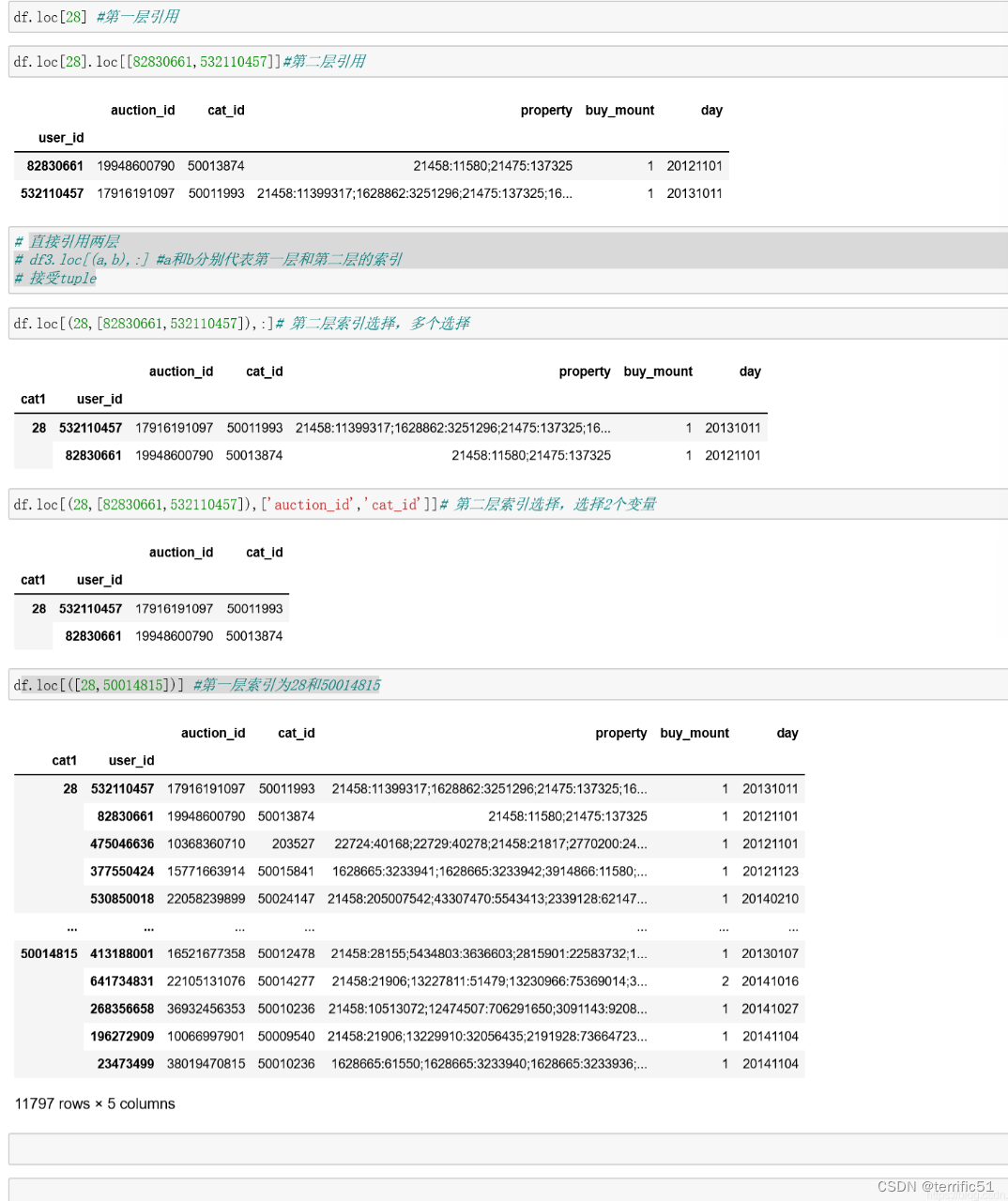
九、数据转换
1.Pandas中使用to_datetime()方法将文本格式转换为日期格式

2.dataframe数据类型如果为datetime64,可以使用dt方法取出年月日等
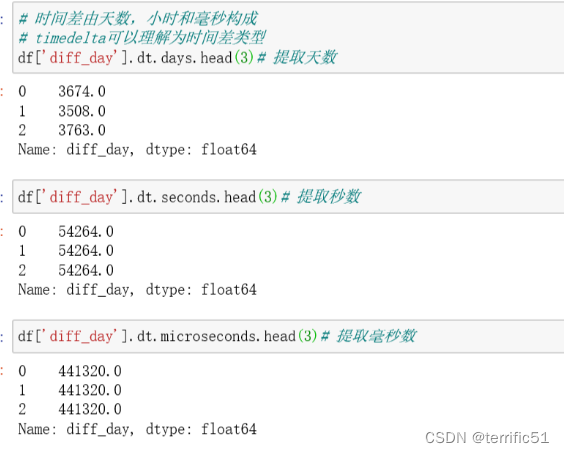
3.对于时间差数据,可以使用timedelta函数将其转换为指定时间单位的数值
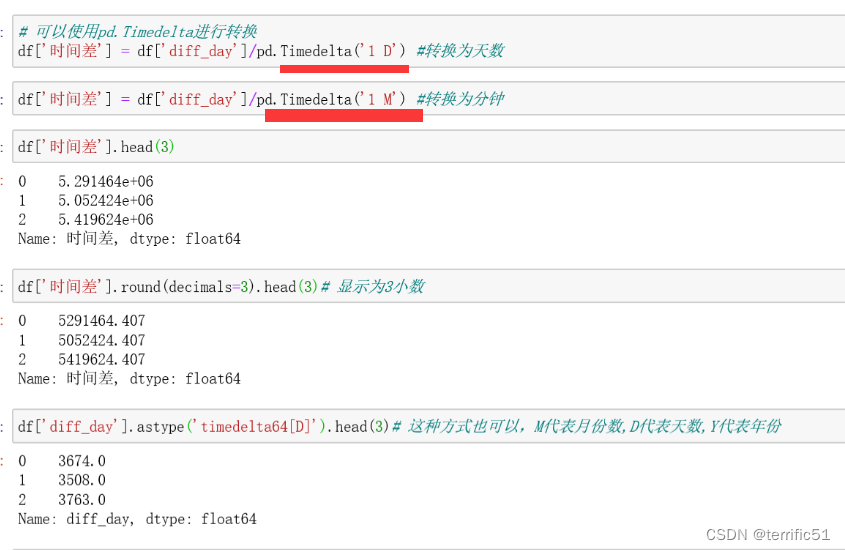
4.时间差数据,可以使用dt方法访问其常用属性