目录标题
- 1,统计目录下所有文件大小-os的使用
- 2,按文件后缀整理文件夹
- 3,递归搜索目录找出最大文件
- 4,计算不同课程的最高分最低分--分组处理
- 5,实现不同文件的关联
- 6,批量txt文件的合并
- 7,统计每个兴趣的学生人数
- 8,获取当前的日期和时间-datetime.datetime.now()
- 9,计算两个日期相隔的天数
- 10,计算任意日期7天前的日期
1,统计目录下所有文件大小-os的使用
os.path.getsize(文件名)-----获取文件的大小
os.listdir(‘路径’)----路径下的所有文件和目录
os.path.isfile(file)----判断是否为文件
import os
print(os.path.getsize('文件.txt')) #文件5423字节,则返回5423
sum_size = 0
for file in os.listdir('.'): #遍历当前
if os.path.isfile(file): #排除是目录的
sum_size +=os.path.getsize(file)
print('总文件大小:',sum_size/1000) #sum_size原本单位是b,除以1000后得到kb
2,按文件后缀整理文件夹
获取后缀名:os.path.splittext(‘路径’)
移动文件:shutil.move(‘原始地址文件’,‘要移动到的地址’)
创建目录:os.mkdir(f’{dir}/{ext}')

import os
import shutil
dir = '路径目录'
for file in os.listdir(dir):
ext = os.path.splitext(file)[1]
ext = ext[1:] #得到后缀名
print(file,ext)
if not os.path.isdir(f'{dir}/{ext}'): #给当前路径创建以后缀名为名字的文件夹
os.mkdir(f'{dir}/{ext}')
source_path = f"{dir}/{file}"
target_path = f"{dir}/{ext}/{file}"
shutil.move(source_path,target_path) #写路径的时候都要落脚到最后的文件名或者文件夹名
创建文件夹后:
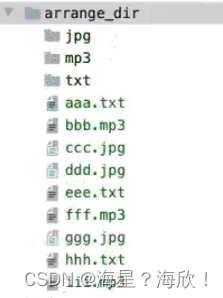
3,递归搜索目录找出最大文件
没用os.listdir()–不然后面要if判断一下是文件还是目录
用os.walk()–直接得到文件

思路:用一个列表先储存目标路径下的文件和文件大小os.path.getsize()
然后降序排列sorted(),取前10个
import os
search_dir = '放目标目录'
result_files = []
for root,dirs,files in os.walk(search_dir):
for file in files:
file_path = f"{root}/{file}"
result_files.append(file_path,
os.path.getsize(file_path)/1000)
print(sorted(result_files,key=lambda x:x[1],reverse = True)[:10])
4,计算不同课程的最高分最低分–分组处理
思路:用一个字典,把课程名和所有成绩储存起来。然后for遍历字典,输出课程名和最大成绩
文件grades.txt中记下:
语文,1,小张,96
语文,2,小红,90
语文,3,小明,86
语文,4,小王,92
数学,1,小张,96
数学,2,小红,90
数学,3,小明,86
数学,4,小王,92
course_grades={}#key:课程,value:成绩列表
with open('./grades.txt') as fin:
for line in fin:
line = line[:-1]
course,sno,sname,sgrade = line.split(",")###直接获取各列值
if course not in course_grades:
course_grades[course] = []
course_grades[course].append(int(sgrade))
print(course_grades)
for course,grades in course_grades.items():
print(course,max(grades),min(grades),sum(grades)/len(grades))
course_grades中格式:

5,实现不同文件的关联
文件grades.txt中记下:
语文,1,小张,96
语文,2,小红,90
语文,3,小明,86
语文,4,小王,92
数学,1,小张,96
数学,2,小红,90
数学,3,小明,86
数学,4,小王,92
文件teacher.txt中内容:
语文,于老师
数学,树老师
将两文件进行关联:
思路:将teacher.txt中内容放进一个字典中,然后将grades.txt中各行数据和老师列一起for遍历输出
course_teacher_map = {}
with open('./teacher.txt') as fin:
for line in fin:
line = line[:-1]
course,teacher = line.split(",")
course_teacher_map[course] = teacher
print(course_teacher_map)
with open("./grades.txt") as fin:
for line in fin:
line= line[:-1]
course,sno,sname,sgrade=line.split(",")
teacher = course_teacher_map[course] #当前在for循环中
print(course,teacher,sno,sname,sgrade)
course_teacher_map中形式:

6,批量txt文件的合并
python读取文件的两个方法:
1,按行读取:for line in fin
2,一次读取所有内容到一个字符串中: content = fin.read()
思路:遍历目标路径,找出是txt结尾的文件,打开,将内容append到一个空列表中,然后写入新文件中
目标路径下:放着文件1.txt,文件2.txt,文件3.txt
import os
data_dir = "目标目录"
content = []
for file in os.listdir(data_dir):
file_path = f"{data_dir}/{file}"
if os.path.isfile(file_path) and file.endswith('.txt'):
with open(file_path) as fin:
contents.append(fin.read())
final_content = '\n'.join(contents) #每个内容加一个换行符
with open("./结果存放.txt",'w') as font:
font.write(final_content)
复述一遍:
import os
mubiao ="目标目录"
con = []
for files in os.listdir(mubiao):
files_path = f"{mubiao}/{files}"
if os.path.isfile(files_path) and file_path.endswith('.txt'):
with open(files_path) as fin:
con.append(fin.read())
final_con = '\n'.join(con)
with open("心文件.txt",'w') as fout:
fout.write(final_con)
最后结果存放.txt中内容:

7,统计每个兴趣的学生人数
文件student_like.txt中内容:
小张 篮球,羽毛球
小米 乒乓球,台球
小明 羽毛球,台球
like_count =[]#key是爱好,values是计数
with open('./student_like.txt') as fin:
for line in fin:
line = line[:-1]
names,likes = line.split(" ")
like_list = likes.split(",")#直接用split划分出来
for i in likes:
if i not in like_count:
like_count[j] =0
like_count[j]+=1
print(like_count)
思路:一行一行读取文件–把爱好split出来–每遇到一次加一
8,获取当前的日期和时间-datetime.datetime.now()
import datetime
curr_datetime = datetime.datetime.now()
print(curr_datetime,type(curr_datetime)) #是class类型,对象
#更改日期输出格式--strftime
str_time = curr_datetime.strftime('%Y-%m-%d %H:%M:%S')#更改日期格式
print(str_time)
#单独获取年月日。。
print("year:",curr_datetime.year)
print("month:",curr_datetime.month)
print("day:",curr_datetime.day)
print("hour:",curr_datetime.hour)
print("minute:",curr_datetime.minute)
print("second:",curr_datetime.second)

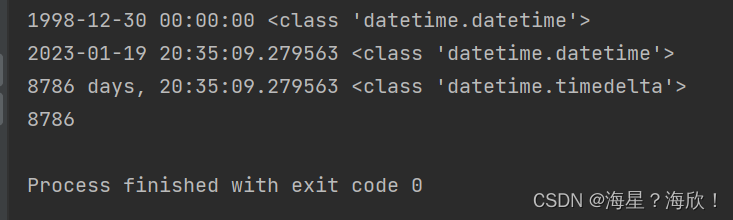
9,计算两个日期相隔的天数
转变为日期格式–datetime.strptime
import datetime
brithday = '1998-12-30' #现在是字符串类型,需要先转变为日期格式
brithday_date = datetime.datetime.strptime(birthday,'%Y-%m-%d') #这时候后才可以用
print(brithday_date,type(brithday_date))
curr_datetime = datetime.datetime.now()
print(curr_datetime,type(curr_datetime))
#两个日期类型的数据,进行相减
minus = curr_datetime-brithday_date
print(minus,type(minus))
print(minus.days)
10,计算任意日期7天前的日期
日期要记得转成日期类型 :datetime.strptime(date, ‘%Y-%m-%d’)
天数做加减时也需要改成日期类型:time_gap = datetime.timedelta(days=days)
import datetime
def get_diff_days(pdate, days): # 输出: pdate前days天的日期
pdate_obj = datetime.datetime.strptime(pdate, '%Y-%m-%d')
time_gap = datetime.timedelta(days=days) # 天数也变成日期类型
pdata_result = pdate_obj - time_gap
return pdata_result
print(get_diff_days("2023-01-19", 7))


![[hive]维度模型分类:星型模型,雪花模型,星座模型|范式](https://img-blog.csdnimg.cn/img_convert/a5b29ba853b3e6b68de12d03bccfe19d.gif)