使用自监督学习对AMD分类

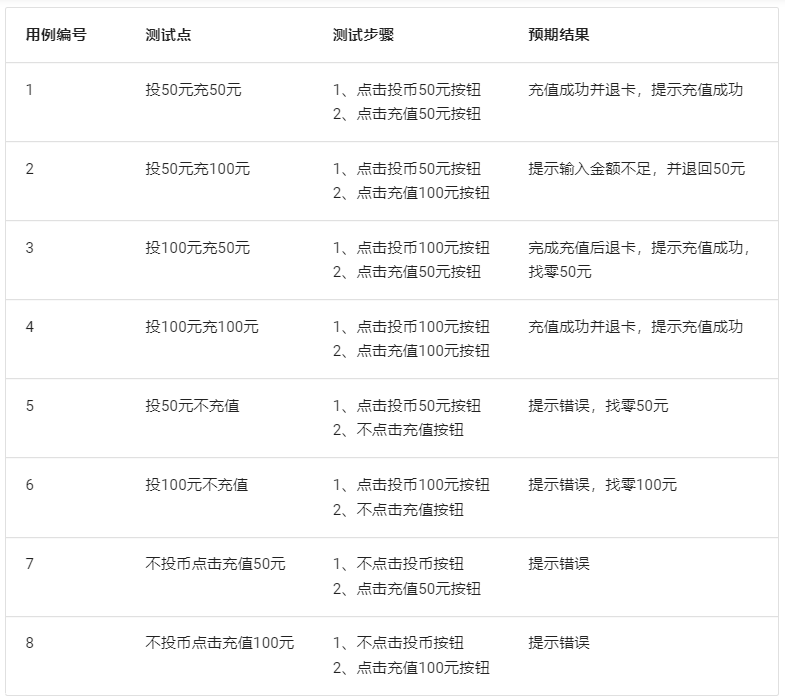
文章目录
- 使用自监督学习对AMD分类
- 一、简介
- 二、先验知识
- 三、文章核心内容
- 四、使用方法
- 1. 非参数化实例歧视(中文翻译过来总是奇奇怪怪,其实就是NPID)
- a 挑战
- b 解决方案
- c 转化!
- 2. 数据集
- 3. 数据预处理
- 五、结论
- 六、可借鉴点
一、简介
长时间考虑和接触的问题都是监督学习,都在考虑label的标注,但是实际生活中的很多问题都存在label标记很难,或是工作量太大,亦或是触及信息泄露问题。所以无监督和自监督是大家最希望的解决方法。
二、先验知识
脱色和地理萎缩对AMD的影响最严重
三、文章核心内容
使用自监督深度学习使用数据驱动的AMD特征对其严重程度进行分类并发现眼部疾病
四、使用方法
敲黑板,划重点!新知识点
1. 非参数化实例歧视(中文翻译过来总是奇奇怪怪,其实就是NPID)
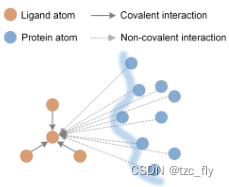
**在分类问题中,我们的任务是将所有的数据(10000+图片)分为几类,NPID可以想象为将所有数据区分为这10000+(和数据集同大小)类,将类别数量扩展为实力数量。**有监督学习根据图片之间的相似性将所有的图片分为N个类别,而通过将类别数量扩展为实例数量的方式,最终可以得到一个表示实例之间明显相似性的表征
a 挑战
类别的数量和整个数据集的大小相当,将softmax层扩展为与类别相当大小是不现实的
b 解决方案
作者采用噪声对比估计(NCE)逼近整个softmax分布,之后采用近端正则化的方法稳定学习过程。 使用non-param softmax 代替原来的softmax
c 转化!
通过这种方式将判别学习转化为度量学习,其中实例之间的距离通过非参数方式直接根据表征进行计算
2. 数据集
100848张眼底照
3. 数据预处理
使用拉普拉斯滤波处理
五、结论
使用I监督也可以都达到监督学习的效果
六、可借鉴点
对于相似程度很高的数据进行分裂的过程中可以尝试将其实例化,使用NPID进行分类,或许可以取得不错的效果。我还没有进行尝试,当然这种方法针对没有label的数据集是很友好的,但是如果label标注并不复杂或者消耗时间精力不大,则还是建议使用监督学习。应用类型更推荐使用监督学习,如果是方法创新可以在无监督上面多花时间和精力