编码:
print('云'.encode('utf8'))
print(b'\xe4\xba\x91'.decode('utf8'))
要注意代码的编码方式。
7.1文件概述
windows中一个文件的完标识:
D:\Downloads\新建文本文档.txt
依次是路径,文件名主干,拓展名。没有包含除了文本字符以外的其他数据。
文件分为两种:一种是文本文件,一种是二进制文件。
py的sys模块中定义了3个标准文件,stdin(标准输入)、stdout(标准输出)、stdout(标准错误文件)
解释器中导入sys后可以对标准文件操作:
import sys
file =sys.stdout
file.write('hello')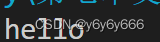
7.2文件的基础操作
7.2.1打开与关闭
- 打开文件
open(file,mode='r',encoding=None)file 表示路径。
more 表示打开方式
encoding 表示指定文件的编码方式
打开模式:
默认r
r/rb:只读,文件不存在打开失败
w/wb:只写,文件已存在重写,不存在创建
a/ab:追加,没有创建
r+/rb+:读写,不存在打开失败
w+/wb+:读写,已存在重写
a+/ab+:读或写追加
2.读取文件
file1=open('9.txt','r+',encoding='utf8')
#file1.write('我:新年快乐!!!')
content=file1.read()
file1.close()
name=content.split(':')[2]
print(name)split('分割方式')[下标]
下标可以是范围。实际上就是对字符串的切割
read可以有参数,指定固定的长度,(下标)
read(n) 0~n-1
不关闭文件,再次写读取会接着上次继续读取。
换行也是一个字符。
一行一行读取:
file.readlines()f=open('第七章文件与数据格式化.py',encoding='utf8')
linelist=f.readlines()
f.close()
for l in linelist:
print(l)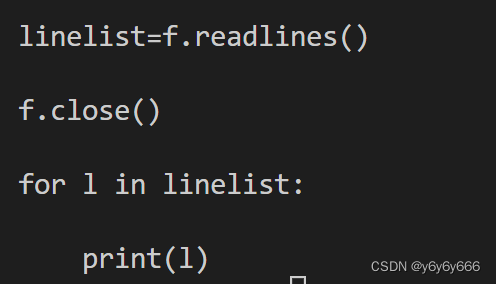
会多一些空行,因为print输出默认有换行。
可以改下。
print(l,end='')或者用splitlines()
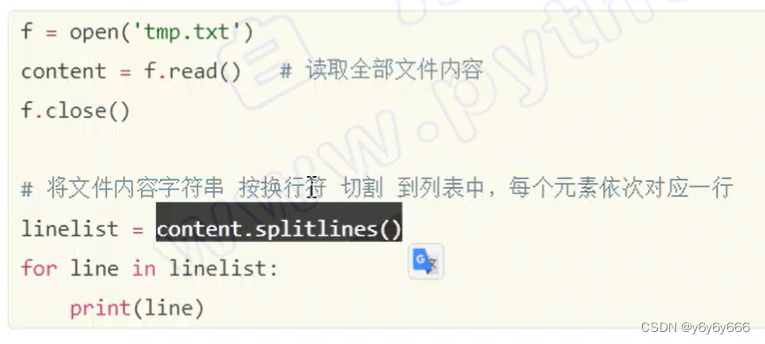
f=open('第七章文件与数据格式化.py',encoding='utf8')
content=f.read()
linelist=content.splitlines()
f.close()
for l in linelist:
print(l)二进制打开
f=open('第七章文件与数据格式化.py','rb')
content=f.read(666)
f.close()
print(content)
3.文件的复制
f=open('屏幕截图 2023-01-15 182940.jpg','rb')
content=f.read()
f.close()
f=open('666666.jpg','wb')
f.write(content)
f.close()
print(content)文件的复制