遗留和现代数据库中的向量搜索
向量数据库是一种将数据(包括文本、图像、音频和视频)存储为向量的数据库,向量是高维空间中对象或概念的数学表示。
注意:根据数据的复杂程度和细节,每个向量的维数可能差别很大,从几个到几千个不等。
1. 介绍
在过去的两到三年里,数据库领域发生了几个关键变化:
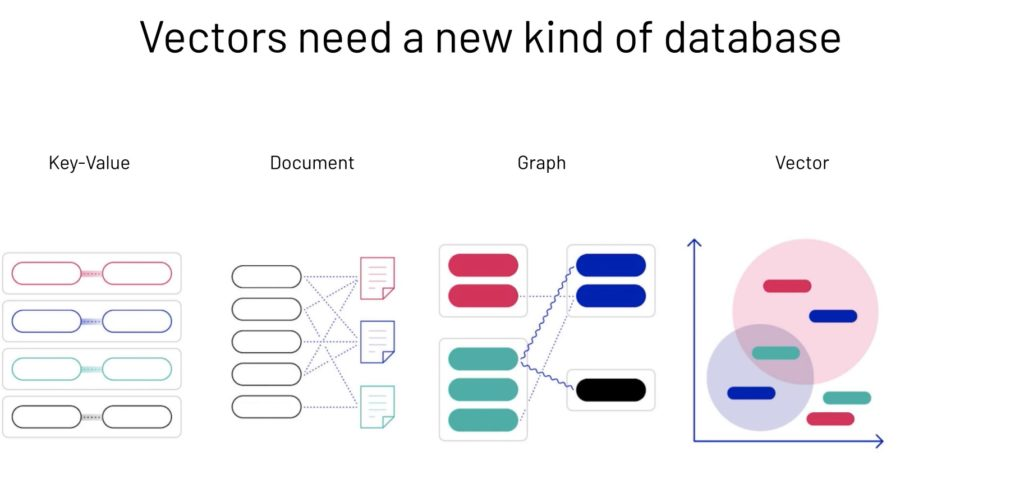
出现了一种新的"向量数据库"类别,其中包括 2019 年的 Milvus、2020 年的 Vespa、2021 年的 Weaviate 和 2022 年的 Qdrant 等开源平台,以及 2019 年推出的 Pinecone 等云解决方案。这些数据库专用于向量搜索,专注于使用各种机器学习模型。然而,它们可能缺乏传统的数据库功能,例如事务、分析、数据复制等
Elasticsearch 在 2019 年增加了向量搜索功能。
随后从 2022 年到 2023 年,包括 Redis、OpenSearch、Cassandra、ClickHouse、Oracle、MongoDB 和 Manticore Search 在内的成熟数据库以及 Azure、Amazon AWS 和 Cloudflare 等云服务开始提供向量搜索功能。
其他知名数据库,如 MariaDB,正在集成向量搜索功能*。
对于 PostgreSQL 用户,'pgvector' 扩展自 2021 年起实现了此功能。
虽然 MySQL 尚未宣布原生向量搜索功能的计划,但 PlanetScale 和 AlibabaCloud 等提供商提供的专有扩展已可用。 
2. 向量数据库如何工作? 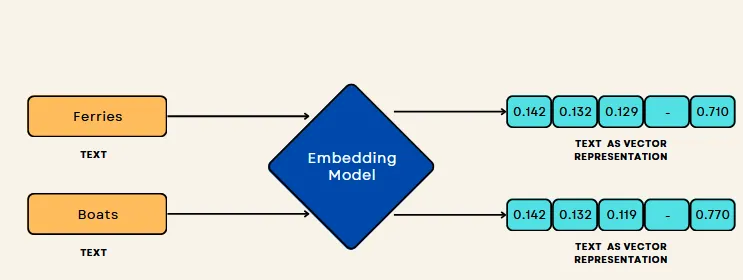
向量数据库的主要优点是能够根据数据与向量的接近度或相似度(转换为向量之后)快速而准确地定位和检索数据。
这样就可以基于语义或上下文相关性进行搜索,而不像传统数据库那样仅仅依赖于精确匹配或设定条件。例如,使用向量数据库,您可以:
-
查找具有相似声音和节奏的歌曲 -
发现具有相同主题和观点的文章 -
识别具有相似功能和评论的产品
向量数据库旨在处理复杂数据,不同于SQL 等以表格格式存储简单数据的传统关系数据库。向量数据库使用不同的方法进行搜索,包括**近似最近邻 (ANN)**搜索技术(如散列和基于图形的搜索)。
注意:要理解什么是 ANN,请想象一下,您有一个拥有数百万本书的大型图书馆。您正试图找到一本与特定书籍(比如说"[古兰经]{.underline}")最相似的书。但是,搜索所有这些书将花费很长时间。这就是 ANN 的作用所在,它无需查看每一本书即可找到最接近的匹配书。它的工作原理如下:
索引:创建一个可以快速指向最相似书籍的特殊索引。
近似值:使用此指数来估计哪本书可能是最接近的匹配。
通过使用 ANN,只需几次迭代就可以找到最近的邻居"我们案例中的书",而不必搜索整个图书馆。
3. 向量空间和向量相似度
让我们讨论一下为什么最近这么多数据库都启用了向量搜索功能,以及它到底是什么。
让我们从一个实际的例子开始。考虑两种颜色:红色,RGB 代码为 (255, 0, 0),橙色,RGB 代码为 (255, 200, 152)。为了比较它们,让我们将它们绘制在三维图上,其中每个点代表不同的颜色,轴对应于颜色的红色、绿色和蓝色成分。然后,我们从图的原点到代表我们颜色的点绘制向量。现在我们有两个向量:一个代表红色,另一个代表橙色。
如果我们想找到这两种颜色之间的相似性,一种方法就是简单地测量向量之间的角度。这个角度可以从 0 到 90 度变化,或者如果我们通过取余弦值对其进行归一化,它将从 0 到 1 变化。然而,这种方法没有考虑向量的大小,这意味着即使颜色 A、A1、A2 代表不同的色调,余弦值也会为它们产生相同的值。
为了解决这个问题,我们可以使用余弦相似度公式,该公式考虑了向量长度------向量点积除以其幅度的乘积。 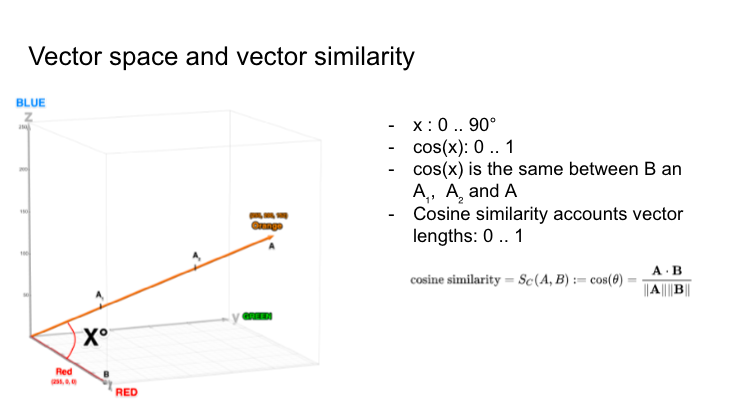
这个概念是向量搜索的精髓。用颜色直观地进行可视化很简单,但现在想象一下,我们有一个数百或数千个维度的空间,而不是三个颜色轴,其中每个轴代表一个物体的特定特征。虽然我们无法轻松地在幻灯片上描绘它或完全可视化它,但从数学上讲这是可行的,原理保持不变:您在多维空间中有向量,然后计算它们之间的相似性。
还有一些其他公式可以找到向量相似度:例如点积相似度和欧几里得距离,但正如 OpenAI API 文档所说,它们之间的差异通常并不重要。 
截图: https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use
4. 向量特征:稀疏向量
因此,一个物体可能具有各种特征。具有红色、绿色和蓝色成分的颜色是最简单的例子。在现实生活中,它通常更复杂。
例如,在文本搜索中,我们可以将文档表示为高维向量。这引出了"词袋"的概念。该模型将文本转换为向量,其中每个维度对应一个唯一的单词,值可能是单词出现的二进制指示符、出现次数或基于其频率和逆文档频率(称为 TF-IDF)的单词权重,这反映了单词对集合中文档的重要性。这被称为稀疏向量,因为大多数值为零,而大多数文档没有太多单词。
当谈到图书馆和搜索引擎(如 Lucene 、 Elasticsearch 和 Manticore Search )中的全文搜索时 ,稀疏向量有助于加快搜索速度。基本上,您可以创建一种特殊的索引,忽略没有搜索词的文档。因此,您不必每次都针对搜索检查每个文档。稀疏向量也很容易理解,从某种意义上说,它们可以进行逆向工程。每个维度都对应一个特定的明确特征,因此我们可以从向量表示追溯到原始文本。这个概念已经存在了大约 50 年。 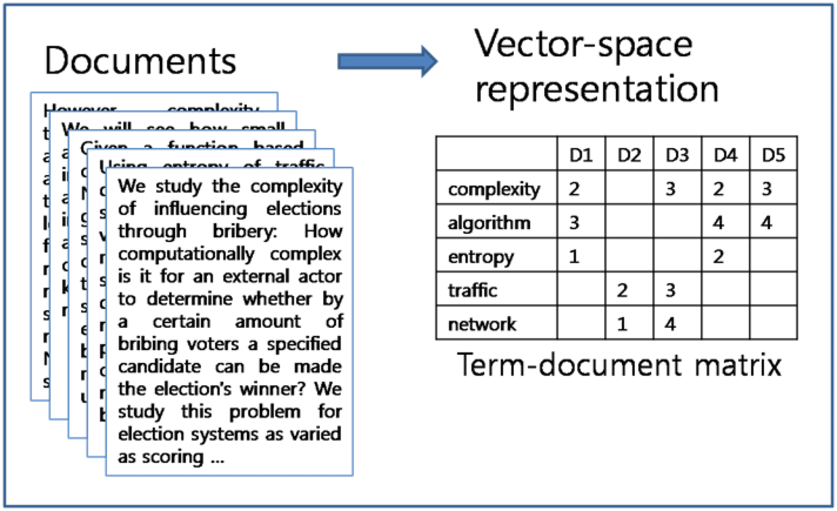
图片: https://www.researchgate.net/figure/Figure4DocumentrepresentationintheVectorSpaceModel22_fig1_312471174
5. 向量特征:密集向量
传统的文本搜索方法(如 TF-IDF )已经存在了几十年,它们会产生依赖于词频的稀疏词向量。主要问题是什么?它们通常忽略了单词的使用背景。例如,"苹果"这个词可能与水果和科技公司相关联,没有任何区别,因此在搜索中可能会对它们进行类似的排名。
但请考虑一下这个类比:在向量空间中,哪两个物体的距离更近:一只猫和一只狗,还是一只猫和一辆车?传统的生成稀疏向量的方法(如下图顶部所示的向量)可能难以提供有意义的答案。稀疏向量通常是高维的,大多数值为零,表示给定文档或上下文中大多数单词的缺失。
随后,深度学习革命兴起,引入了 上下文嵌入 。如图片下部所示,这些是密集的向量表示。与可能有数万个维度的稀疏向量相比,密集向量维度较低(例如图片中的 784 个维度),但却包含连续值,可以捕捉细微的语义关系。这意味着同一个词可以根据其上下文具有不同的向量表示,而不同的词如果具有相同的上下文,则可以具有相似的向量。BERT 和 GPT 等技术使用这些密集 向量 来捕捉复杂的语言特征,包括语义关系、区分同义词和反义词以及理解反讽和俚语------这些任务对于早期的方法来说都相当具有挑战性。
此外,深度学习不仅限于文本,还可以处理图像、音频和视频等复杂数据。这些数据还可以转换为密集的向量表示,用于分类、识别和生成等任务。深度学习的兴起与数据可用性和计算能力的爆炸式增长相吻合,这使得人们能够训练复杂的模型,揭示数据中更深层次、更微妙的模式。 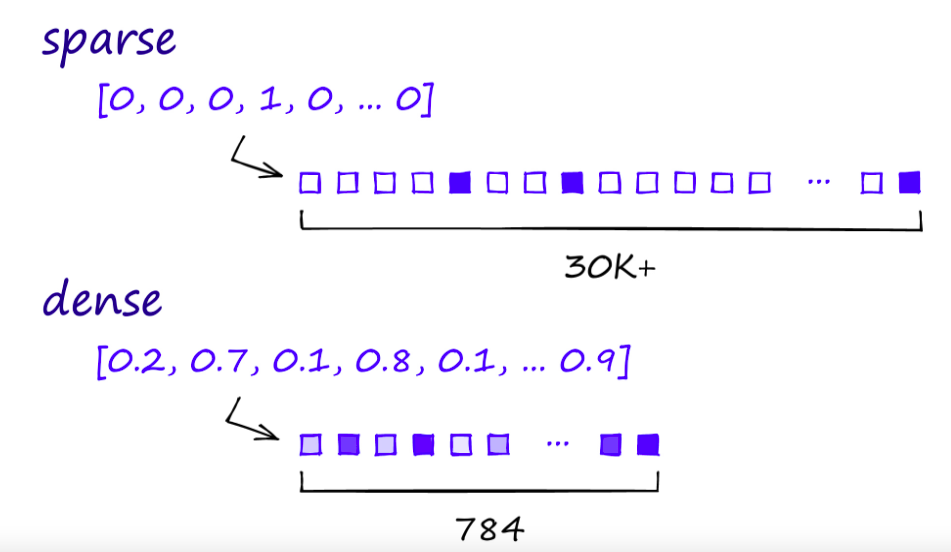
图片: https://cdn.sanity.io/images/vr8gru94/production/96a71c0c08ba669c5a5a3af564cbffee81af9c6d-1920x1080.png
6. 嵌入
此类模型提供的向量称为"嵌入"。重要的是要理解,与之前显示的稀疏向量不同,其中每个元素可以表示一个明确的特征,例如文档中存在的单词,而嵌入的每个元素也代表一个特定的特征,但在大多数情况下,我们甚至不知道该特征是什么。
例如, Jay Alammar 做了一个有趣的实验 ,他使用 GloVe 模型对维基百科进行向量化,然后用不同的颜色可视化一些单词的值。我们可以在这里看到:
各个词语之间出现了一条一致的红线,表明在一个维度上存在相似性,但它所代表的具体属性仍然未知。
诸如"女人"和"女孩"或"男人"和"男孩"等术语在多个维度上表现出相似性,表明存在相关性。
有趣的是,"男孩"和"女孩"与"女人"和"男人"有着明显的相似之处,暗示着青春的潜在主题。
除涉及"水"一词外,所有分析的词都与人有关,其中"水"用于区分概念类别。
除其他术语外,"国王"和"女王"之间的明显相似性可能暗示了皇室的抽象表现。 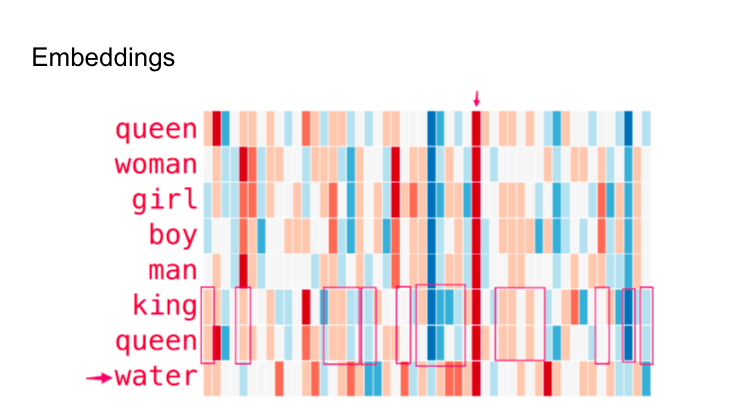
图片: https://jalammar.github.io/illustrated-word2vec/
因此,通过深度学习生成的密集向量嵌入可以以紧凑的形式捕获大量信息。与稀疏向量不同,密集嵌入的每个维度通常都是非零的,并且具有一定的语义意义。这种丰富性是有代价的 - 对于密集嵌入,由于每个维度都密集地填充了值,我们不能简单地跳过不包含特定术语的文档。相反,我们面临着将查询向量与数据集中的每个文档向量进行比较的计算强度。这是一种自然资源密集型的蛮力方法。
然而,已经开发出了专门针对密集向量的索引。这些索引(例如 KD 树、Ball 树或更现代的方法(如 HNSW (分层可导航小世界)图)非常智能,但有时它们需要进行一些猜测才能快速完成。这种猜测可能意味着它们并不总是能 100% 正确地给出答案。数据库采用的最流行的索引是 HNSW,它代表分层可导航小世界。它被 Postgres、 Lucene 、 Opensearch 、 Redis 、 SOLR 、 Cassandra 、 Manticore Search 和 Elasticsearch 的 pgvector 扩展使用。其算法构建了一个多层图结构。每一层都是一个图,其中每个节点(代表一个数据点)都与其最近的邻居相连。底层包含所有节点(数据点),每个连续的上层包含来自下层的节点子集。最顶层具有最少的节点。搜索从上层开始,然后逐渐向下移动到下层。这种分层方法使搜索过程更加高效。简而言之,HNSW 就像任何其他索引一样,只是预先生成一些快捷方式,然后您可以使用这些快捷方式来加快查询处理速度。还有其他向量索引,例如 Spotify 和其他公司维护的 Annoy ,每个索引在性能、资源消耗和准确性损失方面都有各自的优缺点。 
图片: https ://cdn.sanity.io/images/vr8gru94/production/d6e3a660654d9cb55f7ac137a736539e227296b6-1920x1080.png
7. K 近邻
向量搜索实际上是一个涵盖各种任务的总称,例如聚类和分类等。但通常,数据库为向量搜索添加的第一个功能是"K 最近邻搜索"(KNN),或其近亲"近似最近邻搜索"(ANN)。它之所以有吸引力,是因为它使数据库能够找到与给定文档向量最相似的文档,从而增强了数据库的搜索引擎的强大功能,而这是它们以前所缺乏的。
Lucene、Elasticsearch、SOLR 和 Manticore Search 等传统搜索引擎处理各种自然语言处理任务(例如形态学、同义词、停用词和例外情况),所有这些任务都旨在查找与给定查询匹配的文档。KNN 通过不同的方式实现了类似的目标 - 仅比较表中与文档相关的向量,这些向量通常由外部机器学习模型提供。
让我们以 Manticore Search 为例,探索数据库中典型的向量搜索是什么样的。
首先,我们创建一个表,其中有一列标题为 image_vector :
SQL
create table test ( title text, image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2' );
这个向量是 浮点型 ,这一点很重要,因为不支持这种数据类型的数据库必须先添加它,因为密集向量通常存储在浮点数组中。此时,您通常还会通过指定向量维度大小、向量索引类型及其属性来配置字段。例如,我们指定要使用 HNSW 索引,则向量的维数为 5,相似度函数为 l2 ,即欧几里得距离。
然后,我们向表中插入几条记录:
SQL
insert into test values ( 1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821) ), ( 2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406) );
每条记录都有一个标题和一个对应的向量,在现实场景中,该向量可能是深度学习模型的输出,该模型对某种形式的高维数据进行编码,例如图像或声音、文本嵌入或 OpenAI API 中的其他内容。此操作将数据存储在数据库中,并可能触发重建或调整索引。
接下来, 我们利用 KNN 函数执行向量搜索 :
SQL
select id, knn_dist() from test where knn ( image_vector, 5, (0.286569,-0.031816,0.066684,0.032926) );
+------+------------+
| id | knn_dist() |
+------+------------+
| 1 | 0.28146550 |
| 2 | 0.81527930 |
+------+------------+
2 rows in set (0.00 sec)
在这里,我们查询数据库以找到最接近我们指定的输入向量的向量。括号中的数字定义了我们寻找最近邻居的特定向量。对于任何旨在实现向量搜索功能的数据库来说,这一步都至关重要。在此步骤中,数据库可以利用特定的索引方法(例如 HNSW),也可以通过将查询向量与表中的每个向量进行比较来执行强力搜索以找到最接近的匹配项。
返回的结果显示了与输入向量最接近的向量的标题以及它们与查询的距离。距离值越低,表示与搜索查询的匹配程度越高。 
8. 嵌入计算
到目前为止,大多数数据库和搜索引擎都依赖于外部嵌入。这意味着,当您插入文档时,您必须事先从外部源获取其嵌入,并将其包含在文档的其他字段中。搜索类似文档时也是如此:如果搜索的是用户查询而不是现有文档,则需要使用机器学习模型为其计算嵌入,然后将其传递给数据库。此过程可能导致兼容性问题、需要管理额外的数据处理层以及搜索性能的潜在低效。这种方法的操作复杂性也高于必要的复杂性。除了数据库之外,您可能还必须保持另一项服务运行以生成嵌入。
一些搜索引擎,如 Opensearch、Elasticsearch 和 Typesense,现在通过自动创建嵌入来简化事情。他们甚至可以使用其他公司(如 OpenAI)的工具来实现这一点。我认为我们很快就会看到更多这样的情况。更多的数据库将开始自行创建嵌入,这可能会真正改变我们搜索和分析数据的方式。这一变化意味着数据库将不仅仅是存储数据;它们实际上会理解数据。通过使用机器学习和人工智能,这些数据库将变得更智能,能够预测和适应,并以更先进的方式处理数据。
9. 混合搜索方法
一些搜索引擎采用了一种称为混合搜索的方法,该方法将传统的基于关键字的搜索与先进的神经网络技术相结合。混合搜索模型在需要精确关键字匹配(传统搜索技术提供)和更广泛的上下文识别(向量搜索功能提供)的情况下表现出色。这种平衡的方法可以提高搜索结果的准确性。例如, Vespa 通过将 其混合搜索 与经典的 BM25 排名和 ColBERT 模型分别进行比较来测量其准确性 。在他们的方法中,他们使用经典的 BM25 作为第一阶段排名模型,并仅根据 BM25 模型计算排名前 K 个文档的混合分数。结果发现,混合搜索模式在大多数测试中都优于它们中的每一个。
另一种更简单的方法是倒数排名融合 (RRF),这是一种将不同搜索算法的排名相结合的技术。RRF 根据每个列表中的排名计算每个项目的分数,排名越高,得分越高。分数由公式 1 / (排名 + k) 确定,其中"排名"是项目在列表中的位置,"k"是用于调整较低排名影响的常数。通过对来自每个来源的这些修改后的倒数排名进行求和,RRF 强调了不同系统之间的共识。这种方法融合了各种算法的优势,从而产生更强大、更全面的搜索结果。 
表格: https://blog.vespa.ai/improving-zero-shot-ranking-with-vespa-part-two/
公式: https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
10. 优质向量数据库的特点
-
可扩展性:处理海量数据集并适应插入率、查询率和硬件的变化。 -
多用户支持:优先考虑多用户应用程序的数据隔离。 -
全面的 API 套件:提供全套 API 和 SDK,实现与各种应用程序的无缝交互。 -
用户友好界面:减少学习曲线并提供便捷的功能导航。 -
数据集成与可视化:实现与其他数据源(关系数据库、云存储服务)的无缝集成,并提供探索和理解数据的可视化工具。 -
支持其他数据格式:支持各种文件类型(图像、音频文件......)并包括不同格式的转换和处理工具。 -
自动化数据清理和预处理:自动化执行标准化、过滤噪音/异常值和处理缺失值等任务,以确保数据干净可靠。
11. 选择前的最佳实践
-
分析您的需求:评估您的项目需求,包括数据类型、数量和性能期望。 -
评估功能:根据您的需求评估速度、可扩展性和数据保护等功能。 -
考虑社区:选择一个拥有活跃社区的数据库来获得支持和资源。 -
测试数据库:尝试不同的数据库以确保兼容性和最佳性能。 -
预算和安全考虑:考虑安全问题、预算限制和知识产权保护等因素,确定您是否需要开源或闭源数据库。
12. 如果您有预算,您需要考虑开源 VDB?
-
社区支持:您需要访问一个庞大且活跃的开发人员和用户社区,他们可以帮助您解决问题或进行改进(您将面临同样的挑战)。 -
灵活性:您需要有修改软件来满足您的特定需求的能力。 -
成本效益:您不想支付许可费、订阅费或隐藏费用。 -
透明度:您希望确切了解软件的工作原理并信任其功能。 -
持续改进:您希望获得一个不断发展的解决方案,该解决方案能够借助社区的贡献与最新的功能和改进保持同步。
13. 结论
向量搜索不仅仅是一个概念或搜索引擎的一项小众功能;它是一种实用工具,可以改变我们检索数据的方式。近年来,数据库领域发生了重大变化,新的以向量为中心的数据库不断涌现,而老牌数据库也增加了向量搜索功能。这反映了对更高级搜索功能的强烈需求,而向量搜索可以满足这一需求。像 HNSW 这样的高级索引方法使向量搜索速度更快。
展望未来,我们预计数据库将不仅仅支持向量搜索;它们可能会自己创建嵌入。这将使数据库更易于使用且功能更强大,将它们从基本存储空间转变为可以理解和分析数据的智能系统。简而言之,向量搜索是数据管理和检索的重大转变,标志着该领域的一项令人振奋的发展。
本文由 mdnice 多平台发布








![[每周一更]-(第99期):MySQL的索引为什么用B+树?](https://img-blog.csdnimg.cn/direct/28d4ab14d98a4c1789188140397bafac.jpeg#pic_center)