一、模块
1-1 Python 自带模块
Json模块
处理json数据
'{"key":"value"}'
json不是字典 本质是一个有引号的字符串数据
json注意点 {} 中的数据是字符串引号必须是双引号
使用json模块可以实现将json转为字典,使用字典的方法操作数据 。 或者将字典转为json
json数据可以实现不同程序之间传递数据
比如使用json将python程序的数据传递java程序
-
json.dumps()
-
json.loads()
# json模块使用
# 导入模块
import json # 直接导入模块
# 1-打开读取jiso文件
with open('D:/Python大数据就业/4-Python基础/day07-模块-网络-多任务/4-资料/order_detial.json','r',encoding='utf-8') as f:
data_lines = f.readlines()
print(data_lines)
# 2- 对读取的文件数据进行处理
# 需要将每行的json数据转为字典处理
for line in data_lines:
# 对每行数据去除\n
line_str = line.replace('\n','')
print(line_str)
# 将json字符串转为字典 loads 将字典数据转为json字符串 json_str = json.dumps(字典数据)
# 如果直接导入模块 需要使用 模块名.函数() 模块名.变量
line_dict = json.loads(line_str)
print(type(line_dict))
# 使用字典操作方法处理数据
total_price= line_dict['total_price']
print(total_price)
Datetime模块
处理日期时间数据的
# 日期时间模块
from datetime import datetime,timedelta
# 获取当前日期时间
dt_now = datetime.now()
print(dt_now)
# 获取时间戳 timestamp需要将日期传递到方法中
unixtime_now = datetime.timestamp(dt_now)
print(unixtime_now)
# 将时间戳数据转为datetime时间
dt = datetime.fromtimestamp(1617021920)
print(dt)
# 日期的加减
# 获取加减的时间单位
t = timedelta(days=7)
dt_add = dt_now + t
print(dt_add)
dt_sub = dt_now - t
print(dt_sub)
# 字符串时间 转为datetime类型的时间
dt_str = '2017-10-20 15:20:22'
dt2 = datetime.strptime(dt_str,'%Y-%m-%d %H:%M:%S')
print(type(dt2))
# 将datetime类型数据转为 字符串
dt_now_str = dt_now.strftime('%Y/%m/%d %H:%M:%S')
print(dt_now_str)
Decimal模块
处理小数数据
类型是双精度浮点 保证小数计算时精度的准确性,一般在进行价格金额计算时使用
# Decimal模块使用
# 导入模块中的所有函数,类,变量
from decimal import *
# 将小数数据转为Decimal
d = Decimal(3.1415926)
print(d)
# 指定保留小数 会进行四舍五入
d2 = d.quantize(Decimal('0.000'))
print(d2)
d3 = Decimal(5.123).quantize(Decimal('0.000'))
d4 = d2+d3
print(d4)
random模块
随机产生数据
# random使用 # 将randint函数通过as命名了一个别称 # randint 可以根据指定范围随机产生一个整数数据 from random import randint as rt num = rt(0,3) print(num) name = ['张三','李四','王五','赵六','aa','bb'] # 随机产生下标 index = rt(0,len(name)-1) print(name[index]) # 验证码 date_str = '123456789asdfghjklqwertyuiopzxcvbnm' index1 = rt(0,len(date_str)-1) index2 = rt(0,len(date_str)-1) index3 = rt(0,len(date_str)-1) index4 = rt(0,len(date_str)-1) code = date_str[index1] + date_str[index2] + date_str[index3] +date_str[index4] print(code)
1-2 三方模块
第三方开发的代码文件,上传到python的官方模块库中,方便其他开发人员使用
把代码开源个其他程序员
使用三方模块需要进行下载
pip下载安装
pip是python自带的包模块管理工具
清华大学源:Simple Index
阿里云源:Simple Index
中国科技大学源:Simple Index
豆瓣源:http://pypi.douban.com/simple/
pip install 模块名==版本 -i 安装源
安装爬虫模块
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
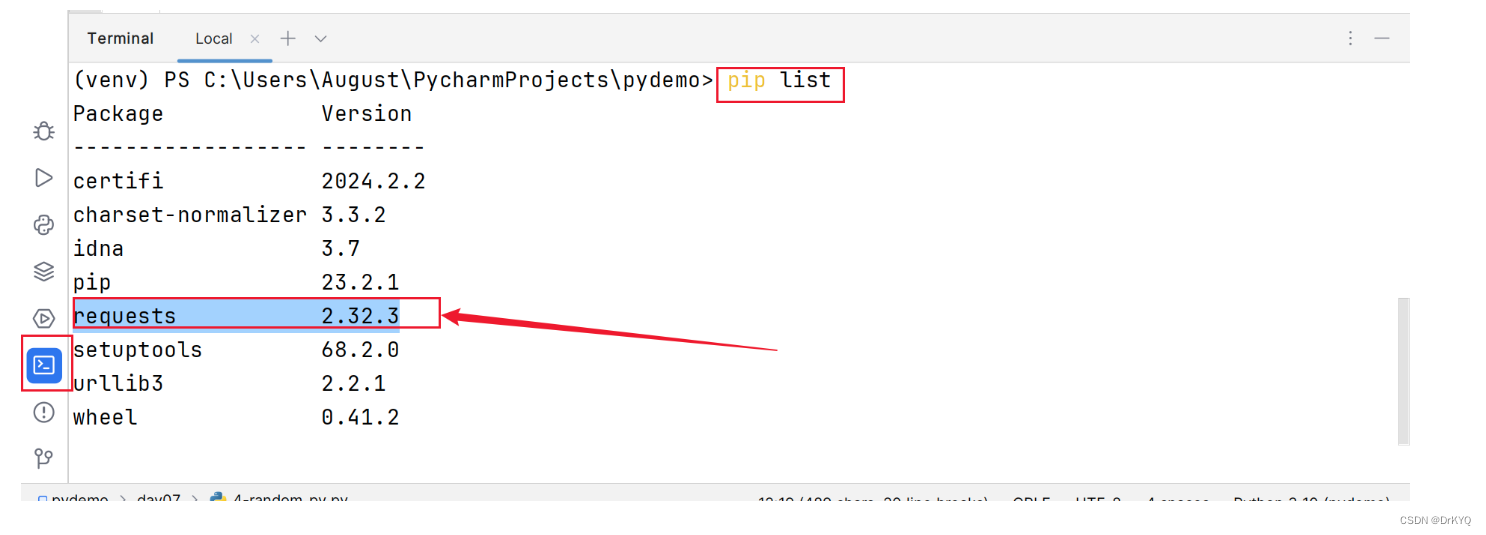
查看是否安装成功
pip list
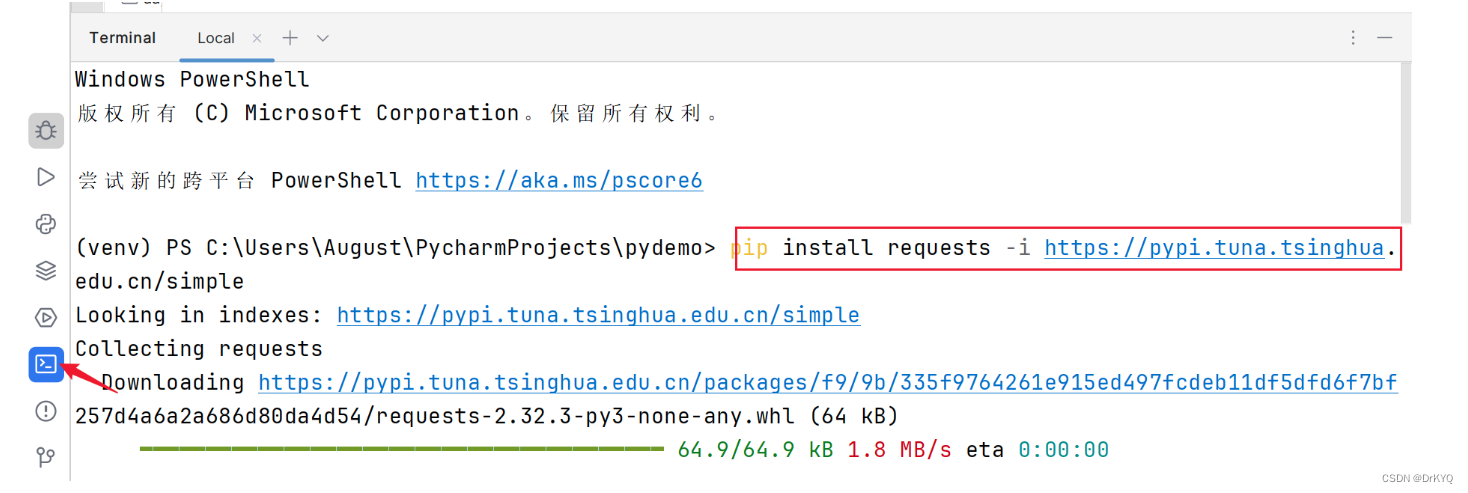
whl文件安装
1-从官网下载whl文件 PyPI · The Python Package Index

2-在进行pip安装
pip install whl文件位置
-
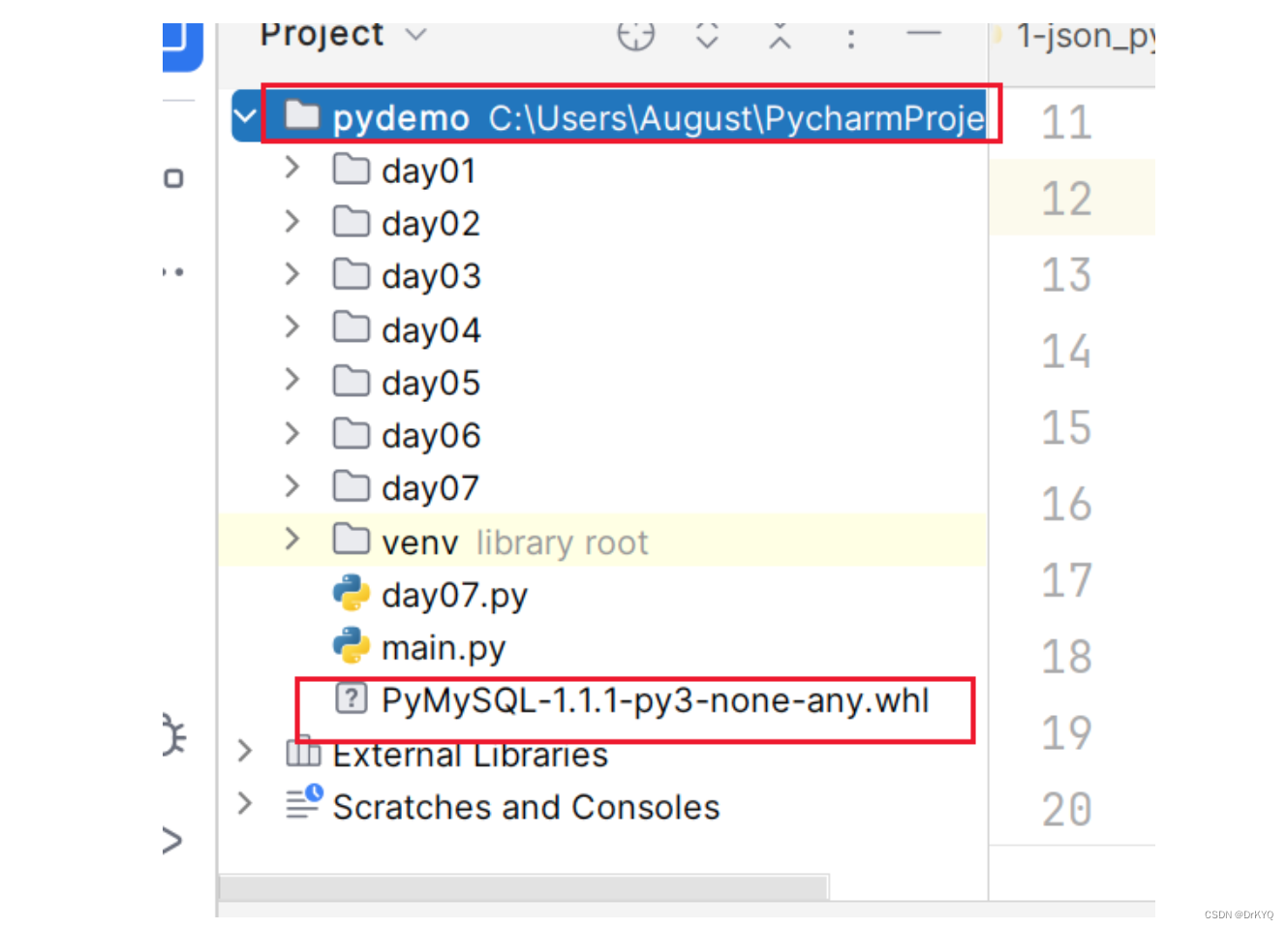
安装pymysql模块

1-3 requests模块使用(拓展)
可以数据采集,测试开发
网络通讯介绍
网络通讯就是程序之间进行通讯,相互传递数据内容
网络通讯三要素
(1)IP地址:网络虚拟环境下的唯一标识,类似于人的身份证号,通过IP可以找到计算机;
(2)端口:表示计算机中某软件的地址信息,通过端口可以找到计算机中的软件;
(3)协议:协议就是通信规则,程序之间必须按照规则传递信息,否则双方无法识别彼此信息
网络通讯模型
C/S模型
C:client
S:server
B/S模型
B:brower
S:server
TCP协议
规定了程序之间的
通讯方式TCP是双向通讯,类似手机通话 双方可以进行数据传递操作
UDP是单向通讯,类似广播 只能有一个人传递数据,其他人等待接收数据
安全数据传输方式是TCP
1-先连接对方程序,连接成功后会返回确认信息。 确认网络是否通畅
2-向对方程序发送数据,对方接受数后,会返回确认信息
3-数据发送完成,会在发送一个关闭连接的消息,对方接受到消息后就知道发送完成
HTTP协议
规定了程序之间的
通讯数据格式web开发中使用浏览器作为客户端,在进行数据传递时,使用http协议,规定了数据的格式
请求的数据格式 也叫作请求报文
请求行 GET / HTTP/1.1
GET 请求方式 表示获取数据
POST 请求方式 上传数据
请求头
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 代表设备信息
头部中没有user-agent会认为是一个爬虫程序
请求体
携带请求数据
响应的数据格式 叫作响应报文 返回的结果不符合格式,就无法被浏览器解析获取
响应行 HTTP/1.1 200 ok
HTTP/1.1 http协议斑斑
200 响应状态 成功 400表示失败 404 找不到页面资源
ok 响应的信息
响应头部
Content-Type: text/html; charset=utf-8 指定返回的数据形式 html前端页面
Server:BWS/1.1 服务名称
响应体
返回处理后的数据给浏览器
json
html页面
图片
视频
音频
requests使用
数据采集的本质就是使用程序模拟浏览器的行为
Requests: HTTP for Humans™ — Requests 2.32.3 documentation
采集网址
返回json数据
天气接口网址:https://api.oioweb.cn/api/weather/weather?city_name=北京市
返回网页html数据
传智图书库: 图书列表 - 传智教育图书库
-
获取json数据
# 请求服务器获取json数据
import requests
# 1-发送请求
# 定义请求网址
url = 'https://api.oioweb.cn/api/weather/weather?city_name=上海市'
# 定义请求头部数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
# 发送get请求
respose = requests.get(url,headers=headers) # 定义变量接收响应的数据
# 对返回的json数据进行解析,转为字典
response_dict = respose.json()
print(response_dict)
# 提取需要的字段数据
# 获取风向数据
wind_direction = response_dict['result']['wind_direction']
print(wind_direction)
-
获取html页面数据
xpath语法 XPath 教程
html是标签语言,使用xpath可以提取标签中的数据
额外需要模块
lxml模块 将页面数据转为标签元素数据element,就可以使用xpath语法
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
# 获取html页面中数据
import requests
from lxml import etree
# 1-发送请求
# 定义请求网址
url = 'https://resource.ityxb.com/booklist/find.html?cz-pc-dh'
# 定义请求头部数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
# 发送get请求
respose = requests.get(url,headers=headers) # 定义变量接收响应的数据
# 获取html的页面数据
html_text = respose.text
# 将html页面转为element元素数据
html_element = etree.HTML(html_text)
# 使用xpath语法开发获取数据
book_name1 = html_element.xpath('//*[@id="content-container"]/div[2]/div[3]/div/div[1]/div[1]/div[2]/p/a/text()')[0]
book_name2 = html_element.xpath('//*[@id="content-container"]/div[2]/div[3]/div/div[1]/div[2]/div[2]/p/a/text()')[0]
book_name3 = html_element.xpath('//*[@id="content-container"]/div[2]/div[3]/div/div[1]/div[3]/div[2]/p/a/text()')[0]
book_name4 = html_element.xpath('//*[@id="content-container"]/div[2]/div[3]/div/div[1]/div[4]/div[2]/p/a/text()')[0]
print(book_name1)
print(book_name2)
print(book_name3)
print(book_name4)
1-4 pymysql模块使用(拓展)
PyMySQL documentation — PyMySQL 0.7.2 documentation
操作mysql数据库
# 使用pymysql模块操作数据
import pymysql
# 创建mysql的连接
clinet = pymysql.connect(host='localhost',port=3306,user='root',password='root')
# 生成游标操作数据库
cur = clinet.cursor()
# 数据库操作
# 本质是写sql语句,写在字符串中
sql_str = '''
create database if not exists pydata45 charset=utf8
'''
# 执行sql
cur.execute(sql_str)
# 创建表
sql_str2 = '''
create table if not exists pydata45.user(
id int,
name varchar(20),
age int,
gender varchar(20)
)
'''
# 执行sql语句
cur.execute(sql_str2)
# 写入数据
# 将列表数据写表中
sql_str3 = '''
insert into pydata45.user values(%s,%s,%s,%s)
'''
data_list= [1,'张三',20,'男']
# 执行写入语句
cur.execute(sql_str3,data_list)
# 写入数据必须有commit
clinet.commit()
# 将字典数据写入进入
sql_str4 = '''
insert into pydata45.user values(%(id)s,%(username)s,%(age)s,%(gender)s)
'''
data_dict= {'id':2,'username':'李四','age':20,'gender':'男'}
# 执行写入语句
cur.execute(sql_str4,data_dict)
# 写入数据必须有commit
clinet.commit()
# 查询写入的数据
sql_str5 = '''
select * from pydata45.user
'''
# 执行sql语句
cur.execute(sql_str5)
# 获取查询的数据
data = cur.fetchall()
print(data)
# 关闭连接
cur.close()
clinet.close()
1-5 自定义模块
本质就是编写一个python文件
文件名要符合python的命名规范
-
定义一个模块文件
# 自定义的模块文件 # 封装业务代码 name = '张三' def add_func(a,b): data = a+b return data class Student: def __int__(self,name,age): self.name = name self.age = age def func(self): print(self.name) print(self.age)
-
其他开发人员使用模块文件
# 开发人员自己的代码文件
from itcast import name,add_func,Student
print(name)
res = add_func(10,20)
print(res)
s = Student('张三',20)
s.func()







![[每周一更]-(第99期):MySQL的索引为什么用B+树?](https://img-blog.csdnimg.cn/direct/28d4ab14d98a4c1789188140397bafac.jpeg#pic_center)