文章目录
- 一、ELK简介
- 1.1 ELK的作用与应用
- 1.2 ELK的组成
- 1.3 Elasticsearch
- 1.4 Logstash
- 1.5 Kibana
- 1.6 ELK架构简述
- 1.7 基础知识
- 1.7.1 数据格式
- 1.7.2 正排索引和倒排索引
- 1.7.3 全文搜索
- 二、ES入门---基于HTTP的使用方式(了解)
- 2.1 索引操作
- 2.1.1 创建索引
- 2.1.2 查询索引
- 2.1.3 删除索引
- 2.1.4 索引映射关系
- 2.2 文档操作
- 2.2.1 创建文档
- 2.2.2 查询文档
- 2.2.3 更新文档
- 2.2.4 删除文档
- 三、ES入门---基于Java API的使用方式(了解)
- 3.1 环境准备
- 3.2 一般流程
- 3.3 索引操作
- 3.3.1 创建索引
- 3.3.2 查询索引
- 3.3.3 删除索引
- 3.3.4 索引映射关系
- 3.4 文档操作
- 3.4.1 创建文档
- 3.4.2 查询文档
- 3.4.3 更新文档
- 3.4.4 删除文档
- 四、Kibana的使用(重要)
- 4.1首页菜单列表说明
- 4.2 Discover详讲
- 4.2.1 菜单/功能选项
- 4.2.2 通过日志进行故障排查的思路
- 4.2.3 待补充内容
- 参考链接
一、ELK简介
1.1 ELK的作用与应用
作用:ELK 是一个用于数据收集、分析和展示的开源技术栈。
应用:日志分析、应用程序监控、运营智能、安全审计等多种场景,其中日志分析最具有代表性。
1.2 ELK的组成
ELK包含Elasticsearch,Logstash和Kibana三个核心组件,ELK即这三个核心组件的首字母,这些核心组件的详细介绍见后文。
1.3 Elasticsearch
Elasticsearch基于Apache Lucene构建,是一个全文搜索和分析引擎,通常简称ES,主要特点如下:
- 它采用了分布式架构,支持水平扩展,能够收集和存储大量数据,并提供近乎实时地、高效地搜索和分析功能。
- 通过RESTful API方式进行交互,使用起来简单十分方便。
- 功能强大,提供了高级查询与分析功能,如复杂查询和聚合操作。
1.4 Logstash
Logstash是一款开源的数据收集和处理引擎,常常作为连接数据源和数据存储/分析系统的数据管道,从不同源头接收数据(输入),经过一系列处理(过滤)后,再将处理后的数据传输到对应的目的地(输出)。这一过程是实时发生的,适合处理大量且高速流动的数据流。
输入:可以从文件系统、消息队列、数据库、网络协议等接收数据。
过滤:在数据在传输过程中,使用过滤插件对数据进行处理,让原始数据变得结构化且易于分析。
输出:处理后的数据可以被发送到多个目的地,常见的输出包括Elasticsearch、文件系统、消息队列、数据库等。
1.5 Kibana
是ELK中的一个开源的数据分析与可视化平台,使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作,并利用图表、表格及地图对数据进行多元化的分析和呈现。
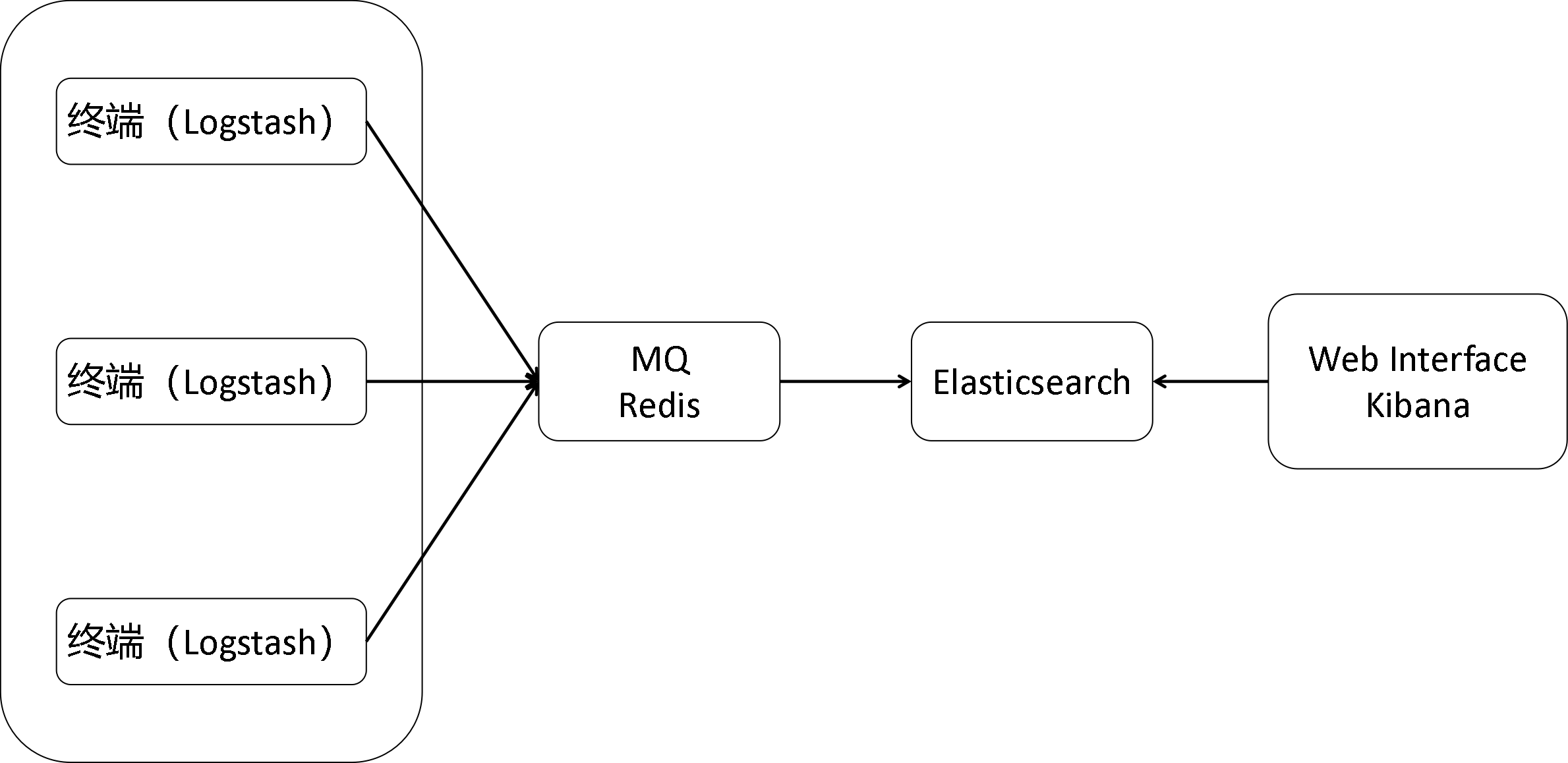
1.6 ELK架构简述
在多个设备上使用Logstash来收集并处理数据,然后将数据统一汇总到Elasticsearch。
为避免Elasticsearch过载,可以将Logstash处理完的数据先汇总到Redis或MQ上,再异步地汇总到Elasticsearch。
用户通过Kibana来使用ELK,Kibana提供了功能界面和结果展示,具体的搜索和分析功能实际是通过调用Elasticsearch完成的。
1.7 基础知识
1.7.1 数据格式
ES是面向文档型数据库,数据存储有三层维度,从大到小分别是索引、文档、字段。
数据库由多个索引组成,每个索引中存放了许多文档,每个文档中包含许多字段。
需要注意的是,这里的文档并不是指文件,而是由多个字段组成的数据,字段由字段名和字段值组成,类似于键值对,此时文档可以类比为一个json数据。
1.7.2 正排索引和倒排索引
正排索引和倒排索引都是信息检索系统中常用的索引结构,主要用于提高数据查询的效率,在文本搜索领域有着广泛的应用。
正排索引:记录了从文档(唯一标识符)到关键字的映射,用于已知文档求关键字的场景。
倒排索引:记录了从关键字到文档(唯一标识符)的映射,用于已知关键字求文档的场景。
1.7.3 全文搜索
是一种在非结构化数据中(如文档、网页、数据库记录等)查找包含特定关键词或短语的技术。它允许用户在一篇文章、一段文字、一本书籍或整个文档集合中搜索内容。
二、ES入门—基于HTTP的使用方式(了解)
ES集群间组件的通信端口:9300
RESTful API的对应端口:9200
2.1 索引操作
向ES服务器发送HTTP请求,通过RESTful API完成CRUD操作。
2.1.1 创建索引
通过PUT请求创建索引。
创建名为new_index的索引:http://localhost:9200/new_index。
2.1.2 查询索引
通过GET请求查询索引。
查询名为new_index的索引:http://localhost:9200/new_index。
查询所有索引:http://localhost:9200/_cat/indices?v。
2.1.3 删除索引
通过DELETE请求删除索引。
删除名为new_index的索引:http://localhost:9200/new_index。
2.1.4 索引映射关系
ES中可以通过映射关系来设置哪些字段用于索引,被索引时是否支持分词操作。
通过PUT请求或GET在new_index索引创建或查询映射关系,请求地址都为:http://localhost:9200/new_index/_mapping。
在创建映射关系时,需要使用请求体来设置具体的映射关系:
{
"properties" : {
"字段1" : {
"type" : "text", // type为text表示该字段支持分词,为keyword表示不支持分词
"index" : true // index为true表示该字段支持使用索引查询,为false则不支持
},
"字段2" : {
"type" : "keyword",
"index" : false
}
}
}
2.2 文档操作
2.2.1 创建文档
通过POST请求创建文档,在请求体中给出文档的字段信息。
在new_index索引中创建_id字段为new_doc的文档:http://localhost:9200/new_index/_doc/new_doc。
注意1:在索引名后要加上/_doc,表示是创建文档操作。
注意2:在/_doc之后可以加上指定的id,若没有加上,则会随机生成一个id。
{
"title":"苹果",
"category":"水果"
}
2.2.2 查询文档
通过GET请求实现查询文档的操作。
主键查询
在new_index索引中查询_id字段为new_doc的文档:http://localhost:9200/new_index/_doc/new_doc。
如果没找到该文档,那么响应体的found值为false。如果找到了该文档,那么响应体的found值为true,文档的字段信息会放入响应体的_source中。
全查询
在new_index索引中查询所有文档:http://localhost:9200/new_index/_search。
查询的文档信息列表放在了响应体的hits中。
条件查询 + 字段过滤、分页、排序
在new_index进行查询:http://localhost:9200/new_index/_search。
在请求体中实现条件查询、字段过滤、分页、排序、高亮等操作:
- 使用
query关键字给出查询条件(例子给出的是使用字段等值匹配的条件查询)。 - 使用
_source关键字来进行字段过滤(指定查询的具体字段)。 - 使用
from和size关键字来实现分页查询。 - 使用
sort关键字来对结果进行排序。
{
"query" : {
"match" : {
"字段名" : "字段值"
}
},
"from" : 0,
"size" : 2,
"_source" : ["字段1", "字段5"],
"sort" : {
"第一个排序字段的字段名" : {
"order" : "desc"
},
"第二个排序字段的字段名" : {
"order" : "asc"
}
}
}
组合查询和范围查询
使用组合查询时,要在query.bool来设置:
- 多个条件需要同时满足时使用
must关键字来设置,多个条件只需要满足其中一个时使用should关键字来设置,其值为一个列表,每个列表元素对应一个条件。 - 范围查询时通过过滤来实现的,需要使用
filter.range关键字来设置,其中gt、lt、gte、lte分别表示大于、小于、大于等于和小于等于。(g表示greater,l表示less,e表示equal)
{
"query" : {
"bool" : {
"must" : [
{
"match" : {
"字段1" : "值1"
}
},
{
"match" : {
"字段2" : "值2"
}
}
],
"filter" : {
"range" : {
"age" : {
"gt" : 5000
}
}
}
}
}
}
条件查询的匹配规则
使用match进行匹配时,会先对给出的匹配值进行分词(如划分为一个个单一的字),然后使用这些分词通过倒排索引来查询文档。因此,只要文档匹配其中任意一个分词,都会被查询出来,而不是说必须完全匹配给出的匹配值。如查询手机品牌为“华米”的文档,那么手机品牌为华为、小米和红米的文档都会被查询出来,尽管手机品牌为华米的文档一个都不存在。
若要求完全匹配,那就不能使用match,此时要换为match_phrase。
聚合查询
在查询的基础上,通过请求体设置聚合操作。
常见的聚合操作有:统计数量(terms)、分组并求均值(avg)
{
"aggs" : { // 表示聚合操作
"price_group" : { // 统计结果的名称,名称是自定义的
"terms" : { // 分组并统计数量
"field" : "price" // 统计或分组字段
}
}
},
"size" : 0 // 默认会在"hits"中显示完整数据,这样可以不用显示
}
2.2.3 更新文档
通过PUT请求实现全量修改文档的操作。
对于全量修改,请求体中需要包含该文档进行全量修改后的所有字段以及它们的最新数据。
请求的url为:http://localhost:9200/index/_doc/xyz。
请求体和新增时的一致。
通过POST请求实现局部修改文档的操作。
对于局部修改,请求体中仅需包含该文档中进行局部修改的字段以及它们的最新数据。
请求的url为:http://localhost:9200/index/_update/xyz。(\_update表明是修改,\_doc,表明是新增)
请求体也有所变化。
{
"doc":{
"需要修改的字段名":"修改后的值"
}
}
2.2.4 删除文档
通过DELETE请求实现删除文档的操作。
主键删除
在index索引中删除_id字段为xyz的文档:http://localhost:9200/index/_doc/xyz。
三、ES入门—基于Java API的使用方式(了解)
3.1 环境准备
略
3.2 一般流程
// 1. 创建ES客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("hostname", port, "http"))
);
// 2. 完成操作
// 2.1 获取对应的请求对象
// 2.2 设置请求参数
// 2.3 使用客户端调用相应的方法执行操作,并得到响应结果
// 2.4 查看/处理响应结果
...
// 3. 关闭ES客户端(这里需要处理异常)
esClient.close();
3.3 索引操作
3.3.1 创建索引
...
// 1. 创建请求对象
CreateIndexRequest req = new CreateIndexRequest("index_name");
// 2. 创建索引:使用ES客户端调用创建索引的方法,获取响应
CreateIndexResponse res = esClient.indices().create(req, RequestOptions.DEFAULT);
// 3. 获取响应状态,判断成功还是失败
boolean acknowledged = res.isAcknowledged();
...
3.3.2 查询索引
...
// 1. 创建请求对象
GetIndexRequest req = new GetIndexRequest("index_name");
// 2. 查询索引:使用ES客户端调用查询索引的方法,获取响应
GetIndexResponse res = esClient.indices().get(req, RequestOptions.DEFAULT);
// 3. 从响应中获取索引信息
...
3.3.3 删除索引
...
// 1. 创建请求对象
DeleteIndexRequest req = new DeleteIndexRequest ("index_name");
// 2. 删除索引:使用ES客户端调用删除索引的方法,获取响应
DeleteIndexResponse res = esClient.indices().delete(req, RequestOptions.DEFAULT);
// 3. 获取响应状态,判断成功还是失败
boolean acknowledged = res.isAcknowledged();
...
3.3.4 索引映射关系
// 1. 创建请求对象
CreateIndexRequest request = new CreateIndexRequest("index_name");
// 2. 创建XContentBuilder来构建映射
XContentBuilder mappingBuilder = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("字段1")
.field("type", "text")
.endObject()
.startObject("字段2")
.field("type", "keyword")
.field("analyzer", "ik_max_word") // 使用IK分词器
.endObject()
.endObject()
.endObject();
// 3. 构建请求参数并执行
request.mapping(mappingBuilder);
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
3.4 文档操作
3.4.1 创建文档
** 创建单个文档**
...
// 1. 创建请求对象
IndexRequest req = new IndexRequest();
// 2. 设置文档的索引和id(流式操作)
req.index("index_name").id("doc_id");
// 3. 准备文档数据(json字符串)
// (下例通过ObjectMapper实现对象转json)
User user = new User();
user.setName("小明");
user.setGender("男");
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString();
// 4. 将文档数据放入请求体
req.source(json, XContentType.JSON);
// 5. 创建文档并返回结果
IndexResponse res = esClient.index(req, RequestOptions.DEFAULT);
...
批量创建多个文档
...
// 1. 创建请求对象
BulkRequest req = new BulkRequest();
// 2. 创建多个文档数据
// 2.1 按单次插入的方式准备IndexRequest对象
// 2.2 然后将这些IndexRequest对象添加到BulkRequest对象
req.add(indexReq1);
req.add(indexReq2);
req.add(indexReq3);
// 3. 执行批量创建文档的操作
BulkResponse res = esClient.bulk(req, RequestOptions.DEFAULT);
...
3.4.2 查询文档
主键查询
...
// 1. 创建请求对象
GetRequest req = new GetRequest();
// 2. 设置文档的索引和id(流式操作)
req.index("index_name").id("doc_id");
// 3. 查询文档并返回结果
GetResponse res = esClient.get(req, RequestOptions.DEFAULT);
// 4. 获取文档数据
// 4.1 Map类型的文档数据:res.getSource();
// 4.2 json类型的文档数据:res.getSourceAsString();
...
条件查询 + 字段过滤、分页、排序、高亮
注意1:字段过滤,分页,排序,高亮是通过SearchSourceBuilder对象设置的。
注意2:查询条件是通过QueryBuilder设置的,具体的QueryBuilder对象是通过QueryBuilders回去的。
注意3:QueryBuilder对象是作为SearchSourceBuilder对象的query参数使用的,而SearchSourceBuilder对象是作为请求体的source参数使用的。
注意4:全查询以及其他高级查询,主要是使用了特定的QueryBuilder,其他部分基本一致。
...
// 1. 创建请求对象
SearchRequest req = new SearchRequest();
// 2. 设置文档的索引
req.indices("index_name");
// 3. 创建SearchSourceBuilder对象
SearchSourceBuilder ssBuilder = new SearchSourceBuilder();
// 4. 字段过滤
String[] includes = {"希望查询的字段"}
String[] excludes = {"希望过滤的字段"}
ssBuilder.fetchSource(includes, excludes);
// 5. 分页
ssBbuilder.from(0);
ssBbuilder.size(2);
// 6. 排序
ssBbuilder.sort("排序字段", SortOrder.DESC);
// 7. 高亮(本质是在高亮字段的值前后加上字符串)
HighlightBuilder hBuilder = new HighL
lightBuilder();
hBuilder.preTags("<font color='red'>");
hBuilder.postTags("</font>");
bBuilder.field("高亮的字段");
// 8. 获取条件查询的QueryBuilder对象(但条件完全匹配为例)
TermsQueryBuilder tqBuilder = queryBuilders.termsQuery("字段名","匹配值");
// 9. 准备请求参数
builder.query(tqBuikder);
req.source(ssBuilder);
// 10. 查询并返回结果
SearchResponse res = esClient.search(req, RequestOptions.DEFAULT);
// 11. 获取结果中的文档
SearchHits hits = res.getHits();
条件查询的匹配规则
使用queryBuilders.termsQuery时是完全匹配。
使用queryBuilders.matchQuery时是分词匹配。
全查询
...
MatchQueryBuilder mqBuilder = QueryBuilders.matchAllQuery();
ssBuilder.query(mqBuilder);
...
组合查询
多个条件的组合查询通过BoolQueryBuilder实现。
...
BoolQueryBuilder bqBuilder = new BoolQueryBuilder();
bqBuilder.must(queryBuilders.termsQuery("字段名1","匹配值1"););
bqBuilder.mustNot(queryBuilders.termsQuery("字段名2","匹配值2"););
bqBuilder.should(queryBuilders.termsQuery("字段名3","匹配值3"););
ssBuilder.query(bqBuilder);
...
范围查询
范围查询通过QueryBuilders.rangeQuery()实现。
...
// 年龄大于18小于等于60
RangeQueryBuilder rqBuilder = QueryBuilders.rangeQuery("age");
rqBuilder.gt(18);
rqBuilder.lte(60);
ssBuilder.query(rqBuilder);
...
模糊查询
模糊查询通过QueryBuilders.fuzzyQuery()实现。
模糊查询时要设置模糊度,即允许相差的字符个数,通过fuzzyQuery()的参数设置。
...
FuzzyQueryBuikder fqBuilder = QueryBuilders.fuzzyQuery("字段名", "匹配值").fuzziness(Fuzziness.ONE);
ssBuilder.query(fqBuilder);
...
聚合查询和分组
相较于条件查询,相当于将QueryBuilder换成了AggregationBuilder,并将SearchSourceBuilder对象调用的方法换成了aggregation。
AggregationBuilder通过AggregationBuilders获取,特定的聚合操作用相应的AggregationBuilder即可。聚合查询如max,分组查询如terms(分组并统计数量)。
...
AggregationBuilder aBuilder = AggregationBuilders.max("统计结果名称").field("统计或分组字段");
ssbuilder.aggregation(aBuilder);
...
3.4.3 更新文档
全量修改
// 1. 创建请求对象
UpdateRequest updateRequest = new UpdateRequest(indexName, id);
// 2. 设置具体的全量修改
updateRequest.doc(updatedDocJson, XContentType.JSON); // 提供完整的新文档内容
updateRequest.upsert(updatedDocJson, XContentType.JSON); // 如果文档不存在,则插入新文档
// 3. 更新文档并返回结果
UpdateResponse updateResponse = esClient.update(updateRequest, RequestOptions.DEFAULT);
局部修改
...
// 1. 创建请求对象
UpdateRequest req = new UpdateRequest();
// 2. 设置文档的索引和id(流式操作)
req.index("index_name").id("doc_id");
// 3. 准备局部修改的数据
req.doc(XContentType.JSON, "要修改的字段名", "修改后的值");
// 4. 更新文档并返回结果
UpdateResponse res = esClient.update(req, RequestOptions.DEFAULT);
...
3.4.4 删除文档
主键删除
...
// 1. 创建请求对象
DeleteRequest req = new DeleteRequest();
// 2. 设置文档的索引和id(流式操作)
req.index("index_name").id("doc_id");
// 3. 删除文档并返回结果
DeleteResponse res = esClient.delete(req, RequestOptions.DEFAULT);
...
批量删除
类似于批量创建多个文档~
四、Kibana的使用(重要)
无论是RESTful API的方式还是Java API的方式,使用ES都不太方便。大多数场景,我们都可以借助Kibana的可视化界面来完成操作。
4.1首页菜单列表说明
- Discover(数据探索):用于搜索、浏览和交互ES中的数据。
- Visualize(可视化):让用户能够将数据转化为各种图表形式。
- Dashboard(仪表盘):允许用户将多个可视化组件组合到一个可交互的界面上,形成一个综合的数据监控面板。
- Timelion(时序控件):专注于时间序列数据的可视化。
- Canvas(画布):允许用户通过自由布局、艺术设计和技术功能的结合,将ES中的数据转变为富有吸引力和互动性的信息图。
- Management(管理):是进行系统和数据源配置的地方,让用户能够配置Kibana设置、索引模式(Index Patterns)、空间(Spaces)、 Saved Objects(已保存对象)等。
4.2 Discover详讲
4.2.1 菜单/功能选项
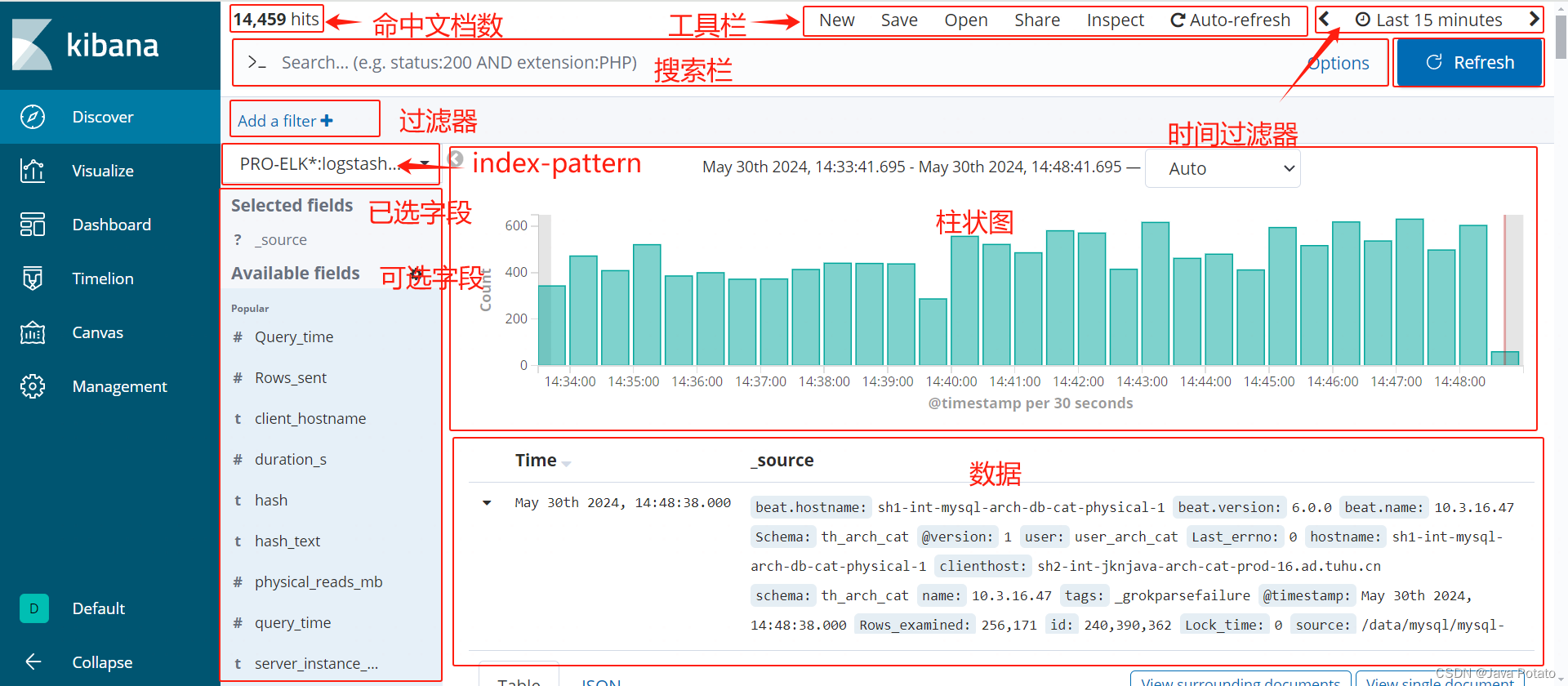
index-pattern
Kibana使用索引模式来组织ES索引,通过*来匹配一组具有相似命名模式的索引,这组索引在过滤时能用作条件的索引字段是相同的,在查询结果中能展示的字段也是相同的。索引模式由运维创建和维护。
过滤器
每次点击过滤器添加按钮可以添加一个过滤条件,此时可以选择条件字段、过滤规则,并填写相应的过滤条件参数。其中,可选的条件字段是索引模式中所设置的,使用的匹配模式是完全匹配,多个过滤条件之间是且关系。此外,filter也支持使用Elasticsearch Query DSL来设置过滤条件。
字段
这里指查询结果中展示的字段。当选定一个索引模式后,就会在可选字段部分列出能看到的所有字段,从中选择并添加希望展示的字段,已选择的字段会在已选字段中展示。若没有选择,默认展示所有字段。
补充:可选字段前面的前缀#、t、?分别表示number类型、text类型和位置类型的字段,其中位置类型的字段不能用于discover查询和visualize可视化。
时间过滤
时间过滤器根据@timestamp作为过滤字段,提供了多种方便快捷的时间过滤方式。
也可以直接点击时间柱状图的柱子进行时间过滤。
搜索栏
使用搜索栏时要遵循Kinana查询语法,可以用,但没必要。
进行一些简单的条件筛选时,通常使用filter,而不必手写查询条件。
进行一些复杂的条件筛选时,如聚合查询、多条件查询,此时可以使用filter并以Elasticsearch Query DSL方式实现。
工具栏
New:允许用户创建新的查询、可视化或仪表板。
Save:用于保存当前正在编辑或配置的查询、可视化或仪表板。
Open:允许用户打开之前保存的查询、可视化或仪表板。
Share:使用户能够分享当前的查询、可视化或仪表板给其他Kibana用户。
Inspect:此功能主要用于查看和分析Kibana发送到ES的底层请求详情。
Auto-refresh:允许用户设置一个时间间隔,在该间隔时间内,Kibana会自动重新加载或更新当前页面上的数据视图,比如仪表板或可视化。用于监控实时数据流、跟踪最新指标或在故障排查时持续观察系统状态。
4.2.2 通过日志进行故障排查的思路
关注于一些关键字段
- requestId:单词请求的唯一标识。
- applicationName:应用AppId。
- message:具有可读性的信息。
- url:调用地址。
- 具有标识作用的字段:如订单号,手机号。
链路追踪:
- 根据关键字寻到requestId
- 根据requestId查询调用链路
- 分析错误依赖的上下游,根据remotename判断调用方
- 异步调用时,RequestId可能存在没有透传,一般通过上下游链路透传的某一参数进行查询
4.2.3 待补充内容
// to do
参考链接
ELK详解(一)——ELK基本原理
Kibana用户手册