前言
深度学习技术在当今技术市场上面尚有余力和开发空间的,主流落地领域主要有:视觉,听觉,AIGC这三大板块。
目前视觉板块的框架和主流技术在我上一篇基于Yolov7-LPRNet的动态车牌目标识别算法模型已有较为详细的解说。与AIGC相关联的,其实语音模块在近来市场上面活跃空间很大。
从智能手机的语音助手到智能家居中的语音控制系统,再到银行和电信行业的语音身份验证,语音技术的应用日益广泛。那么对应现在ACG技术是可以利用原音频去进行训练学习,从而得到相对应的声音特征,从而进行模仿,甚至可以利用人工智能生成的语音可以以假乱真,给社会带来了严重的安全隐患。
当前,语音深度鉴伪识别技术已经取得了一定的进展。研究人员利用机器学习和深度学习方法,通过分析语音信号的特征,开发出了一系列鉴伪算法。
然而,随着生成大模型和其他语音合成技术的不断进步,伪造语音的逼真度也在不断提高,使得语音鉴伪任务变得愈加复杂和具有挑战性。本项目系列文章将从最基础的语音数据存储和详细分析开始,由于本系列专栏是有详细解说过深度学习和机器学习内容的,音频数据处理和现主流技术语音分类模型和编码模型将会是本项目系列文章的主体内容,具体本项目系列要讲述的内容可参考下图:
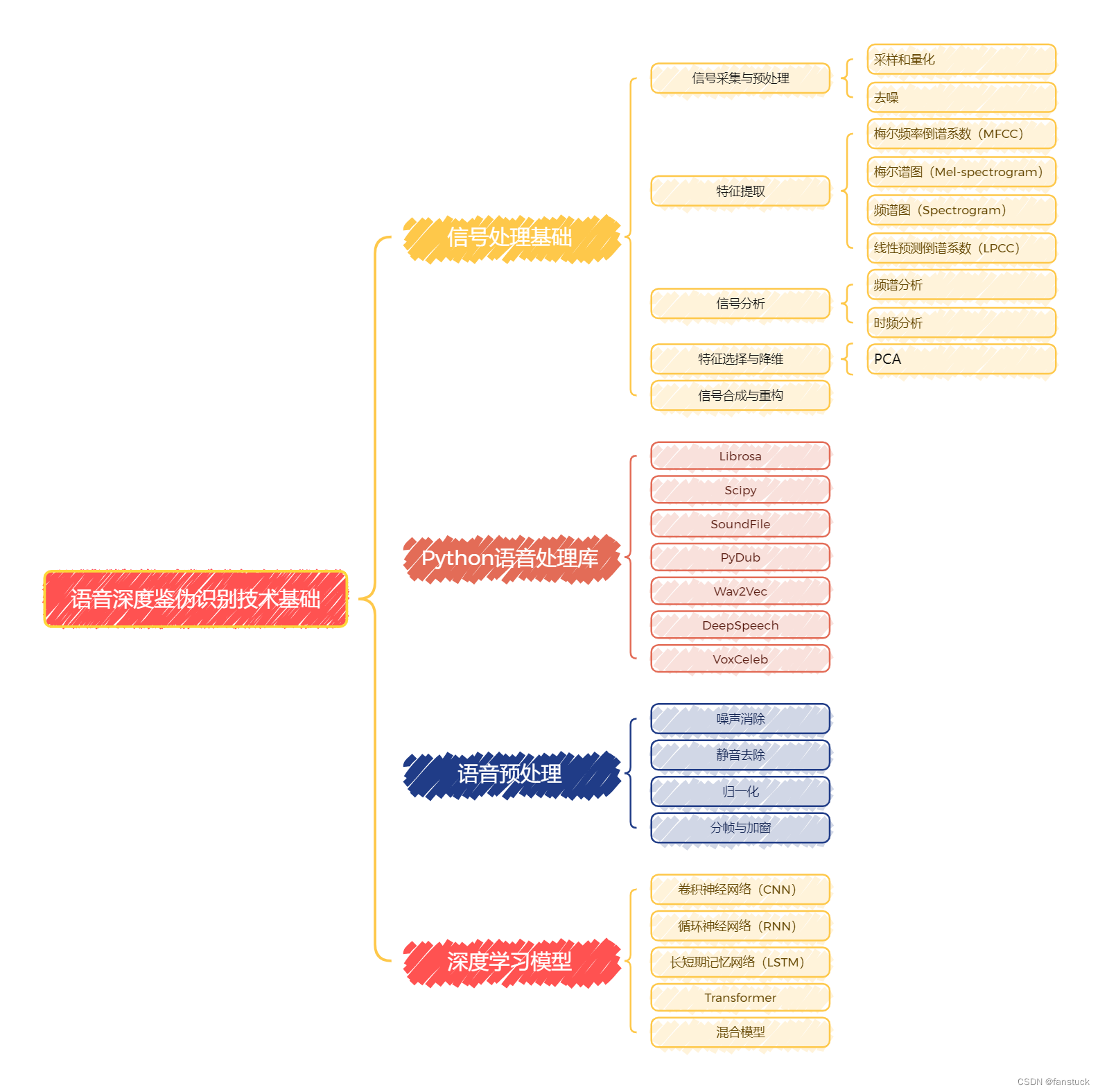 语音模型的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容。
语音模型的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容。
我将尽力让大家了解并熟悉神经网络框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练这些知识。希望有需求的小伙伴不要错过笔者精心打造的专栏。
上篇文章详细解答了所有音频常见存储载体和其特征,以及音频的数据保存形态有哪些?具体数据可视化展示为何种形式?这类问题,对音频数据认知打下了坚实的基础。那么第二章我们就应该对音频数据预处理有大致的了解,从噪音的种类再到各个去噪算法依次了解,那么我们的语音深度鉴伪识别才算入门。
一、音频存储载体
由于音频存储是根据音频数据编码来的,上篇文章已经几乎把所有的音频编码算法都讲解了,固不再重复将每个音频存储载体具体信息详细,只作概览:
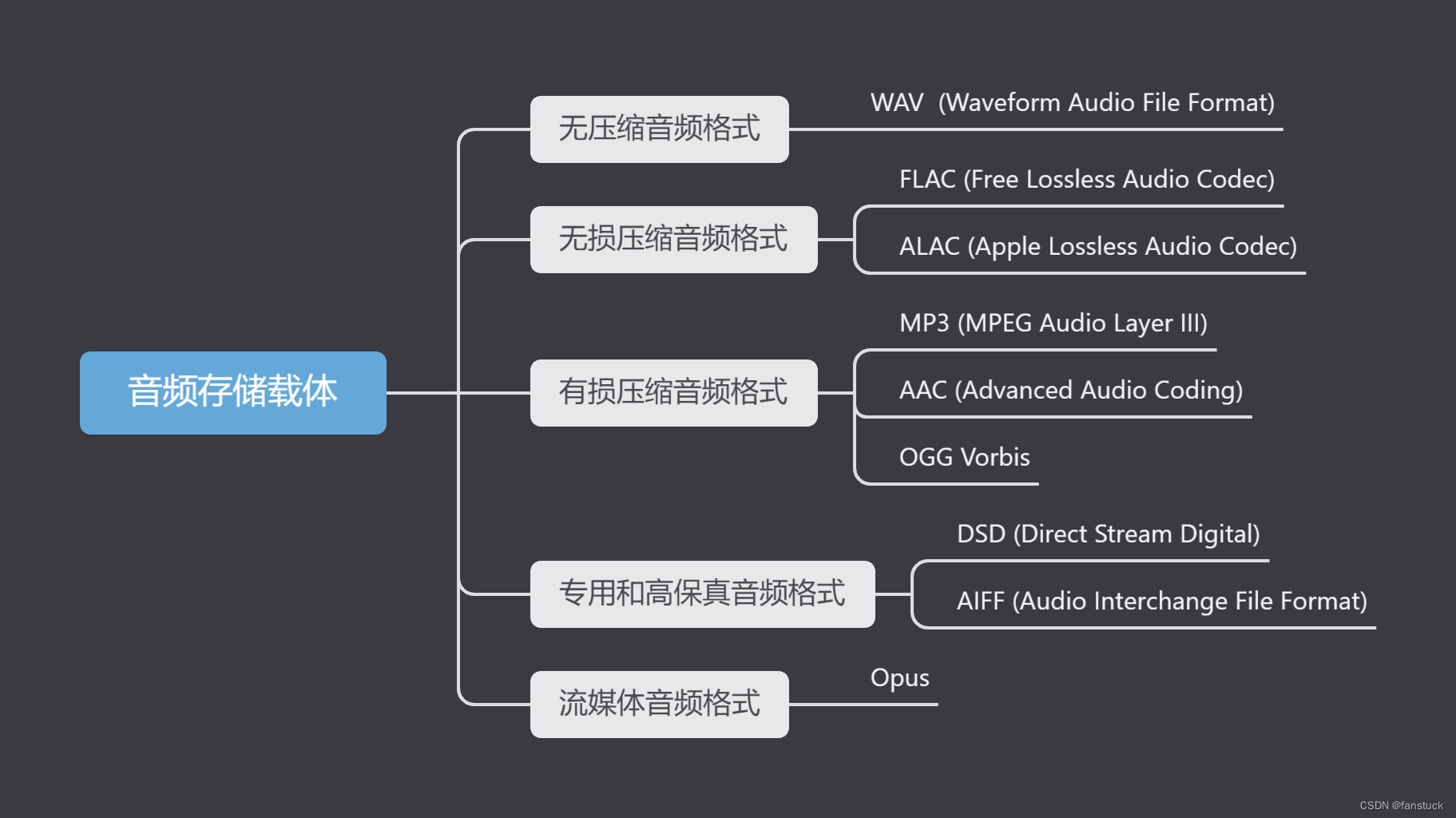
综合比较
| 格式 | 压缩类型 | 音质 | 文件大小 | 主要应用 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| WAV | 无压缩 | 高 | 大 | 音频编辑 | 高质量 | 文件大 |
| FLAC | 无损压缩 | 高 | 中 | 音频存储 | 高质量,文件较小 | 文件仍较大 |
| ALAC | 无损压缩 | 高 | 中 | 苹果设备 | 高质量,兼容苹果 | 跨平台支持少 |
| MP3 | 有损压缩 | 中 | 小 | 音乐存储、传输 | 文件小,支持广泛 | 音质低 |
| AAC | 有损压缩 | 中高 | 小 | 流媒体、移动设备 | 高效压缩,音质好 | 普及度略低 |
| OGG Vorbis | 有损压缩 | 中高 | 小 | 游戏音频、流媒体 | 高质量,开源 | 支持较少 |
| DSD | 无压缩 | 极高 | 极大 | 高保真音频 | 超高保真度 | 文件极大,支持有限 |
| AIFF | 无压缩 | 高 | 大 | 苹果设备 | 高质量 | 文件大 |
| Opus | 有损压缩 | 高 | 小 | 流媒体、实时通信 | 低延迟,高质量 | 存储应用少 |
二、音频数据预处理
既然我们现在已经通过python去尝试了构建一个wav音频文件,自然我们也可以通过编码方式对原有音频进行数据处理,使其音频质量,如后续有建模的必要这会是关键步骤,一切模型都离不开数据质量。和图片去噪的方式也是大相径庭,那么现在我们来实践操作。首先,确保安装了pydub库和ffmpeg:
pip install pydub
sudo apt-get install ffmpeg
如果需要更细粒度的控制,需要使用numpy和scipy生成纯音乐。
pip install numpy scipy soundfile
生成音乐片段:
import numpy as np
import soundfile as sf
def generate_sine_wave(frequency, duration, sample_rate=44100):
"""生成指定频率和持续时间的正弦波"""
t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False)
return 0.5 * np.sin(2 * np.pi * frequency * t)
# 定义音符(频率)和节拍(秒)
notes = {
'C4': 261.63,
'D4': 293.66,
'E4': 329.63,
'F4': 349.23,
'G4': 392.00,
'A4': 440.00,
'B4': 493.88,
'C5': 523.25
}
# 定义乐曲:每个音符和相应的持续时间(秒)
melody = [
('C4', 0.5), ('D4', 0.5), ('E4', 0.5), ('F4', 0.5),
('G4', 0.5), ('A4', 0.5), ('B4', 0.5), ('C5', 0.5)
]
# 生成乐曲
sample_rate = 44100
song = np.array([])
for note, duration in melody:
tone = generate_sine_wave(notes[note], duration, sample_rate)
song = np.concatenate([song, tone])
# 保存生成的纯音乐
sf.write('pure_music.wav', song, sample_rate)
print("纯音乐生成完毕并保存为pure_music.wav")
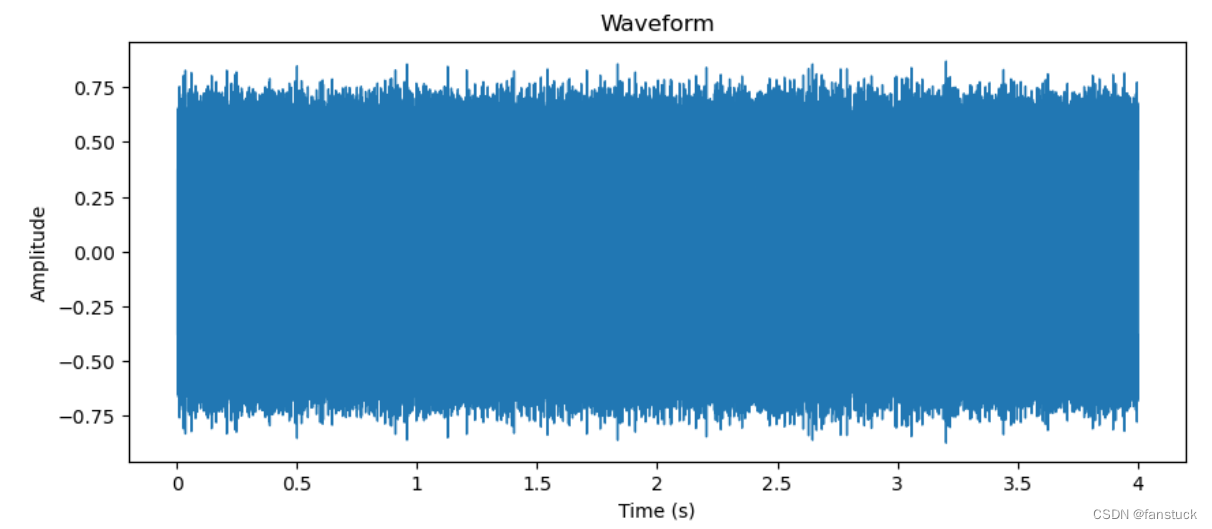
我们可以通过使用matplotlib和librosa.display库绘制音频波形图和梅尔频谱图,来帮助我们更好观测音频数据特征:
import matplotlib.pyplot as plt
import librosa.display
def plot_waveform_and_spectrogram(file_path):
audio_data, sample_rate = librosa.load(file_path, sr=None)
# 绘制波形图
plt.figure(figsize=(10, 4))
librosa.display.waveshow(audio_data, sr=sample_rate)
plt.title('Waveform')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.show()
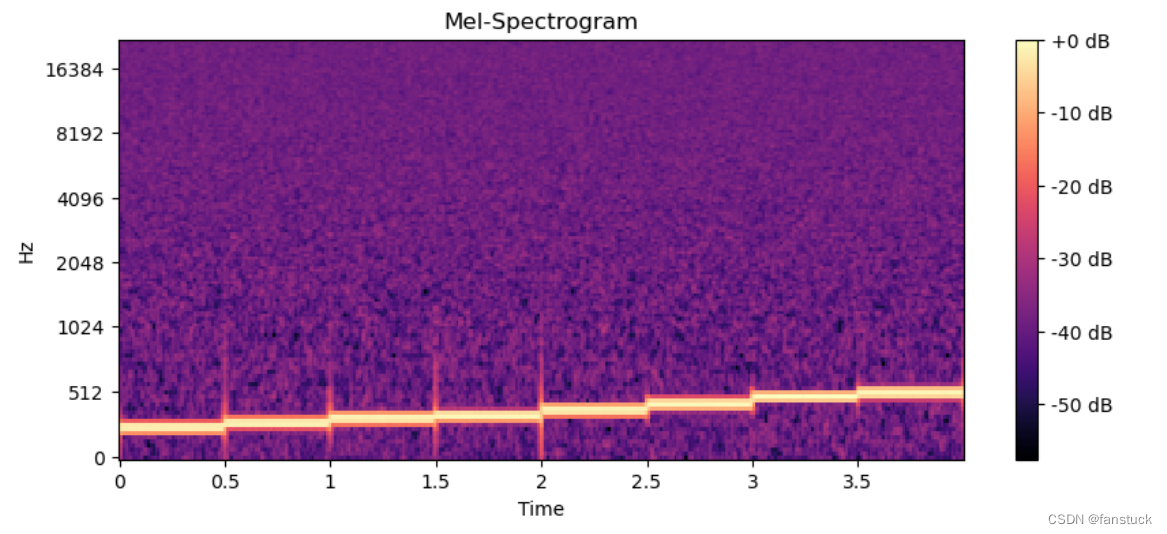
# 计算梅尔频谱图
mel_spectrogram = librosa.feature.melspectrogram(y=audio_data, sr=sample_rate, n_mels=128)
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram, ref=np.max)
# 绘制梅尔频谱图
plt.figure(figsize=(10, 4))
librosa.display.specshow(log_mel_spectrogram, sr=sample_rate, x_axis='time', y_axis='mel')
plt.title('Mel-Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.show()
# 示例:绘制WAV文件的波形图和频谱图
file_path = 'pure_music.wav'
plot_waveform_and_spectrogram(file_path)
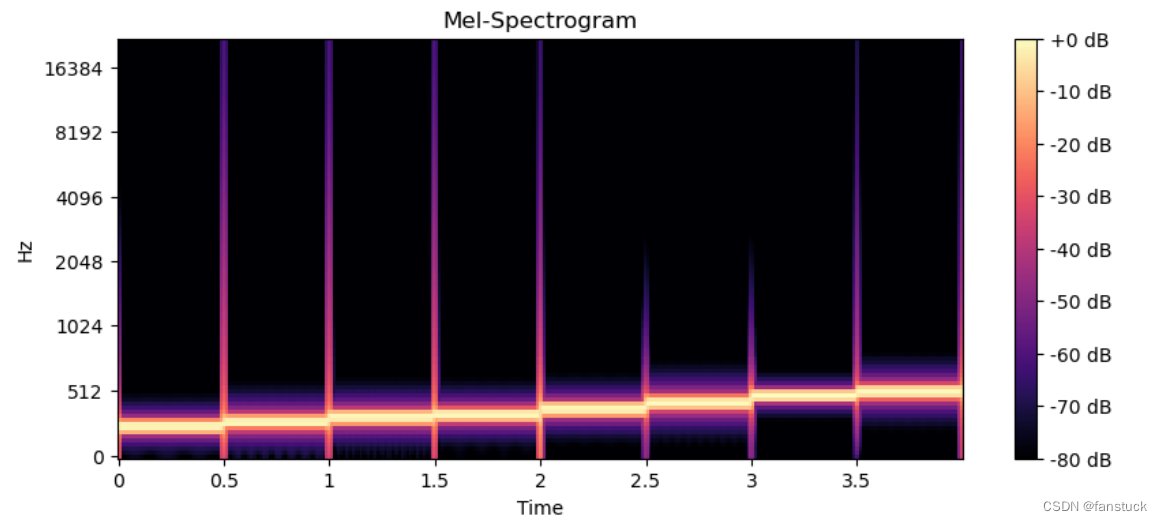
接下来我们通过引入不同的噪音种类,认识噪音种类并尝试辨别哪些噪音种类,最后进行音频去噪。
2.1噪音种类
每种噪音的特征和来源不同,可能会对音频信号的质量产生不同的影响。
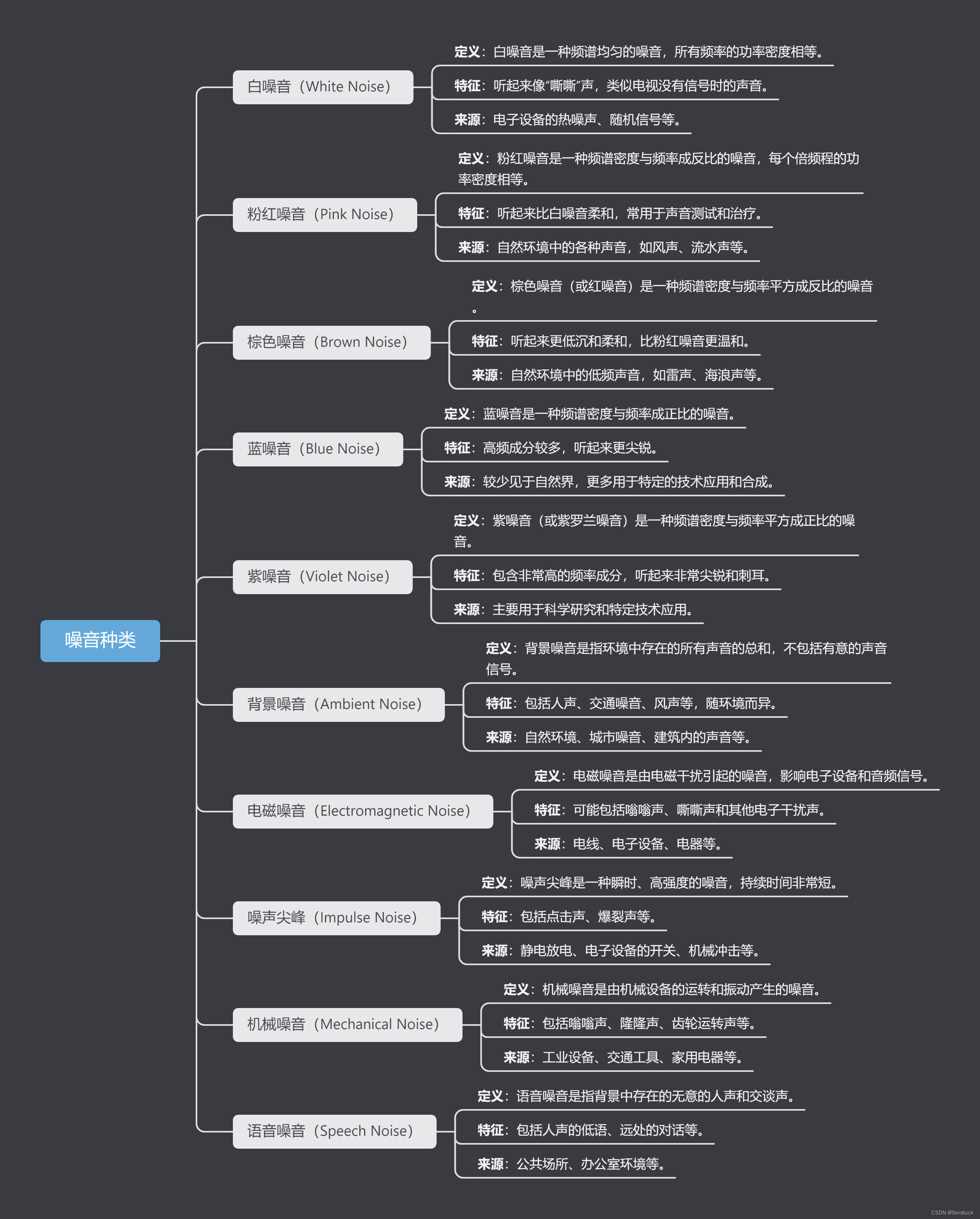
2.1.1. 白噪音
我们来尝试制作白噪音,从制作过程中就能看到特征种类:
import numpy as np
import soundfile as sf
def generate_white_noise(duration, sample_rate):
"""生成指定持续时间的白噪音"""
noise = np.random.normal(0, 1, int(sample_rate * duration))
return noise
# 生成5秒白噪音
sample_rate = 44100
duration = 5.0
white_noise = generate_white_noise(duration, sample_rate)
# 保存白噪音
sf.write('white_noise.wav', white_noise, sample_rate)
该白噪音一听就能够辨别出来,十分明显。听起来像“嘶嘶”声,类似电视没有信号时的声音。
2.1.2.粉红噪音
听起来比白噪音柔和,常用于声音测试和治疗。类似自然环境中的各种声音,如风声、流水声等。
import numpy as np
import soundfile as sf
def generate_pink_noise(duration, sample_rate):
"""生成指定持续时间的粉红噪音"""
white = np.random.randn(int(sample_rate * duration))
fft = np.fft.rfft(white)
fft = fft / np.sqrt(np.arange(1, len(fft) + 1))
pink = np.fft.irfft(fft)
return pink
# 生成5秒粉红噪音
sample_rate = 44100
duration = 5.0
pink_noise = generate_pink_noise(duration, sample_rate)
# 保存粉红噪音
sf.write('pink_noise.wav', pink_noise, sample_rate)
2.1.3.棕色噪音(Brown Noise)
听起来更低沉和柔和,比粉红噪音更温和。自然环境中的低频声音,如雷声、海浪声等。
import numpy as np
import soundfile as sf
def generate_brown_noise(duration, sample_rate):
"""生成指定持续时间的棕色噪音"""
white = np.random.randn(int(sample_rate * duration))
brown = np.cumsum(white) / np.sqrt(sample_rate)
return brown
# 生成5秒棕色噪音
sample_rate = 44100
duration = 5.0
brown_noise = generate_brown_noise(duration, sample_rate)
# 保存棕色噪音
sf.write('brown_noise.wav', brown_noise, sample_rate)
还有更多噪音这里暂且不作更多生成展示,不同类型的噪音在日常生活和各种技术应用中都可能出现,后续处理这些噪声方面会介绍的更加详细。最主要的我们需要花更多的时间去学习如何运用去噪算法,如何选着合适的去噪算法,达到想要的去噪效果。
2.2去噪算法
不同类型的噪音需要采用不同的去噪算法才能达到效果,下面我们来看看都有哪些去噪算法,都可以适用哪些噪音:
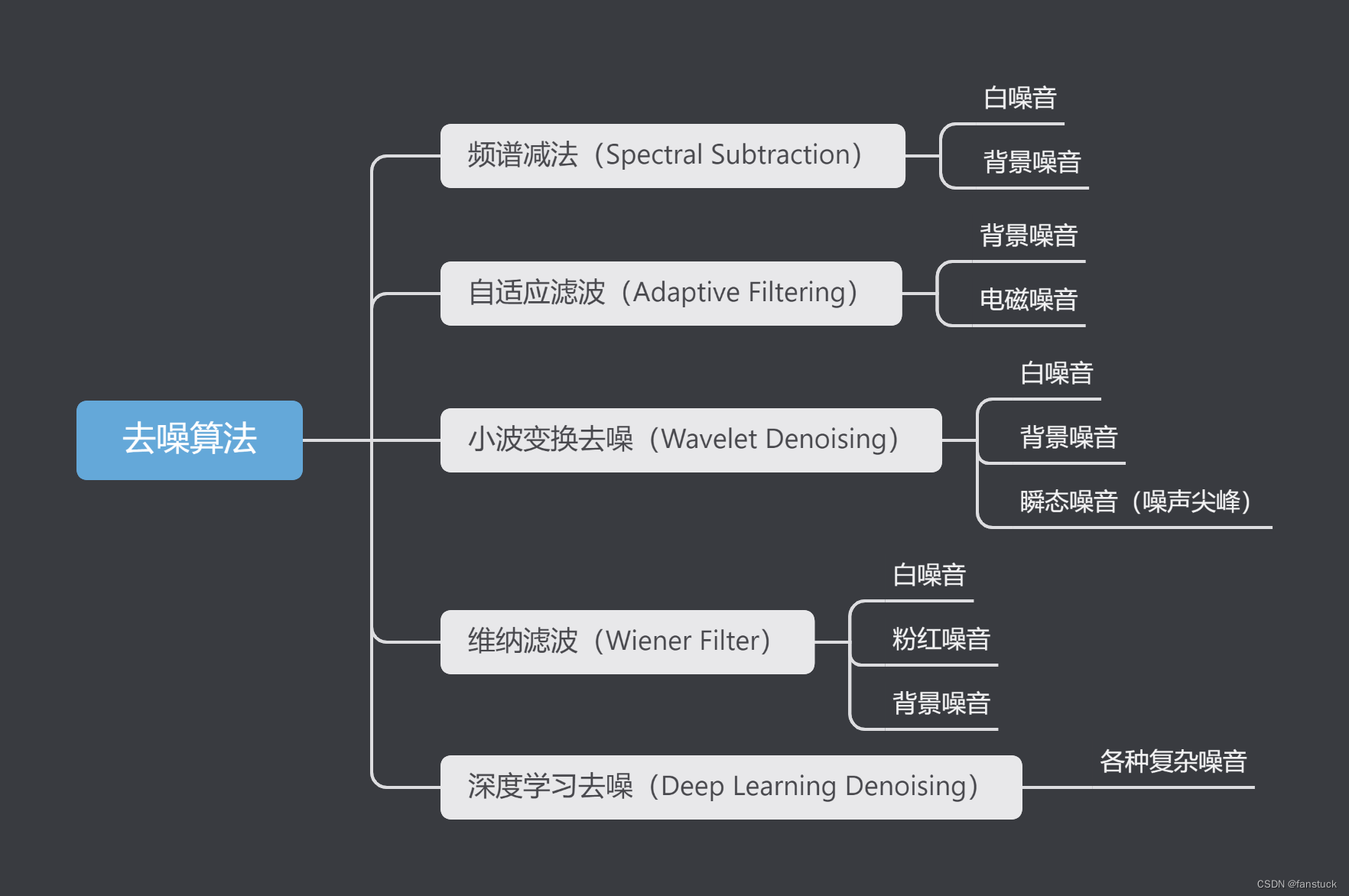
2.2.1.频谱减法(Spectral Subtraction)
频谱减法(Spectral Subtraction)是一种经典的音频去噪技术,用于从噪声污染的信号中减去估计的噪声频谱,以恢复原始的干净信号。该算法最初由 S. Boll 于1979年提出,是一种简单且有效的去噪方法,广泛应用于语音处理、音频增强等领域。
频谱减法利用了噪声信号在频谱上的统计特性,假设噪声是平稳的或缓慢变化的,因此其频谱特性在时间上保持相对稳定。通过估计噪声的频谱并将其从受噪声污染的音频信号中减去,可以在一定程度上恢复原始信号。
用途:
- 语音增强:提高语音信号的可懂度和清晰度,常用于电话通信、语音识别和助听器等领域。
- 音频修复:去除录音中的背景噪音,如风声、交通噪音等,改善音频质量。
- 预处理步骤:在许多音频处理任务中,频谱减法可以作为预处理步骤,以提高后续处理的效果。
频谱减法的核心思想是估计噪声频谱并将其从受污染信号的频谱中减去:
-
预处理:
- 短时傅里叶变换(STFT):将时域信号转换为频域信号,分解为若干帧,每帧进行傅里叶变换,得到每帧的频谱。
-
估计噪声频谱:
- 静音段估计:在信号的静音段或环境噪声段提取噪声频谱的平均值。假设噪声在这些段中是平稳的。
- 平滑估计:使用平滑方法估计噪声频谱,通常采用时间平均或指数加权平均。
-
频谱减法:
- 频谱减法计算:对每一帧信号,计算其幅值谱并减去估计的噪声幅值谱:
∣ S ( f ) ∣ = m a x ( ∣ Y ( f ) ∣ − ∣ N ( f ) ∣ , 0 ) |S(f)|=max(|Y(f)|-|N(f)|,0) ∣S(f)∣=max(∣Y(f)∣−∣N(f)∣,0)
其中,|Y(f)|是受噪声污染的信号的幅值谱,∣N(f)∣ 是估计的噪声幅值谱, ∣𝑆(𝑓)∣是去噪后的信号的幅值谱。
- 频谱减法计算:对每一帧信号,计算其幅值谱并减去估计的噪声幅值谱:
-
相位恢复:使用原始信号的相位谱 θ Y ( f ) θ_{Y}(f) θY(f)和去噪后的幅值谱 ∣𝑆(𝑓)∣ 重构频域信号:
- S ( f ) = ∣ S ( f ) ∣ e j θ Y ( f ) S(f)=|S(f)|e^{jθ_{Y}(f)} S(f)=∣S(f)∣ejθY(f)
-
逆变换:
- 逆短时傅里叶变换(ISTFT):将去噪后的频域信号通过逆短时傅里叶变换转换回时域信号,得到去噪后的时域信号。
那么首先我们对我们生成的纯音乐添加白噪音:
import soundfile as sf
import numpy as np
# 读取纯音乐文件
pure_music, sample_rate = sf.read('pure_music.wav')
def generate_white_noise(duration, sample_rate):
"""生成指定持续时间的白噪音"""
noise = np.random.normal(0, 1, int(sample_rate * duration))
return noise
# 获取纯音乐的持续时间
duration = len(pure_music) / sample_rate
# 生成与纯音乐长度相同的噪音
white_noise = generate_white_noise(duration, sample_rate)
# 将白噪音添加到纯音乐
white_noise_music = pure_music + 0.1 * white_noise # 0.1表示噪音的强度,可以调整
# 保存合成后的音频
sf.write('pure_music_with_white_noise.wav', white_noise_music, sample_rate)
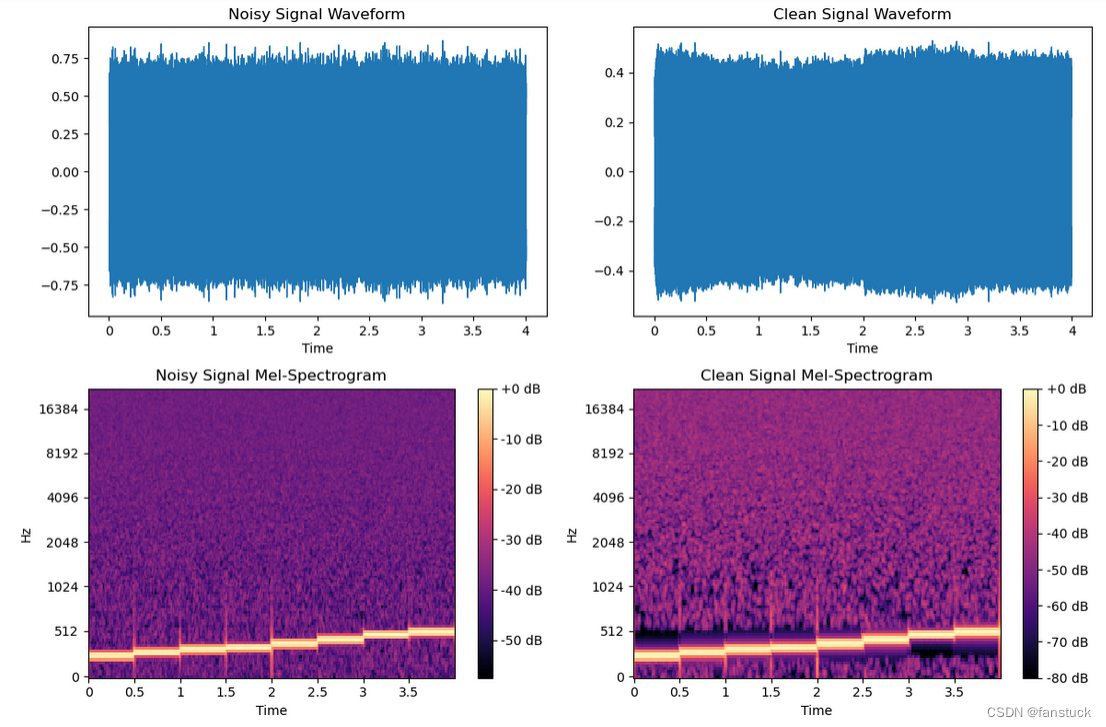
合成之后的音频听起来噪声是很明显的,此时我们可以通过特征可视化看到区别:
为加噪音之前:
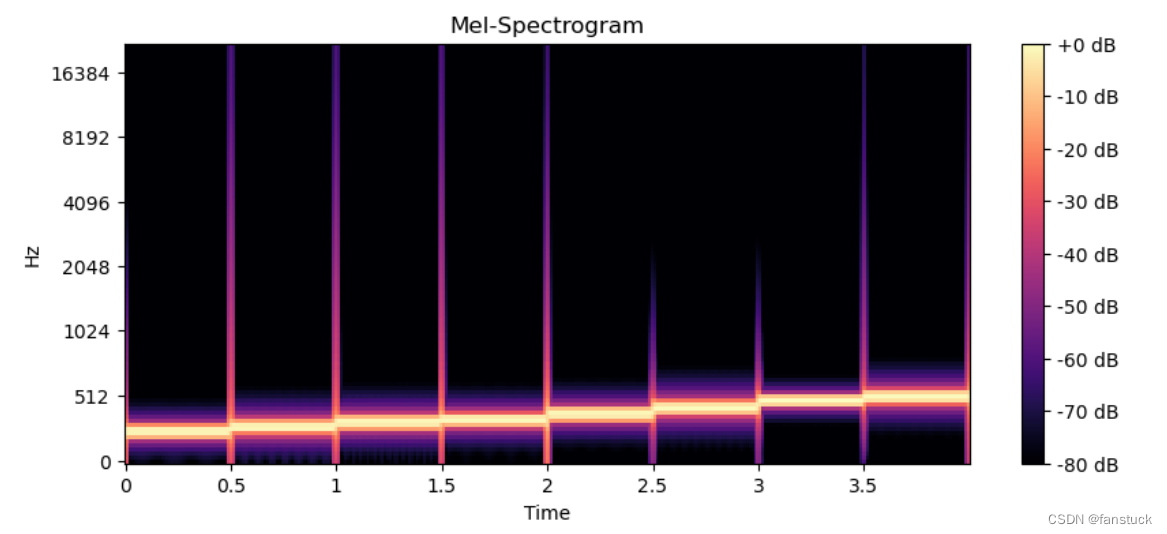 加入噪音之后:
加入噪音之后:
现在我们再用去噪算法进行去噪处理:
def spectral_subtraction(noisy_signal, noise_signal, sample_rate):
# 计算短时傅里叶变换(STFT)
noisy_stft = librosa.stft(noisy_signal)
noise_stft = librosa.stft(noise_signal)
# 计算噪声的平均频谱
noise_spectrum = np.mean(np.abs(noise_stft), axis=1, keepdims=True)
# 对每一帧信号进行频谱减法
magnitude = np.abs(noisy_stft)
phase = np.angle(noisy_stft)
clean_spectrum = np.maximum(magnitude - noise_spectrum, 0)
# 重构频域信号
clean_stft = clean_spectrum * np.exp(1j * phase)
# 逆STFT得到时域信号
clean_signal = librosa.istft(clean_stft)
return clean_signal
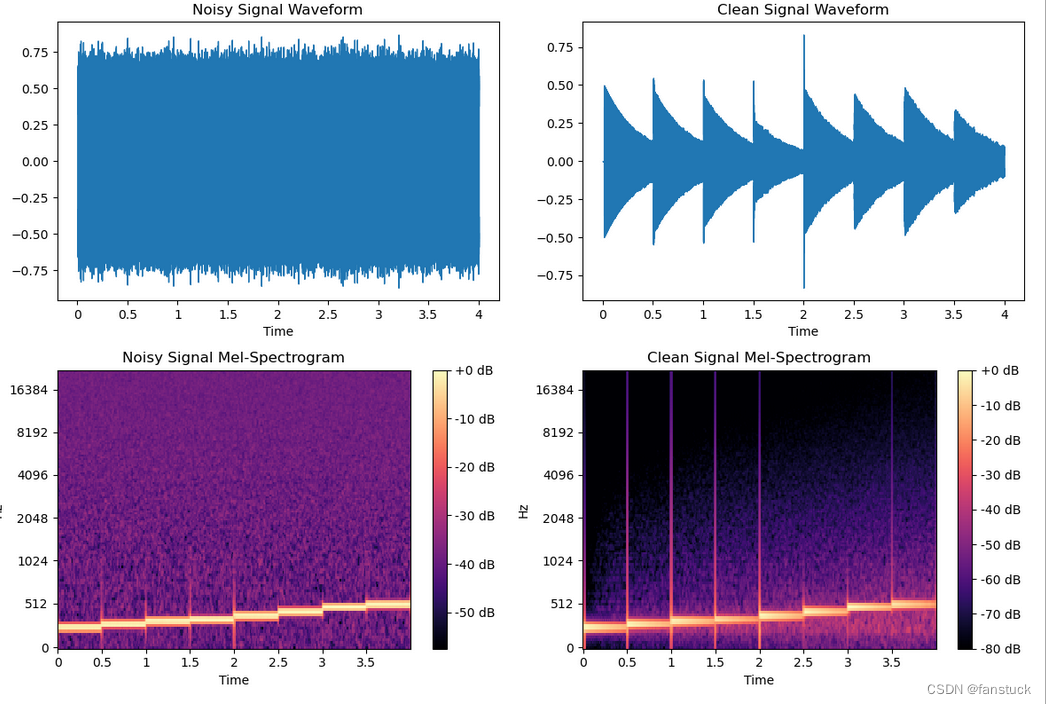
处理之后对比如下所示,大家可以听视频感觉,噪音还是有所降低的,但是不多:
 ### 2.2.2自适应滤波(Adaptive Filtering)
### 2.2.2自适应滤波(Adaptive Filtering)
自适应滤波是一种动态调整滤波器参数以最小化输出误差的信号处理技术。它广泛应用于各种需要实时调整和优化的系统中。自适应滤波器根据输入信号的统计特性不断更新其参数,因而能够在非平稳环境中有效工作。一般适用于背景噪声(Background Noise)、电磁干扰噪声(Electromagnetic Interference Noise)、语音噪声(Speech Noise)、回声(Echo)、噪声尖峰(Impulse Noise)这五种噪音。
具体算法逻辑
自适应滤波器通过最小均方(LMS)算法调整滤波器系数以最小化误差。常见的自适应滤波算法包括LMS和RLS(递归最小二乘)。
LMS算法
LMS算法是一种简单且有效的自适应滤波算法,其主要步骤如下:
-
初始化:
- 设定滤波器系数初始值为零或随机值。
- 设定步长因子 μ 以控制更新速度。
-
迭代更新:
- 对于每一个输入信号样本:
- 计算滤波器输出y(n): 𝑦(𝑛)=𝑤(𝑛)𝑇𝑥(𝑛),其中 w ( n ) w(n) w(n) 是滤波器系数向量,𝑥(𝑛)$ 是输入信号向量。
- 计算误差e(n):e(n)=d(n)-y(n),其中𝑑(𝑛) 是期望信号。
- 更新滤波器系数:w(n+1)=w(n)+2μe(n)x(n)$
- 对于每一个输入信号样本:
-
停止条件:
- 通常设定迭代次数或达到误差最小值时停止。
-
def lms_filter(noisy_signal, reference_signal, mu, num_taps):
n = len(noisy_signal)
w = np.zeros(num_taps)
y = np.zeros(n)
e = np.zeros(n)
for i in range(num_taps, n):
x = noisy_signal[i-num_taps:i]
y[i] = np.dot(w, x)
e[i] = reference_signal[i] - y[i]
w = w + 2 * mu * e[i] * x
return e # 返回误差信号作为去噪后的信号
在自适应滤波算法中去噪效果受到步长因子 (𝜇μ) 和滤波器长度 (num_taps)影响尤其重要,如果这些参数设置不当,可能会导致滤波效果不佳,甚至使噪声加重。可以通过:
- 调整步长因子:步长因子 (𝜇μ) 决定了滤波器系数的更新速度,过大或过小的步长因子都可能影响滤波效果。
- 增加滤波器长度:较长的滤波器可以捕捉更多的信号特征,但也增加了计算复杂度。
- 使用参考信号:在实际应用中,通常需要一个参考信号作为期望信号 (𝑑(𝑛)d(n))。如果没有理想信号,可以尝试使用噪声信号的估计值。
- 预处理和后处理:在滤波前后进行适当的预处理和后处理,例如平滑、归一化等。
这几种处理方法,我更推荐前面三种方法,简单高效。其中在自适应滤波应用中,参考信号的选择取决于具体的应用场景和目标。
# 读取音频文件
noisy_signal, sample_rate = librosa.load('pure_music_with_white_noise.wav', sr=None)
noise_signal, _ = librosa.load('pure_music_with_white_noise.wav', sr=None)
reference_signal, _ = librosa.load('pure_music.wav', sr=None) # 使用参考信号
# 自适应滤波参数
mu = 0.00001 # 步长因子
num_taps = 512 # 滤波器长度
期望信号是仿真中不考虑噪声影响的系统输出,在实际中我们是无法获得的,只能在仿真中得到。期望信号与具体的应用场合有关。比如在胎儿的心音检测中。输入信号x(n)=sm(n)+sb(n),其中sm为孕妇的心音信号,sb为胎儿的心音信号。此时自适应滤波器要输出的是胎儿的心音信号sb(n)。因此此时可以将x(n)看做是期望输出信号,sm为输入信号,这样,通过自适应滤波器之后就得到实际需要的sb(n)了。x(n)可以通过放置在胎儿位置的传感器得到,sm可以通过放置在远离胎儿的位置的传感器得到。
实际上,基于维纳滤波的问题都涉及到期望信号的理解。很多人往往会问,要是知道了期望输出信号,还需要滤波做什么呢?实际上不完全是这么回事的。如果从去相关的角度,就非常好理解期望信号的问题了。
期望信号是仿真中不考虑噪声影响的系统输出,在实际中我们是无法获得的,只能在仿真中得到。期望信号与具体的应用场合有关。比如在胎儿的心音检测中。输入信号x(n)=sm(n)+sb(n),其中sm为孕妇的心音信号,sb为胎儿的心音信号。此时自适应滤波器要输出的是胎儿的心音信号sb(n)。因此此时可以将x(n)看做是期望输出信号,sm为输入信号,这样,通过自适应滤波器之后就得到实际需要的sb(n)了。x(n)可以通过放置在胎儿位置的传感器得到,sm可以通过放置在远离胎儿的位置的传感器得到。
实际上,基于维纳滤波的问题都涉及到期望信号的理解。很多人往往会问,要是知道了期望输出信号,还需要滤波做什么呢?实际上不完全是这么回事的。如果从去相关的角度,就非常好理解期望信号的问题了。
提取纯噪声
从录音中提取纯噪声部分通常涉及识别和分离音频中的噪声段有:
手动方法
- 试听音频:手动试听音频文件,找到没有目标信号的噪声段。
- 音频剪辑工具:使用音频剪辑工具(如Audacity),手动剪切和提取噪声段。
自动方法
- 静音检测:通过检测音频中的静音段或低能量段,自动识别可能的噪声段。
- 语音活动检测(VAD):使用语音活动检测算法,识别和提取无语音活动的段落作为噪声参考信号。
我们也可以通过计算音频信号的短时能量,设定能量阈值从而提取低能量段的音频信号,也就是大概率为噪音信号,再将所有噪声段合并成一个信号。
# 计算音频信号的短时能量和零交叉率
frame_length = 2048
hop_length = 512
# 短时能量
energy = np.array([
np.sum(np.abs(noisy_signal[i:i+frame_length]**2))
for i in range(0, len(noisy_signal), hop_length)
])
# 零交叉率
zcr = np.array([
librosa.feature.zero_crossing_rate(noisy_signal[i:i+frame_length])[0, 0]
for i in range(0, len(noisy_signal), hop_length)
])
# 标准化能量
energy = energy / np.max(energy)
# 设定能量阈值和ZCR阈值
energy_threshold = 0.02
zcr_threshold = 0.1
# 找到低能量段和高ZCR段的索引
low_energy_indices = np.where(energy < energy_threshold)[0]
high_zcr_indices = np.where(zcr > zcr_threshold)[0]
# 提取低能量段和高ZCR段的音频信号
noise_segments = []
for idx in np.intersect1d(low_energy_indices, high_zcr_indices):
start = idx * hop_length
end = start + frame_length
noise_segments.append(noisy_signal[start:end])
# 检查是否找到任何低能量段和高ZCR段
if len(noise_segments) > 0:
# 将所有噪声段合并成一个信号
pure_noise = np.concatenate(noise_segments)
else:
# 如果没有找到低能量段和高ZCR段,可以使用白噪声作为默认参考信号
print("没有找到低能量段和高ZCR段,使用白噪声作为参考信号")
duration = len(noisy_signal) / sample_rate
pure_noise = np.random.normal(0, 1, int(sample_rate * duration))
# 保存提取的噪声段
sf.write('extracted_noise.wav', pure_noise, sample_rate)
然后再次去噪即可,不过自适应滤波并不适合去噪白噪音,固大家可以自行尝试其他噪音去噪效果。
本篇文章先写到此,内热太多也不好一下再继续写接下来三种算法。本系列将从最基础的音频数据认知开始一直讲解到最终完成整个语音深度鉴别模型的落地使用,对此项目感兴趣的,对此领域感兴趣的不要错过,多谢大家的支持!