一、【写在前面】
prometheus自定义指标本质是用代码自己写一个网络访问的采集器,你可以在官网看到,Client libraries | Prometheus官方支持的语言有GO JAVA PYTHON RUBY RUST, 第三方的库就支持的更多了,有BASH C CPP LUA C# JS PHP R PERL等,所以基本都可以找到自己需要的语言
因为考虑到prometheus官方提供的node exporter有限,社区的exporter需要找找找然后自己魔改,所以这篇文章写一个自定义指标的示例,小改一下就能自己用,但是当然您需要提前搭建一套prometheus才行,所以此文章作为以下的补充grafana + Prometheus + node-exporter + pushgateway + alertmanager的监控解决方案-CSDN博客
二、【基本介绍】
1. exporter是什么
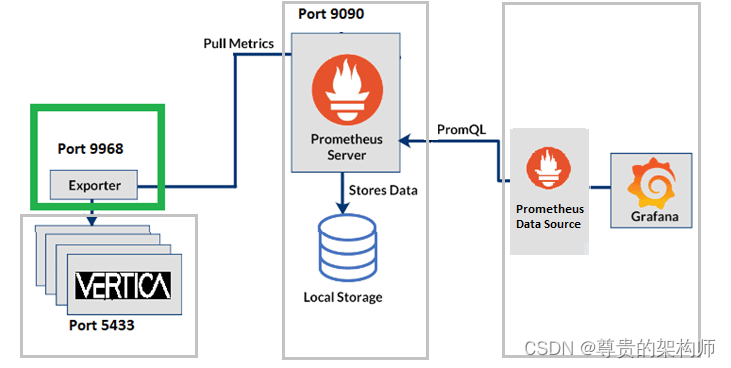
exporter就是我们传统意义上说的agent。笔者到网上找了张架构图,你可以看到exporter部署在目标机器或者目标机器外,采集所需的指标,然后再由Prometheus定期拉取,也就是说,你可以看到,这个过程可能存在两个定时过程,一个是exporter处指标的定时更新,另一个是prometheus的定时拉取。
2. 支持哪些类型的指标
这个库还是蛮清楚明了的,官网文档一页就能看完,它支持这么几种类型,根据需要选取就行,这是他的官网,Instrumenting | client_python, 下面是用GPT总结的几个常用类
1. Counter(计数器)
特点:
- 单调递增,只能增加或重置为零,不能减少。
使用场景:
- 统计事件发生的总次数,如请求数、错误数等。
from prometheus_client import Counter
c = Counter('requests_total', 'Total number of requests')
c.inc() # 增加1
c.inc(5) # 增加5
2. Gauge(仪表)
特点:
- 可以增加、减少或设置为任意值。
使用场景:
- 表示瞬时值,如当前温度、内存使用量、并发请求数等。
from prometheus_client import Gauge
g = Gauge('memory_usage_bytes', 'Memory usage in bytes')
g.set(12345) # 设置为12345
g.inc() # 增加1
g.dec(2) # 减少2
3. Summary(摘要)
特点:
- 统计事件的持续时间或大小,提供总量、次数以及可配置的分位数信息。
使用场景:
- 记录请求的响应时间、数据包的大小等。
from prometheus_client import Summary
s = Summary('request_latency_seconds', 'Request latency in seconds')
s.observe(0.5) # 记录一个0.5秒的请求延迟
4. Histogram(直方图)
特点:
- 类似于Summary,但提供详细的桶分布信息,统计每个桶内的值的个数。
使用场景:
- 记录请求的响应时间,并分析其分布情况;记录数据包的大小分布。
from prometheus_client import Histogram
h = Histogram('request_latency_seconds', 'Request latency in seconds')
h.observe(0.5) # 记录一个0.5秒的请求延迟
5. Info
特点:
- 记录一些静态的信息,如版本号、配置信息等。
使用场景:
- 记录应用的版本号、配置参数等。
from prometheus_client import Info
i = Info('app_version', 'Application version')
i.info({'version': '1.0.0', 'build': 'abc123'})
6. Enum
特点:
- 表示一组离散的互斥状态。
使用场景:
- 记录应用的运行状态(如启动、运行、停止);记录服务器的健康状态。
from prometheus_client import Enum
e = Enum('app_state', 'Application state', states=['starting', 'running', 'stopping', 'stopped'])
e.state('running')
7. Labels(标签)
特点:
- 为指标附加维度,可以在同一指标名称下记录多个不同维度的数据。
使用场景:
- 记录每个API端点的请求次数;记录不同状态的任务数。
from prometheus_client import Counter
c = Counter('http_requests_total', 'Total number of HTTP requests', ['method', 'endpoint'])
c.labels(method='get', endpoint='/home').inc()
c.labels(method='post', endpoint='/submit').inc()
这里我说一句,这个标签特别适合做多维表,prometheus这个东西它自定义生成的大都是键值对,如果要做多维,用这个会方便一些,但是只限于在label里(也就是[]中)写常量,因为他本质还是在键里写信息,如果键里内容变了,prometheus会认为是新的条目
8. Exemplars(示例)
特点:
- 关联指标数据和具体的事件样本,帮助在分析时追踪和关联具体的事件。
使用场景:
- 关联慢请求的具体trace;提供异常事件的上下文信息。
from prometheus_client import Histogram
h = Histogram('request_latency_seconds', 'Request latency in seconds')
h.observe(0.5, {'trace_id': '12345'}) # 记录一个0.5秒的请求延迟,并附加trace ID
# 本质上不是一个新类三、【代码实现】
1. 安装prometheus client 库
pip install prometheus_client2. 复制代码
让GPT写了一个用线程精准定时的采集指标,你可以看到,本质就是创建一个 指标类型(这里是Counter和Gauge) 然后把数字用set塞进去就行。
from prometheus_client import start_http_server, Counter, Gauge
import threading
import random
import time
# 创建计数器
REQUEST_COUNTER = Counter('periodic_tasks_total', 'Total number of periodic tasks executed')
# 创建仪表
PERIODIC_GAUGE = Gauge('periodic_task_value', 'Value generated by periodic task')
def generate_metrics():
"""生成指标的函数,每30秒执行一次"""
REQUEST_COUNTER.inc() # 增加计数器
value = random.uniform(0, 100)
PERIODIC_GAUGE.set(value) # 设置仪表值
print(f"Generated metrics: {value}")
def schedule_periodic_metrics(interval):
"""调度定时任务的函数,确保每interval秒执行一次"""
generate_metrics()
# 使用threading.Timer确保精确的定时
threading.Timer(interval, schedule_periodic_metrics, [interval]).start()
if __name__ == '__main__':
# 启动一个Prometheus HTTP服务器,用于抓取指标数据
start_http_server(8000)
# 启动精确定时任务,每30秒生成一次指标
schedule_periodic_metrics(30)
# 保持主线程运行
while True:
time.sleep(1)
3. 确认连通情况
把上面的脚本跑起,然后另一边在Prometheus里的yml写上连接的ip和端口,并且重启prometheus,随后网页 “1.1.1.1:8000/targets” 查看情况
- job_name: 'trading_observer'
static_configs:
- targets: ['1.1.1.1:8000']
看到这个up就是连接上了

之后就可以在grafana中通过指标名获取数据了