MySQL使用索引的最佳指南
- 1.选择合适的字段创建索引
- 2.尽可能的考虑建立联合索引而不是单列索引
- 3.注意避免冗余索引
- 4.考虑在字符串类型的字段上使用前缀索引代替普通索引
- 5.索引失效的情况
1.选择合适的字段创建索引
- 不为 NULL 的字段 :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
- 被频繁查询的字段 :我们创建索引的字段应该是查询操作非常频繁的字段。
- 被作为条件查询的字段 :被作为 WHERE 条件查询的字段,应该被考虑建立索引。
- 频繁需要排序的字段 :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- 被经常频繁用于连接的字段 :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
- 数据表的主键,最好选用带顺序性的值,而不是使用
UUID - 如果实在需要使用非主键字段查询,那么尽量要写明查询的结果字段,而并非使用
*
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了😨
2.尽可能的考虑建立联合索引而不是单列索引
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
联合索引存在的矛盾:
联合索引存在一个致命的问题,比如在用户表中,通过id、name、age三个字段建立一个联合索引,此时来了一条查询SQL,如下:
SELECT * FROM `users` WHERE name = "meimei" AND age = "18";
而这条SQL语句是无法使用联合索引的,为什么呢?因为查询条件中,未包含联合索引的第一个字段,想要使用联合索引,那么查询条件中必须包含索引的第一个字段,如下:
SELECT * FROM `users` WHERE name = "meimei" AND id = 6;
因此在建立索引时也需要考虑这个问题,确保建立出的联合索引能够命中率够高。
建立联合索引时,一定要考虑优先级,查询频率最高的字段应当放首位🤯
同时,MySQL的最左前缀原则,才匹配到范围查询时会停止匹配,比如>、<、between、like这类范围条件,并不会继续使用联合索引,举个栗子:
SELECT * FROM tb WHERE X="..." AND Y > "..." AND Z="...";
当执行时,虽然上述SQL使用到X、Y、Z作为查询条件,但由于Y字段是>范围查询,因此这里只能使用X索引,而不能使用X、Y或X、Y、Z索引。
3.注意避免冗余索引
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
4.考虑在字符串类型的字段上使用前缀索引代替普通索引
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
前缀索引虽然带来了节省空间的好处,但也正由于其索引节点中,未存储一个字段的完整值,所以MySQL也无法通过前缀索引来完成
ORDER BY、GROUP BY等分组排序工作,同时也无法完成覆盖扫描等操作😩
5.索引失效的情况
但想要查看一条SQL是否使用了索引,需要用到一个自带的分析工具ExPlain
例如:
EXPLAIN SELECT * FROM `zz_users`;
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | zz_users | ALL | NULL | NULL | NULL | NULL | 3 | |
+----+-------------+----------+------+---------------+------+---------+------+------+-------+
id:这是执行计划的ID值,这个值越大,表示执行的优先级越高。select_type:当前查询语句的类型,有如下几个值:
simple:简单查询。
primary:复杂查询的外层查询。
subquery:包含在查询语句中的子查询。
derived:包含在FROM中的子查询。table:表示当前这个执行计划是基于那张表执行的。type:当前执行计划查询的类型,有几种情况:
all:表示走了全表查询,未命中索引或索引失效。
system:表示要查询的表中仅有一条数据。
const:表示当前SQL语句的查询条件中,可以命中索引查询。
range:表示当前查询操作是查某个区间。
eq_ref:表示目前在做多表关联查询。
ref:表示目前使用了普通索引查询。
index:表示目前SQL使用了辅助索引查询。possible_keys:执行SQL时,优化器可能会选择的索引(最后执行不一定用)。key:查询语句执行时,用到的索引名字。key_len:这里表示索引字段使用的字节数。ref:这里显示使用了那种查询的类型。rows:当前查询语句可能会扫描多少行数据才能检索出结果。Extra:这里是记录着额外的一些索引使用信息,有几种状态:
using index:表示目前使用了覆盖索引查询。
using where:表示使用了where子句查询,通常表示没使用索引。
using index condition:表示查询条件使用到了联合索引的前面几个字段。
using temporary:表示使用了临时表处理查询结果。
using filesort:表示以索引字段之外的方式进行排序,效率较低。
select tables optimized away:表示在索引字段上使用了聚合函数。
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
- 使用
SELECT *进行查询; - 在索引列上进行计算(
+、-、*、/、!.....)、函数、类型转换等操作; - 以
%开头的LIKE查询比如like '%abc';; - 查询条件中使用
or,且or的前后条件中有一个列没有索引,涉及的索引都不会被使用到; - 发生隐式转换;
- 使用联合索引时,查询条件未包含联合索引的第一个字段(未准守最左匹配原则);
- 字符类型查询时不带引号导致索引失效;
- 不同字段值对比导致索引失效;
从一张表中查询出一些值,然后根据这些值去其他表中筛选数据,这个业务也是实际项目中较为常见的场景,下面为了简单实现,就简单用姓名和性别模拟一下字段对比的场景:(其中user_name属于联合索引的第一个字段)
EXPLAIN SELECT * FROM `zz_users` WHERE user_name = user_sex;

- 反向范围操作导致索引失效
一般来说,如果SQL属于正向范围查询,例如>、<、between、like、in...等操作时,索引是可以正常生效的,但如果SQL执行的是反向范围操作,例如NOT IN、NOT LIKE、IS NOT NULL、!=、<>...等操作时,就会出现问题,例如:
EXPLAIN SELECT * FROM `zz_users` WHERE user_id NOT IN(1,2,3);
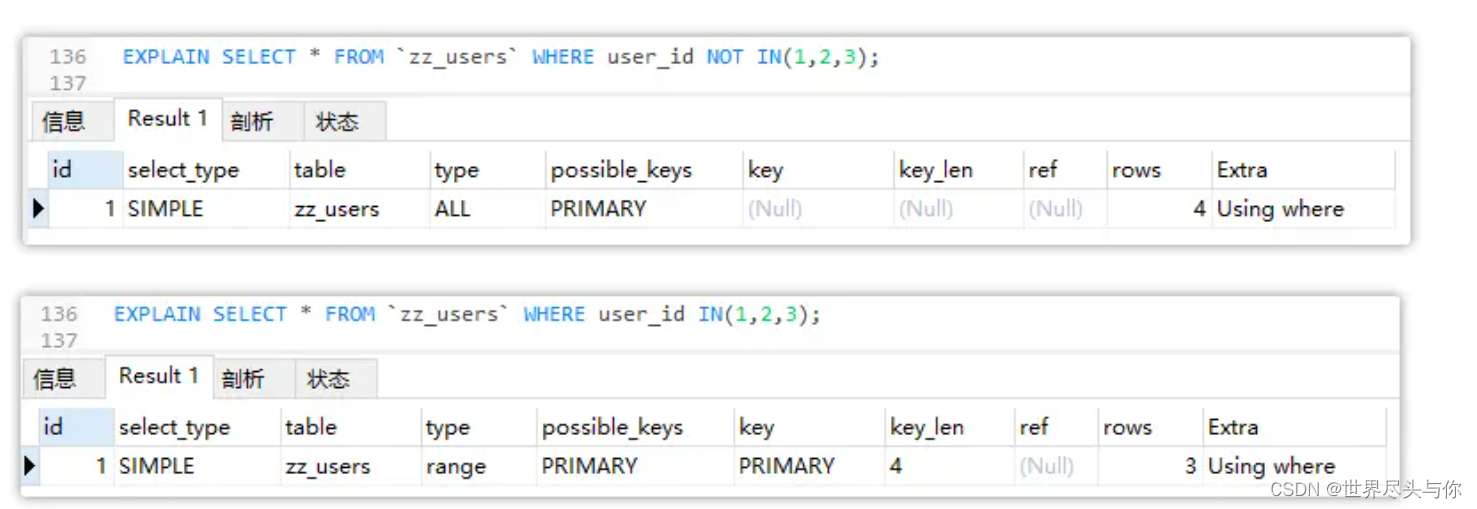
使用NOT关键字做反向范围查询时,并不会走索引,索引此时失效了,但是做正向范围查询时,索引依旧有效
- 走索引扫描的行数超过表行数的
30%
在MySQL中还有一种特殊情况会导致索引失效,也就是当走索引扫描的行数超过表行数的30%时,MySQL会默认放弃索引查询,转而使用全表扫描的方式检索数据,因此这种情况下走索引的顺序磁盘IO,反而不一定有全表的随机磁盘IO快。