【验证码识别】Yolov8入门到实战点选验证码数据集分类训练,孪生训练,导出onnx,搭建部署接口
文章目录
- 【验证码识别】Yolov8入门到实战点选验证码数据集分类训练,孪生训练,导出onnx,搭建部署接口
- 声明
- 一、标注验证码数据集
- labelme标注验证码数据集
- 1直接下载安装包
- 2通过pip安装labelme
- half_model_label标注验证码数据集
- 二 、使用yolov8开始训练
- yolov8安装使用
- 目标检测:
- 导出onnx使用
- 分类训练
- 三、孪生训练
- 问题拆解
- yolov5训练过程:
- Siamese训练过程:
- onnx介绍:
- 四、搭建部署自己的接口
声明
本文章中所有内容仅供研究、学习交流使用,不能用作其他任何目的,严禁用于商业用途和非法用途,否则一切后果自负,与作者无关。如有侵权请联系作者删除文章
一、标注验证码数据集
labelme标注验证码数据集
1直接下载安装包
github开源地址: Releases · labelmeai/labelme (github.com)
2通过pip安装labelme
如果你使用这种方式推荐conda进行安装虚拟环境,对于深度学习来说会方便很多
conda create -n yolov8 python=3.8
conda activate yolov8
pip install labelme
最后输入 labelme就能弹出打标界面了。
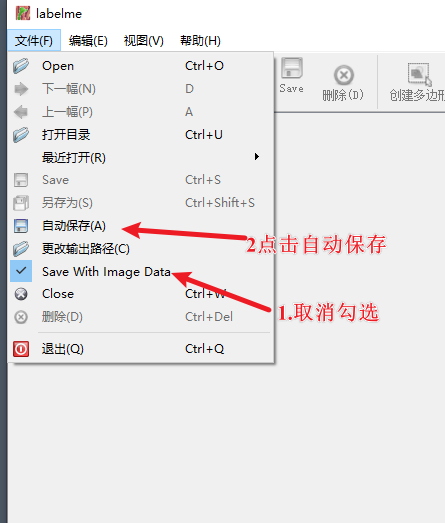
最重要的设置,每次打标都需要打开:
开启自动保存标注结果(不会每次弹窗),取消勾选Save With Image Data不把图像的编码内容保存到标注标签中。
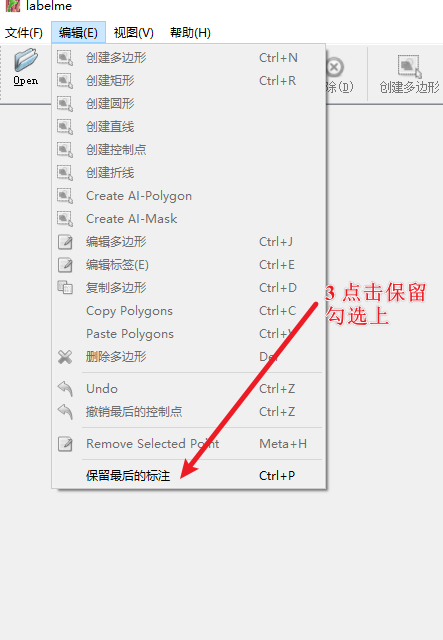
关键:保留最后的标注可以继承上一张图的打标的框,不用每次标记图都要重新画框了,还可以保证每个标注图像大小都一样,对于后面的孪生标注很有用。
最后将json格式的标注文件转为我们训练需要的特定格式内容:
{目标类别id} {归一化后的目标中心点x坐标} {归一化后的目标中心点y坐标} {归一化后的目标框宽度w} {归一化后的目标框高度h}。与其他数据不同的是,yolo标签只有类别id,并无具体类别名称,此外,其以相对尺寸描述标注框的xywh信息,不受图像尺寸改变的影响
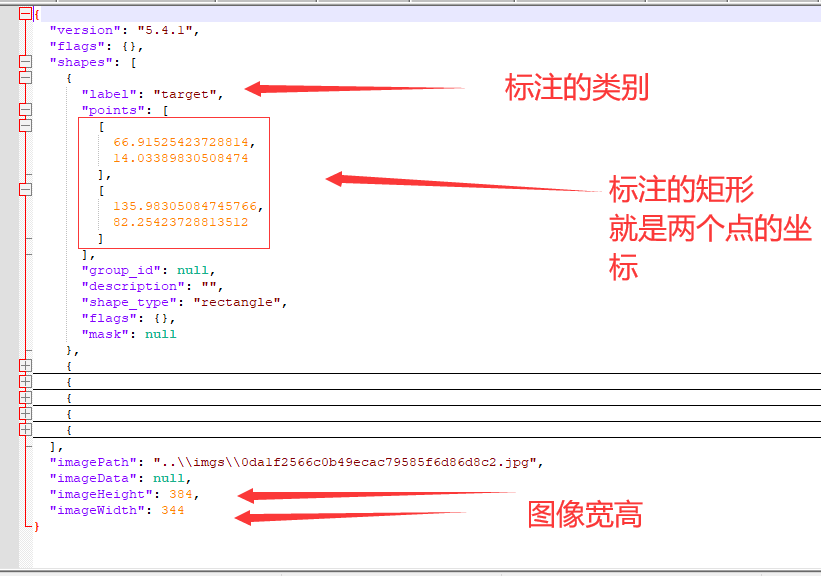
标注文件中的每一行表示一个边界框(bounding box),假设图像的宽度 W=1000,高度 H=800,有一个边界框:
- 类别ID 7:
- 左上角坐标:(500,400)
- 右下角坐标:(712, 561)
我们计算第一个边界框的归一化值:
x
c
e
n
t
e
r
=
500
+
712
2
⋅
1000
=
1212
2000
=
0.606
x_{center} = \frac{500 + 712}{2 \cdot 1000} = \frac{1212}{2000} = 0.606
xcenter=2⋅1000500+712=20001212=0.606
y c e n t e r = 400 + 561 2 ⋅ 800 = 961 1600 = 0.600625 y_{center} = \frac{400 + 561}{2 \cdot 800} = \frac{961}{1600} = 0.600625 ycenter=2⋅800400+561=1600961=0.600625
w i d t h = 712 − 500 1000 = 212 1000 = 0.212 width = \frac{712 - 500}{1000} = \frac{212}{1000} = 0.212 width=1000712−500=1000212=0.212
h
e
i
g
h
t
=
561
−
400
800
=
161
800
=
0.20125
height = \frac{561 - 400}{800} = \frac{161}{800} = 0.20125
height=800561−400=800161=0.20125
最终的到以下结果
<类别ID> <x_center> <y_center> <width> <height>
6 0.606 0.600625 0.212 0.20125
half_model_label标注验证码数据集
这个是有懒佬他们开发的,我觉得挺好用的,功能很多,大家自己去探索下。half_model_label: 半自动模型识别标注
二 、使用yolov8开始训练
yolov8安装使用
在前面的虚拟环境中安装
pip install ultralytics
conda list ultralytics#查看安装情况
官网地址: https://github.com/ultralytics/ultralytics
如果使用gpu训练,安装CUDA、CUDNN、Python、Pytorch、Torchvision 的版本都要要相互对应 Previous PyTorch Versions | PyTorch
目标检测:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from YAML
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, cache=True, imgsz=320, batch=16, workers=0, device=device, resume=resume)
训练完模型使用best.pt 进行预测:

from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
预测的结果相关参数可以去看官方文档:Predict - Ultralytics YOLO Docs
效果还是不错:

导出onnx使用
最后可以导出onnx,注意imgsz=320必须和训练是参数一致。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
分类训练
分类训练主要是准备数据集,如下图:

这个是由9个格子组成的魔方,我们可以这样思考分类
如果不考虑形状,总共有 2的9次方=512 种可能的矩阵这个分类太多了。
转换为数学的方法,我们有对于一个 3x3 的矩阵,有以下几种种对称变换:
- 顺时针旋转 90 度
- 水平翻转
- 垂直翻转
- 对角线 (左上到右下) 翻转
- 对角线 (右上到左下) 翻转
(1 1 1)
(1 0 1)
(0 0 0)
1表示黑色 0表示白色 白色不可见,我们可以算出有102种类别
先分大的类别,我们这里将有几个空格为大类别,0-9进行分类然后再细分
这里提供写的脚本:搭建的一个flask进行分类
# -*- coding: utf-8 -*-
from flask import Flask, jsonify, request, send_from_directory, render_template
import os
app = Flask(__name__)
IMAGE_FOLDER = 'data'
CLASSIFY_FOLDER = 'classify'
# 获取图片列表
@app.route('/api/images', methods=['GET'])
def get_images():
images = [f for f in os.listdir(IMAGE_FOLDER) if f.endswith('.png')]
return jsonify(images)
# 处理分类请求
@app.route('/api/classify', methods=['POST'])
def classify_image():
data = request.json
image_name = data['image']
classification = data['classification']
classify_folder = os.path.join(os.getcwd(), CLASSIFY_FOLDER)
target_folder = os.path.join(classify_folder, classification)
if not os.path.exists(target_folder):
os.makedirs(target_folder)
source_path = os.path.join(IMAGE_FOLDER, image_name)
target_path = os.path.join(target_folder, image_name)
os.rename(source_path, target_path)
return jsonify({'message': 'success'})
# 提供图片文件
@app.route('/images/<filename>')
def send_image(filename):
#当前文件夹
img_path = os.path.join(os.getcwd(), IMAGE_FOLDER)
return send_from_directory(img_path, filename)
@app.route('/')
def index():
return render_template('demo.html')
if __name__ == '__main__':
app.run(debug=True)
效果如下:输入类别即可

最后在进行细分,我也不知道咋起的名字了,反正这几天打标签人都傻了,红红火火恍恍惚惚哈哈哈哈哈哈哈。
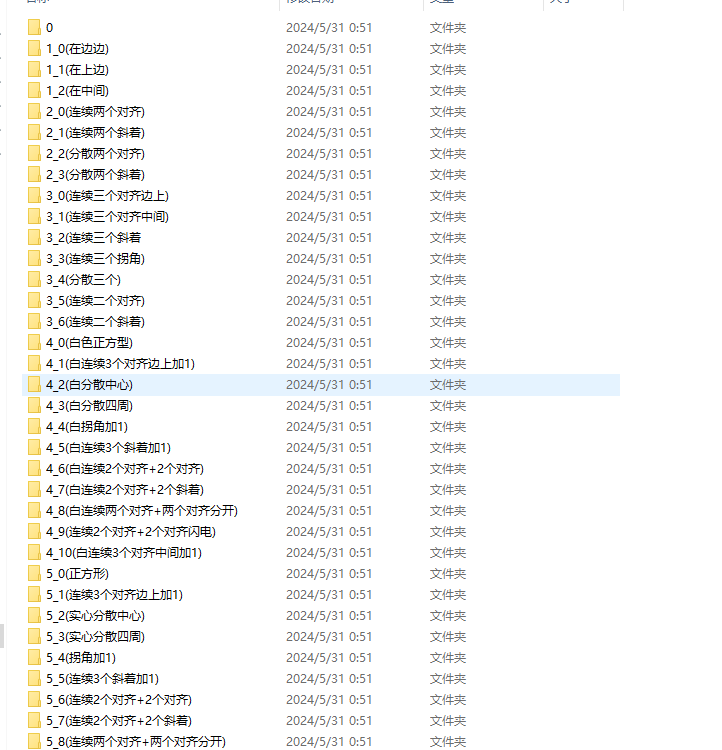
完成细分后进行训练集,测试集,验证集进行划分:
import os
import shutil
from pathlib import Path
from random import shuffle
# 定义路径
base_dir = Path(r"D:\data\魔方细分\classify")
train_dir = base_dir / "train"
test_dir = base_dir / "test"
val_dir = base_dir / "val"
for directory in [train_dir, test_dir, val_dir]:
directory.mkdir(exist_ok=True)
# 遍历前所以文件夹
folders = [f for f in base_dir.iterdir() if f.is_dir()][:-1]
for class_dir in folders:
images = list(class_dir.glob('*'))
shuffle(images)
total_images = len(images)
train_count = int(total_images * 0.85)
test_count = int(total_images * 0.14)
val_count = total_images - train_count - test_count # 剩余的分配给验证集
train_images = images[:train_count]
test_images = images[train_count:train_count + test_count]
val_images = images[train_count + test_count:]
(train_dir / class_dir.name).mkdir(exist_ok=True)
(test_dir / class_dir.name).mkdir(exist_ok=True)
(val_dir / class_dir.name).mkdir(exist_ok=True)
for img in train_images:
shutil.move(str(img), str(train_dir / class_dir.name / img.name))
for img in test_images:
shutil.move(str(img), str(test_dir / class_dir.name / img.name))
for img in val_images:
shutil.move(str(img), str(val_dir / class_dir.name / img.name))
shutil.rmtree(class_dir)
print("数据集划分完成!")
最后开始分类训练:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-cls.yaml") # build a new model from YAML
model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n-cls.yaml").load("yolov8n-cls.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="mnist160", epochs=100, imgsz=64)
分类训练没有标签,直接根据文件夹来的,所有是没有yaml文件和标签文件的。他会自动识别你的所有种类进行训练。
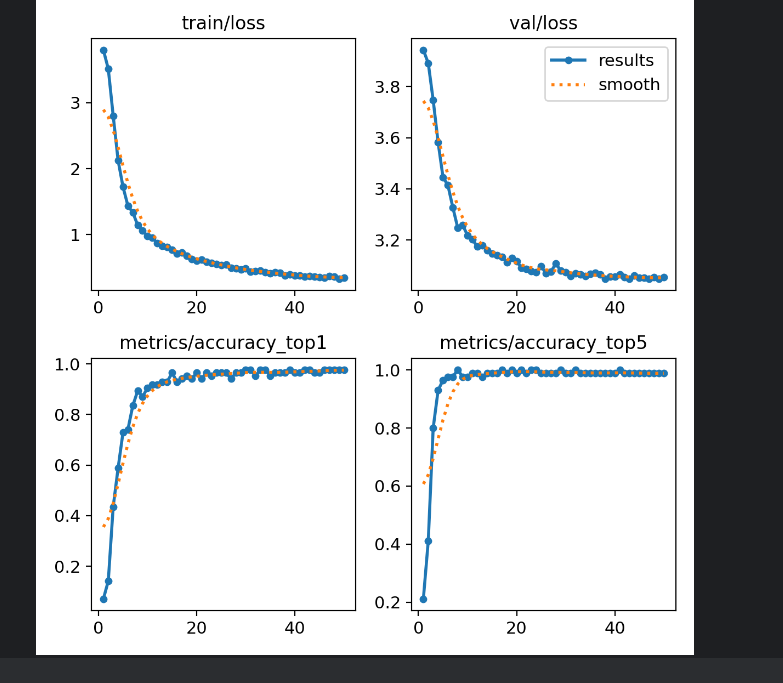
训练结果还不错:

三、孪生训练
看了下时间快下班了,大家可以参考一下这个
https://github.com/bubbliiiing/Siamese-pytorch
https://github.com/MgArcher/Text_select_captcha
下面是复制的:
问题拆解
对于点选式验证码的问题,我们可以将其拆解为两个小问题:
1、确定需要点击的字的数量和位置: 对于点选式验证码,准确识别和定位需要点击的字的数量和位置是解决问题的关键。 其中,一种常见的目标检测算法是 YOLO,通过标注数据集和训练模型,可以实现对需要点击的字进行准确识别和定位。本项目采用的是 yolov5 模型,该模型在目标检测方面表现出色,具有高速和较高的准确性。
2、对点击的字进行排序: 在确定出需要点击的字的位置后,需要按照一定的规则对这些字进行排序。采用传统的方案是通过识别图片中的文字,然后按照文字位置进行排序,但这种方法训练困难。因此,本项目采用了图片匹配模型,使用 Siamese 孪生网络对需要点击的字与预先准备好的字库中的字进行匹配,找到最佳匹配的字,并按照一定的规则进行排序。Siamese 孪生网络在图像匹配方面表现优异,能够有效地提高排序的准确性和稳定性。
-
部分训练集
百度网盘链接:https://pan.baidu.com/s/1IYfxVpanXyqVQ8ZFVOskrg 提取码:sp97
-
训练模型
训练代码在下方参考文档中
yolov5训练过程:
训练流程一般包括如下几个步骤:获取训练数据集、数据预处理、模型选择、设置损失函数、反向传播和更新权值等。
对于 YOLO 模型的训练流程,可以参考下方参考文档中的文档。基本流程是,首先下载训练数据集,数据集应该包含带有标注的图像和对应的标注数据。然后使用标注工具对图像进行标注,标注工具可以在 GitHub 上找到。标注的数据应该包括目标的类别和位置信息。
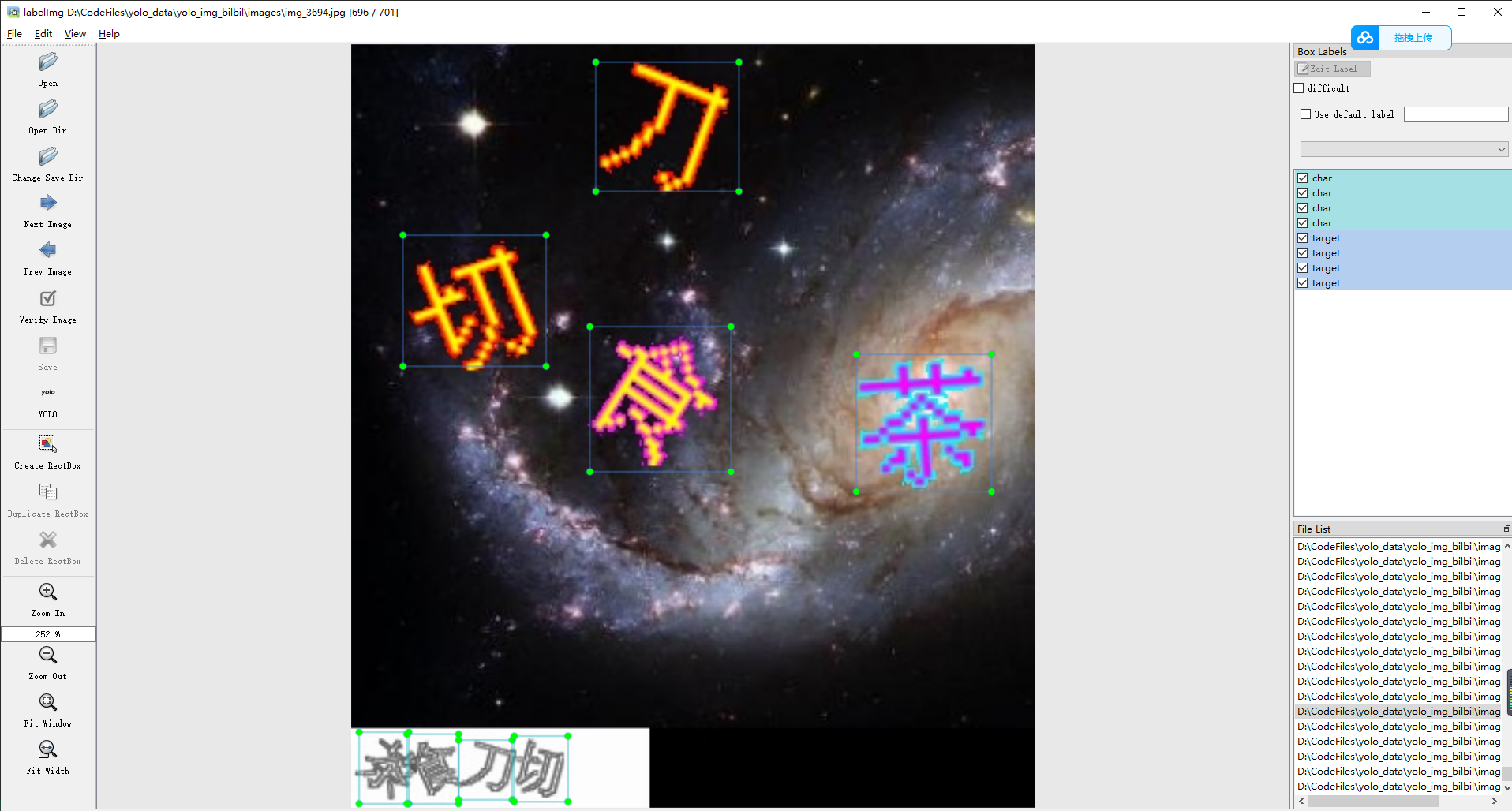
yolo标注结果
如图所示,可以对背景图中的文字进行 char 类别的标注,对需要检测的文字进行 target 类别的标注。在训练时,模型会学习如何从图像中定位和识别目标文本。
接下来是选择合适的模型。YOLO 系列模型有多个版本,可以根据不同的需求选择适合的版本。选择好模型后,需要设置损失函数和训练参数,进行模型训练。在训练过程中,需要采用反向传播算法计算损失函数的梯度,并更新权值,以提高模型的预测准确度。本项目使用的预训练模型是yolov5s6。
训练结束后,可以将模型保存成 ONNX 格式,以便在推理时进行加载和使用。
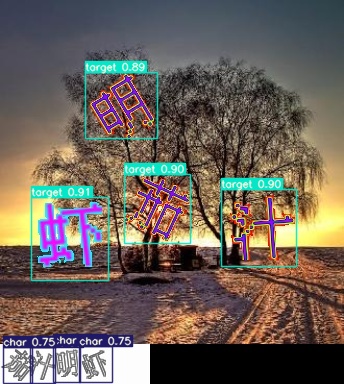
yolo检测结果
Siamese训练过程:
在使用孪生网络进行图像检索任务的训练前,需要对数据集进行准备。与其他模型不同,孪生网络的训练需要用到正负样本对,因此需要对数据集中的每张图像都生成一些与之匹配和不匹配的样本对。
具体实现时,一般采用已经训练好的检测模型来生成样本对。
具体操作流程如下:首先,使用检测模型对数据集中的图像进行检测,截取出每个目标的图像片段;然后,把该图像片段分别与数据集中的其他目标进行匹配和不匹配的组合,形成匹配和不匹配的样本对;最后,根据样本对的匹配情况对其进行标注,将匹配和不匹配的样本对分别放到不同的文件夹中,按照类别和顺序标注好,方便后续使用。
如下图所示,每张图像都会对应一个匹配和不匹配的样本对,每个样本对包含两张图像,分别作为孪生网络的输入。
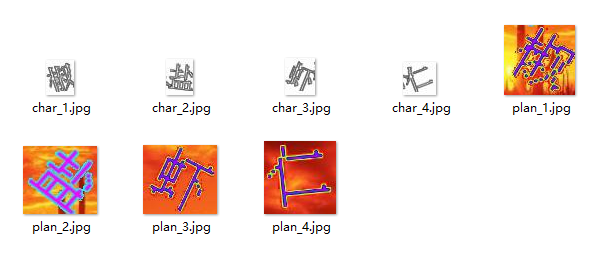
孪生网络标注结果
训练数据准备好后,具体训练过程可参考下方参考文档中的文档。
同样的,训练结束后,可以将模型保存成 ONNX 格式,以便在推理时进行加载和使用。
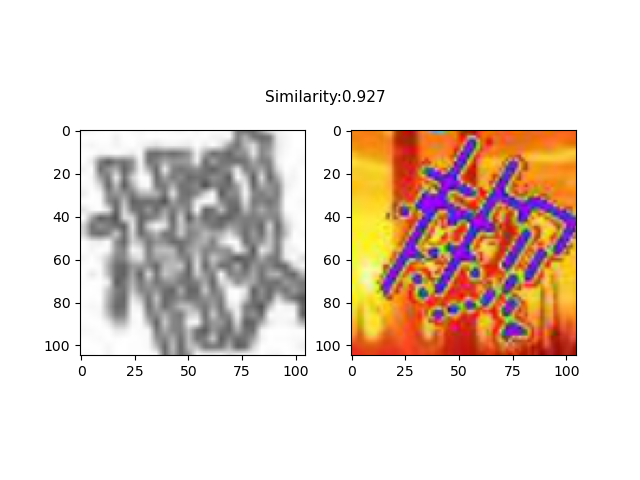
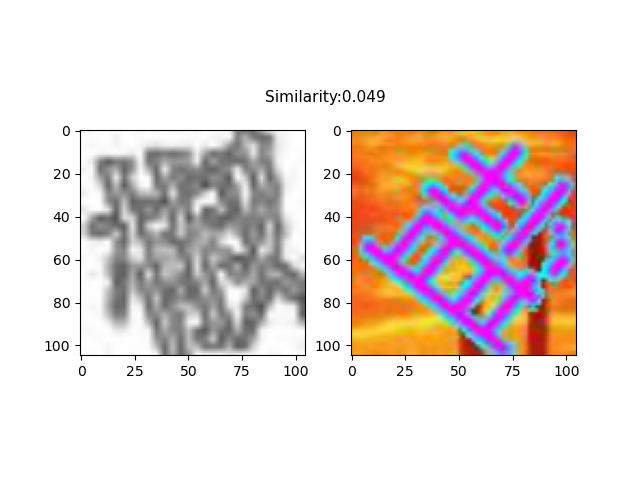
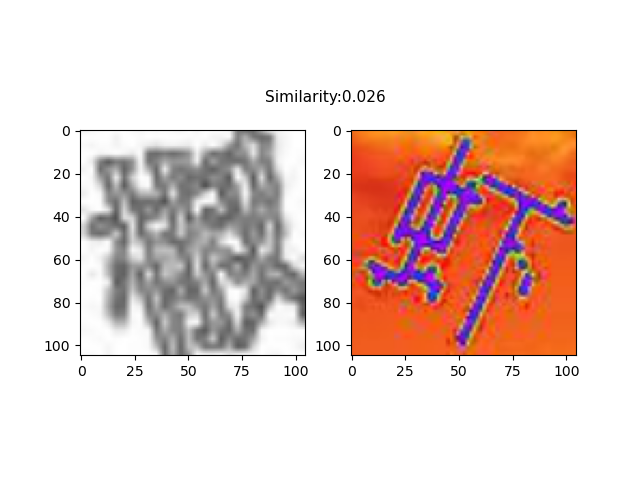

孪生网络标注结果
如图所示,孪生网络输出的结果可以给出背景图中的目标与右下角的目标最相似的结果,而左下角的目标则可以通过按照左坐标进行排序来得到。由此,可以方便地得到背景图中所有目标的顺序。
- 推理部署
推理部署过程是将 YOLO 和 Siamese 模型都转换为 ONNX 模型,以便在 CPU 上使用模型,并提高部署难度和运行速度。通过模型转换,可以将模型从原有的深度学习框架中的特定格式转换成 ONNX 格式,使得模型可以在多个平台上使用,并且可以在不同的编程语言之间轻松交互。
onnx介绍:
ONNX,即开放神经网络交换格式(Open Neural Network Exchange),是一个可以让不同深度学习框架之间互相转换和
使用模型的开放标准。它由 Facebook 和 Microsoft 共同开发,旨在为深度学习模型的部署和迁移提供更加方便和灵活的解决方案。
ONNX 支持包括 PyTorch、TensorFlow、CNTK 和 MXNet 等在内的多个深度学习框架,可以将这些框架训练出的模型转换成
ONNX 格式,从而可以被其他框架或应用所使用。
ONNX 的主要优点包括:
互操作性好:ONNX 支持多个深度学习框架之间的模型转换,使得它们可以互相使用和部署,从而减少了开发和部署的难度和成本;
高效性能:ONNX 可以在多种硬件和软件平台上运行,并提供了 C++和 Python 接口,可以大幅提高模型执行的效率和速度;
易于扩展:ONNX 的架构简单清晰,可以轻松地添加新的层次和类型,方便应对不断升级变化的深度学习技术和需求。
总之,ONNX 是一个方便快捷的深度学习模型转换和交换标准,可以帮助开发者更加轻松地将深度学习模型进行部署和迁移。
在将模型转换为 ONNX 格式后,对代码进行编译也是必不可少的一步。通过编译,可以将 Python 代码转换成机器语言代码,进一步提高模型的运行效率和速度。同时,也可以减少代码的存储空间,使得模型能够更快地在 CPU 上加载和运行。
四、搭建部署自己的接口
编写docker一键部署,有需要可联系我