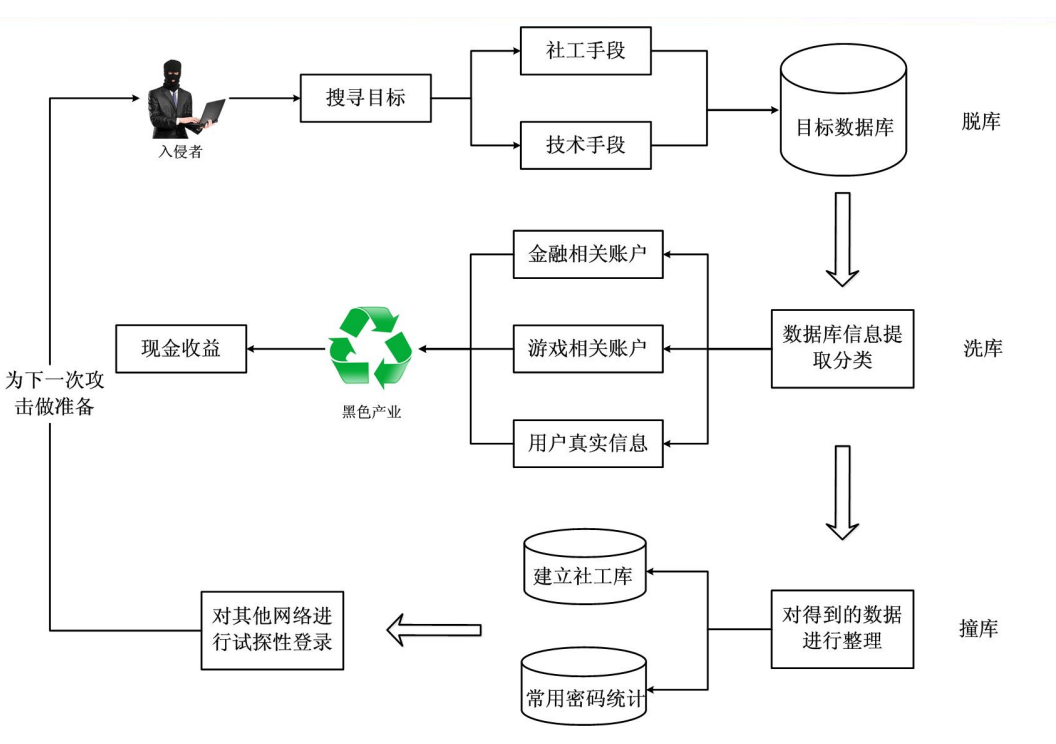
前言
接上文,前文对模型没有过多介绍,随着看的资料增多,对模型有了更多的自我认识,记录一下。要了解模型,我们先从零开始创建一个模型开始:
最简单的方法是使用Python和scikit-learn库。关于scikit-learn库,在这做个简单介绍,类似的库和框架有很多如NumPy、Pandas、TensorFlow、PyTorch,这些不是本文重点,后续有必要再补充,这里不做详细介绍。
Scikit-learn
Scikit-learn(以前称为scikits.learn,也称为sklearn)是一个强大的Python机器学习库,它集成了众多简单高效的机器学习算法,通过一套共用的接口进行调用,极大地方便了机器学习的应用和研究。
一个简单的案例
以下是一个简单的代码示例,演示如何创建和训练一个线性回归模型来预测数据。主要是为了方便大家更好的理解模型。它包括了如下内容:
test.py
主要包括准备数据集、创建和训练模型、评估模型性能、生成模型文件
# 安装scikit-learn库
# 运行以下命令来安装scikit-learn库,如果你还没有安装它:
# !pip install scikit-learn
# 导入必要的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import joblib
# 生成一个简单的数据集
# 假设我们有一些简单的线性数据,y = 2x + 1
X = np.array([[i] for i in range(10)]) # 特征(Feature)
y = np.array([2*i + 1 for i in range(10)]) # 标签(Label)
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# 保存模型
joblib.dump(model, 'linear_regression_model.pkl')
test2.py
加载模型,并输入内容,测试输出结果
from joblib import load
# 加载模型
model = load('linear_regression_model.pkl')
# 使用模型进行预测
# 假设你有一个名为X的输入数据,可以这样进行预测:
predictions = model.predict([[10],[11]])
print(predictions)
执行结果
依次执行test.py、test2.py。结果如下:


案例分析
模型
通过案例,我们可以了解到,模型相当于一个函数,输入后得到对应输出值,上述案例是一个最简单线性回归模型(y=2x+1)。
上述模型尽管复杂性和性能可能与那些大规模数据集上训练的常见预训练模型规模、复杂度、性能有巨大差距,但本质上是一样的,也可以被看作一个预训练模型。
简单模型(我们的线性回归模型)
- 训练数据:在一个小型数据集上训练,可能只涉及非常简单的特征和目标。
- 模型复杂度:模型结构简单,如线性回归、简单的神经网络等。
- 初步训练:模型经过初步训练,学到了一些特定任务的特征。
- 持续提升:可以在更多的数据上继续训练,不断改进性能。
复杂预训练模型(如 BERT、ResNet)
- 训练数据:在大型、丰富的数据集上训练,如 ImageNet、Wikipedia 文本等。
- 模型复杂度:模型结构复杂,包含大量的层和参数,如深度卷积神经网络、变压器网络等。
- 初步训练:模型经过大规模数据集的训练,学到了广泛的特征和模式。
- 迁移学习:在特定任务上进行微调,通过较少的数据和训练时间达到高性能。
模型文件
生成了一个linear_regression_model.pkl文件,它能够被加载并运行得到符合预期的结果。
.pkl 文件用于保存和加载机器学习模型,使得我们可以将训练好的模型持久化存储,通过使用 joblib 库生成(joblib 在内部使用了 pickle 进行序列化,但进行了优化以提高性能,特别是处理大量数据时。)。
个人一句话总结,生成模型的过程模型的进行序列化和反序列化操作。
文件格式
为什么格式是,pkl,和常见的不同?主要原因是使用的库或框架不同,因为不同的机器学习框架和应用场景对模型的存储和加载有着不同的需求。
机器学习模型可以以多种格式保存,常见的包括
.pkl(Pickle)、.pt(PyTorch)、.h5(HDF5)、ONNX(Open Neural Network Exchange)、PMML(Predictive Model Markup Language)以及.bin格式。每种格式都有其特定的用途和优劣势。
.pkl文件通常用于保存任意 Python 对象,包括机器学习模型,但可能受到 Python 版本和库版本的影响。.pt文件是 PyTorch 框架的标准格式,专门用于保存 PyTorch 模型。.h5文件通常与 Keras 和 TensorFlow 框架一起使用,支持压缩和高性能读写。ONNX 格式允许在不同的深度学习框架之间转换模型。PMML 是一个用于表示数据挖掘和机器学习模型的通用 XML 格式。.bin文件通常用于保存预训练的词嵌入模型等,以二进制格式存储,适用于特定的应用场景。选择模型保存格式应考虑工作流程和系统集成需求。
.pt
.bin
问题
这个模型也太简单了,输出值等于输入值乘以2+1。这还有什么训练的必要吗?
确实这个例子确实非常简单,因为我们直接定义了线性关系 y=2x+1。在这种情况下,我们实际上已经知道了模型的参数(系数为2,截距为1),不需要进行训练。但是,实际中的数据通常更加复杂和不确定。
下面我们进行一个更为实际的问题:
一个基于糖尿病数据集的例子,我们将使用线性回归模型来预测糖尿病进展。
案例二
以下代码是一个基于糖尿病数据集的例子,我们将使用线性回归模型来预测糖尿病进展。步骤如下:
①加载糖尿病数据集,并将特征和目标变量分别存储在 X 和 y 中。
②数据集分割:将数据集分为训练集和测试集,测试集占20%。
③创建和训练模型:创建线性回归模型并使用训练数据进行训练。
④预测和评估:使用测试数据进行预测,并计算均方误差(MSE)和R^2得分来评估模型性能。
⑤输出模型参数:打印模型的系数和截距。
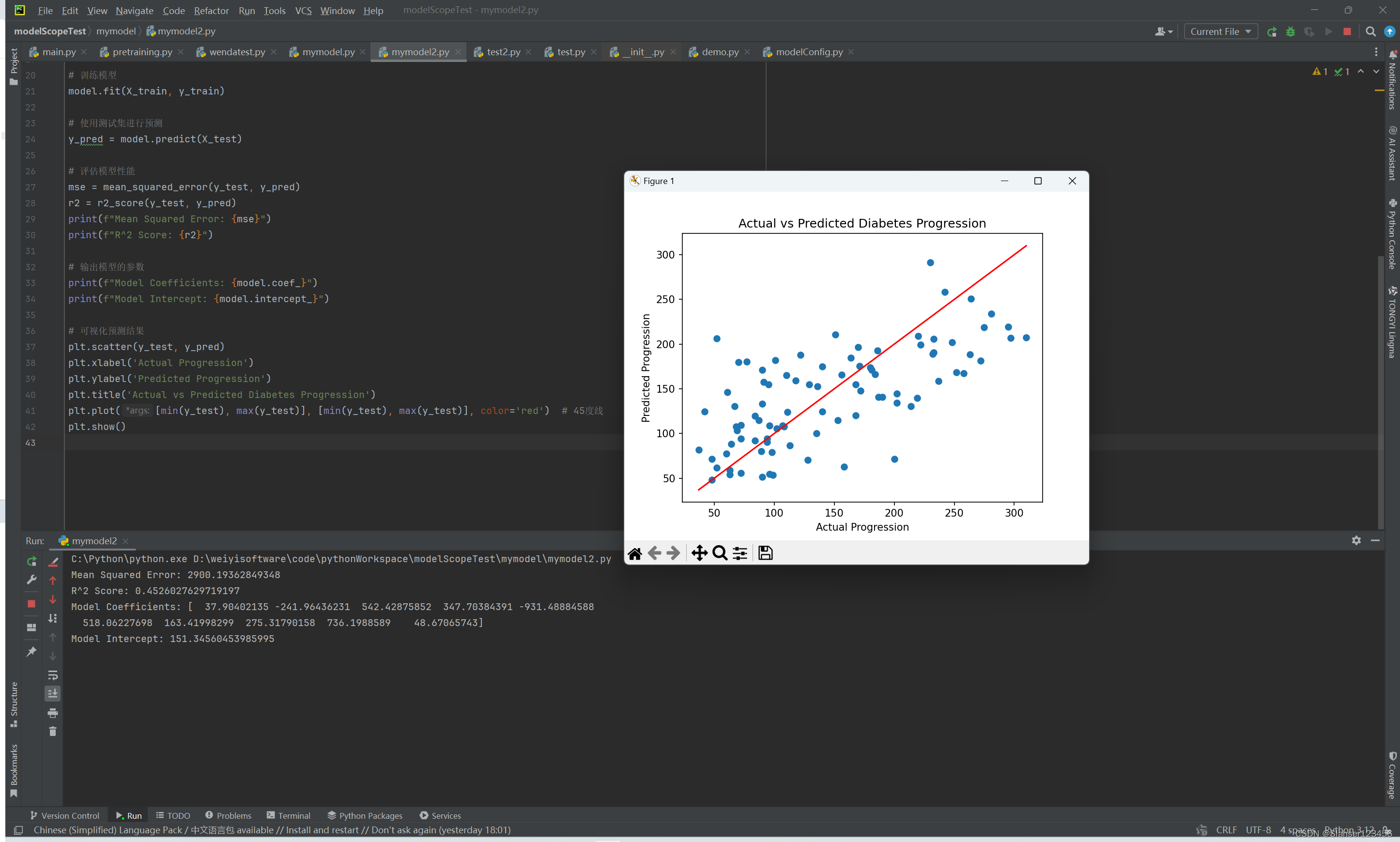
⑥可视化结果:绘制实际值与预测值的散点图,并添加一条45度线以便直观对比预测效果。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载糖尿病数据集
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R^2 Score: {r2}")
# 输出模型的参数
print(f"Model Coefficients: {model.coef_}")
print(f"Model Intercept: {model.intercept_}")
# 可视化预测结果
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Progression')
plt.ylabel('Predicted Progression')
plt.title('Actual vs Predicted Diabetes Progression')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red') # 45度线
plt.show()
案例二分析
训练模型
首先要明白一点,在机器学习中,“训练”指的是模型从数据中学习并调整内部参数的过程,以便能够对新的数据进行预测。这个过程是通过对训练数据进行迭代优化来完成的,模型会尝试不同的参数组合,以最大程度地减少预测误差。
上述运行结果中可以看出来,训练后得到的评估结果得分并不高。
当你运行一次程序,即调用 model.fit(X_train, y_train) 进行训练时,模型确实会根据提供的训练数据来学习,并调整自身的参数。但是,模型学到的内容并不会存储在你的脑子里,而是存储在模型的内部参数中。当你调用 model.predict(X_test) 对新的数据进行预测时,模型会使用已经学到的参数来进行预测。
每次运行程序,模型都会重新进行训练,即使你之前已经运行过相同的程序。这是因为计算机程序的运行是一个临时性的过程,程序结束后,模型的状态并不会被保留。要想在多次运行中保持模型的状态,你可以将训练好的模型保存到文件中,在需要时再加载使用。
我们可以增加训练数据,想必会更精准。我们数据量目前无法变化,下面将训练数据比例增加,可以看到得分变高了。

模型调优
如果我们选择的模型合适,经过大量的数据训练后,再评估时,得分会达到我们的预期,即大部分预测会准确,那么这个时候我们的模型就可以直接使用了。
如果大量数据训练后,依旧达不到要求,例如上述训练后,得分依旧不高(因为我们没有数据了) 。
这种情况下,我还想继续提高得分,应该怎么办?
那就需要改进模型的性能,这就是我们常说的
模型调优
主要包括以下内容:
特征工程:优化特征工程可能是提高模型性能的有效方法。尝试添加新的特征、组合现有特征或者进行特征选择,以提供更丰富和更有信息量的特征。
模型调优:对于已有的模型,尝试调整其超参数或参数,以提高模型的性能。你可以使用交叉验证和网格搜索等技术来寻找最佳的参数组合。
集成学习:尝试集成多个模型的预测结果,如投票法、堆叠法等。集成学习可以通过组合多个模型的预测结果来减少方差,从而提高整体性能。
模型融合:将多个模型的预测结果进行加权平均或者其他组合方式,以获得更稳健的预测。模型融合可以结合不同模型的优点,进一步提高预测的准确性。
更多数据:尝试收集更多的数据来训练模型。更多的数据通常可以帮助模型更好地学习数据的模式,提高性能。
异常值处理:检测并处理异常值,以减少其对模型的影响,从而提高模型的鲁棒性和泛化能力。
模型选择
当然,还有一个原因可能是你的模型并不适合这个场景,这个时候需要你更换模型。在实际应用中,选择合适的模型是一个挑战,特别是对于初学者来说,我们需要学习的有:
了解常用模型:学习一些常用的机器学习模型,了解它们的原理、优缺点和适用场景。这可以帮助你在需要时更快地选择合适的模型。
参考文献和教程:阅读机器学习领域的文献和教程,了解不同模型的特点和适用范围。你可以从书籍、博客、论文、在线课程等资源中获取信息。
交叉验证和网格搜索:使用交叉验证和网格搜索等技术来比较不同模型的性能。这些技术可以帮助你在给定数据集上评估多个模型,并选择性能最好的模型和参数组合。
集成学习:尝试集成学习方法,如随机森林和梯度提升树等。集成学习将多个基本模型的预测结果进行组合,通常可以获得比单个模型更好的性能。
领域知识:了解你所处理数据的领域知识也是选择模型的重要因素。有时候,根据数据的特点和背景知识,可以有针对性地选择合适的模型。
一些学习建议
要想了解更多机器学习相关的内容,基础很重要以下推荐一些基础学习内容:
-
Coursera 课程 - 机器学习(Andrew Ng):
- 这门课程由斯坦福大学教授 Andrew Ng 主讲,是深入理解机器学习基础的绝佳选择。课程涵盖了监督学习、无监督学习、深度学习等多个领域,并提供了丰富的编程作业来帮助学员巩固所学知识。
- Coursera 课程链接
-
书籍 - 《Python机器学习》(Python Machine Learning)(Sebastian Raschka, Vahid Mirjalili):
- 这本书介绍了机器学习的基本理论和实践,以及如何使用 Python 和 scikit-learn 库实现常见的机器学习算法。书中包含大量示例代码和实践项目,适合初学者和有一定编程经验的人士。
- 《Python机器学习》书籍链接
-
网站 - Kaggle:
- Kaggle 是一个数据科学竞赛平台,提供丰富的数据集、教程和机器学习竞赛。你可以在 Kaggle 上找到很多与机器学习和数据科学相关的项目,学习他人的代码和技巧,还可以参与竞赛提升自己的能力。
- Kaggle 网站链接